Pyspark处理数据中带有列分隔符的数据集
Posted DeepHub IMBA
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pyspark处理数据中带有列分隔符的数据集相关的知识,希望对你有一定的参考价值。
本篇文章目标是处理在数据集中存在列分隔符或分隔符的特殊场景。对于Pyspark开发人员来说,处理这种类型的数据集有时是一件令人头疼的事情,但无论如何都必须处理它。
数据集基本上如下所示:
#first line is the headerNAME|AGE|DEP
Vivek|Chaudhary|32|BSC
John|Morgan|30|BE
Ashwin|Rao|30|BE
数据集包含三个列" Name ", " AGE ", " DEP ",用分隔符" | "分隔。如果我们关注数据集,它也包含' | '列名。
让我们看看如何进行下一步:
步骤1。使用spark的Read .csv()方法读取数据集:
#create spark session
import pyspark
from pyspark.sql import SparkSession
spark=SparkSession.builder.appName(‘delimit’).getOrCreate()
上面的命令帮助我们连接到spark环境,并让我们使用spark.read.csv()读取数据集
#create
df=spark.read.option(‘delimiter’,’|’).csv(r’<path>/delimit_data.txt’,inferSchema=True,header=True)
df.show()
从文件中读取数据并将数据放入内存后我们发现,最后一列数据在哪里,列年龄必须有一个整数数据类型,但是我们看到了一些其他的东西。这不是我们所期望的。一团糟,完全不匹配,不是吗?答案是肯定的,确实一团糟。
现在,让我们来学习如何解决这个问题。
步骤2。再次读取数据,但这次使用Read .text()方法:
df=spark.read.text(r’/Python_Pyspark_Corp_Training/delimit_data.txt’)
df.show(truncate=0)
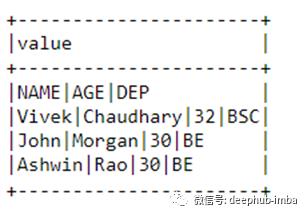
#extract first row as this is our header
head=df.first()[0]
schema=[‘fname’,’lname’,’age’,’dep’]
print(schema)
Output: ['fname', 'lname', 'age', 'dep']
下一步是根据列分隔符对数据集进行分割:
#filter the header, separate the columns and apply the schema
df_new=df.filter(df[‘value’]!=head).rdd.map(lambda x:x[0].split(‘|’)).toDF(schema)
df_new.show()
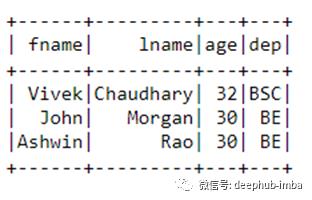
现在,我们已经成功分离出列。
我们已经成功地将“|”分隔的列(“name”)数据分成两列。现在,数据更加干净,可以轻松地使用。
接下来,连接列“fname”和“lname”:
from pyspark.sql.functions import concat, col, lit
df1=df_new.withColumn(‘fullname’,concat(col(‘fname’),lit(“|”),col(‘lname’)))
df1.show()
要验证数据转换,我们将把转换后的数据集写入CSV文件,然后使用read. CSV()方法读取它。
df1.write.option(‘sep’,’|’).mode(‘overwrite’).option(‘header’,’true’).csv(r’<file_path>\cust_sep.csv’)
下一步是数据验证:
df=spark.read.option(‘delimiter’,’|’).csv(r<filepath>,inferSchema=True,header=True)
df.show()
现在的数据看起来像我们想要的那样。
作者:Vivek Chaudhary
deephub翻译组
以上是关于Pyspark处理数据中带有列分隔符的数据集的主要内容,如果未能解决你的问题,请参考以下文章