Hive/Spark小文件解决方案(企业级实战)
Posted 大数据私房菜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive/Spark小文件解决方案(企业级实战)相关的知识,希望对你有一定的参考价值。
程序产生小文件的原因
程序运行的结果最终落地有很多的小文件,产生的原因:
读取的数据源就是大量的小文件
动态分区插入数据,会产生大量的小文件,从而导致map数量剧增
Reduce/Task数量较多,最终落地的文件数量和Reduce/Task的个 数是一样的
小文件带来的影响
文件的数量决定了MapReduce/Spark中Mapper/Task数量,小文件越多,Mapper/Task的任务越多,每个Mapper/Task都会对应启动一个JVM/线程来运行,每个Mapper/Task执行数据很少、个数多,导致占用资源多,甚至这些任务的初始化可能比执行的时间还要多,严重影响性能,当然这个问题可以通过CombinedInputFile和开启JVM重用来解决;
但是文件存储在HDFS上,每个文件的元数据信息(位置、大小、分块信息)大约占150个字节,文件的元数据信息会分别存储在内存和磁盘中,磁盘中的fsimage作为冷备安全性保障,内存中的数据作为热备做到快速响应请求(+editslog)。
如何解决小文件问题
1、distribute by
少用动态分区,如果场景下必须使用时,那么记得在SQL语句最后添加上distribute by
假设现在有20个分区,我们可以将dt(分区键)相同的数据放到同一个Reduce处理,这样最多也就产生20个文件,dt相同的数据放到同一个Reduce可以使用DISTRIBUTE BY dt实现,所以修改之后的SQL如下:
insert overwrite table temp.wlb_tmp_smallfile partition(dt)
select * from process_table
DISTRIBUTE BY dt;
修改完之后的SQL运行良好,并没有出现上面的异常信息,但是这里也有个问题,这20个分区目录下每个都只有一个文件!!这样用计算框架(MR/Spark)读取计算时,Mapper/Task数量根据文件数而定,并发度上不去,直接导致了这个SQL运行的速度很慢

能不能将数据均匀的分配呢?可以!我们可以使用DISTRIBUTE BY rand()控制在map端如何拆分数据给reduce端的,hive会根据distribute by后面列,对应reduce的个数进行分发,默认采用的是hash算法。rand()方法会生成一个0~1之间的随机数[rand(int param)返回一个固定的数值],通过随机数进行数据的划分,因为每次都随机的,所以每个reducer上的数据会很均匀。将数据随机分配给Reduce,这样可以使得每个Reduce处理的数据大体一致
主要设置参数:可以根据集群情况而修改,可以作为hive-site.xml的默认配置参数
-- 在 map only 的任务结束时合并小文件
set hive.merge.mapfiles = true;
-- 在 MapReduce 的任务结束时合并小文件
set hive.merge.mapredfiles = true;
-- 作业结束时合并文件的大小
set hive.merge.size.per.task = 256000000;
-- 每个Map最大输入大小(这个值决定了合并后文件的数量)
set mapred.max.split.size=256000000;
-- 每个reducer的大小, 默认是1G,输入文件如果是10G,那么就会起10个reducer;
set hive.exec.reducers.bytes.per.reducer=1073741824;
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
添加了如上的hive参数以及分区表的最后加上 distribute by rand()这样运行后的结果,每个文件都比 hive.merge.size.per.task:256M大(最后一个文件除外)
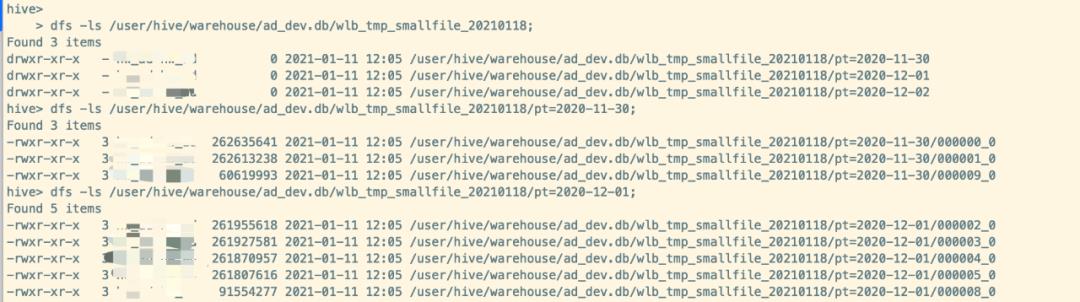
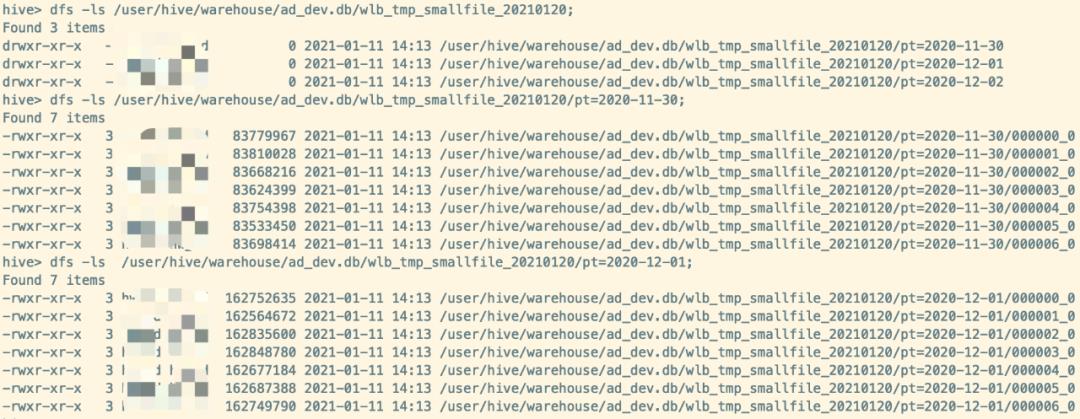
如果想要具体最后落地生成多少个文件数,使用 distribute by cast( rand * N as int) 这里的N是指具体最后落地生成多少个文件数,那么最终就是每个分区目录下生成7个 文件大小基本一致的文件。修改的SQL如下
insert overwrite table temp.wlb_smallfile partition(dt)
select * from process_table
distribute by cast(rand()*7 as int);
2、repartition/coalesce
对于已有的可以使用动态分区重刷数据,或者使用Spark程序重新读取小文件的table得到DataFrame,然后再重新写入,如果Spark的版本>=2.4那么推荐使用 Repartition/Coalesce Hint
在使用SparkSql进行项目开发的过程,往往会碰到一个比较头疼的问题,由于SparkSql的默认并行度是200,当sql中包含有join、group by相关的shuffle操作时,会产生很多小文件;太多的小文件对后续使用该表进行计算时会启动很多不必要的maptask,任务耗时高。因此,需要对小文件问题进行优化。
在Dataset/Dataframe中有repartition/coalesce算子减少输出文件个数,但用户往不喜欢编写和部署Scala/Java/Python代码的repartition(n)和coalese(n),在Spark 2.4.0版本后很优雅地解决了这个问题,可以下SparkSql中添加以下Hive风格的合并和分区提示:
--提示名称不区分大小写
INSERT ... SELECT /*+REPARTITION(n)*/ ...
INSERT ... SELECT /*+COALESCE(n)*/ ...
Coalesce Hint减少了分区数,它仅合并分区 ,因此最大程度地减少了数据移动,但须注意内存不足容易OOM。
Repartition Hint可以增加或减少分区数量,它执行数据的完全shuffle,并确保数据平均分配。
repartition增加了一个新的stage,因此它不会影响现有阶段的并行性;相反,coalesce会影响现有阶段的并行性,因为它不会添加新stage。该写法还支持多个插入查询和命名子查询。
额外补充两者的区别
coalesce,一般有使用到Spark进行完业务处理后,为了避免小文件问题,对RDD/DataFrame进行分区的缩减,避免写入HDFS有大量的小文件问题,从而给HDFS的NameNode内存造成大的压力,而调用coalesce,实则源码调用的是case class Repartition shuffle参数为false的,默认是不走shuffle的。
假设当前spark作业的提交参数是num-executor 10 ,executor-core 2,那么就会有20个Task同时并行,如果对最后结果DataFrame进行coalesce操作缩减为(10),最后也就只会生成10个文件,也表示只会运行10个task,就会有大量executor空跑,cpu core空转的情况;
而且coalesce的分区缩减是全在内存里进行处理,如果当前处理的数据量过大,这样很容易就导致程序OOM异常
如果 coalesce 前的分区数小于 后预想得到的分区数,coalesce就不会起作用,也不会进行shuffle,因为父RDD和子RDD是窄依赖
repartition,常用的情况是:上游数据分区数据分布不均匀,才会对RDD/DataFrame等数据集进行重分区,将数据重新分配均匀,
假设原来有N个分区,现在repartition(M)的参数传为M,
而 N < M ,则会根据HashPartitioner (key的hashCode % M)进行数据的重新划分
而 N 远大于 M ,那么还是建议走repartition,这样所有的executor都会运作起来,效率更高,如果还是走coalesce,假定参数是1,那么即使原本申请了10个executor,那么最后执行的也只会有1个executor。
3、使用HAR归档文件
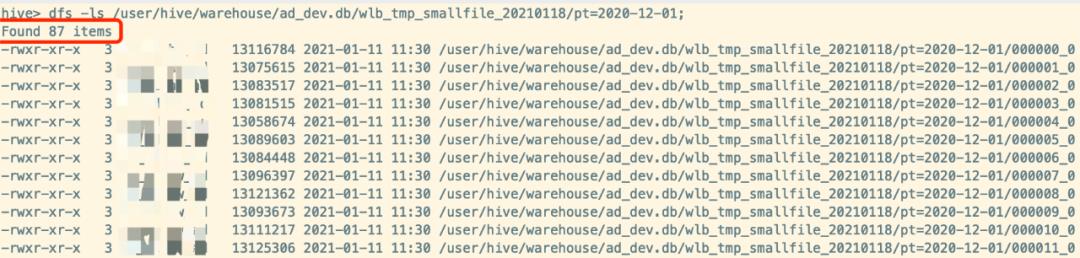
以上方法可以修改后运用于每日定时脚本,对于已经产生小文件的hive表可以使用har归档,而且Hive提供了原生支持:
set hive.archive.enabled= true ;
set hive.archive.har.parentdir.settable= true ;
set har.partfile.size=256000000;
ALTER TABLE ad_dev.wlb_tmp_smallfile_20210118 ARCHIVE PARTITION(pt='2020-12-01');
以上是关于Hive/Spark小文件解决方案(企业级实战)的主要内容,如果未能解决你的问题,请参考以下文章
hive on spark hql 插入数据报错 Failed to create Spark client for Spark session Error code 30041