一网打尽Spark高频面试题
Posted 大数据那些事
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一网打尽Spark高频面试题相关的知识,希望对你有一定的参考价值。
01
Spark主要解决什么问题?
02
Spark为什么会有自己的资源调度器?
Hadoop的Yarn框架比Spark框架诞生的晚,所以Spark自己也设计了一套资源调度框架。
03
Spark的运行模式都有哪些?
04
Spark的常用端口号都有哪些?
05
简述Spark的架构与作业提交流程。
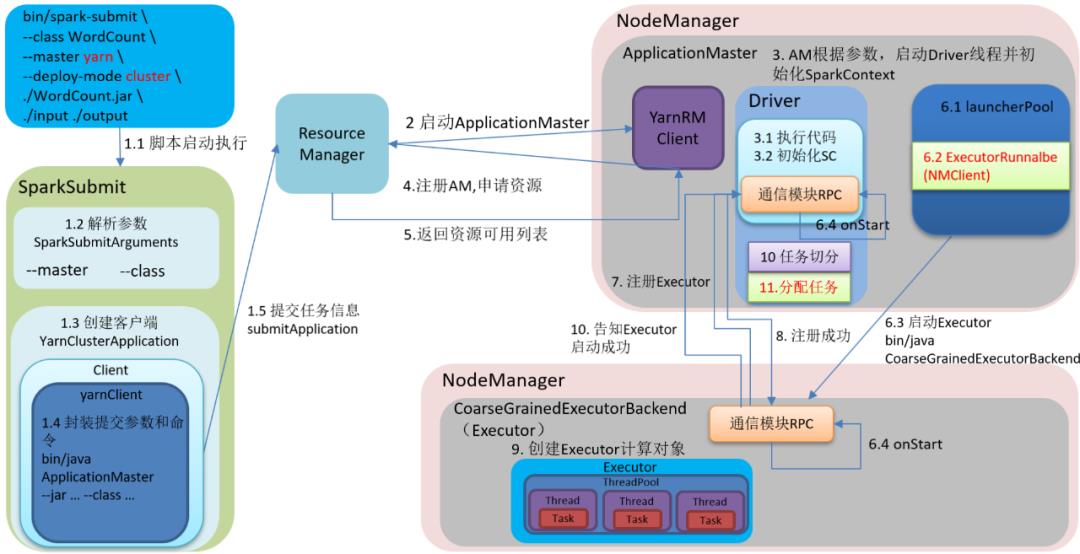
06
Spark任务通过什么形式进行提交?作业提交参数都有哪些?
使用shell脚本提交。
1)在提交任务时的几个重要参数
executor-cores —— 每个executor使用的内核数,默认为1,官方建议2-5个,我们企业是4个
num-executors —— 启动executors的数量,默认为2
executor-memory ——executor内存大小,默认1G
driver-cores ——driver使用内核数,默认为1
driver-memory —— driver内存大小,默认512M
2)给一个提交任务的样式
spark-submit \
--master local[5] \
--driver-cores 2 \
--driver-memory 8g \
--executor-cores 4 \
--num-executors 10 \
--executor-memory 8g \
--class PackageName.ClassName XXXX.jar \
--name "Spark Job Name" \
InputPath \
OutputPath
07
RDD都有哪些重要特性?(简述你对RDD的认识)
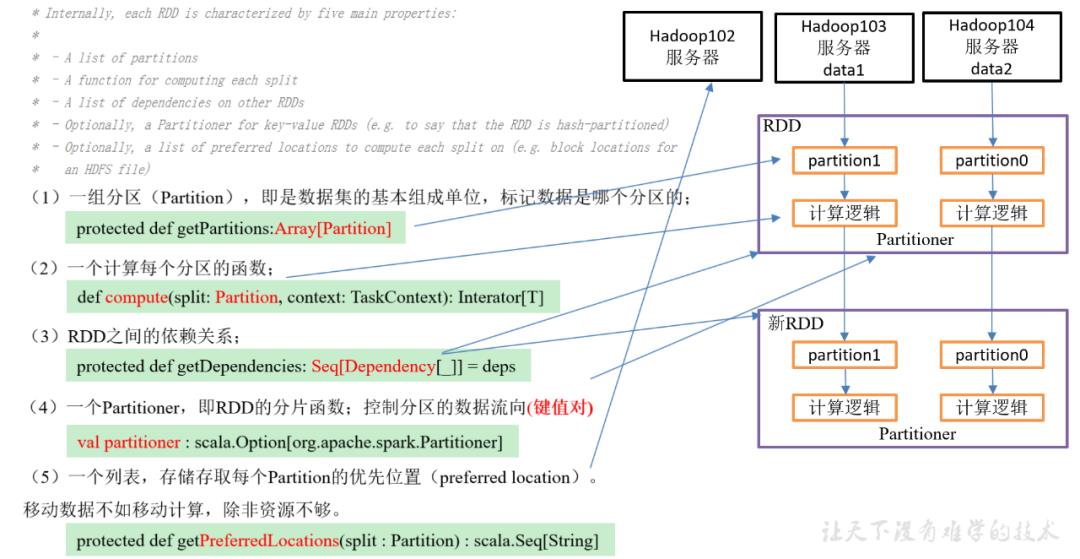
08
Spark常用的transformation算子都有哪些?
1)单Value
(1)map
(2)mapPartitions
(3)mapPartitionsWithIndex
(4)flatMap
(5)glom
(6)groupBy
(7)filter
(8)sample
(9)distinct
(10)coalesce
(11)repartition
(12)sortBy
(13)pipe
2)双vlaue
(1)intersection
(2)union
(3)subtract
(4)zip
3)Key-Value
(1)partitionBy
(2)reduceByKey
(3)groupByKey
(4)aggregateByKey
(5)foldByKey
(6)combineByKey
(7)sortByKey
(8)mapValues
(9)join
(10)cogroup
09
map和mapPartition有什么区别?
1)map:每次处理一条数据
2)mapPartitions:每次处理一个分区数据
10
repartition和coalesce有什么区别?
11
reduceByKey和groupByKey有什么区别?
12
13
Kryo序列化?
14
Spark如何进行任务的划分?
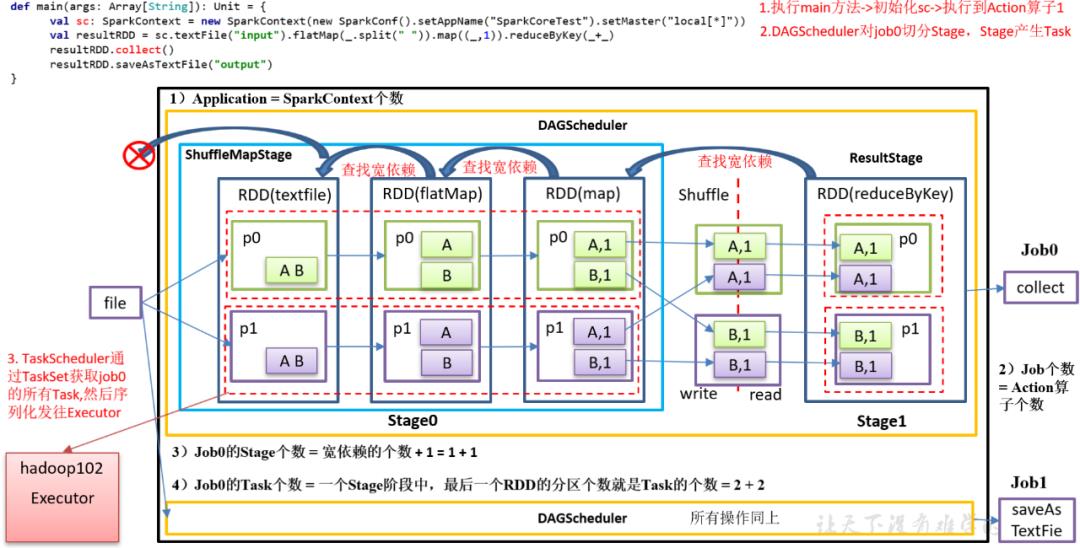
15
缓存cache和检查点checkpoint区别有什么区别?
16
Spark累加器的工作原理?
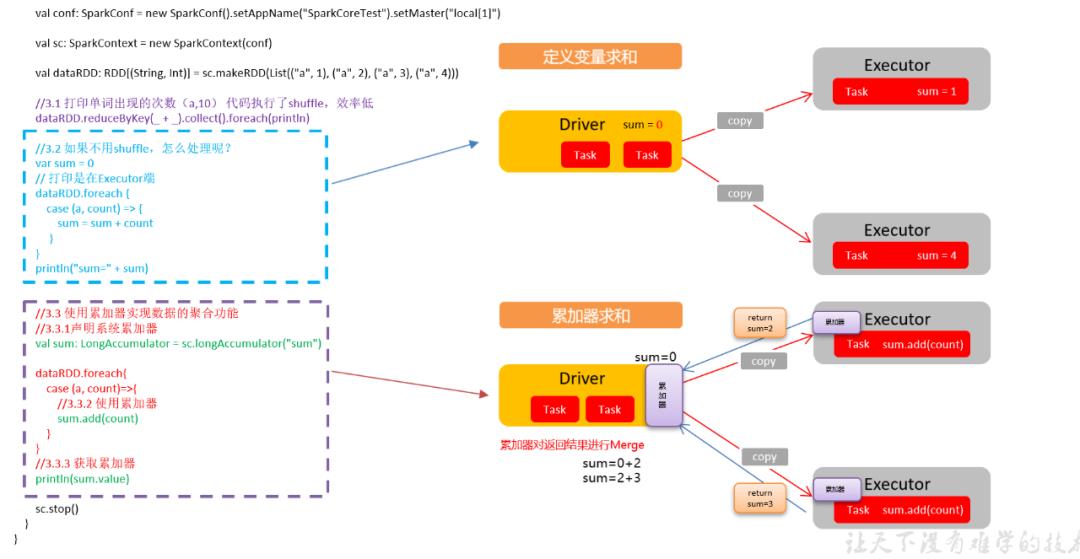
17
Spark广播变量的工作原理?
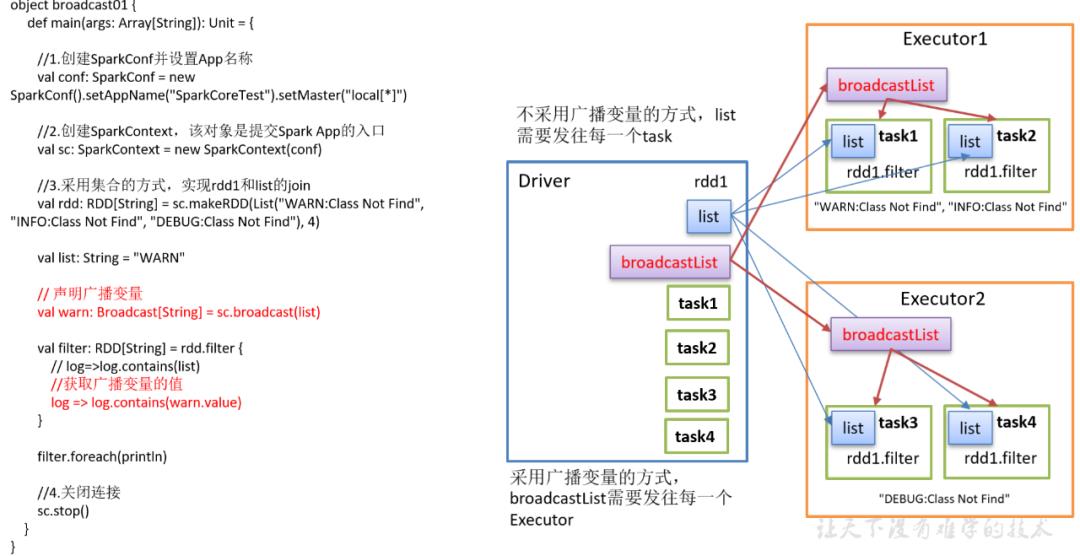
18
SparkSQL中RDD、DataFrame、DataSet三者如何进行互相转换?
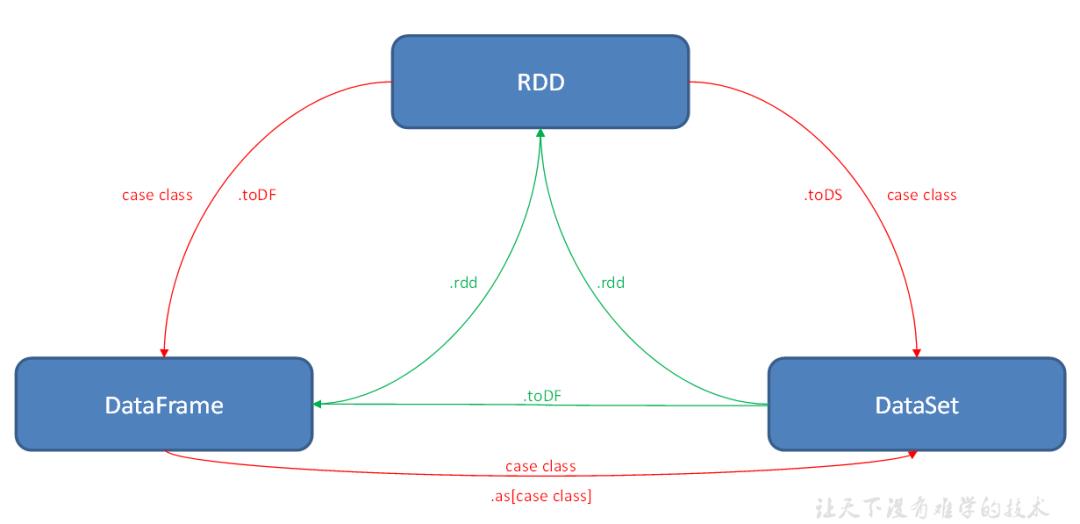
19
当Spark涉及到数据库的操作时,如何减少Spark运行中的数据库连接数?
20
如何使用Spark实现TopN的获取(描述思路或使用伪代码)?

●
●


B站|大数据那些事
想获取更多更全资料
扫码加好友入群
欢迎各位大佬加入开源共享
共同面对大数据领域疑难问题
来稿请投邮箱:miaochuanhai@126.com
以上是关于一网打尽Spark高频面试题的主要内容,如果未能解决你的问题,请参考以下文章