英雄惜英雄-当Spark遇上Zeppelin之实战案例
Posted 大数据技术与架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了英雄惜英雄-当Spark遇上Zeppelin之实战案例相关的知识,希望对你有一定的参考价值。
我们在之前的文章中提到过一文中介绍了 Zeppelin 的主要功能和特点,并且最后还用一个案例介绍了这个框架的使用。这节课我们用两个直观的小案例来介绍 Zepplin 和 Spark 如何配合使用。
到目前为止,Apache Spark 已经支持三种集群管理器类型(Standalone,Apache Mesos 和 Hadoop YARN )。本文中我们根据官网文档使用 Docker 脚本构建一个Spark standalone mode ( Spark独立模式 )的环境来使用。
Spark独立模式环境搭建
Spark standalone 是Spark附带的简单集群管理器,可以轻松设置集群。您可以通过以下步骤简单地设置 Spark独立环境。
注意
由于 Apache Zeppelin 和 Spark 为其 Web UI 使用相同的 8080 端口,因此您可能需要在 conf / zeppelin-site.xml 中更改 zeppelin.server.port 。
1. 构建 Docker 文件
您可以在脚本 / docker / spark-cluster-managers 下找到 docker 脚本文件。
cd $ZEPPELIN_HOME/scripts/docker/spark-cluster-managers/spark_standalone
docker build -t "spark_standalone" .
2. 启动Docker
docker run -it \
-p 8080:8080 \
-p 7077:7077 \
-p 8888:8888 \
-p 8081:8081 \
-h sparkmaster \
--name spark_standalone \
spark_standalone bash;
在这里运行 docker 容器的 sparkmaster 主机名应该在 /etc/hosts 中绑定映射关系。
3. 在Zeppelin中配置Spark解释器
将 Spark master 设置为 spark://< hostname >:7077 在 Zeppelin 的解释器设置页面上。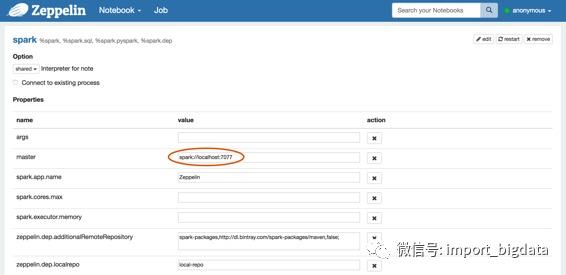
4. 用Spark解释器运行Zeppelin
在 Zeppelin 中运行带有 Spark 解释器的单个段落后,浏览 https://< hostname>:8080,并检查 Spark 集群是否运行正常。
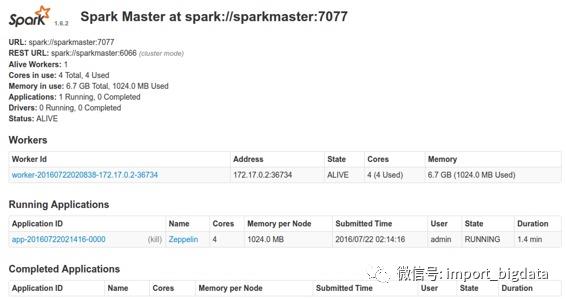
然后我们可以用以下命令简单地验证 Spark 在 Docker 中是否运行良好。
ps -ef | grep spark
Spark on Zepplin读取本地文件
假设我们本地有一个名为bank.csv的文件,样例数据如下:
age:Integer, job:String, marital : String, education : String, balance : Integer
20;teacher;single;本科;20000
25;plumber;single;本科;10000
21;doctor;single;本科;25000
23;singer;single;本科;20000
...
首先,将csv格式的数据转换成RDD Bank对象,运行以下脚本。这也将使用filter功能过滤掉一些数据。
val bankText = sc.textFile("yourPath/bank/bank-full.csv")
case class Bank(age:Integer, job:String, marital : String, education : String, balance : Integer)
// split each line, filter out header (starts with "age"), and map it into Bank case class
val bank = bankText.map(s=>s.split(";")).filter(s=>s(0)!="\"age\"").map(
s=>Bank(s(0).toInt,
s(1).replaceAll("\"", ""),
s(2).replaceAll("\"", ""),
s(3).replaceAll("\"", ""),
s(5).replaceAll("\"", "").toInt
)
)
// convert to DataFrame and create temporal table
bank.toDF().registerTempTable("bank")
如果想使用图形化看到年龄分布,可以运行如下sql:%sql select age, count(1) from bank where age < 30 group by age order by age
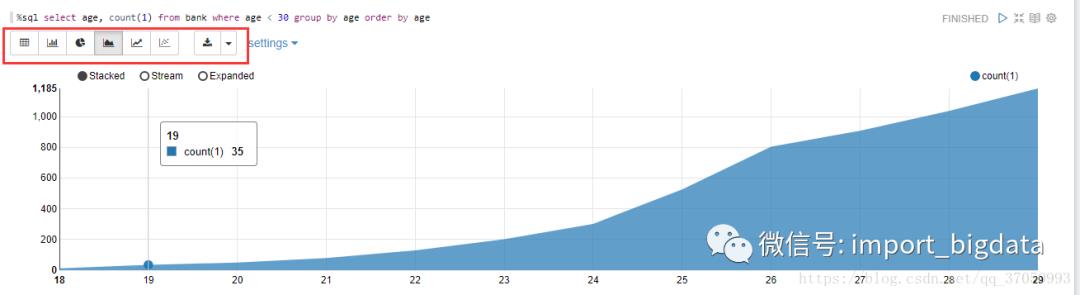
您可以输入框通过更换设置年龄条件30用${maxAge=30}。%sql select age, count(1) from bank where age < ${maxAge=30} group by age order by age
如果希望看到有一定婚姻状况的年龄分布,并添加组合框来选择婚姻状况:%sql select age, count(1) from bank where marital="${marital=single,single|divorced|married}" group by age order by age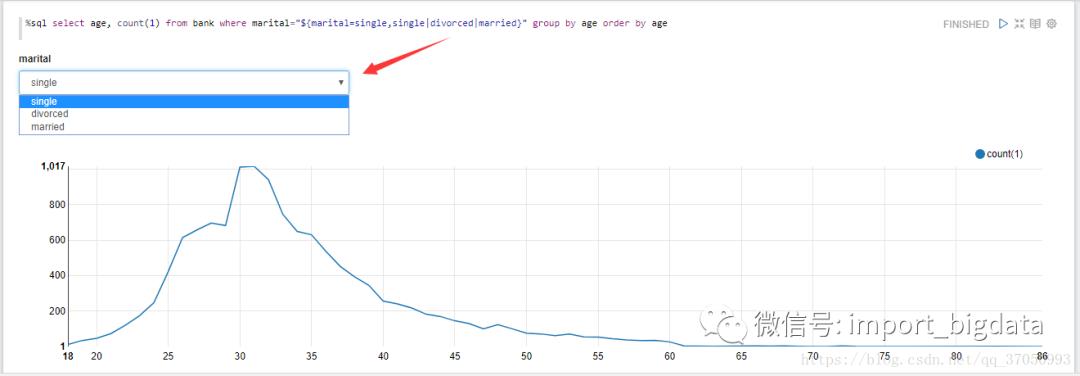
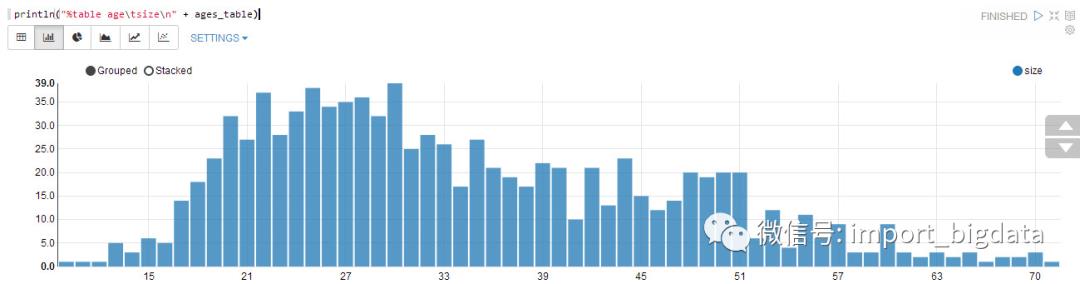
Zeppelin支持画图,功能简单但强大,可同时输出表格、柱状图、折线图、饼状图、折线图、点图。下面将各年龄的用户数用画出来,画图的实现可以将结果组织成下面这种格式:
println(“%table column_1\tcolumn_2\n”+value_1\tvalue_2\n+…)
最后,我们甚至可以直接将运算结果存入 mysql 中:
%spark
df3.write.mode("overwrite").format("jdbc").option("driver","com.mysql.jdbc.Driver").option("user","root").option("password","password").option("url","jdbc:mysql://localhost:3306/spark_demo").option("dbtable","record").save()
Spark on Zepplin读取HDFS文件
首先我们需要配置HDFS文件系统解释器,我们需要进行如下的配置。在笔记本中,要启用HDFS解释器,可以单击齿轮图标并选择HDFS。

然后我们就可以愉快的使用Zepplin读取HDFS文件了:
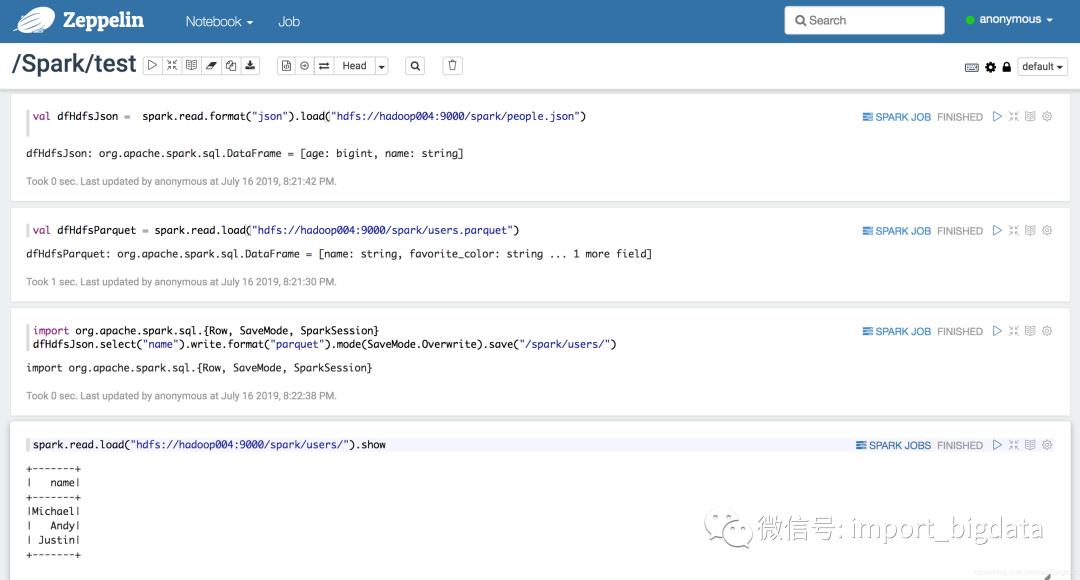
例如:下面先读取HDFS文件,该文件为JSON文件,读取出来之后取出第一列然后以Parquet的格式保存到HDFS上:
Spark on Zepplin读取流数据
我们可以参考官网中,读取Twitter实时流的案例:
import org.apache.spark.streaming._
import org.apache.spark.streaming.twitter._
import org.apache.spark.storage.StorageLevel
import scala.io.Source
import scala.collection.mutable.HashMap
import java.io.File
import org.apache.log4j.Logger
import org.apache.log4j.Level
import sys.process.stringSeqToProcess
/** Configures the Oauth Credentials for accessing Twitter */
def configureTwitterCredentials(apiKey: String, apiSecret: String, accessToken: String, accessTokenSecret: String) {
val configs = new HashMap[String, String] ++= Seq(
"apiKey" -> apiKey, "apiSecret" -> apiSecret, "accessToken" -> accessToken, "accessTokenSecret" -> accessTokenSecret)
println("Configuring Twitter OAuth")
configs.foreach{ case(key, value) =>
if (value.trim.isEmpty) {
throw new Exception("Error setting authentication - value for " + key + " not set")
}
val fullKey = "twitter4j.oauth." + key.replace("api", "consumer")
System.setProperty(fullKey, value.trim)
println("\tProperty " + fullKey + " set as [" + value.trim + "]")
}
println()
}
// Configure Twitter credentials
val apiKey = "xxxxxxxxxxxxxxxxxxxxxxxxx"
val apiSecret = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
val accessToken = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
val accessTokenSecret = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
configureTwitterCredentials(apiKey, apiSecret, accessToken, accessTokenSecret)
import org.apache.spark.streaming.twitter._
val ssc = new StreamingContext(sc, Seconds(2))
val tweets = TwitterUtils.createStream(ssc, None)
val twt = tweets.window(Seconds(60))
case class Tweet(createdAt:Long, text:String)
twt.map(status=>
Tweet(status.getCreatedAt().getTime()/1000, status.getText())
).foreachRDD(rdd=>
// Below line works only in spark 1.3.0.
// For spark 1.1.x and spark 1.2.x,
// use rdd.registerTempTable("tweets") instead.
rdd.toDF().registerAsTable("tweets")
)
twt.print
ssc.start()
同理,Zepplin也可以读取Kafka中的数据,注册成表然后进行各种运算。我们参考一个Zepplin版本的WordCount实现:
%spark
import _root_.kafka.serializer.DefaultDecoder
import _root_.kafka.serializer.StringDecoder
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming._
// prevent INFO logging from pollution output
sc.setLogLevel("INFO")
// creating the StreamingContext with 5 seconds interval
val ssc = new StreamingContext(sc, Seconds(5))
val kafkaConf = Map(
"metadata.broker.list" -> "localhost:9092",
"zookeeper.connect" -> "localhost:2181",
"group.id" -> "kafka-streaming-example",
"zookeeper.connection.timeout.ms" -> "1000"
)
val lines = KafkaUtils.createStream[Array[Byte], String, DefaultDecoder, StringDecoder](
ssc,
kafkaConf,
Map("test" -> 1), // subscripe to topic and partition 1
StorageLevel.MEMORY_ONLY
)
val words = lines.flatMap{ case(x, y) => y.split(" ")}
import spark.implicits._
val w=words.map(x=> (x,1L)).reduceByKey(_+_)
w.foreachRDD(rdd => rdd.toDF.registerTempTable("counts"))
ssc.start()
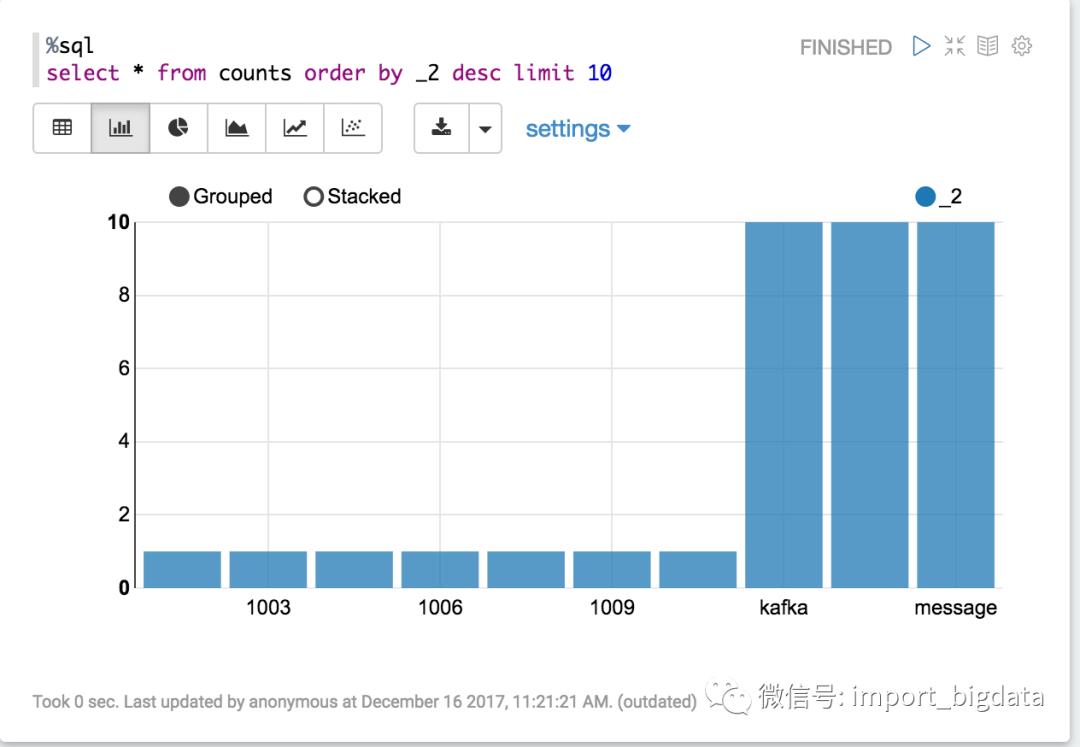
从上面的temporary table counts 中查询每小批量的数据中top 10 的单词值。
select * from counts order by _2 desc limit 10
怎么样?是不是很强大?推荐大家可以自己试试看。

大数据可视化从未如此简单 - Apache Zepplien全面介绍
Flink SQL 1.11 on Zeppelin集成指南
你不可不知的任务调度神器-AirFlow

以上是关于英雄惜英雄-当Spark遇上Zeppelin之实战案例的主要内容,如果未能解决你的问题,请参考以下文章
机器学习英雄访谈录之 Kaggle Kernels 专家:Aakash Nain