0-4 统计建模划分训练/验证/测试集的几种方法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了0-4 统计建模划分训练/验证/测试集的几种方法相关的知识,希望对你有一定的参考价值。
参考技术A 1. 最简单的随机拆分,一般拆为80%训练集20%测试集 或 70%训练集30%测试集。使用训练集训练,然后使用测试集测试模型效果。2. k折交叉验证:把整个数据集设法均分成k折(一般为随机拆分)。然后使用其中的k-1折进行训练,使用剩下的一折测试。这样实际上训出了k个模型。
3. 留一法:k折的极限就是留一。使用m-1个样本进行训练,剩下的那个样本进行测试。
4. 自助采样法 :在原始样本集中有放回的随机采样m次,构成与原始样本集一样大小的训练集(都有m个样本)。根据概率,会有约36.8%的样本没有被采到(另外60+%的样本则有很多被重复采到)。这样可以使用采出来的大小为m且包含重复样本的集合为训练集,剩下约36.8%的样本当测试集。
之所以把数据集分为训练集和测试集,主要是为了在保证模型不要过拟合的前提下,调整超参数使模型性能尽可能地高。因此一般套路是,在训练集训完,然后在测试集上测试,发现性能掉的厉害或者性能还不够好,调调超参,再训一个试试。因此有种说法:训练集是用来学习超参的。
问题是:虽然模型是在训练集上学的,但超参在测试集的测试结果的反馈下进行调整的,这显然也采到了测试集的信息。这样训出来的模型很有可能结果是,模型表现足够好(性能优秀)且在训练集和测试集上表现一致(看似没有过拟合),但放到新数据集上一看其泛化性能并不好。这是因为模型在整个数据集上其实发生了过拟合,这组基于测试集表现找到的超参是仅仅适用于当前这个样本集。
验证集就是用来解决上述问题的。我们把数据集按6/2/2划分为训练集、验证集、测试集。训练一波放到验证集上验证一波,然后调超参,最后觉得差不多了,把模型放到测试集上一测,发现性能没有下降,而在这之前模型和测试集没有发生任何接触,所以证明了其泛化性能,美滋滋,模型训练结束。
但是这里有个bug,前面说是“性能没有发生下降”,模型训练就完美结束了。但如果发生不可忍受的下降呢,说明模型训练的有问题,OK,那就返回去调参,但这次调参,就是由测试集反馈来的,因此引入了测试集的信息,这样来回搞几波,跟前面还有什么区别呢?
要解决这个问题,理论上我们要始终有一个模型从没有接触的测试集,直到“放到测试集上测试然后通过”这件事能一次性完成,模型的泛化性能才能充分可信。但我们事先不知道这个到底什么时候能实现,所以理论上我们得把数据集划分为无数个训练集验证集测试集~~
当然前面说的是理论上,实践中没必要这么较真,模型泛化性能谁也不能保证百分之百,能用就行。毋庸置疑的是,把数据集划分成训练集验证集和测试集,肯定比简单地划分为训练集测试集更好一些。
K折交叉验证
交叉验证的思想
交叉验证主要用于防止模型过于复杂而引起的过拟合,是一种评价训练数据的数据集泛化能力的统计方法。其基本思想是将原始数据进行划分,分成训练集和测试集,训练集用来对模型进行训练,测试集用来测试训练得到的模型,以此来作为模型的评价指标。
简单的交叉验证
将原始数据D按比例划分,比如7:3,从D中随机选择70%的数据作为训练集train_data,剩余的作为测试集test_data(绿色部分)。如下图所示,这里的数据都只利用了一次,并没有充分利用,对于小数据集,需要充分利用其数据的信息来训练模型,一般会选择K折交叉验证。

K折交叉验证
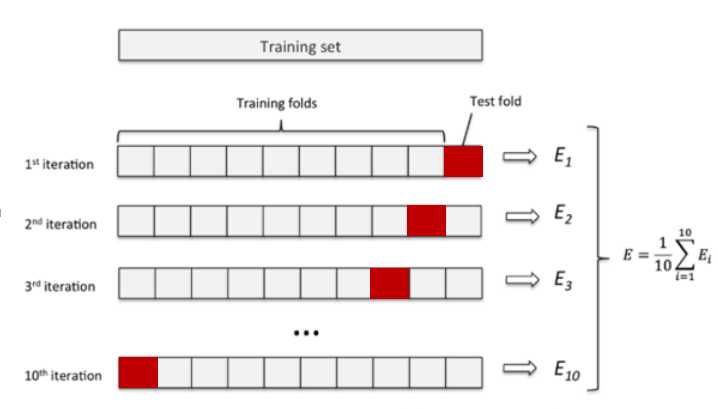
将原始数据D随机分成K份,每次选择(K-1)份作为训练集,剩余的1份(红色部分)作为测试集。交叉验证重复K次,取K次准确率的平均值作为最终模型的评价指标。过程如下图所示,它可以有效避免过拟合和欠拟合状态的发生,K值的选择根据实际情况调节。
python实现
使用scikit-learn模块中的方法KFold,示例如下:
1 from sklearn.model_selection import KFold 2 import numpy as np 3 x = np.array([‘B‘, ‘H‘, ‘L‘, ‘O‘, ‘K‘, ‘P‘, ‘W‘, ‘G‘]) 4 kf = KFold(n_splits=2) 5 d = kf.split(x) 6 for train_idx, test_idx in d: 7 train_data = x[train_idx] 8 test_data = x[test_idx] 9 print(‘train_idx:, train_data:‘.format(train_idx, train_data)) 10 print(‘test_idx:, test_data:‘.format(test_idx, test_data)) 11 12 # train_idx:[4 5 6 7], train_data:[‘K‘ ‘P‘ ‘W‘ ‘G‘] 13 # test_idx:[0 1 2 3], test_data:[‘B‘ ‘H‘ ‘L‘ ‘O‘] 14 # train_idx:[0 1 2 3], train_data:[‘B‘ ‘H‘ ‘L‘ ‘O‘] 15 # test_idx:[4 5 6 7], test_data:[‘K‘ ‘P‘ ‘W‘ ‘G‘]
以上是关于0-4 统计建模划分训练/验证/测试集的几种方法的主要内容,如果未能解决你的问题,请参考以下文章