数据挖掘算法:AdaBoost
Posted 广东工业大学大数据战略研究院
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘算法:AdaBoost相关的知识,希望对你有一定的参考价值。
写在最前:广东工业大学大数据战略研究院一直以“推动大数据理论与应用研究,促进大数据学术交流,力争成为政府和企业的智囊团和思想库”为使命。欢迎各位踊跃赐稿,我们将择优选登,一起交流学习!
这是“数据挖掘”第6篇推送
集成学习
集成学习(ensemble learning)通过组合多个基分类器(base classifier)来完成学习任务,颇有点“三个臭皮匠顶个诸葛亮”的意味。
基分类器一般采用的是弱可学习(weakly learnable)分类器,通过集成学习,组合成一个强可学习(strongly learnable)分类器。
所谓弱可学习,是指学习的正确率仅略优于随机猜测的多项式学习算法;强可学习指正确率较高的多项式学习算法。
集成学习的泛化能力一般比单一的基分类器要好,这是因为大部分基分类器都分类错误的概率远低于单一基分类器的。
偏差与方差
“偏差-方差分解”(bias variance decomposition)是用来解释机器学习算法的泛化能力的一种重要工具。
对于同一个算法,在不同训练集上学得结果可能不同。对于训练集D={(x1,y1),(x2,y2),⋯,(xN,yN)}D={(x1,y1),(x2,y2),⋯,(xN,yN)},由于噪音,样本x的真实类别为yD(在训练集中的类别为y),则噪声为
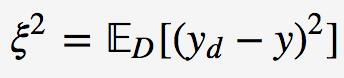
学习算法的期望预测为
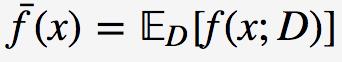
使用样本数相同的不同训练集所产生的方法
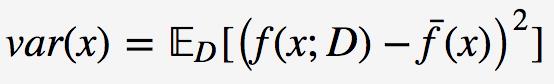
期望输入与真实类别的差别称为bias,则
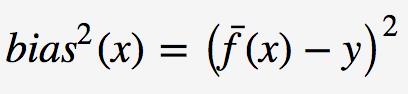
为便于讨论,假定噪声的期望为0,即 以上是关于数据挖掘算法:AdaBoost的主要内容,如果未能解决你的问题,请参考以下文章