数据挖掘竞赛的套路就在这里了,看完本文全明白!
Posted AI开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘竞赛的套路就在这里了,看完本文全明白!相关的知识,希望对你有一定的参考价值。
欢迎大家参与在留言区交流
AI 研习社两大福利就在文末!
不可错过~
AI 研习社按:本文作者兔子老大,原载于知乎专栏——MLの玄学姿势,AI 研习社经授权发布。
前言
刚好在暑假通过参加 Kaggle 的 Zillow Prize 比赛来让我在数据挖掘和机器学习中完成了菜逼到 Level 1 的转变,借这个平台总结一下比赛的经验,先声明本文绝不是只列出名词的文章,每一点背后都会有相应的文字解说,各位客官可以安心吃用和讨论。
其次要强调的是这篇文章不承诺带你上 kaggle top1%,不承诺你看完后就懂数据挖掘,就懂机器学习,这次的总结分享只针对下列有如下问题的人群。
网上其他的攻略文章看得不少,为啥自己还是一波操作猛如虎,一看比分 0-5?
为啥深度学习近年成绩斐然,然而一些问题上了深度学习后,比分却变成了 0-6?
这两个问题会随着介绍整个流程而和大家讨论,所以先来对一般的流程进行总结,流程无非是
数据预处理
特征工程
模型训练与挑选(这里会讨论深度学习可能存在的局限性)
模型融合
接下来我对每一个进行讨论。
数据预处理
这一点我不谈具体的技术,因为这些技术名词时老生常谈,什么归一化,标准化恐怕数据挖掘的第一课就是谈这些东东,这里只讨论两个问题,你知道什么时候该用什么技术手段进行预处理吗?你知道预处理的目标是什么吗?
按我自己的理解,数据本身决定了模型表现的上限,而模型和算法只是逼近这个上限,这和大部分数据挖掘教材中的 RIRO 原则是对应的,因此,对数据的预处理(和特征工程),要干的就是提高模型可逼近的上限,已经提高模型鲁棒性
明白这两个目标,在预处理阶段你需要干什么就很容易反推出来了。
怎么提高模型可逼近上限?
提特征
特定领域还需要滤波和去噪
把干扰模型拟合的离群点扔掉
怎么提高模型的鲁棒性?
数值型数据中的缺失值可以花式处理,默认值,平均值,中位值,线性插值
文本数据可以在字,词,句等粒度不同进行处理
图像数据进模型之前把图像进行 90,180,270 等不同角度翻转也是常见的处理方式了
总的来说,在这里就是需要在不同方面的进行数据的描述,将一份原始数据稍作扩展。
特征工程
特征工程应包括两部分特征抽取和特征挑选,特征挑选的资料网上一搜一大堆,因此这里只讨论特征抽取,为什么?因为巧妇难为无米之炊啊,没有特征你挑选个宝宝吗?
第一个方法叫做按业务常识抽取。
简单点来说,就是通过对你需要分类 / 预测等领域的先验知识来进行抽取,比方说,要区分男生和女生,直接使用性特征肯定要比其他的身高体重这些数据的准确率要高。当然,考虑到每一个人都不可能所有知识都精通,当面对一个陌生的业务领域时,建议优先提取 X1/X2 这样形式的特征(这里的 X1,X2 不一定是一个变量,也可能使一个式子),因为传统的统计流派特别喜欢通过 X1/X2 组成一个叫做 *** 率这样的指标,有时可能有奇效。
第二个方法叫做抽取非线性特征。
线性模型具有简单,快速等优势,但它的劣势也很明显,他只能表达线性关系,而一般现实问题那有这么简单的线性关系。因此,解决方案就是线性模型使用非线性特征。
可能有些同学有有点懵逼,什么叫线性模型搭配非线性特征?看完这个下面这个例子就清楚了:
假设一个回归预测的问题,求的 y=f(x),那么有如下两种形式的表达
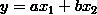 …… (1)
…… (1)
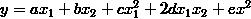 ……(2)
……(2)
(1) 式是线性回归,只能表达线性关系,(2) 式是多项式回归,能够表达非线性关系。这时我们令:
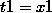
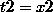
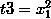
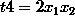
这时再回首去看 (2) 式,就能得到
…… (5)
有些童鞋应该反应过来了,是的,所谓的线性模型使用非线性特征的原理就是将非线性特征记作新的变量 t,然后扔进一个线性模型里面,这时得到的就是关于 t 的线性模型,但却可以表达 x 的非线性关系。
至于提取非线性特征,除了人工提取这种多项式来做特征外,也可用深度学习,SVM 等非线性模型的中间输出来作为非线性特征。这些非线性模型的方法,也大概是把低维度投影到高维度后塞进线性模型,至于说为什么要用非线性模型提取,一是因为省人力,二是因为模型往往能学习到人类常识上意识不到的特征的,至于为什么不适用非线性模型直接进去端对端的工作方式,则是因为每一个非线性模型提取非线性特征的方法都不一样,那么提取出来的非线性特征自然也就不一样了。
但要注意一点的是,是否使用模型来提取非线性特征这个决定要考虑实际情况,因为多个模型的非线性特征组合后,或者是模型融合技术,计算量或时延是不可接受的,有些方法连工程实践上都不一定可取(即使有分布式计算的环境),就更不要说打 kaggle 的大部分都是个人用户,只有台式机或笔记本。
模型训练和选择
合理的划分数据集和训练集,平衡样本,交叉验证这些东西是老生常谈,网上一找一大堆,所以本文继续不谈。
先说说的是模型的选择,机器学习经常被称为玄学,刚开始我以为说的是因为调包侠本根本不知道里面算法的原理,所以这样造成,但后来我发现,即使你知道里面的算法的原理,也依然是玄学。
为什么这么说,我们对比一下其他的一些类型的程序出错是怎么解决的?print 大法?二分排查找 bug?无论是何种方法,只要 bug 可重新,你总是可以通过程序的表现而定位到错误,但机器学习不行,除了模型是否过拟合可以通过一些指标看出,然后调整对应得参数外,其他的一些问题,压根无法通过现象而定位到需要修改的错误。
比如说,预测效果不好,我知道肯定是需要增加特征,但需要增加一个哪些方面的特征?这个特征是需要引入新的数据维度,还可以从现有的数据提取出来?或者说当前的数据的价值已经被我榨干了吗?又或者说,你通过算特征与预测值的相关系数,相关系数低的特征就一定没用了吗?显然不是,因为你现在只是算了单变量的,没有算排列组合的结果,而至于算排列组合的结果,真的能算吗?…… 诸如此类的是没有 100% 准确的指导方案的(可能连 90% 准确的指导方案都没)。
当然,解决方法还是有的,就是不断的堆特征,和堆模型,挑选后来一波融合,指望不同的模型能学到不同的方面,然后互相互补。
落实到行动,就是那句老话,大胆假设,小心求证。
说了这么多,无非说明机器学习模型可能是理论科学,但实践,一定是实验性科学,既然是实现性科学,就要遵守一个原则,先简单后复杂,过早优化是万恶之源,无脑优化则是浪费时间。简单是指模型的简单,数值类型可以先从简单的线性回归开始,(若是图片领域的话,可以选取一些比较基本的 DL 模型,比如预训练好的 vgg 系列),这样出结果的速度肯定优于其他乱七八糟的复杂模型,出结果快,意味着你可以趁早在线下确定较为妥当的测试方式,你的 baseline,快速验证你的其他思路,然后再慢慢优化和调参。
在这个小节最后,来说说这次比赛中关于使用深度学习的感想。
目前公认不适合使用深度学习的情况是当数据量偏少,但一般现在比赛方提供的数据量都非常可观,所以数据量这个条件应该说是可以满足的。
其次的一个公认不适合的地方是,数据不具有局部相关特性。意思就是像图像 / 自然语言等领域,数据之间具有局部相关性,比如说一个像素不能表达足够的信息,但一堆像素就能表示这是小狗还是小猫,语言中由单词组成句子,而一旦这些东西组合的次序被打乱,那么整体所表达的信息亦同时被打乱。这些具有局部相关特性的数据,可以通过一定的网络拓扑提取其中的局部相关特性,同时配合深度达到层次特征的提取,从而达到较为优秀的成果。对比三层 MLP 以及 CNN 在 minst 手写数字识别上的效果差异,就能充分说明这个观点。而对于不具有局部相关特性的数据,没法用特点的网络拓扑来捕捉了他的信息,在深度学习中就只能用 MLP 来完成模型的训练,而 MLP 的效果,一般要弱于 GDBT,RandomForest 等传统模型。
深度学习对比传统方法来说,最大的优势是自动特征的提取,但根据其他大牛分享的经验来说,当人工特征工程做到一定程度后,传统模型是可以超越深度学习的,详见 quora 相似文本匹配的比赛里面,yesofcourse 队伍的视频,里面有一段是关于深度学习和传统机器学习模型的对比,另外亦有有人指出深度学习在面对 x 和 y 的关系是一次推理的情况时,深度学习能学到很好,如果是两层或多层的推理的时候,相比传统模型,深度学习却完全处于劣势,但深度学习结合知识图谱可以有效的解决这个问题。
(个人猜想,这里大牛说到的推理应该是指在逻辑上的关系,比如你爸爸的妈妈的二叔的老婆的姐姐你应该称呼她什么这种推理,而并非数学上 y=f(x) 这种关系)
而在这次比赛中的实际情况则比较有趣。在对数据集进行了基本处理后 (对缺失值填充,去除离群点),没有做任何的特征提取,分别塞进 xgboost 和 3 层 128 单元的 MLP,其中 LB 和线下的表现,两个模型的结果非常接近,差别基本上是小数点后 6 到 7 位。但是后来我人工提取了几个特征,这时两个模型的差异就开始显露出来了。线下差别不大,但 LB 上,xgboost 让我的排名又十分可观的上升,但 MLP 则让我的 LB 得分有了十分可观的…… 下降!起初觉得是产生了过拟合,后来分别加入了 dropout 和正则项尝试,并没有改善,也尝试了使用 autoencoder 进行特征提取,然后应用到传统模型上,效果都不尽人意,最后我决定不使用 DL 那套方法,改而采用传统的机器学习模型 + 人工抽取特征。但在决定放弃 DL 之前,已经浪费了太多的时间在尝试上(因为对 DL 有盲目的信心,总觉得成绩不好是自己的参数问题),没有银弹,具体情况具体分析,这也是以后处事应该要注意的地方。
其实通过分析我发现 DL 产生较为严重的误差原因大概是,lable 其实正负数对半,但模型的输出几乎都是正,即使是负数,该预测值的数值也非常少,并没有找到合适的解决方法。
但无论是 xgboost 还是线性回归,其预测值都可以做到正负各占 50%,因此,目前的方案是对这两个模型最后的结果取了加权平均,目前(2017.7.22)排名到达 342/1702,按照套路,接下来应该有一波模型融合,我是有自信再上升一定的名次的,但因为我还有参加今年的考研,另外这次比赛经历我觉得已经有足够的长进,别没有继续下去的打算,即使是继续也考研后的事了。
模型融合
关于模型融合,方法依旧在网上有一大堆,近几年也没有太大的创新,主要说一下的就是模型融合前画一画误差曲线,确定模型之间是否有融合的需要,比如一个模型完爆另外一个模型,那融合价值就很低。
后话
读万卷书不如行万里路;行万里路不如阅人无数;阅人无数不如高人指路。参与到面向全社会的比赛,其实比参加学校某些我不想提名字的比赛更有意义,虽然拿奖很难,但因为能接触到的是近似真实的流程,不同水平,不同行业背景的人,尤其是认识一个的朋友后会以认识更多牛逼的朋友,这些机会对一个人的知识技能和人脉积累都有巨大的好处,如果你还处于学生时代,这个机会的潜在价值会翻倍。
最后,因为这个比赛还在进行中,所以代码我不会给,但你真想要当伸手党,去 kaggle 的 kernels 上有很多排名比我高的放在了上面,如果只是问题探讨,欢迎在评论区或私信留言,文字应该足够了。
最后的最后,因为我不知道国内除了 top 的一些学校外,其余学校关于机器学习或深度学习方向的研究水平怎么样 (子方向不太在意),广东地区的考生,欢迎热心的知友推荐学校和实验室,在这里先谢谢了,我保证看在推荐的份上不吃你。:P
新人福利
以上是关于数据挖掘竞赛的套路就在这里了,看完本文全明白!的主要内容,如果未能解决你的问题,请参考以下文章