数据挖掘实战:Kaggle竞赛经典案例剖析
Posted Python中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘实战:Kaggle竞赛经典案例剖析相关的知识,希望对你有一定的参考价值。
專 欄
Load Lib
在这边提一下为什么要加
import warnings
warnings.filterwarnings('ignore')
主要就是为了美观,如果不加的话,warning一堆堆的,不甚整洁。
Load data

和正常的套路一样,Id的没有什么卵用但是每个数据集都喜欢加的东西,因此我们弄死它就好了。

Data Statistics
Data Statistics是不能省略的部分,这部分能够首先让你对Data Science有个很基础的认知,也就是play with your data之前的know your data的部分。
在这里说一下,我在之前很简单粗暴的一上来就
dataset=df.iloc[:,1:]
把Id给删掉了,是不对的。正常的套路要先进行Data Statistics之后,才能进行对数据集的操作,否则误删了有价值的数据。。。就不大好了。。。
先看看数据集里有什么东西?
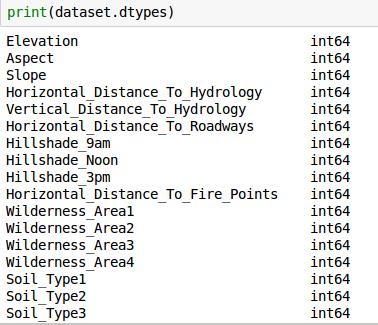
大家发现这个数据集很有趣的地方就是,他的数据类型全部都是int64的,这样Data cleaning的时候压力会小一点。
Data Cleaning
首先,我们来搞定一些没用的项目
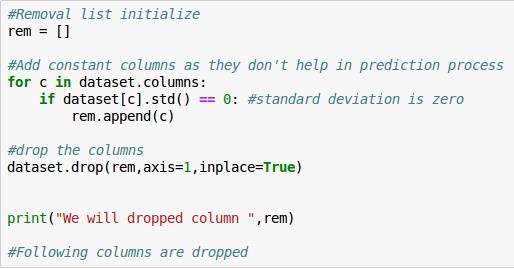
We will dropped column ['Soil_Type7', 'Soil_Type15']
Nice,现在再来看一下:
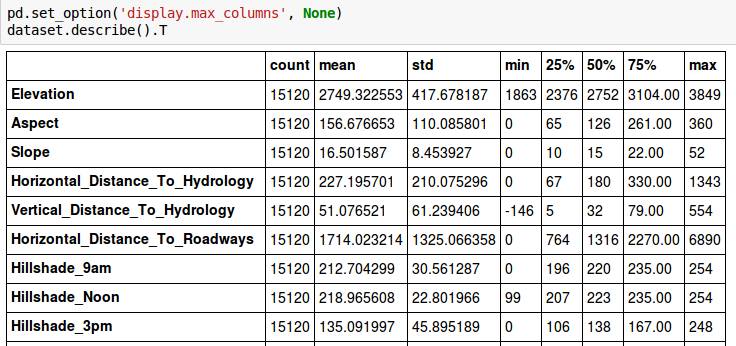
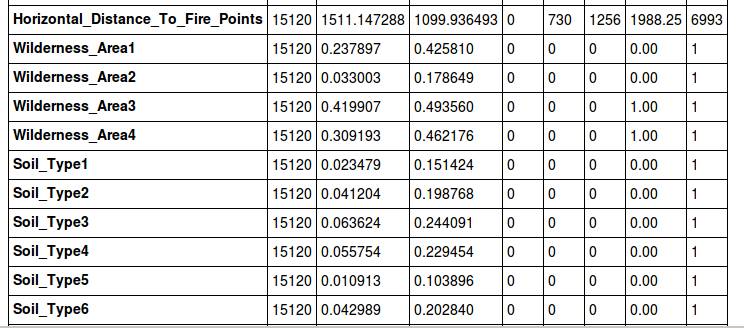
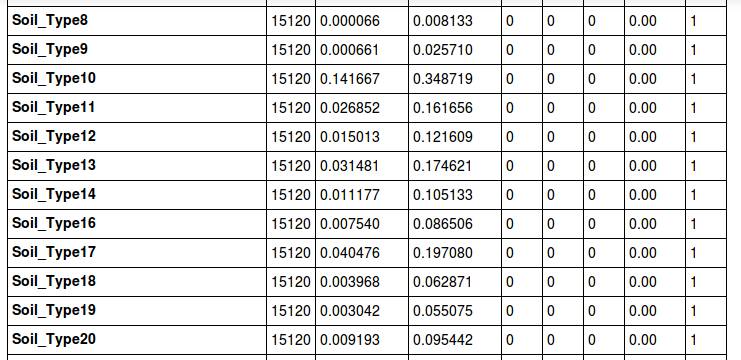
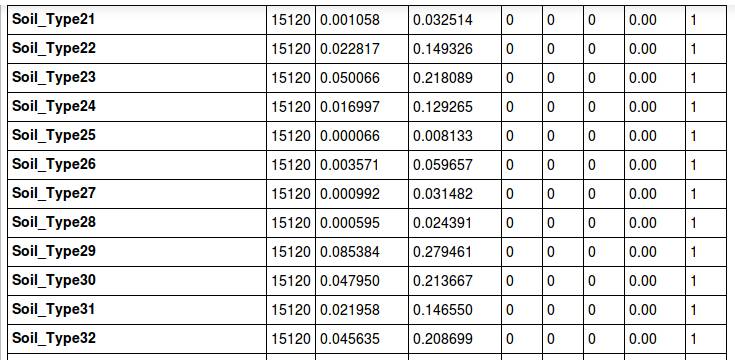
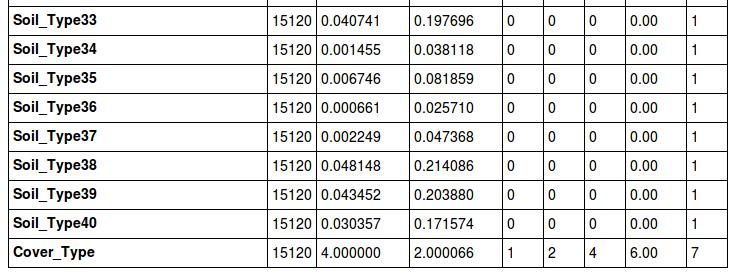
我们现在来看一下偏离量:
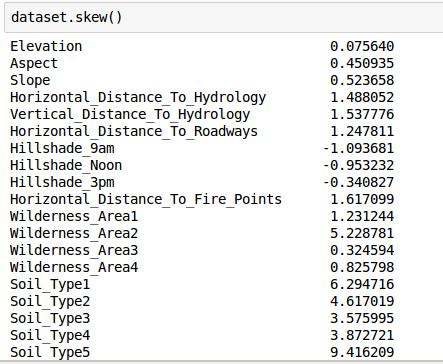
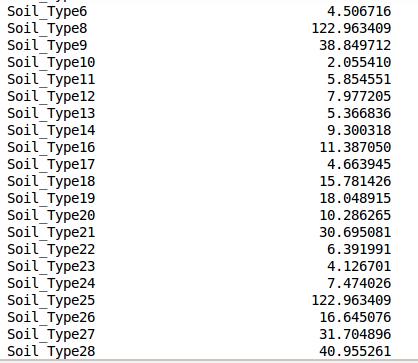

这里要提一下,我之前如果没有执行删除'Soil_Type7', 'Soil_Type15'的内容的话,他们的偏离量为0,同样的,大家也可以通过这个方法来剃掉Soil_Type这个废柴。(本来就是用std剃掉的来着。。。)
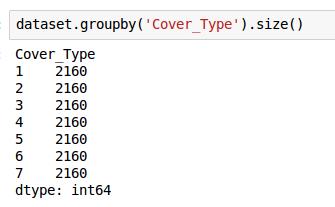
为什么选Kaggle的数据集的原因又出现了,所有的Class都已经equal presence了,这就意味着不需要有一个re-balancing的过程了。
怎么说也是文化人,之前给大家的都不算什么有技术含量的,现在来个好玩的,也是Data Science的核心:Correlationship
首先要提一下,不是随便的啥啥啥数据都可以搞Correlationship的,至少要有continous才可以。
在Data Statistics的过程中,我们对数据有一个基本的认识了,因此,Wilderness_Area和Soil_Type我们不能用,谁教他是不是0就是1呢(一般我们叫它们binary)。
先做个准备
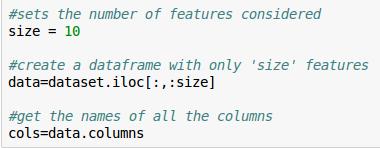
来正戏了,Pandas为什么那么多人用的原因之一就是,它将很多的东西都给工具化了,如果要手码的话。。。简直不寒而栗。。。
但是Pandas只要一句:
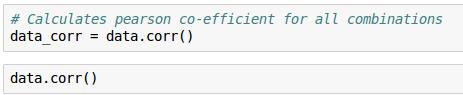
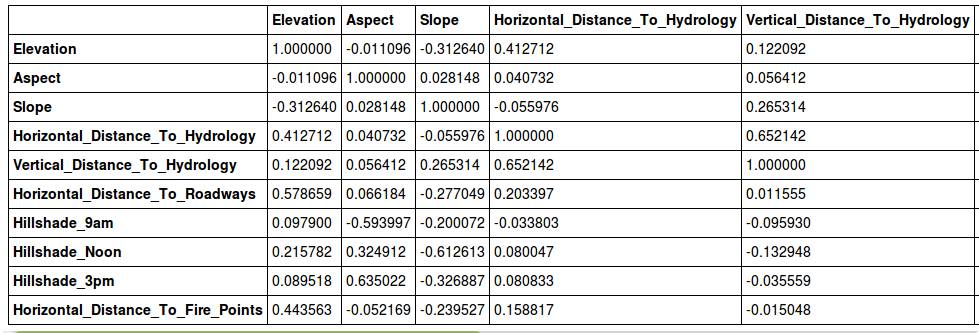
看着很烦对不对?是的,很多没有什么必要的信息也一股脑子的弄了出来。
所以我们设置一个threshold,threshold可以理解为阈值,低于threshold就屏蔽掉好了。一般0.5以上才能说有相关性,0.8以上高度相关。有兴趣的同学可以看下Reference的Wikipedia中Correlation的解释。
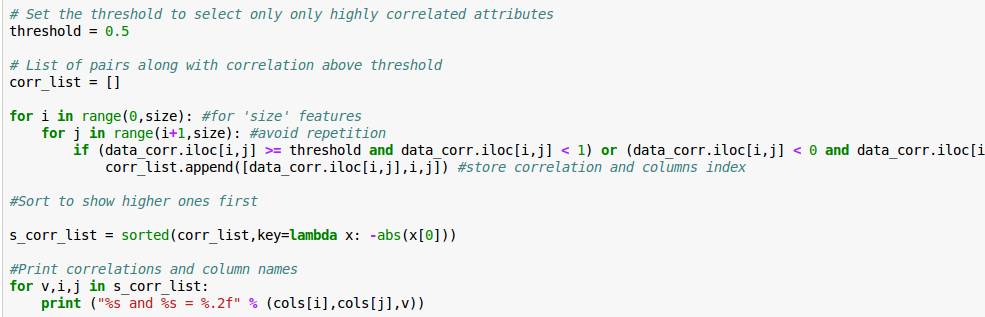

这样,我们得到七个比较有关联的数据。但是还是有人觉得,还是不大像人话。还有人说我没图你说个啥?这里我导入一下seaborn,无他,只是因为我觉得Matplotlib的默认视图做这个。。。是真的很难看啊。。。
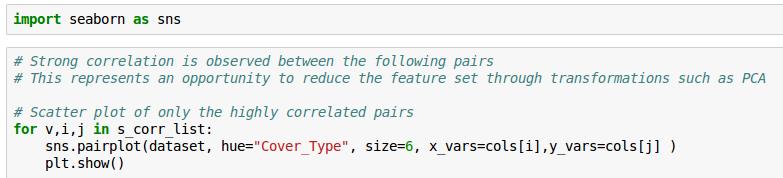
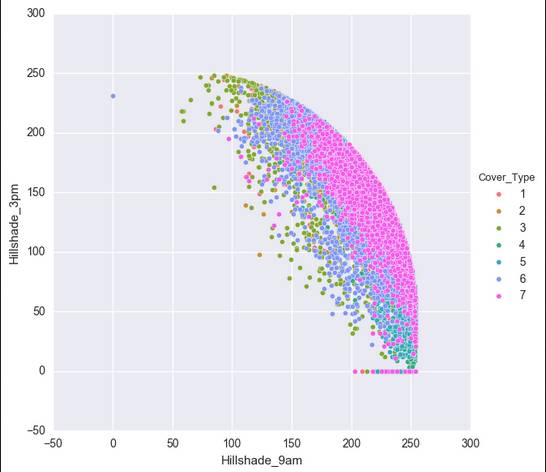
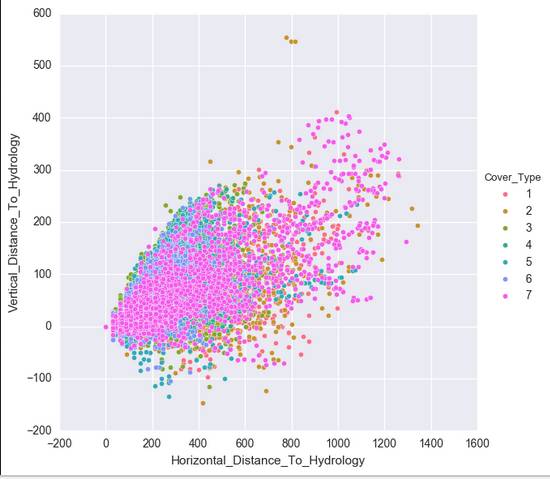
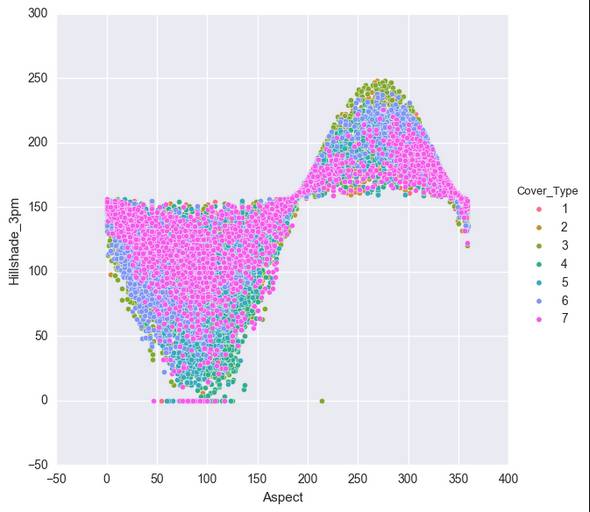
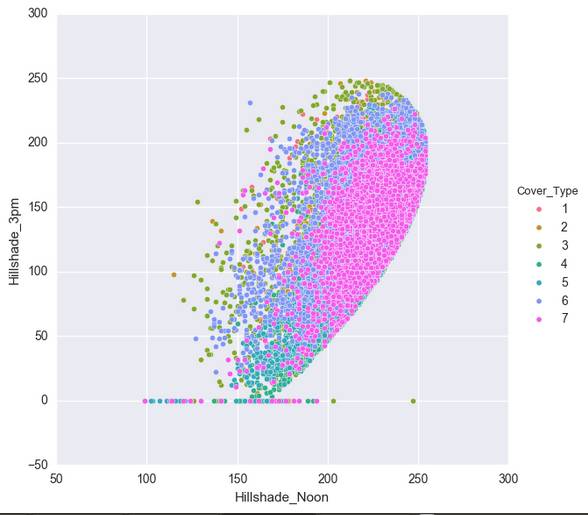
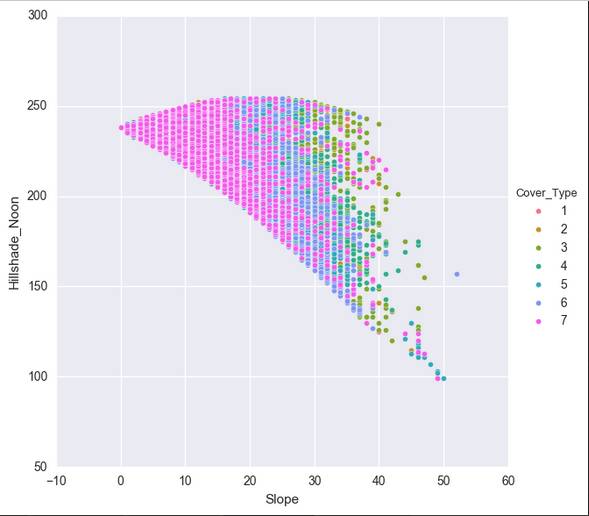
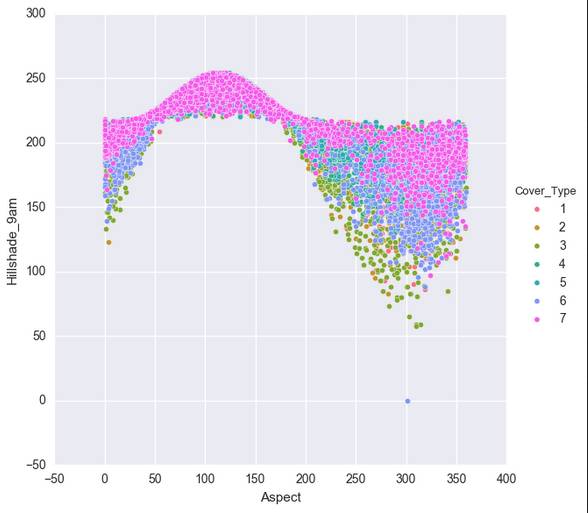
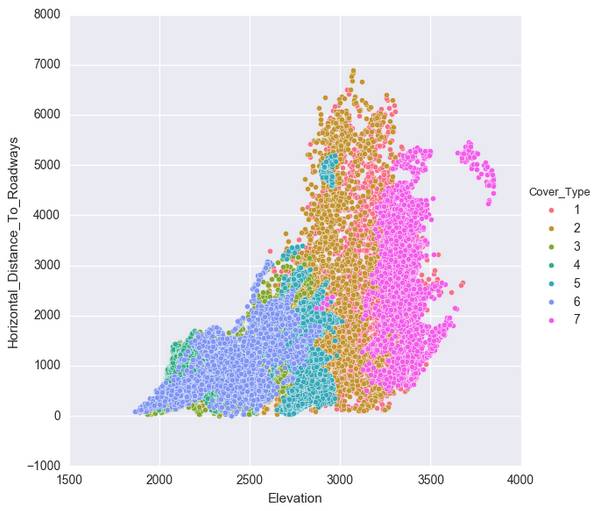
在这里,我们移除了Soil_Type7和Soil_Type15,因为这两项的全是没变。
这里提一下,通过调试
dataset.std()
可以很简单直接的把值压根就没变化的废物给找出来,这个方法很常用。
由于Kaggle的数据集内容本身没有什么需要清理的需求,所以Data Cleaning做到这一步就差不多了。
在这里提一下,通过list将操作保存起来这个习惯很重要——要不然说翻车就翻车了,然后死活都找不到之前做了什么。。。
严谨的数据科学家是不会放过它滴。

致力于成为
国内最好的Python社区
专栏作者申请邮箱
pythonpost@163.com
点击阅读原文申请PyLive主讲人
以上是关于数据挖掘实战:Kaggle竞赛经典案例剖析的主要内容,如果未能解决你的问题,请参考以下文章