数据挖掘算法:KNN
Posted 算法爱好者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘算法:KNN相关的知识,希望对你有一定的参考价值。
(点击上方公众号,可快速关注)
http://www.cnblogs.com/en-heng/p/5000628.html
1. 引言
本文讨论的kNN算法是监督学习中分类方法的一种。所谓监督学习与非监督学习,是指训练数据是否有标注类别,若有则为监督学习,若否则为非监督学习。
监督学习是根据输入数据(训练数据)学习一个模型,能对后来的输入做预测。在监督学习中,输入变量与输出变量可以是连续的,也可以是离散的。
若输入变量与输出变量均为连续变量,则称为回归;输出变量为有限个离散变量,则称为分类;输入变量与输出变量均为变量序列,则称为标注。
2. kNN算法
kNN算法的核心思想非常简单:在训练集中选取离输入的数据点最近的k个邻居,根据这个k个邻居中出现次数最多的类别(最大表决规则),作为该数据点的类别。
算法描述
训练集T={(x1,y1),(x2,y2),⋯,(xN,yN)},其类别yi∈{c1,c2,⋯,cK},训练集中样本点数为N,类别数为K。输入待预测数据x,则预测类别
其中,涵盖x的k邻域记作Nk(x),当yi=cj时指示函数I=1,否则I=0。
分类决策规则
kNN学习模型:输入X,通过学习得到决策函数:输出类别Y=f(X)。假设分类损失函数为0-1损失函数,即分类正确时损失函数值为0,分类错误时则为1。
假如给x预测类别为cj,即f(X)=cj;同时由式子(1)可知k邻域的样本点对学习模型的贡献度是均等的,则kNN学习模型误分类率为
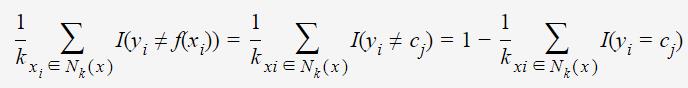
若要最小化误分类率,则应
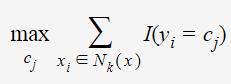
所以,最大表决规则等价于经验风险最小化。
存在问题
k值得选取对kNN学习模型有着很大的影响。若k值过小,预测结果会对噪音样本点显得异常敏感。特别地,当k等于1时,kNN退化成最近邻算法,没有了显式的学习过程。
若k值过大,会有较大的邻域训练样本进行预测,可以减小噪音样本点的减少;但是距离较远的训练样本点对预测结果会有贡献,以至于造成预测结果错误。下图给出k值的选取对于预测结果的影响:
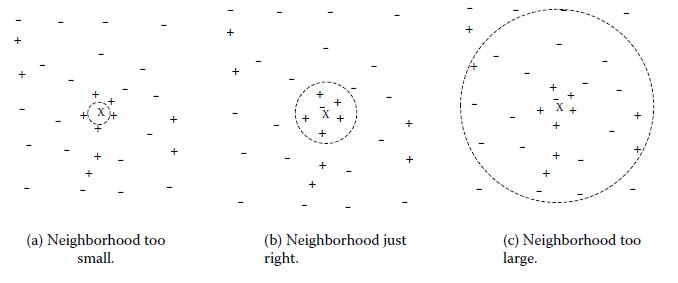
前面提到过,k邻域的样本点对预测结果的贡献度是相等的;但距离更近的样本点应有更大的相似度,其贡献度应比距离更远的样本点大。可以加上权值wi=1/∥xi−x∥进行修正,则最大表决原则变成:
3. 参考资料
[1] Michael Steinbach and Pang-Ning Tan, The Top Ten Algorithms in Data Mining
[2] 李航,《统计学习方法》
数据挖掘算法系列:
觉得本文有帮助?请分享给更多人
关注「算法爱好者」,修炼编程内功
以上是关于数据挖掘算法:KNN的主要内容,如果未能解决你的问题,请参考以下文章