灰常数据挖掘 | 数据理解和预处理
Posted SOTON数据分析
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了灰常数据挖掘 | 数据理解和预处理相关的知识,希望对你有一定的参考价值。
大家好,我是灰灰。上次和大家聊了聊对数据挖掘的理解以及数据挖掘工作的基本框架(),从这次开始,咱们脚踏实地,具体说一说如何一步步进行数据挖掘工作,这次我们的主题是“数据理解与预处理”。

小编遇到过很多人(咳咳,请不要对号入座),拿到数据后不管三七二十一,先丢到模型中去跑,管它具体什么样呢,反正“大数据”嘛,总能整出点东西来。但就像上次说过的,“大数据”很有可能带来“大错误”!所以在数据挖掘工作开始前,认真的理解数据、检查数据,对数据进行预处理是至关重要的。
很多人说,数据准备工作真是个“体力活”,耗时耗力不说,还异常的枯燥无味。这点小编承认,建模之前的数据处理确实是平淡的,它往往不需要多高的智商,多牛的编程技巧,多么高大上的统计模型。但是,它却能时时触发你的兴奋点,因为它需要足够的耐心和细心,稍不留神就前功尽弃。
在这次的内容里,小编首先会从“数据理解”、“变量类型”和“质量检查”三个方面进行阐述,然后会以一个自己做过的实际数据为例进行展示。

拿到数据后要做的第一步就是理解数据。什么是理解数据呢?不是简单看下有多少Excel表,有多少行,多少列,而是要结合自己的分析目标,带着具体的业务需求去看。
首先,我们需要明确数据记录的详细程度,比方说某个网站的访问量数据是以每小时为单位还是每天为单位;一份销售数据记录的是每家门店的销售额还是每个地区的总销售额。
其次,我们需要确定研究群体。研究群体的确定一定和业务目标是密切相关的。比方说,如果我们想研究用户对产品的满意度与哪些因素有关,就应该把购买该产品的所有客户作为研究群体;如果我们想研究用户的购买行为受哪些因素影响,就应该同时考察购买人群和非购买人群,在两类人群的对比中寻找关键因素。
研究群体的确定有时也和数据的详细程度有关。比如我们想研究“观众影评”对“电影票房”的影响,我们既可以把“每部电影”看成一个个体,研究“影评总数”对“电影总票房”的影响,也可以把“每部电影每天的票房”看成一个个体,研究“每天的影评数”对“每天的电影票房”的影响。具体选择哪一种取决于我们手上有什么样的数据,如果只有总票房和总影评数的数据,那我们只能选择第一种;如果有更详细的数据,那就可以考虑第二种方案。
需要注意的是,这两种方案还会影响我们对于模型的选择。例如,如果研究“每天的影评数”对“每天电影票房”的影响,那每部电影又被细分为很多天,同一部电影不同时间的票房会有较高的相似性,这就形成了一种层次结构,可以考虑使用层次模型(hierarchical model)进行分析。
最后,当我们确定了研究目标和研究群体后,我们需要逐一理解每个变量的含义。有些变量和业务目标明显无关,可以直接从研究中剔除。有些变量虽然有意义,但是在全部样本上取值都一样,这样的变量就是冗余变量,也需要从研究中剔除。还有一些变量具有重复的含义,如“省份名称”和“省份简称”,这时只需要保留一个就可以了。

所有变量按其测量尺度可以分成两大类,一类是“分类变量”,一类是“数值变量”。不同类型的变量在处理方法和后期的模型选择上会有显著差别。
【分类变量】
分类变量又称属性变量或离散变量,它的取值往往用有限的几个类别名称就可以表示了,例如“性别”,“教育程度”,“收入水平”,“星期几”等。细分的话,分类变量又可分为两类,一类是“名义变量”,即各个类别间没有顺序和程度的差别,就像“手机系统”中ios和安卓并没有明显的好坏差别,“电影类型”中“动作片”和“科幻片”也都是一样的,说不上哪个更好或更差。另外一类是定序变量,即不同类别之间存在有意义的排序,如“空气污染程度”可以用“差、良、优”来表示、“教育程度”可以用“小学、初中、高中、大学”来表示。
当研究的因变量是分类变量时,往往对应特定的分析方法,我们在后面的章节会陆续讲到,这里暂且不谈。当研究中的自变量是分类变量时,也会限制模型选择的范围。有些数据挖掘模型可以直接处理分类自变量,如决策树模型;但很多数据挖掘模型不能直接处理分类自变量,如线性回归、神经网络等,因此需要将分类变量转换成数值变量。
对于定序自变量,最常用的转换方法就是按照类别程度将其直接转换成数值自变量,例如将空气污染程度 “差、良、优”转换为“1,2,3”。
对于名义自变量,最常用的转换方法就是构造0-1型哑变量。例如,对于“性别”,可以定义“1=男,0=女”。当某个名义变量有K个类别取值时,则需要构造K-1个哑变量。例如教育程度“小学,初中,高中,大学及以上”,可以构造三个哑变量分别为:x1:1=小学,0=其它;x2:1=初中,0=其它;x3:1=高中,0=其它。当x1,x2,x3三个哑变量取值都为0时,则对应着“大学及以上”。
需要注意的是,有时候名义变量的取值太多,会生成太多的哑变量,这很容易造成模型的过度拟合。这时可以考虑只把观测比较多的几个类别单独拿出来,而把剩下所有的类别都归为“其它”。例如,中国一共包含56个民族,如果每个民族都生成一个哑变量就会有55个,这时我们可以只考虑设置“是否为汉族”这一个0-1哑变量。
【数值变量】
我们再来看看数值变量。数值变量就是用数值描述,并且可以直接进行代数运算的变量,如“销售收入”、“固定资本”、“评论总数”、“访问量”、“学生成绩”等等都是数值变量。
需要注意的是,用数值表示的变量不一定就是数值型变量,只有在代数运算下有意义的变量才是数值型变量。例如财务报表的年份,上市时间等,虽然也是用数值表示的,但我们通常不将它们按照数值型变量来处理。
上面我们讲到,分类变量通常要转换成数值型变量,其实有些时候,数值型变量也需要转换成分类变量,这就用到了“数据分箱”的方法。为什么要进行数据分箱呢?通常有以下几个原因:
1. 数据的测量可能存在一定误差,没有那么准确,因此按照取值范围转换成不同类别是一个有效的平滑方法;
2.有些算法,如决策树模型,虽然可以处理数值型变量,但是当该变量有大量不重复的取值时,使用大于、小于、等于这些运算符时会考虑很多的情况,因此效率会很低,数据分箱的方法能很好的提高算法效率;
3.有些模型算法只能处理分类型自变量(如关联规则),因此也需要将数值变量进行分箱处理。
数据分箱后,可以使用每个分箱内的均值、中位数、临界值等作为这个类别的代表值,也可以直接将不同取值范围定义成不同的类别,如:将污染程度划分后定义为“低、中、高”等。
那如何进行数据分箱呢?常用的数据分箱的方法有:等宽分箱(将变量的取值范围划分成等宽的几个区间)、等频分箱(按照变量取值的分位数进行划分)、基于k均值聚类的分箱(将所有数据进行k均值聚类,所得的不同类别即为不同的分箱),还有一些有监督分箱方法,如:使分箱后的结果达到最小熵或最小描述长度等。这里不详细介绍了,有兴趣的童鞋可以自行百度。

对数据中的各个变量有了初步了解后,我们还需要对数据进行严格的质量检查,如果数据质量不过关,还需要进行数据的清洗或修补工作。一般来说,质量检查包括检查每个变量的缺失程度以及取值范围的合理性。
【缺失检查】
原始数据中经常会存在各种各样的缺失现象。有些指标的缺失是合理的,例如顾客只有使用过某个产品才能对这个产品的满意度进行评价,一笔贷款的抵押物中只有存在房地产,才会记录相应的房地产的价值情况等。像这种允许缺失的变量是最难搞的,因为我们很难判断它的缺失是合理的,还是由于漏报造成的。
但无论哪种情况,如果变量的缺失率过高,都会影响数据的整体质量,因为数据所反映的信息实在太少,很难从中挖掘到有用的东西。
对于不允许缺失的变量来说,如果存在缺失情况,就必须进行相应的处理。如果一个变量的缺失程度非常大,比方说达到了70%,那就考虑直接踢掉吧,估计没救了。如果缺失比例还可以接受的话,可以尝试用缺失值插补的方法进行补救。
插补的目的是使插补值能最大可能的接近其真实的取值,所以如果可以从其他途径得到变量的真实值,那一定优先选择这种方法。比如某个公司的财务信息中缺失了“最终控制人类型”和“是否国家控股”这两个取值,这些可以通过网上的公开信息得到真实值;再比如缺失了“净利润率”这个指标的取值,但是却有“净利润”和“总收入”的取值,那就可以通过变量间的关系得到相应的缺失值,即净利润率=净利润/总收入。
当然,更多的时候,我们无法得到缺失值的真实信息,这时就只能借用已有的数据来进行插补了。对数值变量来说,可以用已观测值的均值、中位数来插补缺失值;对分类型变量来说,可以用已观测数据中出现比例最高的类别取值来进行插补。这些方法操作起来非常简单,但它们都是对所有缺失值赋予了相同的取值,所以当缺失比例较大时,可能会扭曲被插补变量与其余变量的关系。
更复杂一点的,我们可以选择模型插补方法,即针对被插补变量和其它自变量之间的关系建立统计模型(如回归、决策树等),将模型预测值作为插补值。
如何处理缺失值是一个很大的研究课题,我们这里只是介绍了最简单可行的方法,有兴趣的读者可以参阅Little和Rubin 2002年的专著“Statistical Analysis with Missing Data”。
【变量取值合理性检查】
除了缺失外,我们还要考察每个变量的取值合理性。每个变量都会有自己的取值范围,比如“用户访问量”、“下载次数”一定是非负的,“投资收益率”一定在0~1之间。通过判断变量的取值是否超出它应有的取值范围,可以简单的对异常值进行甄别。
除了根据变量的取值范围来检查变量质量外,还可以根据变量之间的相互关系进行判断。例如一家公司的“净利润率”不应该大于“总利润率”等。
只有通过了各个方面检测的数据才是一份高质量的数据,才有可能带来有价值的模型结果。

最后,我们给出一个实例分析。在这个例子中,我们的目标是研究电影哪些方面的特征对电影票房有影响。
我们有两方面的数据,一是描述电影特征的数据,二是描述电影票房的数据。由于我们关注的是北美的票房市场,所以描述电影特征的数据可以从IMDB网站得到,它是一个关于演员、电影、电视节目、电视明星和电影制作的在线数据库,里面可以找到每部上映电影的众多信息;电影每天的票房数据可以从美国权威的票房网站Box Office Mojo得到,上面记录了每部电影上映期间内每天的票房数据。
我们将从IMDB得到的数据放到“movieinfor.csv”文件中,将从Box Office Mojo中得到的数据放到“boxoffice.csv”文件中。
这里,我们以2012年北美票房市场最高的前100部电影为例进行讲解。下表给出了这两个数据集中包含的所有变量以及相应的解释。
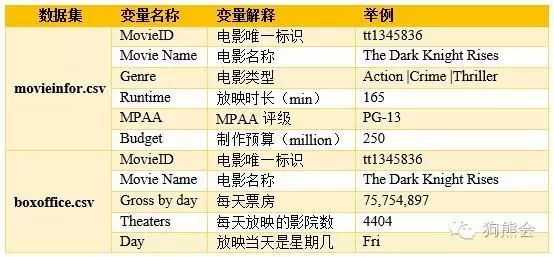
在这两个数据中,movieinfor.csv数据的记录是精确到每部电影的,而boxoffice.csv数据精确到了每部电影中每天的票房数据,是精确到天的。上表中给出的变量中,除了电影名称和ID外,“电影类型”“MPAA评级”(美国电影协会对电影的评级)和“星期几”是分类型变量;“放映时长”、“制作预算”、“电影每天的票房”和“每天放映的影院数”是数值型变量。两份数据都不存在缺失值。
我们首先对两个数据集分别进行变量预处理,然后再根据电影ID将两个数据整合到一起。下面给出了每个变量的处理方法:
【电影类型】
电影类型是一个分类变量。在这个变量中我们发现每部电影都不止一个类型,例如“The Dark Knight Rises”这部电影就有“Action”、“Crime”和“Thriller”三个类型,并且它们以“|”为分隔符写在了一起。同时,不同电影之间可能有相同的类型,也可能有不同的类型,例如票房排名第二的电影“Skyfall”,它的类型是“Action |Adventure |Thriller”。因此,我们首先需要做的是把每部电影所属的类型逐一取出来,然后将所有出现过的类型分别形成一个0-1哑变量,如果这部电影在某个类型上出现了,则相应变量的取值就是1,否则是0.
通过上面一步,我们知道这个数据集中出现过的所有电影类型一共有11个。那是不是按照之前所讲的,应该把它转换为10个哑变量呢?这里需要注意的是,所有的电影类型之间并不是互斥的(即有了action,就不能有其他的类型),所以我们无需因为共线性的原因去掉其中一个。也就是说,如果把每一个电影类型单独作为一个独立的变量,可以衍生出11个新的0-1变量,这完全没有问题。但11个变量未免有点过多,所以我们根据不同电影类型的频数分布情况,只把出现次数明显较多的类型单独拿出来,最终生成了6个0-1型变量,分别为Adventure,Fantasy,Comedy,Action,Animation,Others。
【MPAA评级】
对于这个分类型变量,我们首先可以看一下数据中它所包含的全部取值,发现一共有“PG”,“PG-13”和“R”三个。和上面的电影类型(Genre)不同,对于一部电影而言,它只能有一个MPAA取值。因此,在MPAA变量中,我们需要选择一个作为基准,将另外两个构造成哑变量。例如,我们以“PG”为基准,构造的两个哑变量分别为PG13和R,如果这两个哑变量的取值同时为0,那就相当于电影的MPAA评级是PG。
【放映当天是星期几】
这个变量同MPAA评级一样,每部电影只能有一个取值。如果它在星期一到星期日上都有取值的话,我们可以衍生出6个0-1型哑变量。因为这里我们更关注周末和非周末对电影票房的影响,而并不关注具体是哪一天,所以我们将其进一步概括成一个变量,即“是否是周末”。
【放映时长和制作预算】
放映时长和制作预算这两个变量都是取值大于0的数值型变量,我们可以分别检查它们的取值是否在合理的范围内,然后直接保留它们的数值信息。同时,对“制作预算”而言,假设我们这里关心的不是制作预算的具体数值,而是“小成本电影”和“大成本电影”的票房差异,那我们就可以将这个数值型变量进行分箱处理,转换为一个0-1型的分类变量,即 “是否为小成本电影”。在决定按照什么标准来划分是否为小成本电影时,我们根据之前文献里的研究结果,将制作预算在100 million以下的电影看成是小成本电影。
上述所有变量的处理过程都可以使用R中最基本的语句(table,rep,which等)完成,由于篇幅限制,小编这里就不列出详细的code了,大家感兴趣的话,可以阅读狗熊会的“R语千寻”系列(),相信会在R语言的学习上受到更多启发。最后,我们将所有新生成的变量按照电影ID整合到一起,就大功告成啦。

最后总结一下,小编在这次内容中向大家介绍了拿到数据后的数据理解和预处理工作,内容虽然不难,但同样需要我们认真对待。就好像生活一样,只有踏踏实实走好前面的路,才有可能迎接后面的高潮迭起!
◆ ◆ ◆ ◆ ◆

 如果您对我们的微店商品感兴趣,
如果您对我们的微店商品感兴趣,
请扫描下方二维码
点击“阅读原文”进入微店!
以上是关于灰常数据挖掘 | 数据理解和预处理的主要内容,如果未能解决你的问题,请参考以下文章
PySpark算子处理空间数据全解析: windows模拟开发环境搭建