音乐推荐系统的数据挖掘,了解一下
Posted 浙大信管学会
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了音乐推荐系统的数据挖掘,了解一下相关的知识,希望对你有一定的参考价值。
2018/03/19
听见 好时光

看到这个标题是不是敲激动!对于喜欢听歌的同学们来说,音乐推荐系统肯定都不陌生,无论你是用网易云、酷狗、QQ音乐还是虾米等等。就拿我自己来说,网易云音乐的每日推荐就是日常的一个小确幸好嘛。今天,小编就带你挖掘一下音乐推荐系统可以怎样来实现个性推荐叭。咳咳,看过上一篇推文的童鞋们一定猜到了,这也是数据挖掘课上做的一个项目,嗯,先感谢郑冰杰同学、唐心怡同学、迪尔果同学的分享,小编是不是很有礼貌~

1 商务理解
推荐系统现在是各大产品常用的一种技术,例如某宝,女孩子们体会是不是超级深哈哈哈哈?不可否认,在信息过载的时代,个性化推荐能够创造更好的用户体验和服务质量,满足用户的个性化需求。
推荐系统有四个基本目标:
• 相关性 - 用户更可能消费他们感兴趣的物品
• 新奇 - 当推荐的项目是用户以前从未见过的东西,推荐系统是有用的
• 偶然性 - 这些建议对于用户来说确实是令人惊讶的
• 推荐多样性 - 当所有这些推荐项目非常相似时,会增加用户可能不喜欢这些项目的风险
音乐推荐系统当然就是推荐系统在音乐产品中的运用啦。我们将以KKBox为例来进行分析(啥?没有听说过,不看了不看了),但其实各个音乐推荐系统都是非常类似滴。
KKBox是2004年由一群台湾软件程序员创建的音乐流媒体服务,它以亚洲市场为目标,专注于台湾、香港、马来西亚、新加坡等地区(所以我也没有用过),该公司目前在其推荐系统中使用基于协同过滤的矩阵分解和词嵌入算法。但KKBox希望创建更高效的音乐推荐系统,为此,公司在Kaggle网站上发布了一场比赛,这场比赛是奖励型的,吸引了1,081支队伍和1,229名参赛者(知道为啥以KKBox为例了吧)。

2 数据理解
项目提供了五个数据集,训练集train.csv、用户相关属性集member.csv、歌曲相关属性集song.csv、歌曲额外信息song_extra_info.csv、测试集test.csv。
每个数据集中包含的属性及其含义如下:
train.csv:msno (用户ID)、song_id (歌曲ID)、source_system_tab (用户获取歌曲的方式)、source_screen_name (用户播放时显示的播放路径)、source_type (用户第一次播放歌曲的获取方式)、target (目标变量,用户一个月内是否重复听取)。
member.csv:msno (用户ID)、city (所处城市)、bd (年龄)、gender (性别)、registered_via (注册方式)、registration_init_time (注册时间)、expiration_date (终止日期)。
song.csv:song_id (歌曲ID)、song_length (歌曲长度(ms))、genre_ids (流派类别)、artist_name (歌手姓名)、composer (作曲家)、lyricist (作词者)、language (语言类别)。
song_extra_info.csv:song_id (歌曲ID)、name (歌曲名称)、isrc (国际标准录音代码ISRC编码,由5个数据段组成)。
test.csv:msno、song_id、source_system_tab、source_screen_name、source_type。
3 数据探索
在开始进行正式的数据处理之前,我们可以先用统计工具统计train集里歌曲被听取的次数以及被重复听取的概率(sum(target=1)/count,也即某歌曲被用户第二次点击的次数/该歌曲在数据集中出现的总次数),并观察不同属性对歌曲听取次数和重复听取概率的影响,进一步决定进行怎样的数据处理,是不是敲机智的!

因为版面有限,在这里只给出两个例子,想查看更多,可戳最后滴“阅读原文”。
歌曲听取次数—被重复听取概率
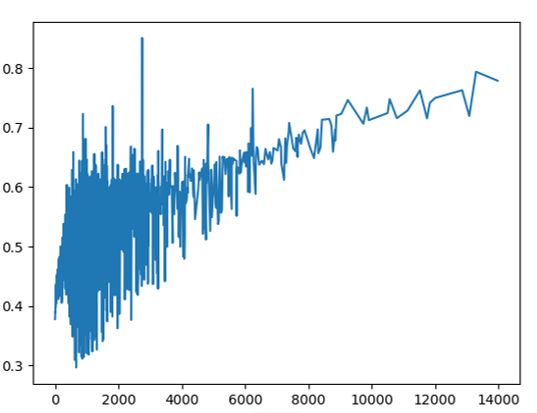
横轴为歌曲听取次数,纵轴为被重复听取概率
两者具有正相关性,歌曲听取次数越多,歌曲被重复听取可能性越大。
也存在这样一种现象,有些歌曲虽然听取次数少,但仍有很高的重复听取概率。
用户注册年份、月份、日期
将连续性变量registration_init_time拆分为其所代表的年、月、日,化为离散型变量,并分别分析特征。以年份为例:
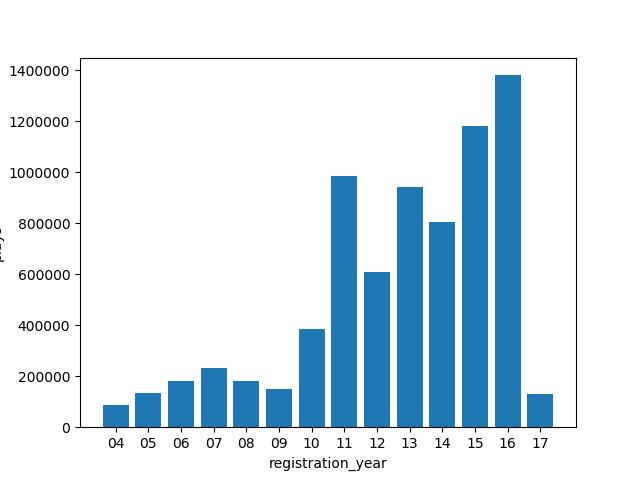
横轴为注册年份,纵轴为歌曲听取次数
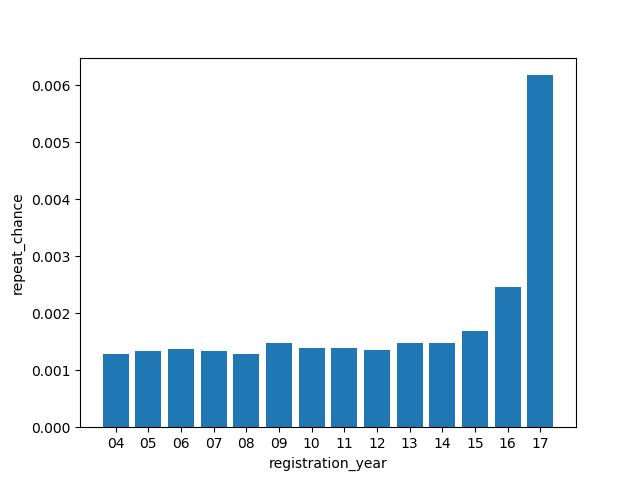
横轴为注册年份,纵轴为被重复听取概率
用户注册年份较晚的听取歌曲数量较多,但对于重复听取歌曲概率并无显著影响,在14~17范围重复听取概率随年份增大,且17年份注册的用户重复听取歌曲的概率较大。
4 数据预处理
处理数据中的噪声
(1)members.csv中的表示年龄的特征bd的范围为[-43,1051],小组认为负值及大于某个较大值 (如大于100) 都是异常的,年龄异常的用户占所有用户的58%。在bd值为[0,100]的范围内,直方图如下:
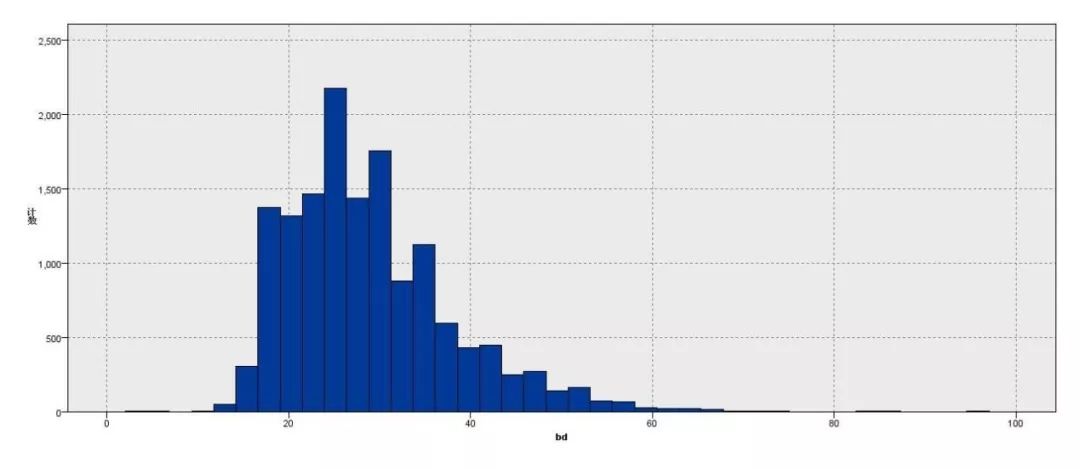
年龄的异常值可能代表了用户的一些较为负面的个人意愿,如不愿意对该软件平台公布个人信息、用户黏性较低、对该软件喜爱程度较低等,因此小组决定使用一个专门的值代表这一类用户。
(2)members.csv中的gender特征也存在57%的空值。基于处理bd同样的考虑,我们也使用一个专门的值代表没有填写性别的用户。
(3)去除罕见数据。噪音数据的存在会导致过拟合,从而造成结果的准确率降低,因此我们决定去掉歌曲名称、用户名称、艺术家、作曲家、作词人出现次数非常少的数据。
数据转换及添加新特征
基于第二部分的数据理解,小组发现有一些特征是非常容易处理的,处理如下:
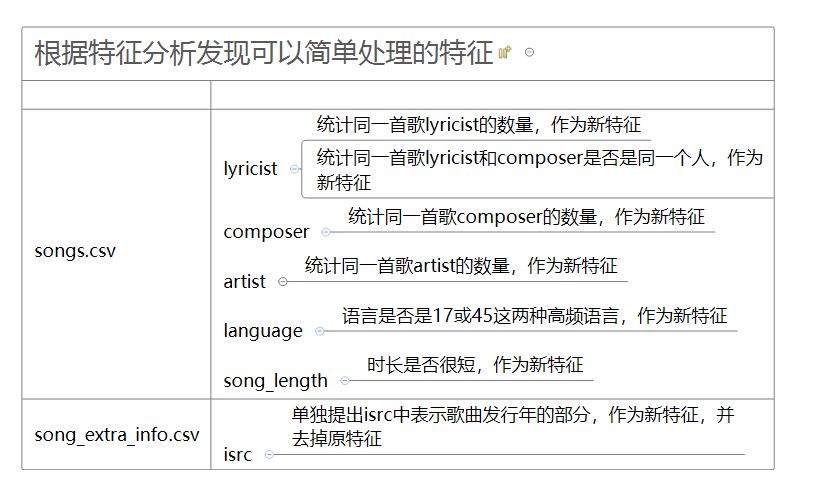
对于members.csv中的registration_init_time和expiration_date,可以将两者相减计算用户的注册时长,并可以将时间分解为单独的年、月、日作为新的特征。
但还有一些特征是显然需要处理但比较棘手的:
songs.csv中的genre_ids表示歌曲的风格,它的值大多是复合的,同一首歌可以具备多种风格,经过统计,一首歌的风格最多有8种,而基本的风格类型有192种。genre_ids之所以需要处理,是因为原表示方法无法表现出不同复合值之间存在的联系,为了解决这个问题,小组想到了以下三种解决方案:
• 在songs.csv中新增192个类型作为特征,0、1为特征值,表示歌曲中是否包含该特征;
• 将genre_ids的值通过word2vec转换成词向量;
• 在songs.csv中新增8个特征,第i个特征表示一首歌的第i个风格。
以上三种方式哪一种更为合适,需要在下一步建立模型后观察结果进行验证,故在这一部分暂不处理。
songs.csv中的composer,lyricist和artists也存在和genre_ids类似的问题,但它们的种类过多,不能使用第一种方法,且存在大量用various artists等指代存在复合值的情况,也不适合使用第三种方法,因此只能考虑以Word2Vec来处理。
Word2Vec
Word2Vec是一种词嵌入(Word Embedding)技术,主要应用在自然语言处理中,通过分析一个词的语境来确定该词的含义。(由于篇幅原因,不懂的可以百度或者看详细的报告呦)在诸多开源的Word2Vec库中,小组选择了gensim,gensim目前只支持Skip-Gram模型。
数据整合
将处理后的members.csv、songs.csv、song_extra_info.csv分别与train.csv、test.csv合并成两张表。由于对复合型特征的处理方式及转换出的词向量是否会提高结果准确度尚不确定,暂时不将得到的词向量加入到表中。
5 建立模型
训练集、验证集及测试集的划分
已有的train.csv和test.csv已经划分好了用于训练的训练集和用来提交结果的测试集,但我们还需要将训练集train.csv划分为一个新的训练集和验证集用于监督性学习。
SVD模型训练
SVD矩阵奇异值分解是适用于任何矩阵的分解方法,它可以将一个大的矩阵以降低维数的方式进行有损压缩。SVD的原理涉及到线性代数,有兴趣的童鞋可查看报告。
尽管数据预处理之后得到了近三十个特征,但是有的特征具有较多缺失值并且很难直观判断它们与target之间的联系,因此小组首先猜测题目给出的大量特征是干扰项。故只选取数据中的song_id和msno作为特征,则可以得到一个非常稀疏的评分矩阵(分数为0和1),根据已有的评分情况再反过来根据分析结果预测评分。
SVD中实现的过程非常简单,只需要将train.csv、test.csv中的msno和song_id分别合并,带入已经封装好的模型进行运算即可。小组在自己划分的训练集和验证集上得到的结果AUC为0.73,将训练好的模型得出test.csv中target的结果,并提交到kaggle网站,得到的AUC为0.59。当时的大致排名为500+/600+。
这样的排名使小组倾向于判断上述猜测是不合理的,题目给出的其他特征应当被运用到模型中去。尽管单独使用SVD模型并不成功,但我们考虑可以将SVD训练得到的结果作为一个特征加入到后续使用的模型中去。
lightGBM算法
lightGBM 是GBDT的改进算法,而GBDT算法属于Boosting算法族,Boosting是集成学习的常用方法。
为什么小组要选择lightGBM模型涅?其一,数据集原有特征及新生成的特征较多,而且这些特征与目标的关系直观上很不明确,属于弱学习器,因而适合使用GBDT。其二,由于数据集的数据量不小,lightGBM容易导致的过拟合问题在这里不会过于显著。
现在我们开始训练辣!首先使用lightGBM默认参数设置训练模型,训练时在验证集上得到的AUC为0.651,提交Kaggle得到的AUC为0.642,排名约为300+/600+。训练时间大约十分钟。哎呦,不错呦,说明这个模型是较为适用的。但是你以为这样就大功告成了?梦里吧。
(1)在lightGBM下验证特征处理方法的有效性
首先需要对去掉罕见数据的合理性进行验证。我们用没有去除过罕见数据的数据集进行训练,验证集和提交Kaggle的准确性都下降了,这说明去除罕见数据是合理的。
还记不记得之前提到过的对genre_ids的三种处理方法?如果还记得的话,那就奖励自己一个么么哒吧~
• 增加192个新特征:内存不足,无法训练,该方法不成功。
• 转换成词向量:将转换得到的词向量取代原特征值进行训练,验证集上得到的AUC为0.661,提交Kaggle得到的AUC为0.649,准确度提升。
• 添加8个新特征:添加8个新特征后,验证集上得到的AUC为0.626,提交Kaggle得到的AUC为0.633,准确度下降,小组猜测可能是由于过多非重要风格及大量空值的存在导致准确度下降。 因此又尝试只添加第一个特征,验证集上得到的AUC为0.659,提交Kaggle得到的AUC为0.648,准确度上升。在继续尝试逐渐添加特征后,发现同时添加第一个和第二个特征时得到的结果最好,此时验证集上得到的AUC为0.667,提交Kaggle得到的AUC为0.651。
后两种方法都对结果都有提升,并且在含义上具有差异。因此小组决定把两种方法得到的特征同时加入到数据集中,验证集上得到的AUC为0.670,提交Kaggle得到的AUC为0.653。
再对lyricists、composers、artists进行类似处理,发现也对结果有正面影响,验证集上得到的AUC为0.675,提交Kaggle得到的AUC为0.657。
在分别继续加入表示用户相似性和歌曲相似性的词向量后,准确性均提高,因此小组将这两者词向量加入到数据集中,验证集上的AUC为0.679,提交Kaggle得到的AUC为0.663。
我们再尝试将SVD模型得到的结果作为一个新特征,得到的准确率提高,验证集上的AUC为0.685,提交Kaggle得到的AUC为0.666。
(2)调整参数
在训练模型时,小组希望可以使训练速度、结果的精确度和过拟合的程度达到平衡,因此要从这三个方面来调整参数。
首先尝试将num_iteration(boosting迭代的次数)提高到500后,训练时在验证集上得到的AUC为0.697,提交Kaggle得到的AUC为0.686,训练时间大约四十分钟,这说明提高num_iteration对提高现有数据集下的准确率非常有效。
之后尝试逐渐提高num_iteration,当num_iteration达到到3000时,训练时间超过六小时,训练时在验证集上得到的AUC下降到0.678,提交Kaggle得到的AUC下降为0.662,小组认为原因应当是其他参数的选用不合理,尤其是learning_rate与num_iteration相比过大。因此我们使用gridSearch方法求其他超参数的最佳组合,此时的learning rate为0.1,训练得到的模型在验证集上的AUC为0.719,提交Kaggle得到的AUC为0.706。
6 模型评价
特征重要性降序排列
在训练的模型中,重要性排名前几位的特征从高到低依次如下:source_type (用户第一次播放歌曲的获取方式)、source_screen_name (用户播放时显示的播放路径)、expiration_date (终止日期)、registration_year (用户注册年份) 、source_system_tab (用户获取歌曲的方式)。
source_type表示用户第一次播放歌曲的获取方式。有12种类型 (除空白值):如local-library、online-playlist、album等,若用户从local-library打开音乐,说明该用户已经喜欢该歌曲;若用户从album打开该歌曲,说明很有可能会对此专辑的其他歌曲感兴趣,因此source_type特征具有很高重要性。
source_screen_name类似,表示用户播放时显示的播放路径。有20种类型:如My library、Search、Discover New等,若用户播放是My library歌曲,说明该用户已经喜欢该歌曲;若用户播放是Search得来,说明对该用户推荐此类型歌曲可能有很好的效果,若是Discover New,说明该用户最近陷入音乐荒,此时推荐歌曲可能会得到很好响应。因此source_screen_name特征重要性也较高。
总体上,模型特征的重要性与数据探索结果基本上是一致的,如特征registration_year和membership_days等,对目标变量的确有显著性影响。而一些特征如歌手、作曲家是否是同一人等,在数据探索时得出无显著性影响的结论,从结果来看,重要性排名最低,对目标变量的确无显著性影响。
模型对比分析
虽然小组的结果已经挺不错了,但距排名第一的队伍仍有一定的差距。对于单纯LightGBM模型来说,小组AUC较低主要原因有:
• 特征数量不足。第一的小组特征选取有约400个,而本小组只有39个。对于LightGBM模型,在一定范围内特征数量越多,模型预测越准确。但受限于硬件设备,无法加入太多特征。
• 某些特征处理不当。比如对于source_type、source_screen_name、source_system_tab、artist_name、language、genre_Id等特征,1st小组采用了条件概率处理的方法,这种处理方式对于种类数目较多的特征时(msno、song_id)效果比较显著。
模型可用性分析
通过这次比赛,公司的目标是改进他们的音乐推荐系统。 模型能够做到这一点的程度是通过比赛的网站Kaggle评出的分数来衡量的,因此分数反映了模型的精确度。精确度计算如下:
精确度 = (正确推荐的项目 / 推荐的项目总数)
本小组的精确得分是: 0.7060(比赛结束以后)。与在比赛排第一名小组比较,他们得到的准确度为0.74787,因此本小组表现相对较好,我们的模型一定程度上可以帮助公司改进音乐推荐系统。然而,这种模式比较简单,需要进一步完善和推动。
7 模型商业应用
音乐推荐系统的好处根本不用我多介绍嘛,对于普通用户,能够减少选择成本和时间成本,对于小众音乐人,为了提高自身知名度,他们会愿意采用付费推广的方式借助音乐软件平台推荐自己的歌曲。而音乐软件则可以根据模型预测结果将音乐推荐给有更大几率重复听取此音乐的用户,以获得更好的推广效果。
今天是不是对数据挖掘有了更深一点点的认识呀~今天的音乐推荐系统相对于昨天的网络小说挖掘,有更多的数据预处理工作,对特征的提取处理也更为精细,是非常典型的噢~如果有兴趣的话,可以点击下面的“查看原文”输入密码xrui下载详细的报告呢。
以上是关于音乐推荐系统的数据挖掘,了解一下的主要内容,如果未能解决你的问题,请参考以下文章