数据挖掘教你如何写一部畅销网络小说
Posted 浙大信管学会
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘教你如何写一部畅销网络小说相关的知识,希望对你有一定的参考价值。
相信不少人都看过网络小说,但看的多了,总会有这样一种感觉,哎,这个场景怎么似曾相识啊!没错,大多数畅销小说的背后,其实都隐藏着一种符合大众审美、具有普适性的模式。作为信管的同学,让我们来看看如何挖掘这种模式,写出自己的一部网络小说吧。
CRISP-DM (cross-industry standard process for data mining), 即"跨行业数据挖掘标准流程",是目前最流行的数据挖掘方法模型,接下来会依照这一模型的数据挖掘流程来展开介绍。
1 商业理解
根据统计,中国网络文学用户规模达到3.53亿,市场规模达90亿元。作家方面,截至2016年底,国内共有600万网络作家,其中,一些“吸金大神”们动辄上千万元的收入,让无数对网络充满梦想的人看到了网络写手的灿烂“钱景”。
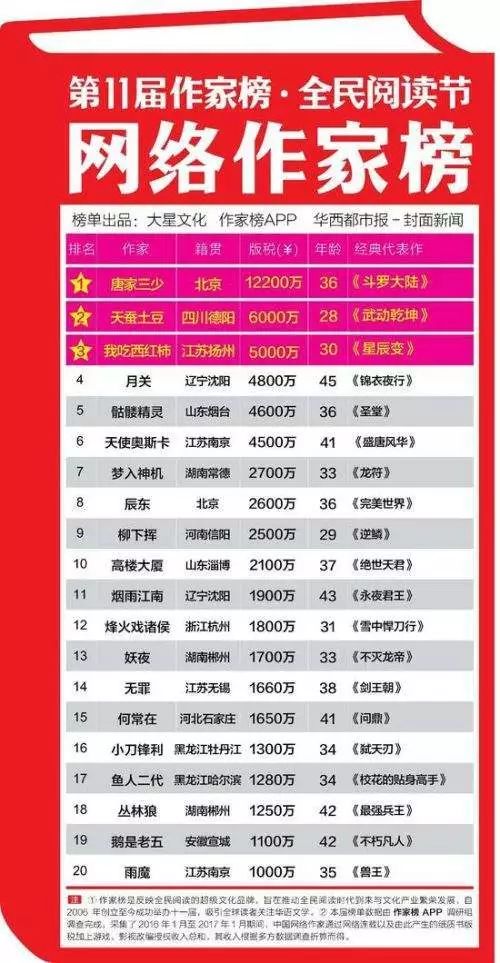
看完这个,是不是非常后悔没有去写网络小说?

你会发现!选择信管、学会数据挖掘,不仅能圆你作家之梦,更能多维度迈上人生巅峰,成为人生赢家,岂不更美滋滋。因为就如最开始所说,我们可以用数据挖掘来探究畅销网络小说的语言模式,用机器学习出一本网络小说啊,不用辛苦的码字,是不是更厉害?不仅如此,我们还可以通过网络小说和传统文学在情节方面的对比,分析如何写是更有文学意义的,给网络小说家以使作品有更高价值的建议呢。干货满满,快来瞧!
2 数据理解

首先我们得思考找什么样的数据(废话,不然挖掘啥东西,挖土吗?)

(1)选取起点中文网排行榜前五十的畅销玄幻小说作为训练文本数据的来源。
(2)将文本分类,主要包括玄幻打斗情节、修炼情节、场景描写等。
(3)选取非网络小说作为对照组。
注意!最后这一步就是为了挽救大家 “作家这个职业已经没救了洗洗睡吧” 这种想法的!
3 数据预处理
想到用什么数据了也别嘚瑟,这可不能直接用,要转换成便于计算机识别和训练的文本,工作量多着呢。

合成训练文本
(1)将小说文档分类,分为东方仙侠风格和西方魔幻风格两大类
(2)将每篇小说进行分词,输出词典与词频,寻找具有情节识别功能的高频词(如战斗拟声词、修炼专有名词),将找到的词提取出来。在各篇小说中查找这些词,并正则提取出邻近300-500 字的内容,即为相应情节段落。
据说“轰”“咻”“唰”这些字后面必定是战斗片段。无言以对.jpg
(3)将每组小说中提取出的段落合并到同一份文档中,调整文档中相关情节的分布距离,每一份聚合文档字数大约为10 万字。
(4)将聚合文档去除空格和空行,并用正则表达式去除网址、广告等无关信息,这样就得到了用于训练的文本数据。
转换文本形式
将文本中文字去除重复后建立索引,用enumerate 方法分别赋予一个顺序码,并存入字典中。
4 训练模型
最重要的来啦,下面可能有点难度噢,稳住,我们能赢!

不知道大家有没有这样的经历,在睡前读较长时间的书后,睡梦中也会出现书中的内容,只不过文字是杂乱的。这是因为你在潜移默化中记住了语言的模式,但是无法在梦中进行创作。我们学习所有语言都是这样的,多听多看才能自己写。但是……
夭寿啦!计算机能识字啦!人类要被取代啦!
咳咳……很遗憾,计算机并不能识字,或者说它识字的方式与我们通常理解的很不一样。计算机不会看“字”,只会读“数”。它不会理解这个词是什么意思,它只能做数学题,即计算这个词出现的概率。比如,说出“元芳”,你也许会不加思索瞬间接上下一句,可是计算机会翻找自己的记忆:我记得看过的社交网络数据里,后接“太帅啦!”占10%,后接“你怎么看?”占80%,后接“狄大人被妖怪抓走啦!”占0%,因此我判断应该是“你怎么看?”
我们在日常说话时当然不会算文字出现的概率啦,这是信息世界的手段。因此我们需要做的,就是把文字转化为数字,让计算机好好看,好好学。
好啦,进入正题啦!
小组采用的数据挖掘工具主要是python中的tensorflow库。
算法选择
采用LSTM长短期记忆神经网络来训练文本,因为小说文本的训练需要联系上下文且语境多样,需要学习的文本数量巨大,相关信息的距离可能非常远。
Embedding 词向量处理
(1)先设置输入变量数量,用tensorflow 中的Variable 函数建立文本的one-hot 稀疏矩阵。
(2)再用embedding_lookup 函数以上下文的文本训练出降维矩阵,降维之后的输入属性数量因文本而异,大致上为500 个。
建立训练模式
(1)将文本数据分批训练,因观察到大多数具有紧密联系的片段在500 字以下,因此建立200-300 的batch size。
(2)用BasicLSTMCell 和MultiRNNCell 建立LSTM 的内层和外层,LSTM 层数为2。
(3)用DropoutWrapper 防止模型过拟合,dropout 时的保留概率设为0.8。
开始训练
(1)将每一批中所有字的文本矩阵作为输入,以下文中的字的概率矩阵作为输出进行训练,计算预测概率矩阵。
(2)开始进行训练,参数大致上设置为速率0.003,步长20-30,循环次数200-250,并计算最终的训练误差。
(由于篇幅原因,我们就不进行名词解释辣,有疑问的同学可以在推文最后点击“阅读原文”查看详细报告或者直接百度噢。)
5 解释和评估
训练误差
经过200 次以上的循环,处理过的玄幻小说文本训练出来的模型误差基本可以降到0.2-0.4(同一篇小说训练误差在0.2左右)。
评估指标
为了量化评估分析输出文本的质量,设定了三个指标:成词率、成句率和成段率。
成词率:正确组词的字占全文字数的比率,只需前后能构成有意义的词汇就属于成词。
成句率:由标点划分的句子中各语法结构完整的句子的字数占全文字数的比率。
成段率:三个句子之间有一定逻辑关系的段落字数占总字数的比率,成段要求没有明显的语义跳跃。
准确性评估
(1)网络小说。由效果最好的训练文本集输出的2000 字文本,成词率高达99.31%,成句率也达到71.67%,成段率有40.54%,训练误差在0.463。可见其已经能很大程度地模仿网络小说写作,基本没有无法构成词组的文字,语义上也能达到较好的效果。为了直观的看到模型效果,我们通过概率模型输出一段文本,摘录如下:
盖茨灵活地在那高达着半空,他的‘脉动防御’和‘大地守护’还一都是眨眼功夫,锋利地利爪猛然用力,简单,又有两名魔法师大人,可是他们畏惧就是越大地攻击竟然伤不了贝贝,可是他却被盖茨防御惊到。这六人的光明斗气就冲向深渊刀魔,每一次看到林雷他们这位体表也冒出了那枚戒指。以紫血软剑阻挡。可看了小子一震到了,正跟这名战士妄人当中逃了出来。他一群要杀的,还是能够施展‘禁锢’。德林柯沃特笑了笑声说道。林雷看到这两只风狼悄然心机一些。同时一道黑影再次砸了过去。这个时候以林雷当初给奥利维亚战斗还到了其他人类,不超很高的攻击。他们这个巨大的熊掌从图焦山直接轰然倒飞,一个巨型火焰在风呼法师,身上满是鲜血,连变大的黑色巨龙,满身靠著依旧是直接化为灰烬,额头地皱,竟然瞬发,林雷的龙尾一抖抓被极速坠下,同时还开始朝迅猛龙背上的魔法师境界,也是瞬间摧毁这重力术影响。这是如此巨石一般,只有无法动弹了。
很像那么回事有木有!电脑真的能自己写小说了有木有!
(2)经典著作。作为对比,通过分析经典著作选段生成的文本成句率只有19.8%,成段率也仅有6.8%,内容较为混乱,含有较多语义语法错误。现将输出文本摘录如下:
城连在一起的胶平公路。这条公路大的矢车菊里。父亲什夫们也不知道,我不怕罪,不怕罚日,也许想管多冷的尸,却笑着更加浓烈。不时,我父亲感知叔自己的低狗,一种不寻动的米风,随着乌量的绸缎子,在拴在木桩上。余下牙头坐起,脸上对着余占鳌,他腰里那两只耳朵。它们竟然是地说,但到过风中,八成是一个人。不来死了,鬼子怕响器。余司令本王文义的脖子,用力摔起,在烟头上像碎块大一颗头上。"往什么?静。"平退,一大群大雁子!高粱上了一一个鸡就焦体的男人。这里,山爷余司令牵着一巴大石桥,也被拉住单薄的黑裤,挂在一起。太阳面腿上碰上一层粗弱的男子用它都射着高粱的尸体,受伤的员们在高粱缝隙里,露出密扣黑衣和拦的风平,随即清气光,被高粱把一群从黑土上扎根开花,结出的血车。"鬼子头那儿被眼珠到她受惯的尸体。余占鳌儿截看着他,双膝跪地,两只大雁在父亲转过枪。余占鳌飞身上前,歪倒了手,从哑巴从肩上摘下。

通过网络小说训练文本与经典名著训练文本的输出结果和以上选段摘录的比较,我们可以清楚地发现网络小说生成的结果更好,更能连词成句、传达语义,而经典名著生成的结果往往无法形成表达明确语义的句子,这也侧面印证了,网络小说可复制性强,往往具有相似的文风与套路,而经典名著具有其独特的风格,因此……
经典是不可复制的!向优秀的当代作家致敬!
6 实践与应用
进步与发展方向
尽管模型已经能够输出拥有较高成词率和成句率的文字,但是还是能够发现很多问题。因此小组提出以下进步与发展方向:
(1)词语内部凝固度分析,识别人名和地名
一部长篇的网络小说中往往有很多人名和奇特的地名,对模型训练有很大的影响,可以识别之后进行替换。
(2)无限猴子
无限猴子定律出自一本名叫《为未来竞争(Competing for the Future)》的商业书籍,是指有无限只猴子用无限的时间会产生特定的文章。也就是说只要能一直一直输出下去,总会找到合适的段落哒!(心疼机器宝宝1秒)
(3)语法分析,排除不合理句子
对于现在输出的文本中一些语法不合理以至于无法传达语义的句子,我们可以通过一些NLP的技术对句子进行语法分析,排除不合理的句子。
(4)分类生成场景并进行整合
在应用中还可以对网络小说进行进一步分类,并整合数据,形成一个常用的场景库,作者可以从库中选择对应的场景,生成文章。以玄幻小说为例,我们可以将其常用场景分成修炼、战斗、环境三大类,当作者写到战斗场景时,直接从库中选择战斗,即可生成一段描写玄幻战斗的文字。
未来应用的展望
小组希望通过机器学习算法训练出畅销网络小说语言模式的模型,将“文笔”量化成为一些矩阵和概率。长此以往,就可以收集到大量的成功作家语言模式。之后网络小说的写作可以在作者写出一句话以后,后面出现一个下拉框,里面有各个畅销风格的接续语句。这样就可以让一些作者摆脱文笔不足的烦恼,让一些文笔功底不足但是想法构思很好的“草根作家”有写出佳作的机会。
鸣谢
该项目指导老师:陈熹老师
该项目小组成员:
信管1501 张桐华 金珊冰 胡妍楠
小组参考书目:
《NLP 汉语自然语言处理原理与实践》郑捷著
《面向机器智能的TensorFlow 实践》山姆·亚伯拉罕等著
本期干货到这里就结束啦,不知道你们get到多少呢,反正我是没有学会哈哈哈哈哈哈。预告一下,下期将推送KKBox音乐推荐系统的数据挖掘项目,不见不散噢~
点击下方“阅读原文”输入密码hc20即可
下载详细项目报告哦
以上是关于数据挖掘教你如何写一部畅销网络小说的主要内容,如果未能解决你的问题,请参考以下文章