基于数据挖掘的路由器系统日志分析系统——SyslogDigest
Posted 智能运维前沿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于数据挖掘的路由器系统日志分析系统——SyslogDigest相关的知识,希望对你有一定的参考价值。
本文介绍一种基于数据挖掘的路由器系统日志(下文简称为路由器日志)分析系统——SyslogDigest,是裴丹老师在AT&T工作时与同事合作发表于IMC2010上的一个工作。
路由器的系统日志记录了在路由设备上的各种事件,通过这些日志运维人员可以追踪查找相关的软硬件错误和可能的网络故障。然而,直接通过日志来进行分析有诸多不便。在目前的ISP网络中,涉及到数量庞大的网络设备,典型的网络监测系统依赖于专业的领域知识,需要有预先设定的规则或者运维人员的介入,将需要分析的日志定位到具体的时间段,以缩减需要处理的数据量,之后再进行后续的分析处理。因此,如果能将这些底层的日志通过自动化处理,生成可读性更强的网络事件是十分有帮助的。
路由器日志的分析与处理有以下的一些挑战:
1. 日志文本低结构化。现今的ISP网络中,涉及到的路由设备数量十分庞大,其上记录的日志信息数据量非常大,而不同厂商、设备型号的日志格式则各有不同。这些日志一般具有一些简单的格式,例如时间戳、设备信号和日志标签等,但具体内容则往往没有统一的格式。
2. 日志信息过于底层。路由记录的原始日志往往是底层硬件、接口的状态,可读性较差,并不能直接对应到网络的事件,这需要额外的专业运维人员进行处理。
3. 日志信息有大量的冗余。并非所有的日志都与我们关心的事件相关,例如许多正常运行时产生的日志信息就对运维人员并无太大的帮助,运维人员更关心那些与网络故障直接相关的信息。通常的一些系统只过滤带有“错误”(error)标签的日志,但这会使得运维人员失去对网络全局的把握。
面对这些实际的问题,本文提出了一个自动化地处理底层原始的低结构化日志的系统——SyslogDigest,该系统能够将原始信息进行聚合、转化和压缩,生成对应的有实际含义的、可按优先级排序的网络事件,方便运维人员进行分析与处理。
整个系统的工作流程分为两个大部分:离线的领域知识学习系统和线上的日志分析系统。其框架如下图所示。
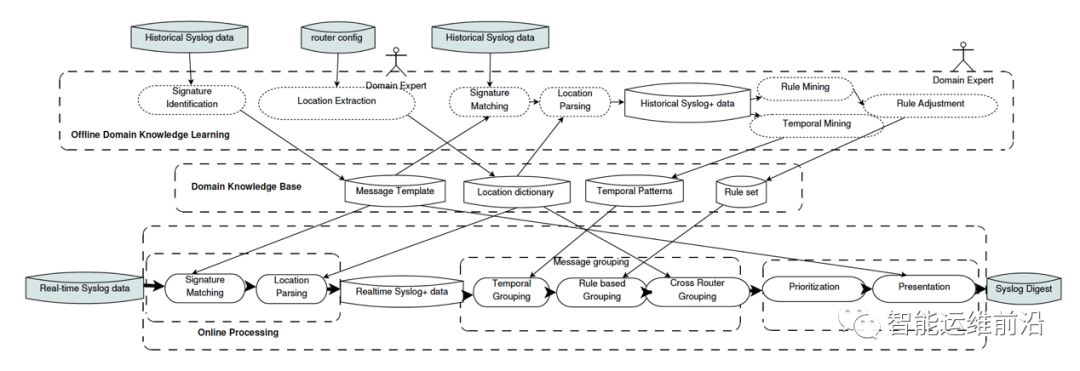
系统工作流程框架图
此外,在同一个路由上,对于相同模板的多条日志,系统通过日志间隔时间来记录日志的时序特征(temporal patterns)。对于不同模板的日志,通过关联分析匹配不同的日志,生成日志模板的关联规则(rule set)。
在实际的运行中,该系统也可以增量调整各参数,添加新的规则、删除过时的规则,以适应新出现的日志文件。
2. 线上分析系统的输入为实际产生的日志文件流以及上述离线生成的参数和知识库。通过模板和位置参数,SyslogDigest系统对每条日志进行匹配和分类。对分类后的日志进行聚合。
聚合部分分为三个阶段:a) 基于时序,通过已有的时序特征,将同一路由上相同模板的日志聚合为一组;b) 基于规则,通过已有的关联规则,将同一路由上相互关联的不同模板日志聚合为一组;c) 跨路由器聚合,通过已知的位置参数,将不同路由之间对应的位置参数(例如,同一连接两端的两个端口号)聚合为一组。
至此,将原始的多条日志聚合为一个完整的网络事件。最后,系统会计算该条事件的优先级权重并输出。
1. 日志模板
多数路由器日志是低结构化的文本,一般均带有简单的日志类别标签。但实际中,具有同样的类别标签的日志也不完全相同,因此,需要提取出同样标签日志的“子类别”。如下图所示,这些日志的类别均为“BGP-5-ADJCHANGE”。

系统日志实例
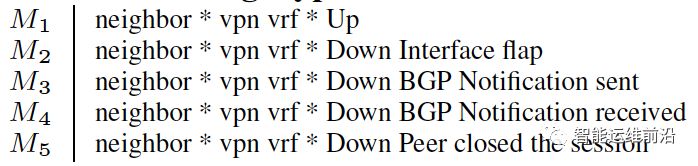
上述实例的日志子类别
SyslogDigest系统通过构造树来识别某一类别所有日志的子类别。对一条日志,可以将它的文本信息分隔为若干个单词。若一个单词出现在一条日志中,我们称之为该词与该条日志相关联。首先,用日志的类别标签作为根节点。对于一个节点。将文本中能关联尽可能多的日志条目的高词频单词组合作为子节点;对于剩余的文本,重复上述操作直至所有日志均被关联。然后按此递归构造子节点。
在整个树构造完成后,进行剪枝,对子节点个数多于一定阈值(本文中取10)的节点,删除其所有子节点,直接作为叶子节点。通过剪枝,避免将参数信息作为模板包含的单词。构造的树如下图所示。
构造完毕后,从根节点到叶节点的每一条路径即为一个日志子类别。
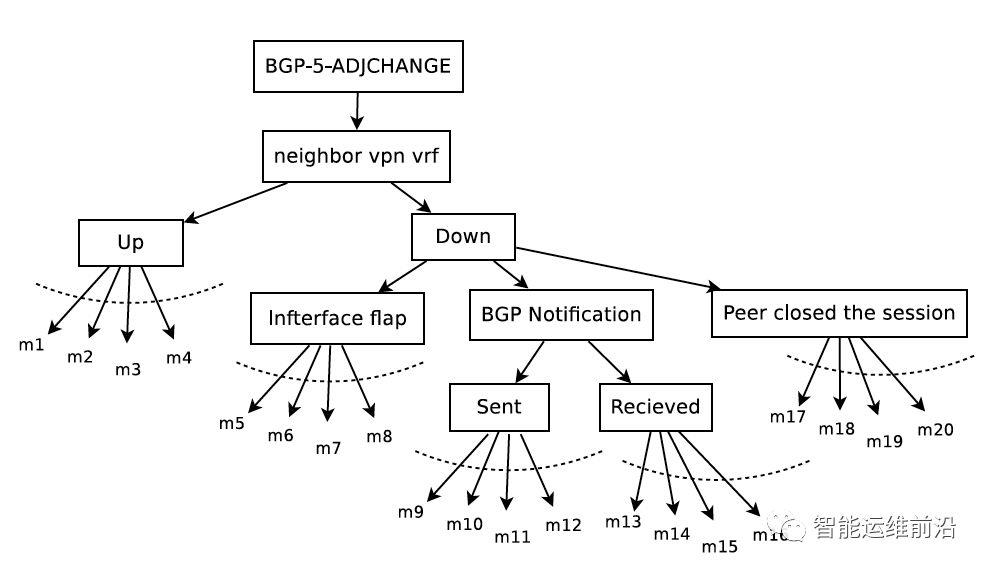
子类别构造树
2. 位置参数
3. 时序特征
需要注意,时序特征针对的是同一路由上相同模板的多条日志。本文所采用的方式是计算日志之间的间隔时间。
同一网络事件往往会引发某一模板的日志短时间内周期产生,在时序上则表现为连续产生的多个较小的时间间隔。将日志的时间间隔视为一个序列S1,S2,…,本文通过指数加权移动平均值(EWMA)来计算,公式如下(α、β为参数)。
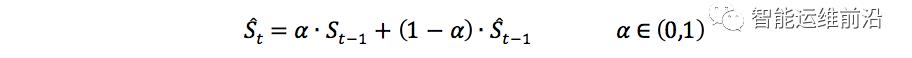
其中等式左侧表示第t个值的预测值。如果有
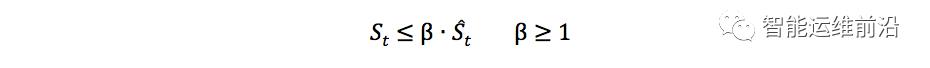
即实际的时间间隔没有比预测值大很多,则该条日志视为同一事件发生。根据数据集的不同,参数的值需要进行调整。
4. 关联规则
关联规则旨在匹配不同模板。同一网络事件中,往往会导致有联系的日志同步产生。本文使用了经典的关联分析算法。将所有的模板类别作为项集;以历史日志作为输入,从第一个日志开始,通过宽度为W的滑动窗口方式生成频繁项集,频繁项集的每一个元素即为滑动窗口内的日志模板序列;支持度(supp(x))定义为数据集中包含该项集x的记录所占的比例;可信度(conf(x=>y))定义为
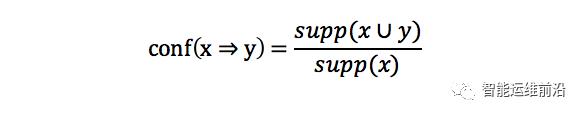
当conf(x=>y)高于阈值confmin时,则x与y关联。
另外,该系统还有增量更新的能力,当线上系统新输入的日志中出现supp(x)和conf(x=>y)均高于阈值(suppmin和confmin)时,则添加新的规则。
5. 优先级权重
本文中,使用三个参数来评估一个事件的优先级(重要性),分别为:
a) 日志模板m发生的频率fm。频率越高则重要性越高。
b) 日志发生的层级lm。越高层的重要性越高。各层级如下图所示。
c) 聚合后事件所包含的日志数量M。
最后计算的优先级权重按如下公式得到:
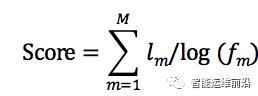
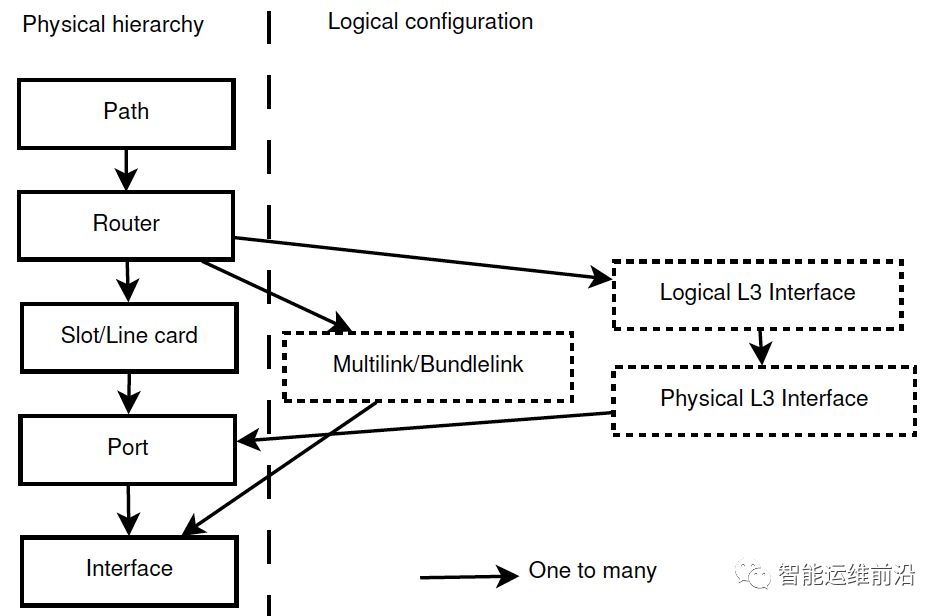
位置信息层级
本文使用了两个数据集来进行实验,分别来自于一个大型ISP骨干网络和一个IPTV骨干网络,记为数据集(Database)A和B。
对两个数据集,本文计算SyslogDigest系统的压缩率来评估系统的效果。压缩率的计算为产生的事件数目除以原始的日志数量。产生的事件实际效果通过运维人员进行人工验证。通过验证,发现该系统能够较好地完成聚合事件的工作。
系统的各参数,会影响最后的压缩率结果,下列图片反应了不同的参数对于系统效果(对产生的规则数量和压缩率)的影响。
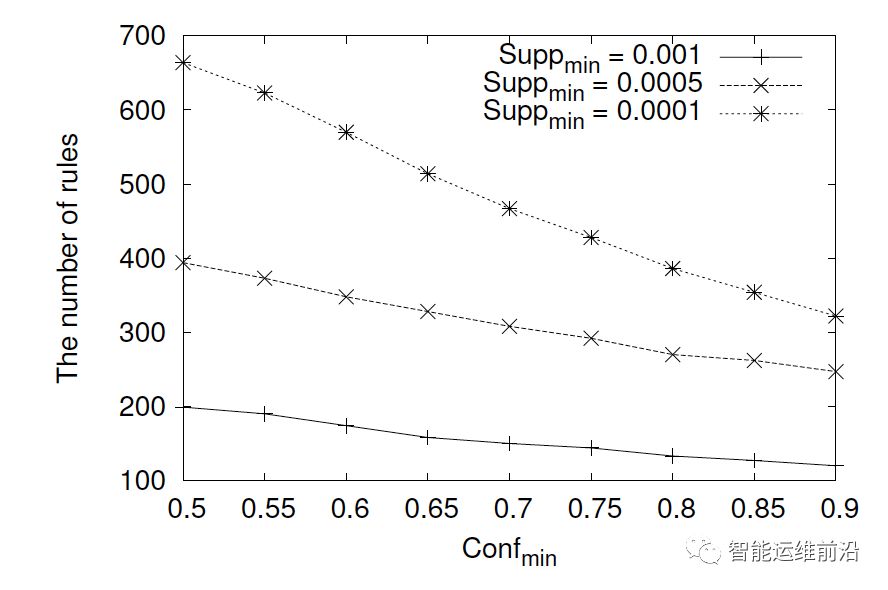
关联分析参数对规则条目数的影响
随着confmin值的增大,学习到的规则数会逐渐减少。suppmin的值越高,获得的规则数也越小。在本文的实验当中,研究人员选取的suppmin的confmin的值分别为0.0005和0.8。
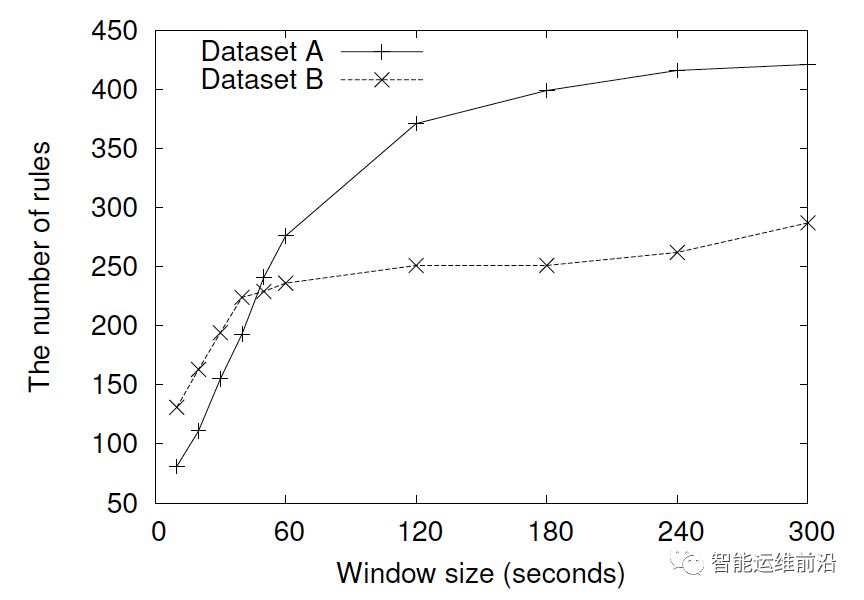
滑动窗口大小W对规则条目数的影响
算法中的滑动窗口大小对学习到的规则数也有影响。总体来说,随着W值的增大,学习到的规则数目会上升,但一旦达到某个临界值之后,规则数目的上升趋势会迅速减小。而增大W的值对系统算法的开销影响较大,综合考虑在数据集A和B中分别选择W的值为120和40。
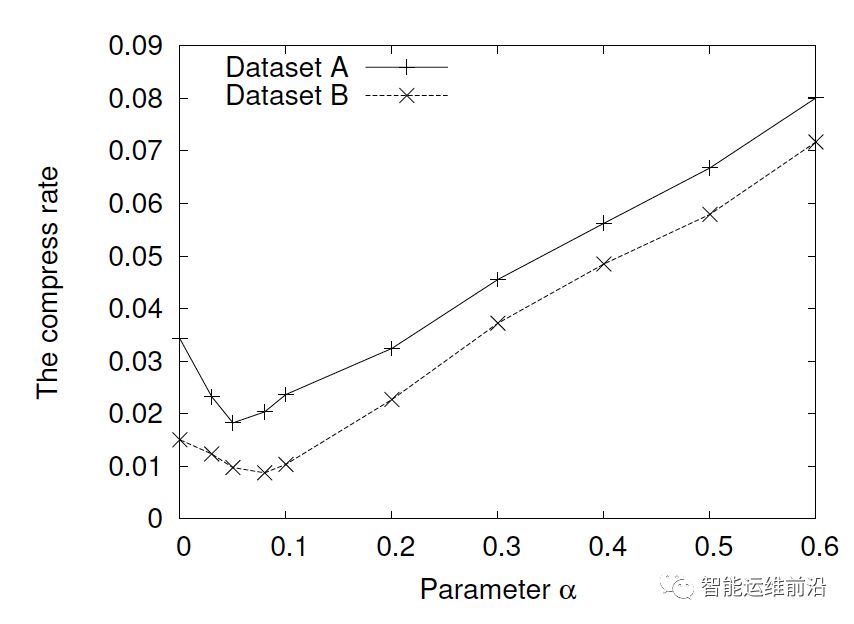
参数α对压缩率的影响(β=2)
在固定参数β的值情况下,可以看出,随参数α的增大,压缩率先降低后上升。在数据集A中,α的值在0.05左右是压缩率最低,在数据集B中,α的值在0.075左右时压缩率达到最小值。因此,在后续实验中,在数据集A、B中分别取0.05和0.075作为参数α的默认值。
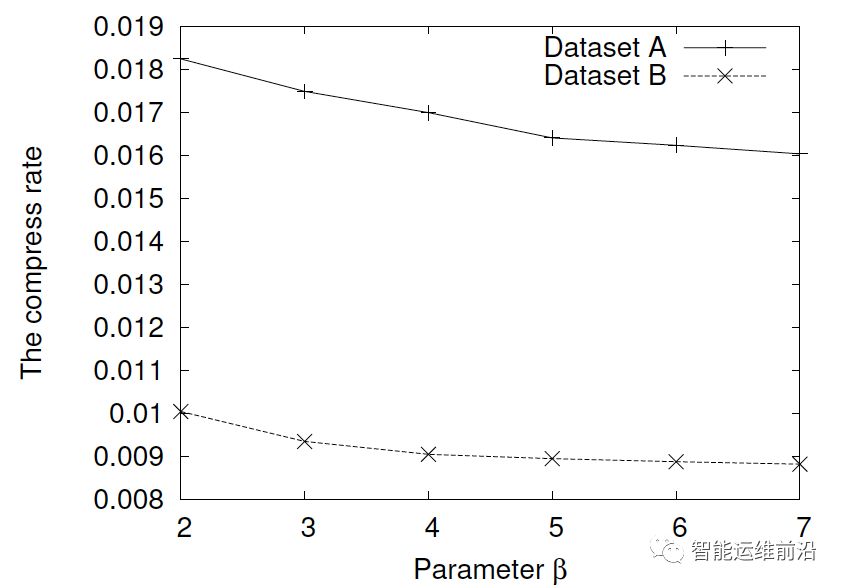
参数β对压缩率的影响(数据集A中α=0.05,B中α=0.075)
在上述的参数α取值条件下,调整参数β的值,随着参数值增大,压缩率成下降的趋势。通过观察可以发现,当β值增大至一定程度后,压缩率下降的速度会降低。因此,在实际实验中,在两个数据集内参数β都选择为5。
综合考虑,最后对两个数据集选择的参数如下:

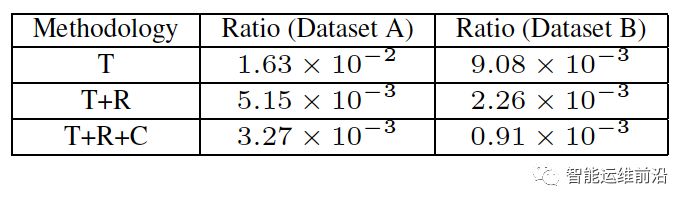
最终在两个数据集上的效果如下:其中T、R、C分别代表基于时序的聚合、基于规则的聚合和跨路由器聚合。
除了实验验证之外,SyslogDigest系统还被应用到了实际的生产环境当中来帮助运维人员进行网络状况的监测和故障分析。例如SyslogDigest系统被应用于商业IPTV网络,来帮助运维人员分析、查找在IP组播时发生的PIM neighbor loss错误。通过该系统可以极大地简化人工干预的部分,提升故障定位的效率。
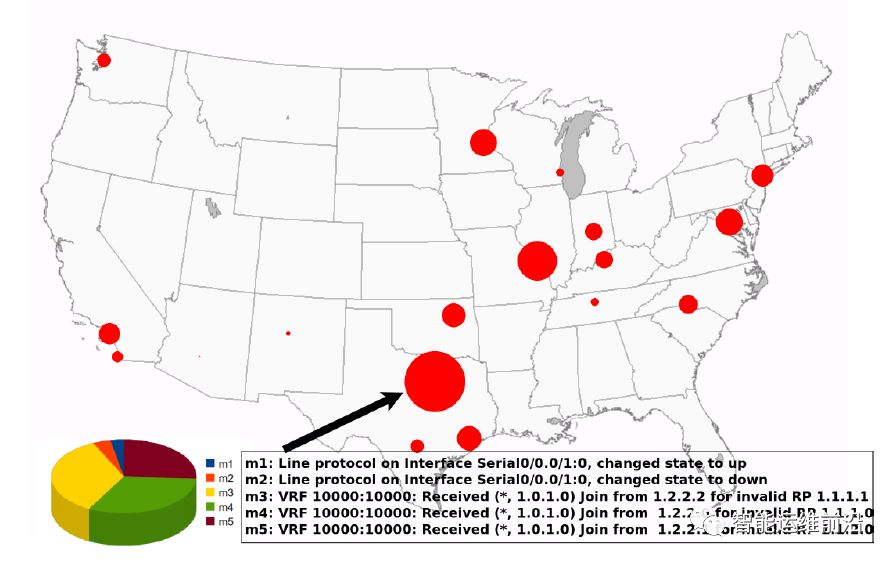
另外,由于SyslogDigest系统对原始日志信息高效的压缩、聚合能力,该系统还能被用于数据可视化。例如下图是2009年12月5日16时的网络状态的快照,该图基于原始的日志进行可视化。为显示更加清晰,原图上的网络拓扑结构和数据链路负载等信息被隐藏了。在图中,红色的圆圈代表了发生的网络事件关联到的日志,圆的面积越大说明日志的数量越多。
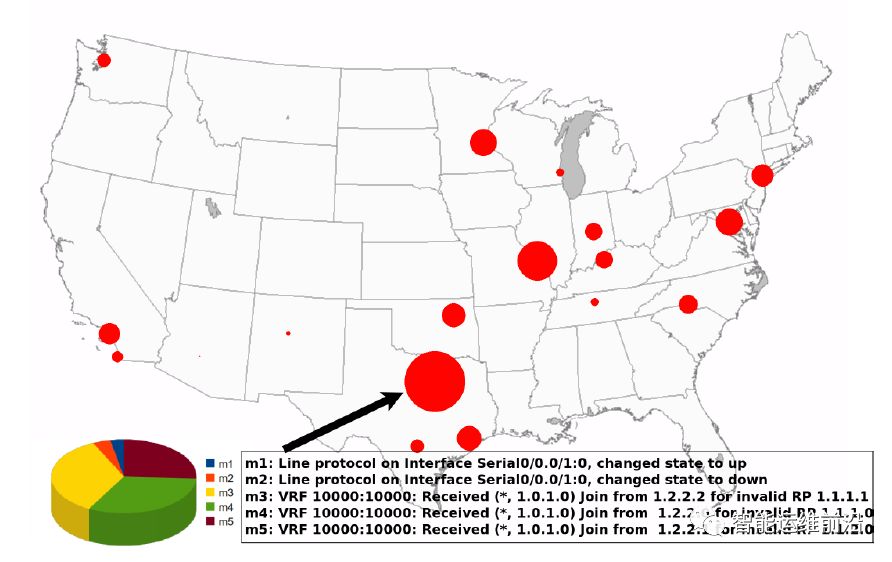
基于原始日志的可视化结果
在可视化过程当中,需要对不同的日志进行解码,最后保留的结果也包含着各种不同的信息格式(在饼图中表示)。另外,该可视化方式还有一个不可忽视的缺点,即圆的面积更大,不能代表发生的网络事件更多(仅仅是日志数量本身更多),这与人们的直觉不相符,也可能影响运维人员对于实际情况的把握和判断。
而基于SyslogDigest系统的可视化结果则是根据网络事件的数量多寡进行表示,如下图所示。通过对比我们可以发现,在原始日志的可视化中面积较大的结点,在新的可视化图像中仅仅是中等大小的圆,这避免了上述所说的因为大量的日志数量而产生的“误导”情况。在另一方面,SyslogDigest系统也极大地减少了输出的条目数量,减少了运维人员后续的处理复杂度。
基于SyslogDigest系统输出的可视化结果
在可视化中应用SyslogDigest系统,对于大型网络的监测和故障定位有着巨大的帮助。通过该系统,运维人员可以高效地追踪网路事件的动态变化,有效地提升了生产效率,减少了不必要的系统和人工开销。
以上是关于基于数据挖掘的路由器系统日志分析系统——SyslogDigest的主要内容,如果未能解决你的问题,请参考以下文章