如何在第一次天池比赛中进入Top 5%?开发工程师初试数据挖掘大赛(下)附学习资料
Posted 天池大数据科研平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在第一次天池比赛中进入Top 5%?开发工程师初试数据挖掘大赛(下)附学习资料相关的知识,希望对你有一定的参考价值。
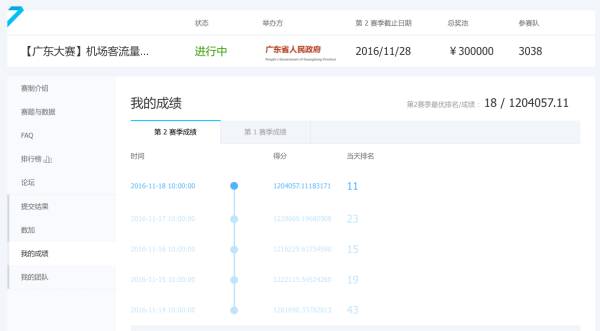
11月28日,广东大赛之机场客流量的时空分布预测赛复赛已完结。12月14日,top5的队伍将前往华南理工大学进行答辩。而比赛过程中,有一位开发工程师,初次接触数据挖掘竞赛,就获得了天池大赛初赛TOP5!上一期天池小报中,我们介绍了他的初赛经验,那么第二赛季他的成绩如何?他又是怎么做的呢?且看他是怎么说的。
初赛结束后休息了几天,就进入到了第二赛季。第二赛季的前五名将进入最终线下答辩,角逐那30万元总奖金(以及公主的青睐和勇士的光荣!)。在这个赛季里,面对巨额奖金的诱惑,无数神牛的踩踏,哥终于展示出了真正的实力,以完美的表现,勇夺第肆拾捌名!
◆ ◆ ◆
赛制变化
哈哈哈,还是说正经的,复赛主要有两个变化,一是数据量变大了,从初赛两周多的数据扩展到了六周,而且需要预测的值从原先的三个小时,变为连续两天的数据。二是复赛必须使用阿里云上的MaxCompute(原ODPS)和PAI机器学习平台作为比赛工具来进行所有的数据分析,处理,建模,训练和预测。
10月28号复赛正式开始,由于之前没有用过阿里的这两个工具平台,所以先花了两天时间来慢慢学习……这里碰到的一个问题是阿里的各种工具平台好像变化都比较快,天池论坛上能找到的各种教学都是基于一个叫“御膳房”的产品的,在这上面绕了不少弯路。还有复赛用的账号体系也有点诡异,提交工单必须用原先的阿里云账号,登陆大数据套件又要用一个单独的RAM账号,如果你用的系统又不幸像我一样设置了默认语言为英语,还会碰到一堆i18n的坑(比如进论坛就直接进了个国际版的,内容都不一样)……总之最后我还是乖乖把系统语言设成中文,结合了天池给的5,6个文档,总算大致摸到了本次比赛主要使用的两个工具:
大数据开发套件(ODPS)
机器学习平台(PAI)
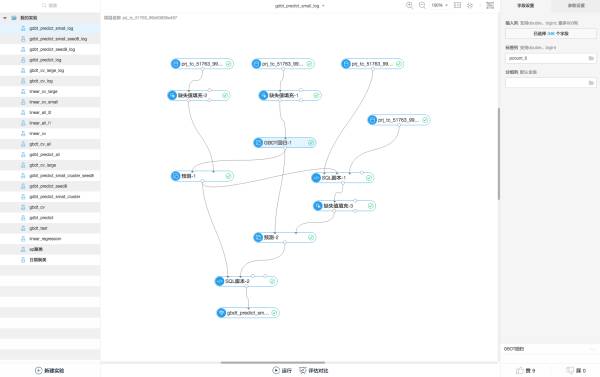 是不是亦可赛艇!
是不是亦可赛艇!
不得不说天池复赛的这个设定还是比较有特色的(相比Kaggle之类的比赛),这两个工具应该也是阿里内部使用的大数据开发平台,能拿出来让选手们用,可以说是非常难得的接触真实大数据开发场景的机会。当然使用过程中还是有不少问题,后面我会提到。
除了工具这块的变化,赛题本身也有了很大的不同。根据初赛的经验,权重最高的那些feature都是时间序列特征,也就是WIFI AP连接数的历史值。初赛只需要预测3个小时,可以很自然地使用预测点前时间段的值,前一天同一时间段的值,历史平均,差分平均,各种平滑方法等作为feature来进行训练和预测。现在一下子变成了预测两整天,如何提取特征成了一个大问题。我的思路主要还是从时间序列和航班分析两方面入手。
时间序列方面,同时间点均值相关的特征都可以得到,但是之前时间点的特征就比较麻烦了。比如我假设要预测的点依赖前三个时间点的数据,那么在训练结束后进行预测时需要预测一个时间点,然后把它加入到feature中,再预测下一个时间点,这样循环进行。这个用代码还是比较好实现的,但是如何用拖拽式的机器学习平台实现,我到最后也没有找到方法……所以我主要是用了前x天同一时间点,或者前x天的前y个时间点之类的方式来构建feature。在预测完一天数据后,要把那天的预测值作为已知进行处理后形成下一天的预测feature。
航班方面,一个自然的想法是如果5点钟有航班在E1区域的某个登机口起飞,那么大致从3点半开始就会有旅客陆续到达机场,过安检,然后优先在E1区域附近候机,顺便连上WIFI玩个阴阳师刷个淘宝看个剧啥的……所以航班排表,是起飞还是降落,在哪个登机区域等都可能会对WIFI连接人数有影响。我的做法是做时间偏移后再进行表join再进行group by计数……后面再详细解释。
另外对于不同日期和不同WIFI AP点,也都可以做一下相关性分析。可以找出一些时序特征相似的AP点进行分组后的分别建模。日期方面则可以反过来通过WIFI AP点均值作为特征分析一下哪几个日期比较异常,在训练时考虑进行筛选处理。
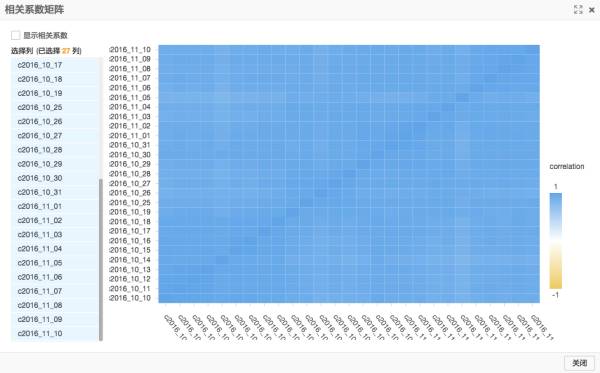 (使用PAI做日期相关度比较,色彩范围没法自定义,不过大致可以看出几个较淡的日期点有异常)
(使用PAI做日期相关度比较,色彩范围没法自定义,不过大致可以看出几个较淡的日期点有异常)
◆ ◆ ◆
特征工程
有了思路之后就要用工具去实现。刚上手ODPS,发现只能写sql了(基本跟Hive用的sql一致),顿时有点慌乱。哥脱缰野马般的思路如何用简简单单的sql做出来啊?感觉不现实啊!然后去看比赛帮助,貌似还可以写Map Reduce来实现嘛!等等,Map Reduce?这都2016年了,还写Map Reduce是不是有点太刀耕火种了点啊!现在不都是Data Frame满天飞吗,人家Spark都不建议直接写RDD操作了……又一顿猛搜找资料,发现ODPS有Python库可以支持Data Frame,在论坛提了几个问题,拿到access key之类的试了下发现用Python库操作ODPS表需要加入IP白名单才行……最后在旺旺上跟比赛组织方确认了,不允许用Python库……正在我万念俱灰要开始写MR的时候,一位用过ODPS的同事跟我说其实ODPS的sql,很好很强大!我又去翻了翻文档,发现还真是有很多内建函数,挖挖脑洞可以实现不少牛逼的功能。比如一个数据表的行列转换,本来numpy里一个transpose就能搞定了,现在上了sql:
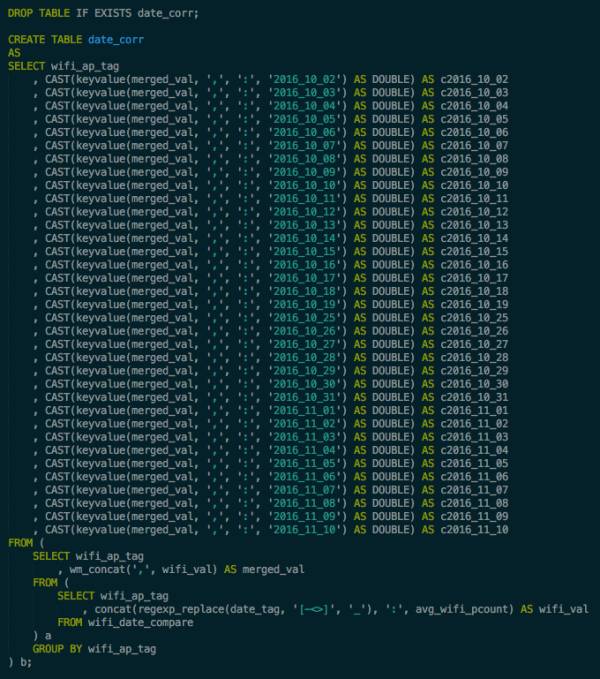 就问你服不服吧!哈哈哈(还写了很多辅助工具用来生成这些sql……)
就问你服不服吧!哈哈哈(还写了很多辅助工具用来生成这些sql……)
有些稍微难搞一点的,比如数据中很多日期格式比较乱需要做预处理,可以自己写个UDF上传上去搞。结合各种内置函数,上面大多数的feature都顺利地实现出来了!刚还特地统计了下,足足写了9000多行sql!难怪好多阿里的数据工程师都说自己是专业写sql的,我算是有切身体会了……
整体做feature过程中用到最多的就是各种时间偏移后的join了。比如前面提到的航班feature,举例来说5:00有一班飞机起飞,那么很可能从3:30到5:30(用上了之前统计的旅客提前到站的中位数和飞机晚点时间的中位数来预估这个范围)这段时间内,这个航班的存在都会对这个登机区域的人数有影响,所以我的做法就是把这个航班时间点做个偏移,比如减去10分钟到4:50,去join原先的时间表,那么4:50这个时间点在最后group by + sum时就会有+1的航班数量了。然后结合上航班的区域,各个时间点,是到达还是离开等做分类,光航班部分的特征就有100多个了。另外还考虑过用上安检和值机那两张表的数据,用来推算不同的航班可能乘坐人数的差别,旅客的不同行为习惯,等等看上去好有道理的分析思路……但是两表一join,发现航班号就没几个对的上的……只好作罢。除了航班,还有AP点相关的一系列feature,比如楼层,登机区域,时序相似度分组等,都可以通过表join和简单的字符串处理加IF语句搞定。
时间序列方面的feature是重头,有很多特征来自于这个,以及各大比赛分享,教材,论文等等。哈哈真的有读不少论文啊,还特地去图书馆看了一圈时间序列的书:
 (理论光环加持下的我!左边这本书对初学者相当友好)
(理论光环加持下的我!左边这本书对初学者相当友好)
在前面提到的各种平均,差分,滑动窗口,指数平滑等特征基础上,为了减少信息损失,还加入了各类min,max,median,偏度,标准差等属性,还试过傅里叶级数,加上各种sin,cos算出来的周期特征值。对一天的各个小时,一周的各天,weekofyear之类的做了one hot encoding的feature,还为了处理中间的国庆中秋两个假期,加入了是否是节假日,距离国庆节开始还有几天,距离国庆节结束还有几天,本周节假日共有几天等等脑洞feature。有好几天我都是对着白云机场的官网,广州天气预报,Mac自带的日历程序,苦苦探寻,就差飞去白云机场安几个摄像头做实地检测了……可惜还是没能找到那个可以突破百万误差大关的“magic feature”。
◆ ◆ ◆
槽点略多的模型训练
特征部分说的差不多了,再来看看另一个更加fancy的机器学习平台。比赛中所有模型的构建,训练,预测都是通过这个PAI平台来做的。平台的本意可能是想让不会写代码的业务人员也能轻松通过拖拽来跑高大上的机器学习任务,但是……都是搞算法的人了,写几行Python没那么难吧!我一上来想用这个平台实现下初赛中的“先做clustering,再对各个分组做线性回归”流程,做出来的东西连我自己都有点害怕!
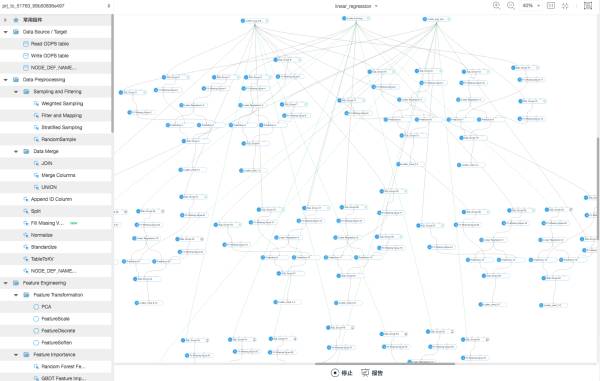 (这张图里还展示了个PAI的bug,不知有没有人能看出来)
(这张图里还展示了个PAI的bug,不知有没有人能看出来)
本来几行代码一个循环能搞定的事情,拖这个图足足花了我一下午……而且这个编辑界面有bug,如果你选中超过一定数量的元素进行copy paste的话,会先窗口卡死,强制刷新后出来3个副本,完全重合在一起的那种,有点痛苦……不知道是不是我的用法有问题,我一直到最后也没找出这个平台上如何进行高效的“组件重用”和“模型重用”,要么复制元素,要么干脆复制整个实验,总之都是挺吃力不讨好的工作(跟当年用JMeter的感觉很像)……相比来说,我更喜欢,DataBricks那种利用notebook进行开发的方式:
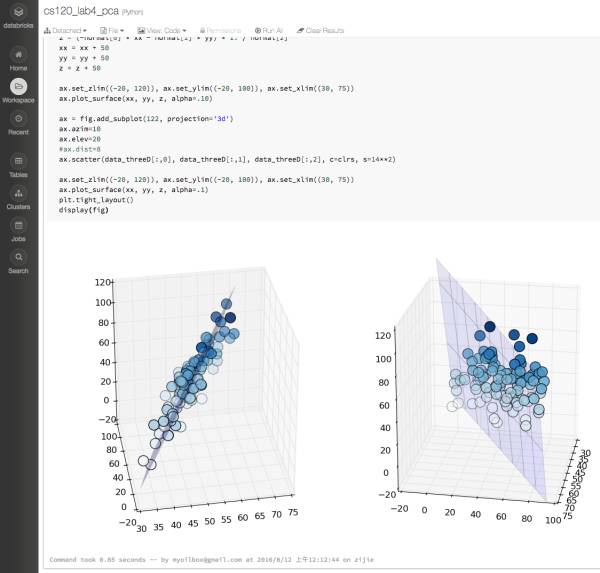
人家也是直接连上Spark集群跑的,也是在浏览器里做开发,数据探索,特征工程,模型训练预测都可以用一个系统搞定,还能拥抱Python/Java丰富的开源库减少重造轮子,这体验实在好太多了……比如本来可以在notebook里直接用matplotlib之类画图观察的,现在也只能先在ODPS里存好数据,然后在PAI里画图,图的种类也比较少,导致很多时候我都是在ODPS里跑了之后从日志里拿数据,然后拷出来在excel里画……曲线救国。
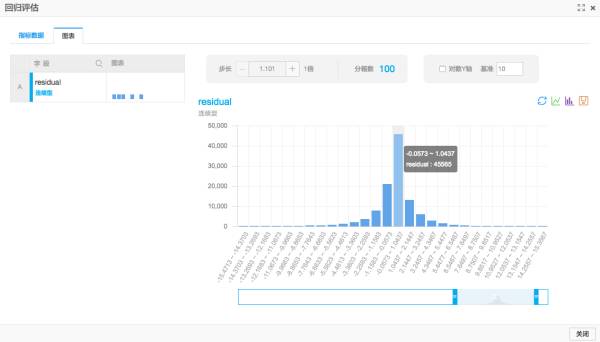 (PAI的回归模型评估组件里自带了一个histogram,方便查看误差分布)
(PAI的回归模型评估组件里自带了一个histogram,方便查看误差分布)
另外notebook里跑的基本都是代码,或者混合些markdown可以直接做出漂亮的报告来,进可做演示发论文,退可抽取代码部署上线。但用了机器学习平台,训练好了模型这个要怎么转化给线上使用呢?可以用ODPS,PAI的命令行接口包装成服务么?模型可以保存吗?好像也有点额外的开发成本……
跟PAI类似的拖拽式机器学习平台貌似也有几个,比如著名的,不过人家只是纯粹为了演示玩玩。还有个牛逼的!可以很方便地拖出一个神经网络来训练,背后应该是自动生成了Keras/Theano之类的模型代码,而且有很多训练过程以及模型insight的可视化展示,这块比起PAI来说还是要好不少。虽然个人觉得给Keras这种已经很傻瓜式的库再做个UI也没多大必要……
 (本地没有搭Keras环境,这个Training的图是从宣传Video里截取的)
(本地没有搭Keras环境,这个Training的图是从宣传Video里截取的)
比赛过程中发现PAI应该还是在频繁升级完善中,回归模型目前只提供了GBRT和线性回归两种,而且线性回归只能是单目标变量。文档跟平台也有点脱节,比如我找了半天都不知道怎么看GBRT模型的feature importance,用里面自带的GBDT模型特征重要性分析跑出来怎么都是空白的……最后提了工单才知道确实是不支持。另外还有one hot encoding,之前在pandas里是get_dummies一行搞定,现在只能用sql来做了……比赛进行到一半发现PAI也加入了one hot encoding的模块,兴高采烈去试了下发现不会用……也没找到文档……只好又切换回sql了。
不过PAI也是有优点的,比如模型训练都可以直接在云上跑了,妈妈再也不用担心我的本本通宵训练烫到宕机了……只可惜……到了比赛最后三天时,由于大家都争相跑模型训练,整个ODPS + PAI平台都变得奇卡无比,选手们纷纷在群里吐槽资源隔离没有做好……我有连续2个晚上都是提交了训练任务去睡觉,早上抢着10点前来收结果做提交结果发现训练执行了一两个小时后就挂掉了,所以也没有新的结果可以提交……有点伤士气。不知道是计算节点的失败调度重试没做好呢还是job master直接挂掉了……
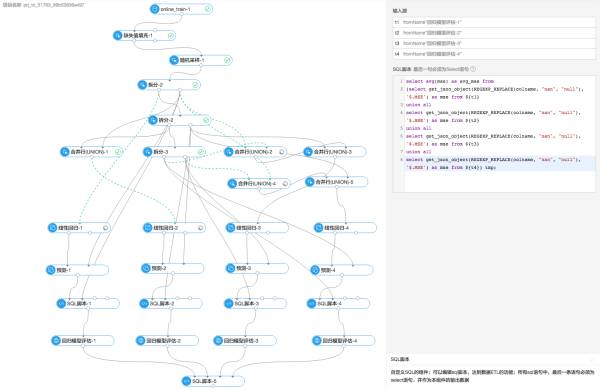 (在PAI上做5-fold的cross validation,要是做stacking估计又要拖出个毛线团来……)
(在PAI上做5-fold的cross validation,要是做stacking估计又要拖出个毛线团来……)
最终,我用ODPS做了大概350来个特征(对比初赛时大概是60来个),然后在PAI上用GBRT做各种cross validation,参数调优,结果预测。本来还想用上线性模型的,但是没有特征权重的数据,直接把300多feature灌进去跑会得到稳定的100% fail……只好作罢。Stacking由于时间原因没精力去走线了(参考上面的附图),base model嘛只有加权平均规则和GBRT,换了几个实验的随机种子,最后做做权重融合聊胜于无吧。这个方法在切换数据之前在第一页保持了一段时间。
还有很多没有尝试的思路,包括
初赛时的clustering + LR/GBRT(不是很确定PAI提供的那个GBRT里那个分组列有没有作用)
ARIMA + 干预分析模型
先预测粗粒度的值,如每日/每小时平均,再作为feature进行二层训练
DTW + kNN预测,但好像一次性预测一天的时间点不太现实
LSTM,只要扯上DL就有可以毁天灭地的感觉
更加暴力的特征交叉生成与选择,可惜GBRT拿不到特征重要度…
如果时间充足,MR熟练到飞起的话倒是可以一试……
◆ ◆ ◆
复赛历程
在复赛中的心路历程跟初赛比平和了许多,也没有通宵达旦去搞各种验证调优了(或许Map Reduce才是正确的方向?)。在切换数据前,随着feature的增长和各种权重的调整验证,慢慢地爬到了前20。中间尝试过对一些误差贡献非常大的AP点做一些特殊处理,比如单独训练,加大regulization,单独使用规则之类,都没有很好的效果。印象最深刻的就是排名第一的SeaSide了!从比赛中期某天开始就大幅领先其它选手,有种当年DL横空出世碾压ImageNet的感觉……还有那个神秘大叔,天池总排名第三的MD,第一次提交貌似就是在11月20日,排名20,这种霸气和自信,我等弱鸡何时才能拥有!
到了21号切换数据(新数据集中有近一周的数据丢失,不过我用的特征构建并不大受影响),风云突变,好多排名靠前的队伍都大幅跳水,有好些之前没怎么见过名字的队伍一下冲进了第一页,只有排名第一的SeaSide一直没有动摇(不得不服啊)!我当时就感觉应该是有个比较简单的方法就能达到挺好的效果,于是果断加大了规则预测的权重,果然成绩缓慢回升。但是换数据后总共也只有7次验证机会,一来我也想不到其它优化方向了,二来也不敢做大幅度的调整怕浪费验证机会,所以每天基本上只是画几个之前提交成绩的曲线,用肉眼看一下跟几个base model的差别,调整下模型融合参数就提交了。一直到最后成绩也没有再次大幅提升。
比赛打到这里,其实选手们也应该都看出来这个赛制的一些缺陷了。根据换数据后的表现,个人感觉除了前十的少数几支队伍,模型的泛化能力其实都差不多……这时候拥有更多次验证机会就显得尤为重要了。所以嘛,能分开组队的就尽量单独组队,如果是同个学校的可以多互相交流下,看看几个方向是不是已经有人试过了,都能很好地提升最终成绩。如果天池能像Kaggle那样leader board分public和private,整体的赛制会合理很多。换数据本身应该是想比拼真正的泛化能力,但是换数据后还能提交多次,那绝对是拉大了这种多次验证机会所能带来的收益啊。
赛制归赛制,我等newbie跟天池老炮们在实力上的差距还是很明显的,尤其是跟第一梯队中的神牛们!非常好奇SeaSide到底是用了什么魔法能从比赛中期就占领榜首,任凭刮风下雨换数据都毫无动摇直至比赛结束。也很可惜拿过两次冠军的MD大叔,以极少量的提交就到了第六,但没能进入最终答辩,不知道还有没有机会听到大叔的分享。
后记
总结下整个比赛经过,从各个方面都展现出了我的各种缺点……最要命的还是基础的分析技能比较差,很多时候有了评估结果也不知道进一步的优化方向。基本上是一直在堆feature,依靠GBRT良好的容错度撞大运。有了这次经验,以后学习的时候可以更有方向性一些。之前自学上课时很多一知半解的内容,也逐渐在比赛中反复思索有了更深入的理解。
最后要祝贺下进入答辩的大牛们,期待你们的分享!也希望以后天池的比赛也能不断改进,越办越好,真正成为众智创新的第一平台!
照例附上一些资料链接:
应用傅立叶级数分析周期性时间序列:
时间序列的干预分析模型:
arxiv上用DRNN做预测的论文:
使用nearest neighbor做时间序列预测:
Box-Jenkins大牛经典著作(其中就有一章讲了个机场的例子,我激动的看了半天):
天池的答辩视频集合(之前的公交预测比赛跟这次机场预测有点类似):
读完点个赞呗!
以上是关于如何在第一次天池比赛中进入Top 5%?开发工程师初试数据挖掘大赛(下)附学习资料的主要内容,如果未能解决你的问题,请参考以下文章