数据挖掘:聊聊那些年你我踩过的“坑”
Posted KPMG大数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘:聊聊那些年你我踩过的“坑”相关的知识,希望对你有一定的参考价值。
题记
半亩方塘一鉴开,天光云影共徘徊。 问渠哪得清如许,唯有源头活水来。
——朱熹
Intro
矿工一枚,有太多的故事(眼泪)想要与大家分享。今天就来谈一谈数据挖掘中常常被我们忽略的小问题(踩过的坑)。
让我们从下面这张图开始吧!
图一 从现实世界到模型世界(图片来自网络)
咳咳注意,本篇不是八卦文,在这里我们要正经地讨论一些小case。如图所示,我们以左图代表现实世界,右图代表模型世界——对,数据挖掘的世界。从左至右的转换虽合情合理(技术上能够实现),又有微妙的不同——是不是更美啦?合情合理是说我们的空间映射不能脱离实际,美颜也要在一定的框架之下,要有技术能够实现。微妙的不同在于,我们常常习惯于这样的美,习惯于用这种方式来解决现实世界的问题(如果生活在唐代,我们可能有不同的解决问题的方法,哈哈)。可能有同学要问,干嘛大费周章,直接在现实世界解决问题不就OK了吗? 然而现实情况是,大部分情况下这样并不能解决问题,甚至很多时候,我们不能得到如左图那样完整的数据。由于这个原因,我们的模型世界异彩纷呈。这个问题太大,之后再讲吧。本着主旨,我们来看看怎么对现实世界进行分析挖掘。
数据挖掘流程概览
首先,数据挖掘遵循着一整套标准开发流程,其中应用较广的是跨行业的CRISP-DM (Cross Industry Standard Process for Data Mining) 标准,以及SAS的SEMMA (Sample,Explore,Modify,Model,Assess) 流程标准。相对来说CRISP-DM应用范围更广一些,如下为CRISP-DM流程图:
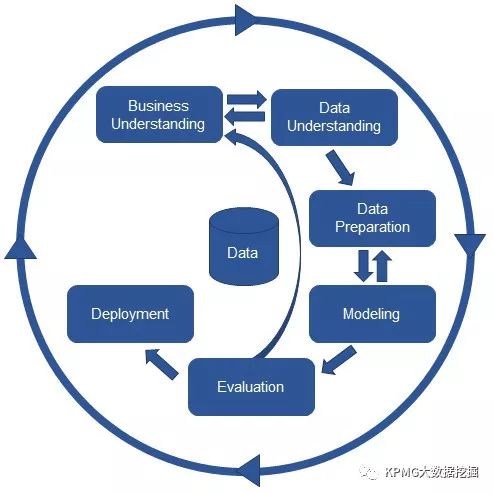
图二 CRISP-DM流程图
CRISP-DM的成功之处在于它是面向数据挖掘项目开发的,并且与行业、背景、数据挖掘工具无关。它可以将整个数据挖掘过程同标准的业务过程相结合,把具体的业务目标映射为数据挖掘目标,从而保障数据挖掘的结果能更好地指导业务决策。
接下来,我们会顺着CRISP-DM流程来挖一挖有哪些坑是我们会不小心掉进去的。
数据挖掘小坑集锦
流程之业务理解
在业务理解阶段,我们实现了或者说需要实现现实世界到模型世界的变迁。我想美,这是我的目的。但是注意——坑来了。
在实际情况中,我们常常遇到的坑是"我想美",即只有一个宏大的愿望,却没能从现实世界中提炼出真正能够落地的地方。比如说,我想要"脸"变得好看些,那么,现实中你需要有"脸"才行啊。这一部分往往不被重视,我是有"脸"的人啊,变美就成。
坑一:业务目标不明晰
美有多种,一定要足够具体,明确客户真正想要达到什么目标。如果是多个目标,且存在互斥关系,如何进行排序取舍? 按照什么标准来执行? 只能美"脸"么? "头发" 能不能做一下呢? 这一坑,有时好过,有时真不好过,认真对待总是对的。
坑二:环境评析不深入
环境评析,是对业务目标的执行与展开。美“脸"可以,有工具么? "脸" 能够给提取出来吧? 是否需要美容专家来指导指导? 这个坑,其实并不大,因为在现阶段大部分情况是"脑袋决定屁股"的嘛。往往是人员、数据、工具等齐全了,领导们觉得是不是得做点什么东西出来了呢? 可能这一点表述的不够严谨,欢迎拍砖。这一坑,要求人员能够胜任评析的工作,能够看出脸的哪部分是哪部分; 要求"脸"足够丰富,能够支撑得起后续的整容计划; 要求工具得当,使得顺手。总体来说,此坑必填才能顺利地将项目进行下去。
坑三:实施计划跟不上变化
基于对环境的评估,以及对业务目标的理解,我们终于能够明确一个还算靠谱的挖掘目标——把脸优化为瓜子脸。于是,我们制定了详细的实施计划,准备大干一场。这一坑,现阶段是开挖了,也填不上,需要在以后阶段逐步cover
流程之数据理解
基于业务理解,在数据理解阶段,以初步数据收集开始,检查数据的可访问性和解决具体的业务问题的充分性,接下来进行一些活动,目的是熟悉数据,识别数据质量的问题,从而获得关于数据的第一手信息,发现有趣的子集,形成对隐含的信息的假设。如图一左图所示,是真正开始进行脸的"抽取"了,为了实现目标,需要结合专家人员的知识,抽取相应的组织数据,如脸部分的明细数据,脸表皮层数据,脸真皮层数据,脸皮下层数据等等,甚至为了整体上的协调,会抽取整体轮廓数据等。这一过程,是业务理解中环境评析的深入与综合。
坑一:原始数据收集困难
为了实现美颜的目的,需要非常多的数据支撑。现实中,可能由于种种原因,有一些关键数据不能够收集。这一坑,有着十分现实的硬约束,比如你就是不能收集客户的隐私信息或者不能得到各国CDS证券的历史交易信息等。这一硬约束,除非通过其它变通的方式来解决,要不就是无解的。
坑二:原始数据重叠
与坑一相反,这个坑恰恰是我有更多的原始数据,但是,数据口径并不统一,如何整合它们将是一个新的难题。如果专家人员能更多地参与和梳理,此坑往往是能够解决的,但也是一个需要耗费相当多人力物力的过程。日前,《银行业金融机构数据治理指引》则明确地表明数据是需要精心“呵护”的。
坑三:以抽样代总体
流程之数据准备
基于对数据的理解与洞察,我们开始了原始数据构造最终数据集(将要输入建模工具的数据)的活动。抽取相应的组织数据,并不能够直接地堆砌,直接堆砌还是现实世界,要达到模型世界,还需要较多步骤的转换才成。看坑。
坑一:重抽样的问题
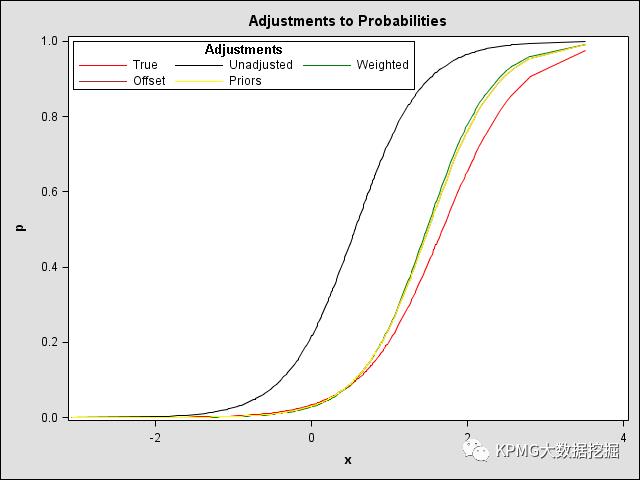
在风险欺诈领域,坏样本总是非常稀少,为了对坏样本有一个较好的拟合,往往会人为增大坏样本的比重。但是调整完样本之后,能够直接应用么? 这个坑,也不太明显。通常情况下,在关注排名的领域是可以的,而在关注实际发生率,如诊断医学、保险学领域则容易犯错。请看下图。在增加调整项和不增加调整项情况下,模型拟合的结果与实际结果有比较大的差别。具体实例请参考SAS官方链接http://support.sas.com/kb/22/601.html。
坑二:变量编码的问题
在进行空间映射时,免不了进行各种变换,其中比较常用的是哑变量转换——dummy coding。而有些软件如SAS会支持进行另一种转换----effect coding。两种转换方式对结果的正确性是没有影响的,但有时候进行数据验证,比方看OR值,使用系数来进行验证,会发现对不上号。这个坑还是比较隐含的,但也需要有清晰的思考。
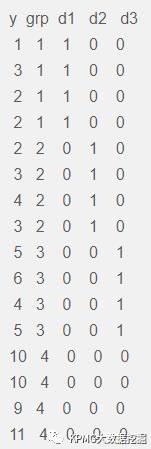
示例: 原始数据

示例:基于数据的dummy coding
如上为对4组水平进行的观测结果,进行哑变量编码如下:
回归结果: F(3, 12) = 76.00 P = 0.0000 R-squared = 0.95
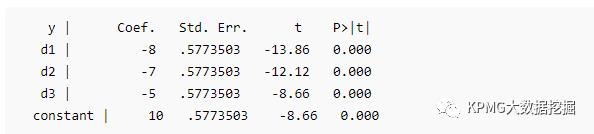
示例:基于数据的effect coding
回归结果: F(3, 12) = 76.00 P = 0.0000 R-squared = 0.95
嗯,聪明的小明已经发现了端倪,你看到了什么呢?
坑三:目标变量问题
在进行监督型模型训练时,目标变量的确定,直接关系到最终模型的效果。这里也有一些小坑——目标变量能否反映问题的实质? 数据准备过程中,是否加入了噪音? 在模型影响因素的选择中,是不是有一些特征是根据目标变量衍生出来的(即以目标预测目标)?此坑虽小,往往在模型开发大半才会发现,不得不引起重视。
流程之建模
相较来说,建模阶段是最复杂的,但坑其实没有那么大,有以下需要关注的地方。
坑一:建模的技术选择
经过以上淬炼,我们终于打造了图一右侧完美的脸庞,现在是时候回归到左侧了。R U Kidding Me? 并没有。模型世界或模型空间,只是我们解决问题的手段而已,现实世界才是我们最终的关注点。完美的脸庞(模型)有助于我们进行对问题的求解。现实生活中,很难判断一个人违约率有多高,但是,在模型世界,我总能够给出一个相应的评分来估计出这个人的违约概率。那么坑在哪里呢?(张望脸)
有坑的地方在于技术选择时需要考虑模型的假设条件,只有相匹配的假设,模型才能发挥出最大作用,也才能对现实进行更深入的刻画。这个坑,通过对技术的深度掌握和多多实践即可解决,不再赘述。
流程之模型评估
在这个项目阶段,你已经构建了一个(或多个)从数据分析的角度来说看上去质量较高的模型。在进行模型的最终部署之前,一定要确定它正确地反映了业务目标。关键的目标是否有一些重要的业务问题没有充分考虑到,让你必须返回到业务理解阶段呢?这个阶段的最后,还应该确定使用数据挖掘结果得到的决策是什么。这一阶段有非常多的评估指标可供选择,可以进行多模型的比较,通常来讲,也没有太多坑。如果有,就是选择指标进行评估时,是否合理,有没有考虑到稀疏数据的问题。
流程之模型部署
在创建模型过程中获得的知识可以被组织起来并以用户能够使用的方式将其呈现。数据挖掘解决方案必须像简单的静态报表一样部署给决策者,或直接写入现有的数据库(数据库评分)。模型的建立通常并不意味着项目的结束。尽管模型的目的是为了提升数据的知识力,但获得的知识需要被组织和表示成用户可用的形式。这常常与包含能支持公司决策的“现场”模型(“live” models)的使用有关,例如,Web 页面的即时个性化服务或者销售数据库的重复积分等。然而,与具体需求有关,部署阶段可认为是与生成一份报告一样简单,或者认为是与实施一个覆盖整个企业可重复的数据挖掘过程一样复杂。
坑一:部署环境问题
这是一个比较常见的问题。在我们辛苦开发后,模型能够较高地反映现实世界了,正准备高高兴兴地大规模应用,却发现开发模型的环境与线上部署的环境不同。这个坑没有行之有效的方法,需要按照线上环境再次进行模型训练。有效规避的方法是提前交流线上的部署环境和应用问题。
坑二:指标稳定性问题
指标稳定是模型能够正确预测的关键,进行稳定性的监控是很有必要的,能够提前发现哪些因素发生了变化,变化的趋势是什么,通常我们使用PSI来进行指标稳定性监控。提示这个坑,是要大家关注模型的后续运行,这一点经常会被忽视。
坑三:预测区分度问题
同样,指标稳定并不表明模型依然有效,关注预测的区分度也是十分必要的。如果指标稳定,但是预测的能力有比较大的折扣,则需要关注是不是业务发生了新的变化,这一变化是否是长期的。提示这个坑,是要大家关注模型的后续运行,这一点也经常会被忽视。
数据挖掘填坑指南
以上基于CRISP-DM通用数据挖掘流程简单总结了一些挖掘过程中会被忽略的问题,并给出了填坑指引。限于篇幅与笔者能力所限,肯定不够全面,望大家指正。
END
以上是关于数据挖掘:聊聊那些年你我踩过的“坑”的主要内容,如果未能解决你的问题,请参考以下文章