浅谈数据挖掘在信用评估中的应用
Posted 66号学苑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈数据挖掘在信用评估中的应用相关的知识,希望对你有一定的参考价值。
信用风险是金融风险管理中的一个热点问题,是指借款者(或债务人)未能满足合同要求而给贷款者(或债权人)带来经济损失的风险。众所周知,数据是对风险进行有效、准确量度的关键因素,特别是信息技术和互联网的发展,金融风险管理对海量数据的依赖越来越大。
对于金融企业来说,大数据可以解决由信息不对称带来的营销、定价、欺诈、信用等问题。与传统的信用风险分析相比,大数据背景下的金融信用风险分析最根本的创新在于使用了大量的非金融数据进行建模。在大数据背景下,金融数据挖掘的数据来源主要有四类。
什么是数据挖掘
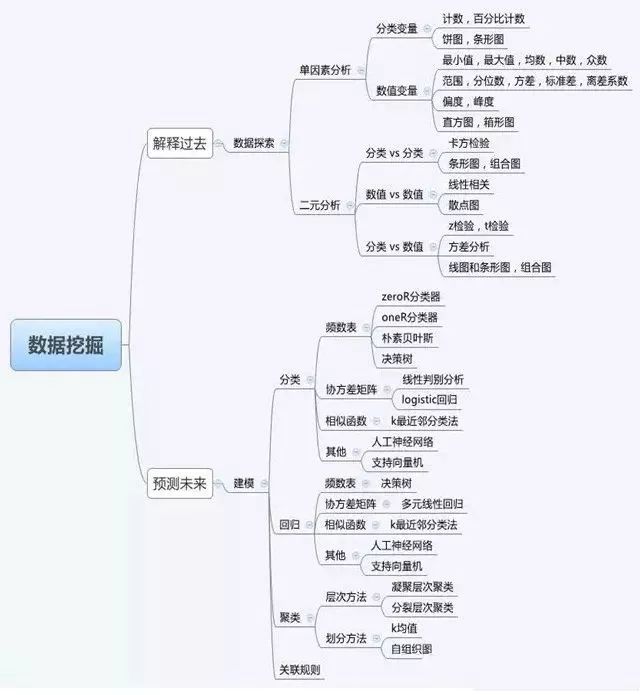
数据挖掘是指从海量数据中发现和提取以前未知的、隐性的、有用的信息形成知识,并用它来支持关键的商业决策的过程。
数据挖掘的另一个名称为数据库中知识发现,即将数据从数据库中提取并经过一定格式的转换,从中发现有用的知识的过程。
就金融领域银行业应用数据挖掘技术来看,通过对海量的业务数据进行处理和分析,掌握其数据规律和模式,然后发现某个客户或者消费群体的消费习惯和兴趣,从而预测其未来需求情况。我们也可以通过对大量贷款客户的信息进行分析归类,发现其违约背后的数据规律和模式,从而进行信用风险评估和预测。
数据挖掘流程
数据准备阶段、数据挖掘、结果评估、应用,以促进挖掘目标的实现(如下图所示)。
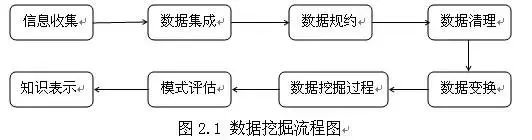
(1)信息收集:根据确定的数据分析对象,抽象出在数据分析中所需要的特征信息,然后选择合适的信息收集方法,将收集到的信息存入数据库。对于海量数据,选择一个合适的数据存储和管理的数据仓库是至关重要的。
(2)数据集成:把不同来源、格式、特点性质的数据在逻辑上或物理上有机地集中,从而为企业提供全面的数据共享。
(3)数据规约:如果执行多数的数据挖掘算法,即使是在少量数据上也需要很长的时间,而做商业运营数据挖掘时数据量往往非常大。数据规约技术可 以用来得到数据集的规约表示,它小得多,但仍然接近于保持原数据的完整性,并且规约后执行数据挖掘结果与规约前执行结果相同或几乎相同。
(4)数据清理:在数据库中的数据有一些是不完整的(有些感兴趣的属性缺少属性值)、含噪声的(包含错误的属性值),并且是不一致的(同样的信息不同的表示方式),因此需要进行数据清理,将完整、正确、一致的数据信息存入数据仓库中。不然,挖掘的结果会差强人意。
(5)数据变换:通过平滑聚集、数据概化、规范化等方式将数据转换成适用于数据挖掘的形式。对于有些实数型数据,通过概念分层和数据的离散化来转换数据也是重要的一步。
(6)数据挖掘过程:根据数据仓库中的数据信息,选择合适的分析工具,应用统计方法、事例推理、决策树、规则推理、模糊集,甚至神经网络、遗传算法的方法处理信息,得出有用的分析信息。
(7)模式评估:从商业角度,由行业专家来验证数据挖掘结果的正确性。
(8)知识表示:将数据挖掘所得到的分析信息以可视化的方式呈现给用户,或作为新的知识存放在知识库中,供其他应用程序使用。
数据挖掘的三种方法
分类回归树
分类回归树是基于统计理论的非参数的数据挖掘技术。基本思想是从根节点开始采用自顶向下的(Top-down)的递归方式在每个节点上对样本集按照给定标准选择分支属性,然后按照相应属性的所有可能取值向下建立分支、划分训练样本,直到一个节点上的所有样本都被划分到同一个类,或者某一节点中的样本数量低于给定值。其特点是在计算过程中充分利用二叉树的结构,即根节点包含所有样本,在一定的分割规则下根节点被分割为两个子节点,这个过程又在子节点上重复进行,成为一个回归过程,直至不可再分成为叶节点为止。
贝叶斯(Bayes)判别分析方法
贝叶斯(Bayes)判别分析方法是在信用评分模型中常用的统计方法。其思路是基于贝叶斯统计理论,根据已获得的每个类别的样本数据,分析并总结客观事物分类的规律性,建立合适的判别函数,然后利用判别函数对新样本所属类别进行判定。
神经网络
神经网络是对人脑或自然的神经网络结构和功能的抽象和模拟,主要由输入层、隐藏层和输出层构成。BP神经网络的主要思想是采用Delta学习规则的权值修正策略,把学习的过程分为两个部分,一部分是信息流经过输入和隐含层的处理计算输出,另一部分是利用输出层误差估计前一层的误差,再用这个误差估计更前一层的误差,形成误差值的反向传播,借此调节网络的权重。
数据挖掘在信用评估中的应用
信用评价模型运用数据挖掘技术,通过对客户基础信息、消费费行为、社交行为、社会信用信息等大量历史数据进行系统性清洗与分析,挖掘数据中蕴含的行为模式及信用特征,捕捉历史信息和信用表现的相关性,以信用评分来综合评估客户的信用表现,结合历史信用分进行信用预测。
数据来源主要包括几部分:
一是用户申请时提交的数据信息,如年龄、性别、籍贯、收入状况等,这些数据可以了解用户的基本情况,验证用户的身份;
二是用户在使用过程中产生的行为数据,包括资料的更改、选填资料的顺序、申请中使用的设备等,可以通过用户的行为来进行特征挖掘;
三是用户在平台上累积的交易数据,如果公司运营比较久的话,可以累积比较多的用户借款相关数据,这类数据对于判断用户信用会有很高的价值;
四是第三方数据,包括来自政府、公用事业、银行等机构的数据,以及用户在电商、社交网络、网络新闻等互联网应用上留存的数据。这类数据可以从多角度展示用户的特征,利用这些数据进行建模分析,可以找出不同特征与信用水平之间的相关性。
信用评分是一个基于统计和数据挖掘研究方法的分类过程。一直以来,判别分析和线性回归是构建信用评分模型应用最广泛的技术。除此之外,还有Logistic回归、概率单元分析、非线性平滑方法特别是K-临近值、最优化理论、马尔可夫模型、递归划分、专家模式、遗传算法和神经网络等。
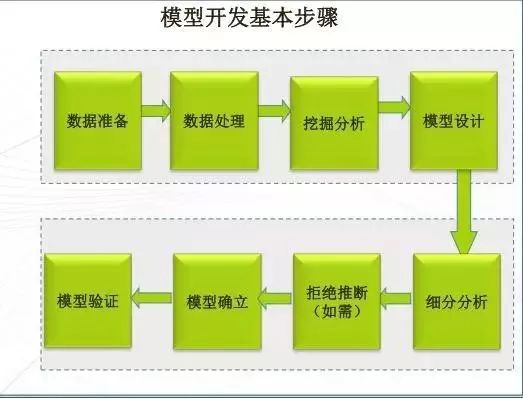
构建一个信用评分模型,首先获取申请人相关数据,接着对信息进行量化处理,然后选用合适的数据挖掘技术,建立信用评分模型,对数据进行分析验证,得出客户的综合信用评分,设定一个合理的阈值,判定客户是否通过申请。其流程如图所示。
数据挖掘在信用风险管理中的效用分析
1.适合非线性特征数据的描述
传统的信用风险分析方法所选取的数据指标一般用于线性的分析,而实际信用风险状况却不是如此。数据挖掘的很多方法适合描述非线性的信用风险状况, 突破了传统线性分析的局限。
2.能够多层次多角度的挖掘信用风险数据
客户的信用状况分析需要借助多维度的数据项进行综合分析,如何分析这些因素之间的相互关联性以及对借款者信用水平的影响程度,是传统分析无法解决好的。通过数据挖掘,我们可以实现多层次和多维度的对数据进行综合分析,揭示信用风险的影响因素。
3.可以提高信用风险计量的准确性
信用风险计量需要基于多维度的海量数据,传统的信用风险定量分析在面对日益复杂的信用环境时会受到许多主观因素的影响,大大降低了分析的准确性。数据挖掘借助多种分析方法如关联技术、聚类分析、神经网络等都可以很好的适应非线性的函数分析,避免分析受到主观因素的影响,提高了风险评估的准确性。
4.数据挖掘工具能够全面的展现信用风险分析结果
数据挖掘工具可以实现任意维度层次、任意维度次序、任意维度反向的数据结果展示,给决策者提供全面清晰的决策依据。
来源|风控命门
更多精彩,戳这里:
以上是关于浅谈数据挖掘在信用评估中的应用的主要内容,如果未能解决你的问题,请参考以下文章