投稿一千,录用「百」篇,数据挖掘顶会ICDM 2019顶会反映了哪些研究趋势? Posted 2021-04-27 AI科技评论
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了投稿一千,录用「百」篇,数据挖掘顶会ICDM 2019顶会反映了哪些研究趋势?相关的知识,希望对你有一定的参考价值。
作者 | Camel
编辑 | 唐里
数据挖掘领域的学者们在过去的9天里,纷纷相聚在北京国家会议中心。
从11月3日到7日,举办了CIKM 2019会议(相关报道参阅《CIKM投稿数量1700篇,图神经网络成热门方向,最佳论文纷纷进行图研究》),紧接着从11月8日到11日,在同一地点又继续举办了数据挖掘顶会ICDM 2019 。两个会议同为CCF列表 B类,其区别在于前者是ACM举办,而后者是IEEE举办;此外CIKM覆盖范围更广,包括了数据库、信息检索和数据挖掘三个领域,而ICDM则更为专注数据挖掘。
IEEE ICDM 会议首次举办于2001年,至今已经是第 19届会议。而作为会议的发起人、数据挖掘领域领军人物吴信东教授则从会议之初一路相随,ICDM国际会议举办地辗转十个国家之后终于来到中国,而吴信东也当之无愧与Granada大学的Francisco Herrera共同担任大会主席,大会的组织则由清华大学和吴信东担任科学院院长的明略科技共同承办。
本次会议共包含了 3 个主旨报告,3 个 tutorial, 6 个特邀工业报告,1 个关于“营销智能”的 pannel 以及 34 个 session。
ICDM从诞生之日起便以录取率低著称,今年也不例外
。ICDM 2019 共收到来自56个国家和地区的1046篇投稿,而仅有95篇(9.1%)被录为regular papers,在此之外还录用了99篇的short papers,才把总录取率提升到18.5%。需要提及的是这1046篇投稿中有2/3的论文第一作者都是学生,且今年是ICDM接收论文数量首次突破一千(去年为948篇)。
注 :short paper 指一些篇幅比较短(一般是4页以下),内容比较少但是具有一定的原创型和新颖性的文章。 regular paper(长文章)是指内容充实,研究比较完整,分析比较充分的文章,文章的篇幅比较长,一般都在10页左右,甚至更长。
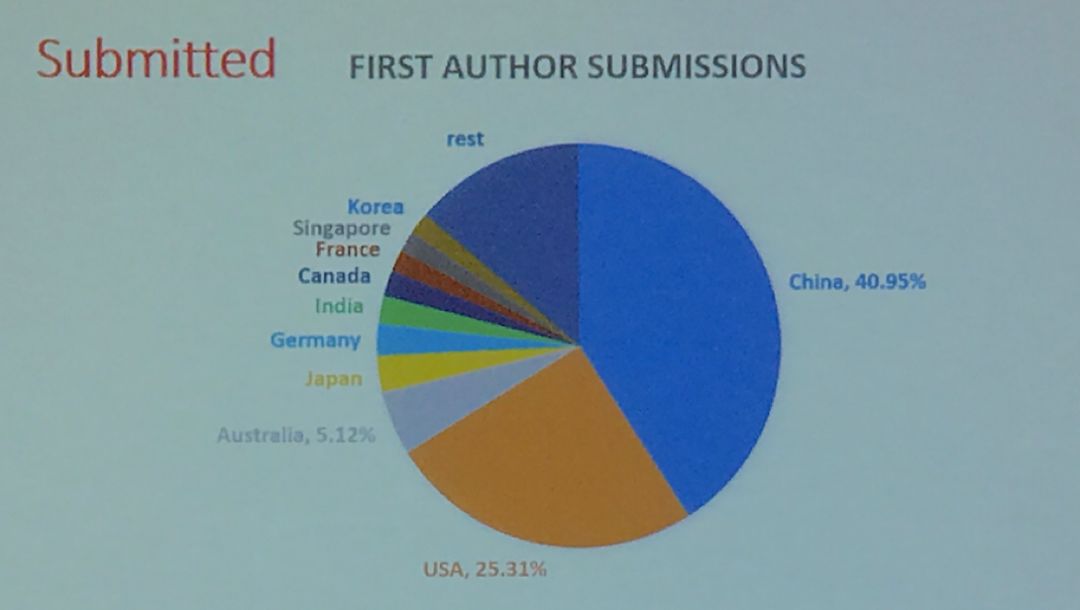
当然组委会也以国籍对投稿论文做了分析,其中
40.95%的来自中国
,而有25.31%的来自美国,其次则是澳、日、德、印、加等国家。国内投稿如此多的原因,一是中国各高校和研究单位在数据挖掘领域本身就比较强;二是会议在国内开,中国的师生投稿和参会的成本相对较低,而美国的学者则更愿意去投SIGKDD等会议。
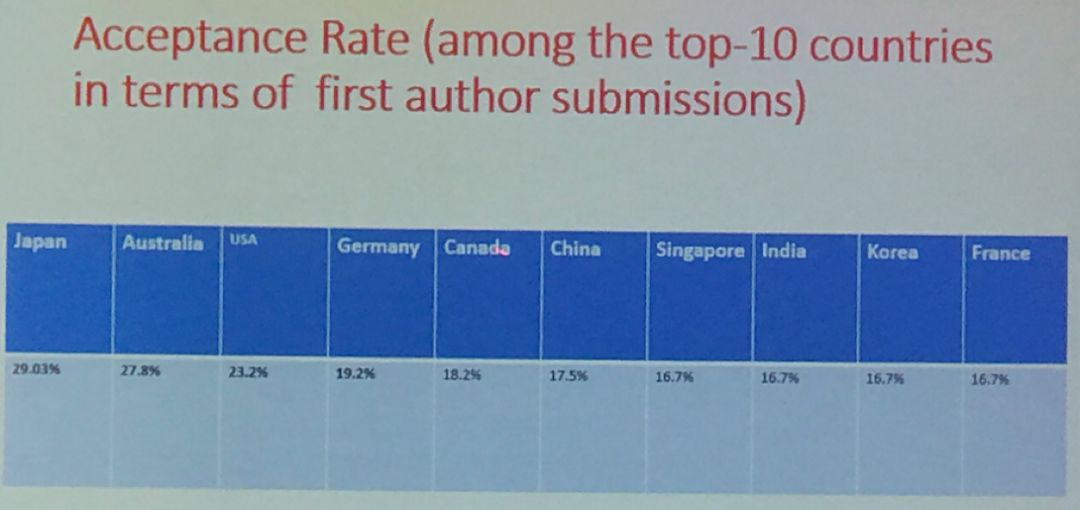
不过,从录取率来看,来自中国的论文平均录取率只有17.5%,相比美国的23.2%、澳大利亚的27.8%以及日本的29.03%则有不小的距离。这说明啥? 离家近了,投稿的胆子也变大了。
最终中国还是胜在了基数大。据吴信东教授介绍,在所有录取的194篇文章中,
其中有74篇来自中国,62篇来自美国
;也即有70%的录用文章是被中美两国所瓜分。
根据录用时的平均最高分以及组织会的投票选择,本次会议的
最佳论文奖获得者授予给了来自GeorgeMason大学的Xiaojie Guo,Liang Zhao等人,而最佳学生论文奖则由Michigan大学的Mark Heimann等人摘取。
补充一点,本次会议还授予了研究贡献奖、10年最具影响力奖、李涛奖。研究贡献奖的获得者是来自斯坦福大学的JureLeskovec教授,他也是ICDM 2010最佳应用论文奖的获得者;而获得10年最具影响力奖的论文是由 Steffen Rendle发表在2010年的论文(Factorization Machines ICDM’10, pp.995-1000);李涛奖是为了纪念数据挖掘领域著名学者李涛,该奖项于去年设立,今年的获奖者为UIUC的华人学者
Hanghang Tong
。
对于投稿分析还有一个比较重要的便是话题分析,组委会对不同的领域投稿做了排序。从下图可以看出
“在传统领域对新数据进行挖掘的算法”和“网络环境的挖掘和关联分析”两年连续霸榜
,其他则都稍有变动,这种分析在一定程度上也反映了数据挖掘领域的主流和新趋势:主流的依旧是主流,新趋势则在上升或下降。
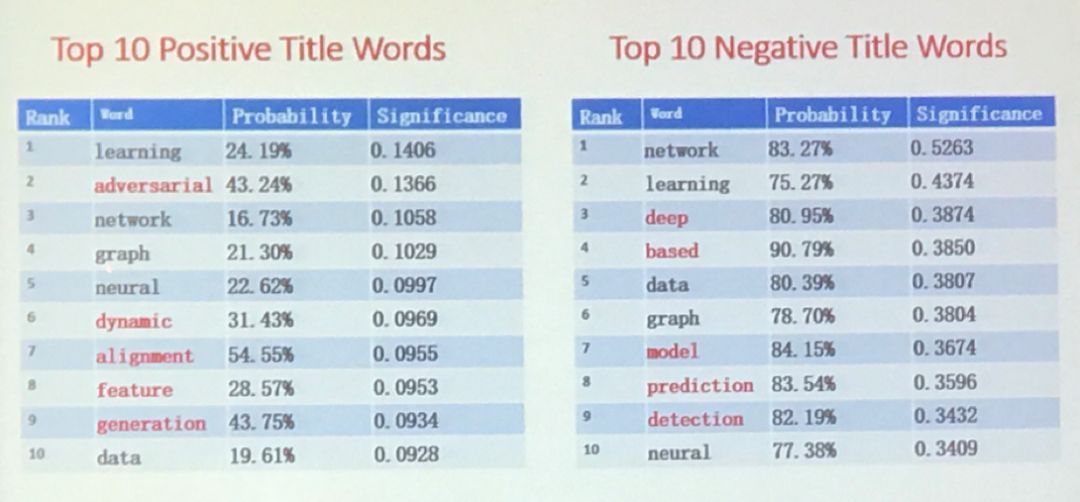
投稿中,尤为关键的一个角色便是审稿人,审稿人的喜好也决定了论文的录取情况。组委会为了分析本年度审稿人的喜好,也尝试了对标题词进行分析,计算方式如下所示:
可以看出标题中带有 adversarial、dynamic、alignment、feature、generation等词汇时论文更容易被录取,而标题中带有 deep 、based、model、prediction、detection等词汇的论文杯具的概率就比较大了,
特别是带有based的论文杯具率达90.79%。
你能从这个标题词汇正、负率中推测出审稿人的喜好是什么吗?
本次大会邀请了数据挖掘的巨擘UIUC的韩家炜教授、IBM研究院的Ronald Fagin以及康奈尔大学的Joseph Halpern做大会主旨报告。
韩家炜的报道主题是Embedding-Based Text Mining: AFrontier in Data Mining。我们对韩家炜以往的研究已经做过详细的报道;而Embedding则是韩家炜近来研究的一个重要方向,在CIKM和ICDM两场会议中,韩教授都详细介绍过他们实验室近来在Embedding方面所做的工作《
Spherical Text Embedding
》,且相应的工作已经发表在NeurIPS 2019。
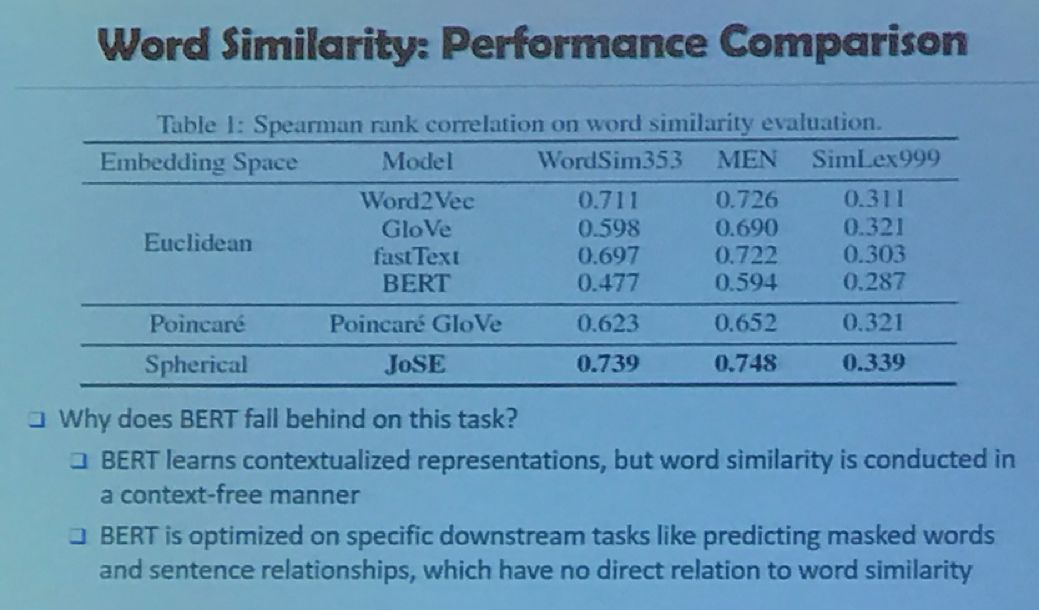
比较有意思的是,据他的学生透露,这篇文章是韩家炜教授本年度最喜欢的一篇工作,但很不幸在最初投稿时却被拒了,因为没有和最近的显学BERT进行比较;随后韩家炜等人做了比较,充分证明并分析了BERT在词相似等任务中确实不如Embedding,如下图所示:
让笔者感到极为佩服的是,作为数据挖掘领域的泰斗,从3日的CIKM一直到11日的ICDM结束,韩家炜教授每天都会去会场参会,让吾等去一天休三天的年轻人汗颜。
Ronald Fagin是IBMFellow(这个Fellow是IBM的最高荣誉,现在全世界范围内也就100位,这可是从IBM 在全世界40万雇员中选出的哦,而且整个历史上总共也就大约250名)。
他在ICDM上的演讲主题为“Applyingtheory of data to practice”,具体来讲就是讲了两个IBM的研究案例。第一个是Top k问题的算法研究,Ronald在报告中提供了一种最优算法,只需要10行就可以解决这个问题;这个算法也获得了2014年的哥德尔奖(理论计算机科学中的最高奖),这个问题是由实践中逐渐提出的,最终却获得了理论界的最高奖项。第二个则是从理论层面提出的问题,即数据交换,本质上来说就是将数据从一种格式转换为另一种格式,但其中实践上的复杂的问题却让数据交换成为一个新的子领域,甚至有专门的会议。Ronald在这里想要强调的就是:理论家一定要和实践家共同起来工作,反之亦然,这样
两种类型的学者共同受益。
康奈尔大学的Joseph Halpern演讲的非常理论,主题为“Actual Causality”。事件C“实际引起”事件E是什么意思?这是Joseph提出的问题。
在报告中,Joseph分析了自亚里士多德、休谟等哲学家对因果关系的分析,他认为许多定义都是根据反事实提出的。(如果C没有发生,那么C就是E的原因,那么E就不会发生。)2001年 Joseph等人提出了一种新的实际原因定义,使用结构方程概念对事实进行建模。由于内容太过抽象,笔者在此就不再详细介绍,
对此感兴趣的读者可以在「AI科技评论」微信公众号回复「Joseph」查看PPT照片
。
值得一提的是,在本次会议中几位赞助商也获得了工业报告的机会。
明略科技在吴信东的带领下,目前对知识图谱做的非常深入,徐凯波博士对明略科技的图挖掘技术在公共安全中的应用做了介绍。
叶杰平是滴滴人工智能实验室负责人,滴滴出行副总裁,他在报告中讲述了滴滴出行在交通中如何应用人工智能。
百度研究院资深研究员熊昊一博士讲述了如何使用百度的AutoDL来实现AI的工业化。值得一提的最近百度刚刚发布了最新版的飞桨(PaddlePaddle)框架,而AutoDL正是飞桨里面重要的一个模块。
南京财经大学信息工程学院的曹杰教授讲述了从线上、线下融合的实用数据管理和商业智能的解决方案研究。
来自LinkedIn 的李子博士,介绍了LinkedIn大规模适应端到端的机器学习。他们在LinkedIn上启动了一个名为“生产机器学习”(简称“ Pro-ML”)的程序。Pro-ML使机器学习工程师的效率提高一倍,同时向来自LinkedIn堆栈的工程师开放AI和建模工具。
同盾科技副总裁、人工智能研究院院长李晓林讲述了他们的联邦学习框架(iBond),以及如何用iBond来把数据孤岛连接起来,同时能够保护数据隐私。
本次会议的最佳论文奖获得者授予给了来自George Mason大学的Xiaojie Guo,Liang Zhao等人,而最佳学生论文奖则由Michigan大学的Mark Heimann等人摘取。
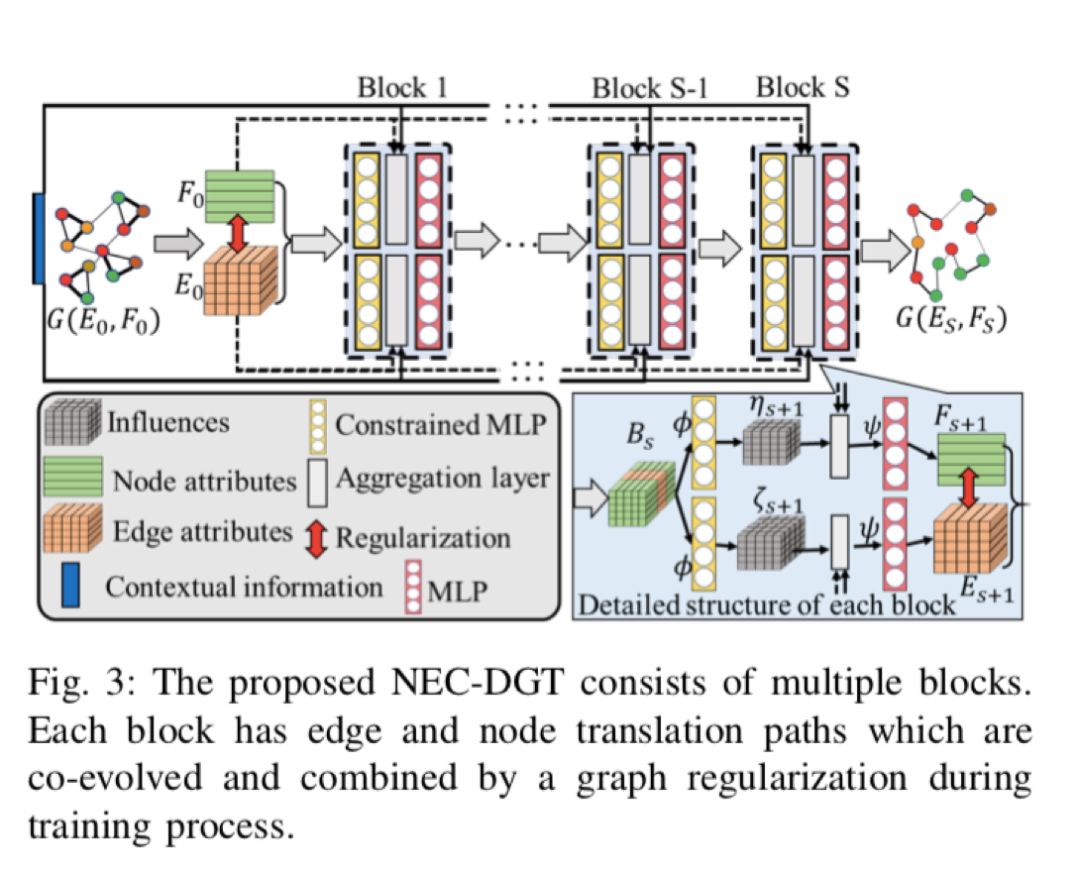
标题:Deep Multi-attributed Graph Translation with Node-Edge Co-evolution
论文链接:http://mason.gmu.edu/~lzhao9/materials/papers/ICDM_2019_NEC_DGT-final.pdf
摘要:图翻译是将图像和语言翻译结合起来的一项研究,其目的是通过限制源域中的输入图来在目标域中生成图。最近,这个话题引起了越来越多的关注。但现有的工作仅限于预测具有固定拓扑图的节点属性,或者仅在不考虑节点属性的情况下仅预测图拓扑,但由于存在巨大挑战,因此无法同时预测它们的两者:1)难以描述交互式,迭代式,节点和边缘的异步转换过程;2)难以发现和保持预测图中节点和边缘之间的固有一致性。这些挑战阻止了用于联合节点和边缘属性预测的通用端到端框架,这是对现实世界应用程序的需求,例如物联网网络中的恶意软件限制以及结构到功能的网络转换。这些实际应用高度依赖于手工制作和临时启发式模型,但无法充分利用大量的历史数据。
在这篇论文中,作者将此通用问题称为“多属性图转换”,并开发了一种无缝集成节点和边缘转换的新颖框架。这里的边缘转换路径是通用的,这被证明是对现有拓扑转换模型的概括。然后,提出了一种基于我们的非参数图拉普拉斯算子的频谱图正则化方法,以学习和保持预测节点和边缘的一致性。最后,作者对合成和实际应用数据进行的大量实验证明了该方法的有效性。
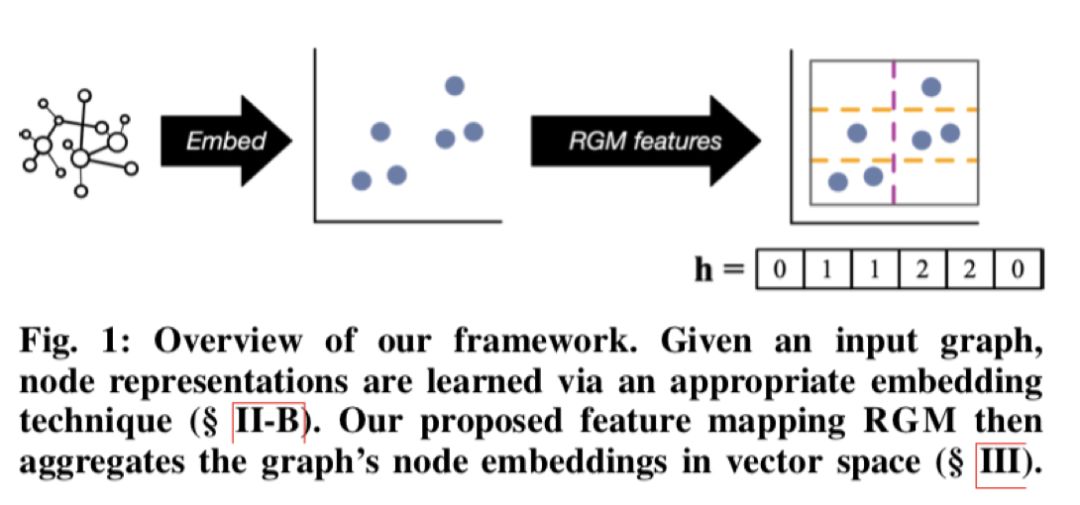
标题:Distribution of Node Embeddings asMultiresolution Features for Graphs
论文链接:https://markheimann.github.io/papers/19ICDM_RGM.pdf
摘要:从生物信息学、神经科学到计算机视觉和社交网络分析,图分类是许多领域的重要问题。也就是说,为了图形分类的目的而比较图形的任务面临着几个主要挑战。特别是,有效的图比较方法必须(1)在表达上和归纳上比较图;(2)有效地比较大图;(3)使用快速机器学习模型进行图分类。
为了解决这些挑战,作者提出了随机网格映射(RGM),这是一种快速计算的特征图,通过其节点嵌入在特征空间中的分布来表示图。作者通过与内核方法的紧密联系来证明RGM的合理性:RGM可证明地近似拉普拉斯内核均值图,并且具有金字塔匹配内核的多分辨率特性。
作者还表明,可以使用Weisfeiler-Lehman框架将RGM扩展为合并节点标签。大量实验表明,使用RGM特征图进行图分类的准确性优于或优于许多强大的图核,无监督图特征图和深度神经网络。此外,在保持高分类精度的同时,将基于其节点嵌入的图与RGM进行比较的速度比竞争基准快一个数量级。
明年ICDM的举办地:意大利的Sorrento——
点击“ 阅读原文”查看 CIKM投稿数量1700篇,图神经网络成热门方向,最佳论文纷纷进行图研究
以上是关于投稿一千,录用「百」篇,数据挖掘顶会ICDM 2019顶会反映了哪些研究趋势?的主要内容,如果未能解决你的问题,请参考以下文章
近期必读的5篇顶会WWW2020推荐系统相关论文-Part2
北理工硕士生「一字不差」抄袭顶会投稿,网友:买论文被忽悠了?
厉害了,网易伏羲三篇论文上榜 AI 顶会 ACL
SIGIR2020推荐系统论文聚焦
重磅 | 数据库自治服务DAS论文入选全球顶会SIGMOD
聚焦计算机视觉前沿,蚂蚁技术研究院4篇论文入选顶会NeurIPS