搜索引擎中的 web 数据挖掘
Posted DataFunTalk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搜索引擎中的 web 数据挖掘相关的知识,希望对你有一定的参考价值。
分享嘉宾:沐沐老师 前百度资深研发
编辑整理:赵丽
内容来源:2019 DataFun Live 11
出品社区:DataFun
注:欢迎转载,转载请注明出处
导读:今天为大家分享的是搜索引擎中的 web 数据挖掘。首先介绍下搜索引擎。实际上,我们每天都会使用的搜索引擎,我们会输入关键词 query 和需求,搜索引擎会根据算法将于 query 最相关且最权威的结果呈现给用户。
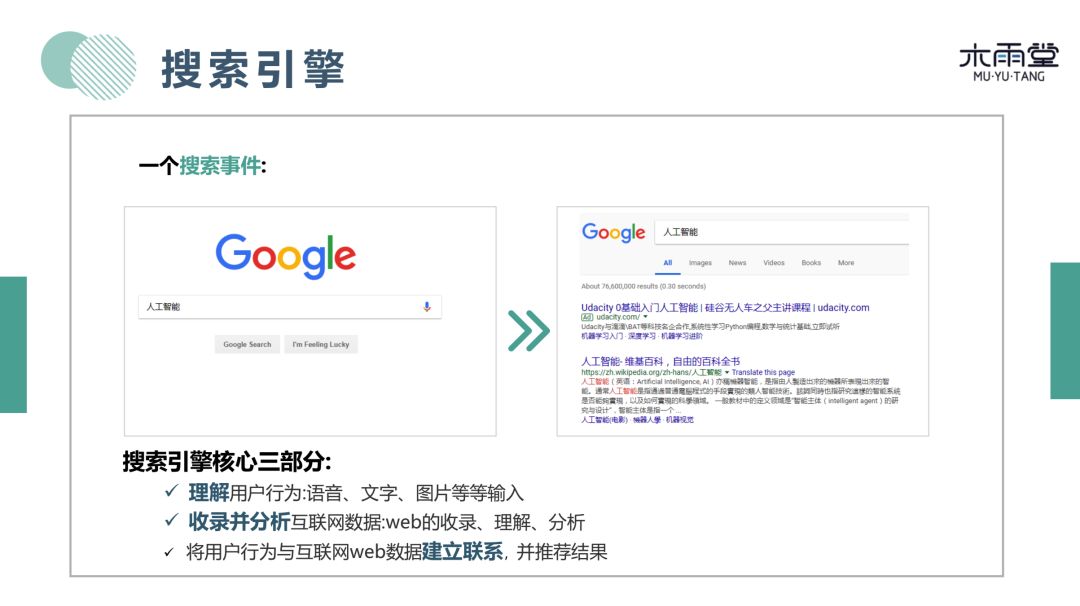
搜索引擎有3个核心部分:
第一:理解用户行为,从最初文字输入到语音和图片输入。
第二:收录并分析互联网数据。
第三:将用户行为与数据建立联系,为用户推荐结果。
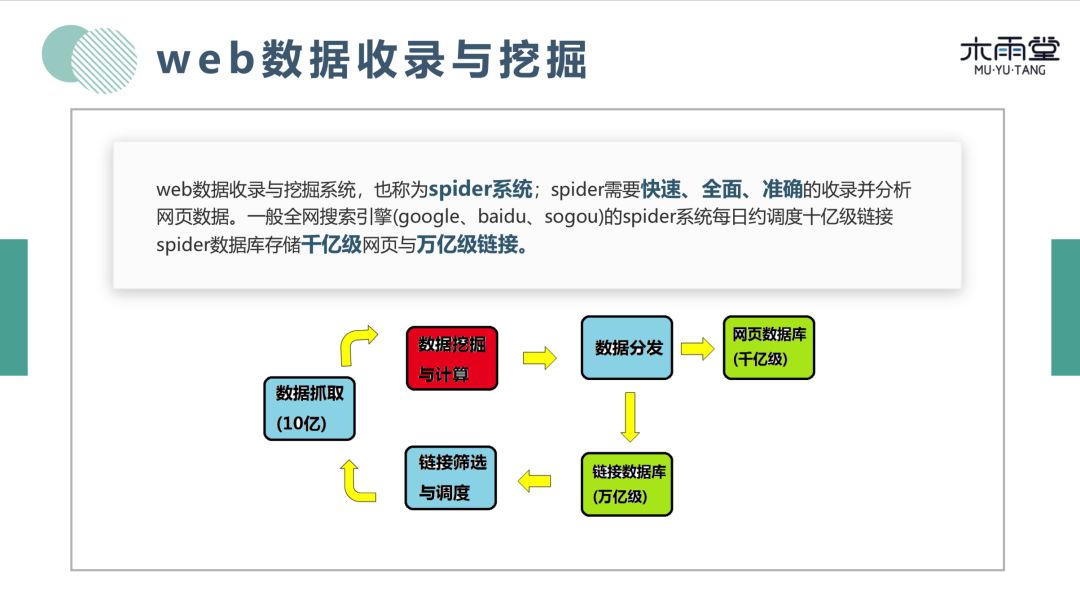
今天主要介绍第二部分内容:互联网 web 数据分析技术。首先看一下 web 数据挖掘与收录系统,也就是 spider 系统。Spider 系统是比较成熟的技术, 目标是:快速、全面、准确的收录并分析网页数据, 一般全网搜索引擎类似 google、百度、搜狗的 spider 系统,每日调度10亿级链接,Spider 数据库存储千亿级网页与万亿级链接。我们可以认为 spider 系统是一个环状的系统,从链接数据库开始,经过相关算法:如链接调度与筛选相关算法,对周期内需要调度的链接进行抓取,然后发给抓取器,进行网页的下载和渲染。然后输入到数据挖掘与计算系统中,对内容进行提取,将网页中的内容保存到内容数据库,链接保存到链接数据库中。我们今天的重点是网页下载之后,网页相关的一些数据挖掘算法。

首先我们看一个例子,互联网用户会浏览新闻、微博等各式各样的网页。我们观察一下网页,思考两个问题,第一个问题,在你观察的网页有什么特征及内容。第二个问题,从整体看来,这是怎样的网页,如何描述这个网页。具体的分析如下:

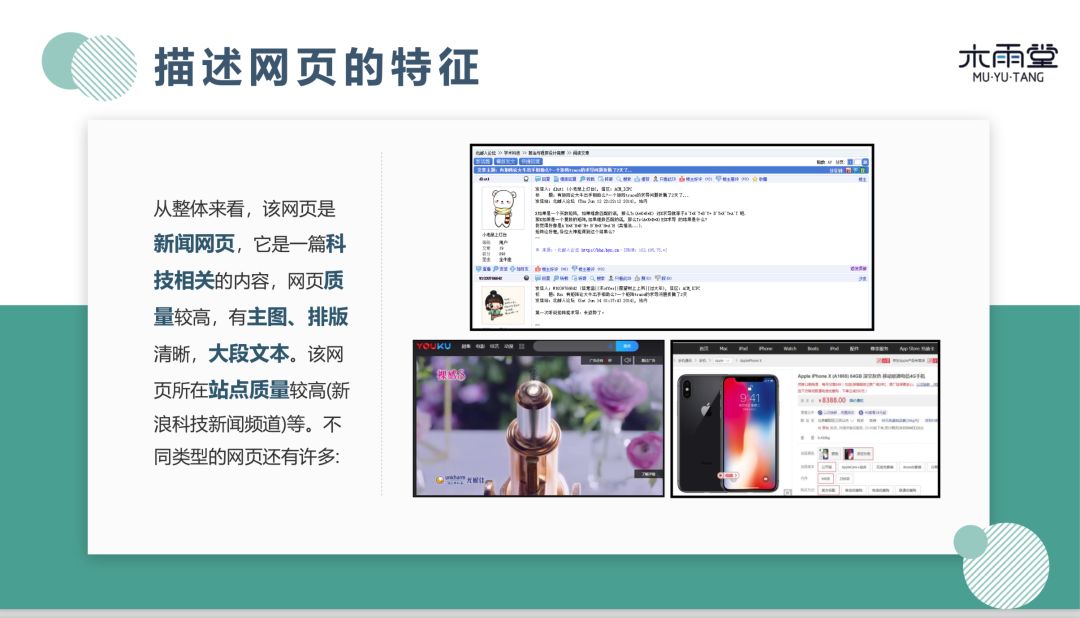
Web 分析技术最核心是对网页特征提取,比如:导航、标题、时间、主图等等。网页内部特征是数据引擎进行排序时用到的关键特征。例如在排序中,时间特征也比较关键,将实效性高且相关网页排在前面。除内部特征之外,还有网页整体特征。我们会用到一些分类和自然语言处理的技术,刚才的例子就是一个新闻网页,内容是科技相关的。会同时计算语义特征和结构特征,例如主图、排版、文本段落等。

Web 数据挖掘中,需要计算并提取网页的百余个网页属性字段,在此之中会使用一些技术,如机器学习的分类、聚类、回归、自然语言处理、规则聚合、主题模型等等。最终的目标是充分的理解网页,为搜索引擎排序提供准确的网页属性。

网页分析用到了许多基础的算法和数据结构。获取网页属性,需要用很多模型计算相应的字段,低层需要构造很多数据结构。了解网页首先需要建立一个 html 树的结构。在这个数据结构中, 如图蓝色的代表标签节点,绿色代表文本节点。文本节点是 html 的内容,内容可以展示在浏览器中。在分析过程中,一些内容比较关键,如标题、超链接与文本内容等相关重要字段。

下面介绍页面分析的一个算法:我们希望充分的理解网页, 在此过程中, 我们可以通过算法划分出不同的区域。如划分为上下左右区域,根据不同的区域提取字段,最终可以对网页进行更深层次的理解,比如说主体边框、标题、关键内容识别理解。
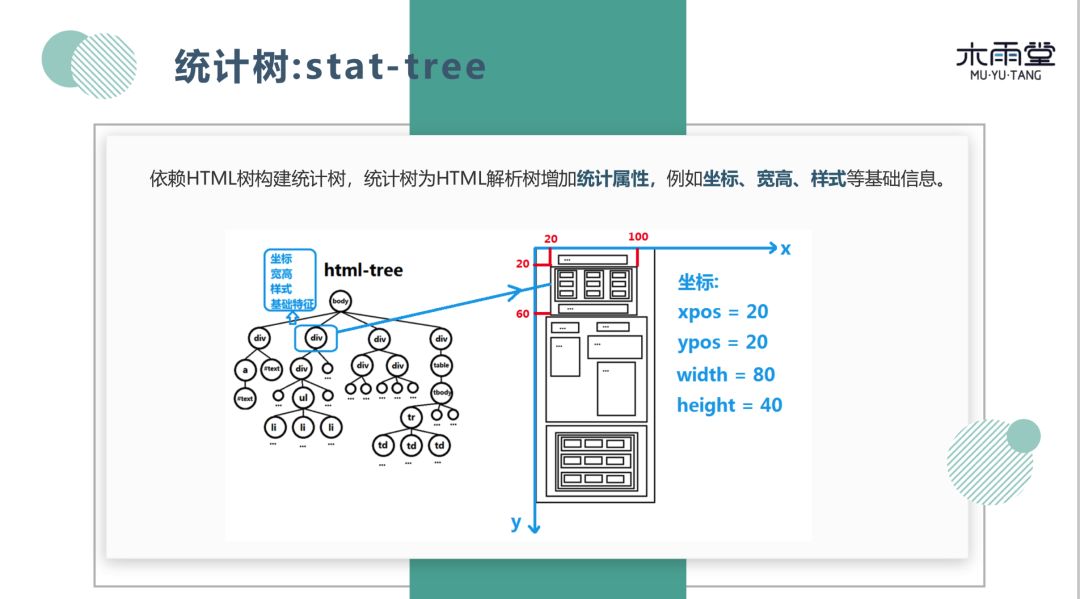
在将网页划分为不同区域的过程中, 需要用到较多的数据结构。例如:依赖 HTML 树构建统计树。所谓统计树就是在建立了 HTML 树之后,对树节点增加统计属性,例如坐标、宽高、样式等等基础信息。往往在识别节点类型(正文节点、图片节点)时,这些基本信息可以帮我们排除没有意义的节点。
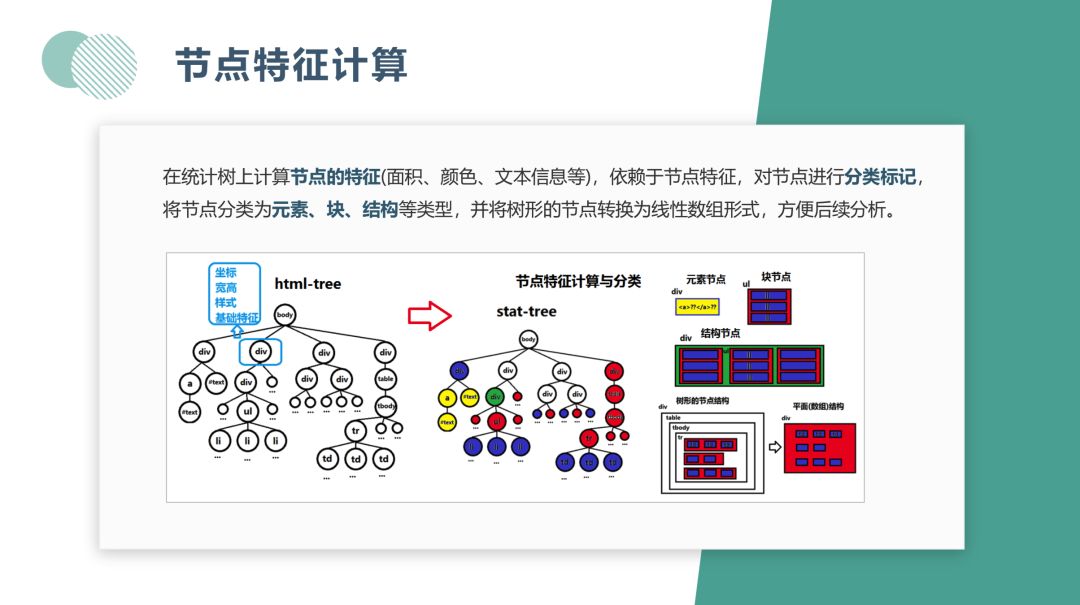
在构造树的过程中,会对节点的特征进行计算,例如节点的面积、颜色等。依赖这些节点特征对节点进行分类标记。例如说网页的布局节点,js 节点,这些具有对应的特征属性,基于此对网页进行分类。分类之后将树形的节点转化成数组的形式,方便后续分析。
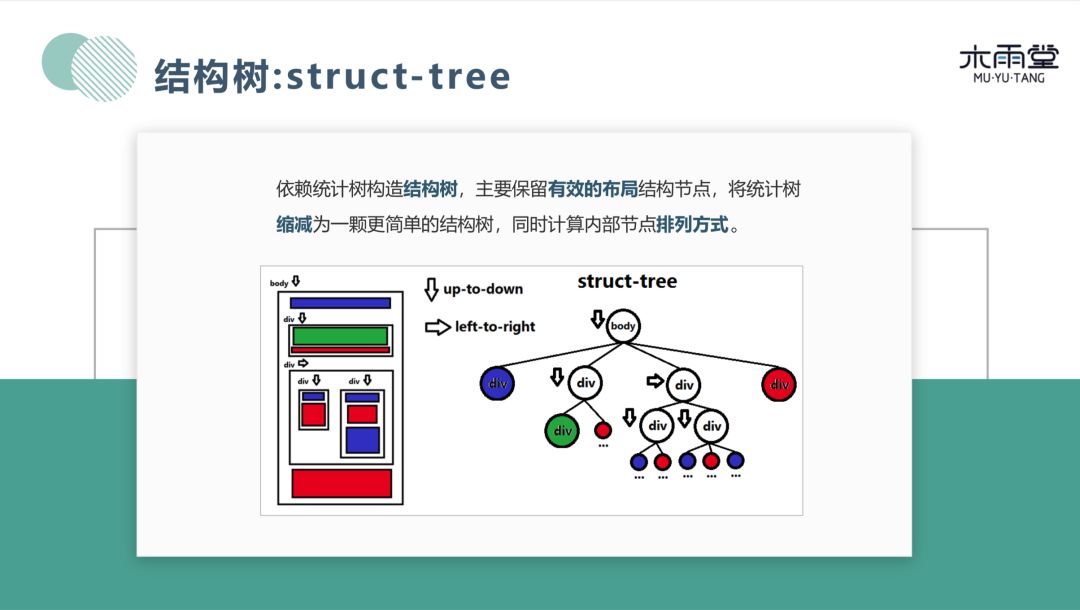
如左图,该网页包含 body 主体,布局节点从上到下一次排开。同样在右图的统计树上,根节点就是 body 节点,下面的四个子节点代表网页块元素。在统计树上进行层次遍历,以保留有效布局结构节点,将树缩减为一个更加简单的树。在遍历过程中,需要算法来计算节点的排列顺序。例如根节点下有4个子节点,分别代表网页中的不同布局块。左图四个布局块是从上到下的排列方式,在右图中会根据深度进行标记。
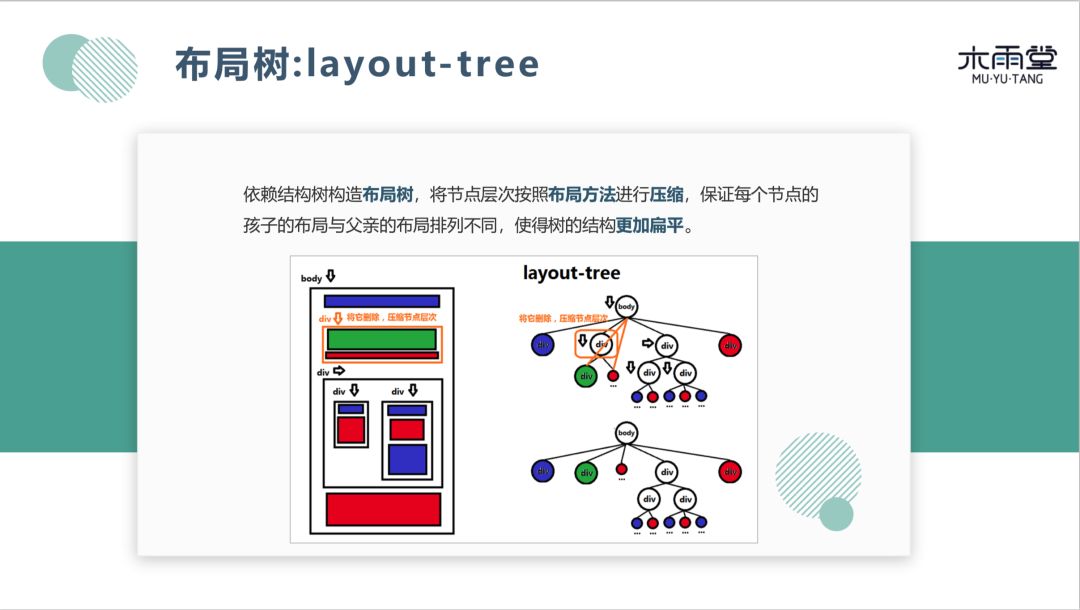
构造完结构树之后,还会对树进行变换:节点删除,节点压缩。左图网页中橙色的节点,对于表示页面意义不大,原因是:根节点下的子节点都是从上到下排列的,橙色节点的子节点排序顺序相同,因此可以对橙色节点删除,将其子节点上移。
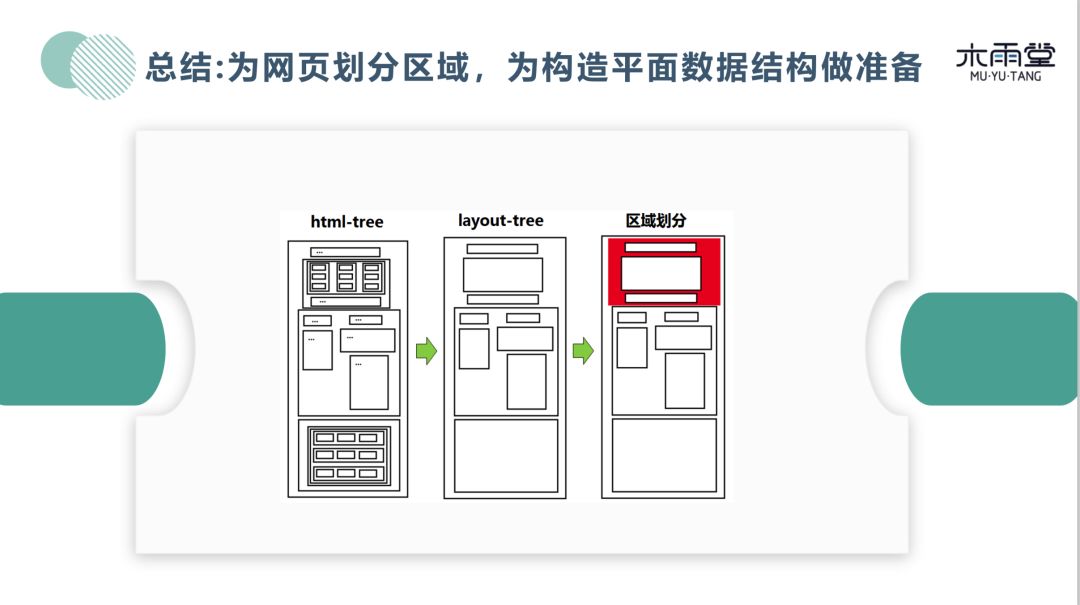
总结:为网页划分区域,为构造平面数据结构做准备。我们从 html tree 做了许多化简得到 layout tree,根据 layout tree 计算区域,从而得到多个分区。

如何根据 layout tree 划分平面,划分思想就是构造划分平面的容器(类比与 c++ 中的 vector)。 我们按广度优先遍历 layout tree,来判断节点是否可以放入到容器中。可以使用规则或者机器学习模型来进行判断。如图中黄框的节点,面积比较小,宽比高的值较大,且包含一些语义信息:导航等,就可判断节点属于上区域容器中。但是5号节点面积较大,判断为上区域是不合适的。那么上区域容器收集完成了。所以5号节点会在下一层进行相应的划分。也可以通过分类模型来判断是否要放入到容器中。
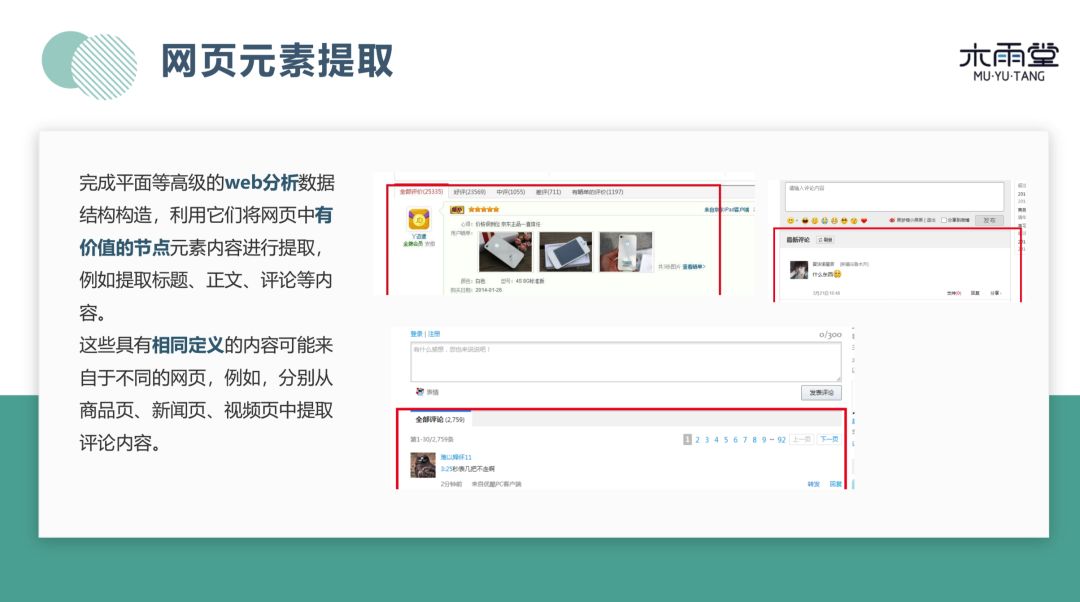
完成平面构造之后,可以利用它们对网页中元素提取。例如图中在提取评论内容,训练一个评论块识别模型,就可以从不同网页中,商品、新闻等网页中提取评论内容。

最后介绍网页分类,这是一个比较通用技术,无论是结构分类还是语义分类思路是比较类似的。例如对网页分类,就是对提取网页的特征向量(如图片数量,链接数量等等统计信息),利用有监督的机器学习模型(如随机森林、逻辑回归等)进行训练,识别网页类型。一般的网页分类系统是多个二分类模型叠加在一起的。例如有多个模型:娱乐,体育新闻等,最终我们会对这些模型结果串联到一起,这样每个类型相互没有依赖,升级迭代比较方便。
本次分享的技术部分就到这里,谢谢大家。

▌配套 PPT 下载

文章推荐:
DataFun:
专注于大数据、人工智能领域的知识分享平台。
一个「在看」,一段时光! 以上是关于搜索引擎中的 web 数据挖掘的主要内容,如果未能解决你的问题,请参考以下文章