吴信东:数据挖掘算法的经典与现代
Posted 明略科技集团
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吴信东:数据挖掘算法的经典与现代相关的知识,希望对你有一定的参考价值。

6月6日,中国计算机学会(CCF)主办的中国计算机学会青年精英大会(CCF YEF)在线上举行,在“经典流传的机器学习与数据挖掘算法”技术论坛上,明略科技首席科学家、明略科学院院长吴信东;UCLA 副教授孙怡舟;微软雷蒙德研究院高级研究科学家东昱晓;CCF高级会员、清华大学计算机系长聘副教授朱军;CCF高级会员、中科院计算所研究员沈华伟几位特邀专家带领了大家重温经典,解读他们心目中的经典机器学习与数据挖掘算法,并与大家分享了这些算法的起源、应用与影响。
其中,明略科技首席科学家、明略科学院院长吴信东做了题为《数据挖掘算法回顾:经典与现代》报告,总时长为1个小时左右,内容主要分为三个部分:数据挖掘中代表性的领域、数据挖掘的经典算法、2006年之后的现代数据挖掘技术。
下文是本场报告的文字版,由 AI 科技评论编辑。

今天主要回顾三个方面,第一方面是数据挖掘比较有代表性的领域;第二方面是分析2006年在IEEE ICDM会议上排名前十位的数据挖掘算法;第三方面是分析2006年以后,数据挖掘两个比较有代表性的方向。

无论是模型研究还是应用,数据挖掘主要有10个代表性的领域。第一个领域是大家耳熟能详的“分类”,主要内容是探讨如何将数据进行归类。在分类领域比较经典的算法包括C4.5、CART、KNN、朴素贝叶斯等等。
其中,C4.5是澳大利亚的研究者在1993年做出的工作;CART是斯坦福大学的统计学教授在1984年的工作,主要面向分类与回归树;KNN是1996年发明的,也是目前比较常用的“物以类聚,人以群分”思想;朴素贝叶斯发明于2001年,其在条件概率的基础上进行了独立性的假设。
第二个领域是“聚类”,其与“分类任务”的差别在于是否有类型标签,聚类任务常常涉及无类型标签的任务。比较经典的算法主要有两个,一个是K-Means,于1967年提出,另一个是BIRCH,全称是利用层次方法的平衡迭代规约和聚类,是数据库领域的研究者于1994年提出,其效率比K-Means更高。
第三个领域是“关联分析”,这类主题在互联网和日常生活中广泛存在,经典的案例是“啤酒与尿片”的故事。早期最有代表性的算法是Apriori,作为关联规则挖掘(Association rule mining)的代表性算法,其主要任务就是设法发现事物之间的内在联系。另一个代表性的算法是华人学者韩嘉炜在2000年提出的关联分析算法—FP树,其效率比Apriori提高了一个数量级。
上面三个是数据挖掘领域里面最有代表性的三个领域,只有了解了这三类领域才算数据挖掘基本入门。
第四个领域是“统计学习”,更多的是挖掘分析数字期望,数据特征。两类比较有代表性的算法,一是SVM(支持向量机),其是一类按监督学习方式对数据进行二元分类的广义线性分类器;另一个是EM(期望极大)算法,其是一类通过迭代进行极大似然估计的优化算法。这两类算法对初学者要求比较高,因为涉及很多统计分析。

第五个领域是“Link Mining”(链接挖掘),主要处理万维网中网页的链接、结构。PageRank和HITS是此领域比较经典的算法,其中,PageRank是谷歌搜索网页背后的算法支撑,当时发明这个算法的两个人(佩奇和布林),虽然现在还没有拿到博士学位,但两位现在都是美国工程院的院士;HITS是由康奈尔大学的Jon Kleinberg 博士于1997 年首先提出的,是一种网页重要性的分析的算法。
第六个领域是“Bagging和Boosting”,其核心思想是“三个臭皮匠顶一个诸葛亮”,也即群体智慧超越个人智慧,其作为一种模型融合的方法,可以将弱分类器融合之后形成一个强分类器,而且融合之后的效果会比最好的弱分类器更好。经典的代表算法是AdaBoost。
第七个领域是“序列模式”,其将空间、时间等另外的维度引入了关联分析。其代表性的算法是GSP和PrefixSpan。
第八个领域是“Integrated Mining”,这一领域最开始由新加坡国立大学的几位华人学者探索,比较有名的是Liu Bing(刘兵)老师,他1998年首次提出了CBA算法,将集成分类与关联规则挖掘融合了起来。
第九个领域是“图挖掘(Graph Mining)”,其在计算机以外的领域应用广泛,例如化学、生物等等。比较有代表性的算法是gSpan。
第十个领域是“深度学习”,其集大成之作是2015年由图灵三剑客Yann LeCun, Yoshua BengioGeoffrey Hinton那篇发表在Nature上面的《DeepLearning》。
十大经典算法

数据挖掘领域的十大算法评选是基于我2006年在IEEEICDM上推出的数据挖掘算法Top 10。这十个算法如上图所示,按第十到第一的次序分别是:CART、Naive Bayes、KNN、AdaBoost、PageRank、EM、Apriori、SVM、K-means、C4.5。
其中,CART是由斯坦福大学的四个统计学教授发明,这四位老师只有一位是IEEE Fellow,另外三位是美国的工程院院士、美国科学学院院士,在统计回归领域非常有名望;第七名的位次是由朴素贝叶斯、KNN、AdaBoost三个算法并列;PageRank排在了第六名;统计学习方法EM排在了第五位;Apriori这一关联分析方法排在第四位;SVM(支持向量机)在第三位;聚类算法K-Means在第二位;2006年,澳大利亚学者Ross Quinlan开发的C4.5算法排在了第一位。
上述10个算法是2006年评选的,14年过去了,这十大算法是否时过境迁?是否需要重新评选?
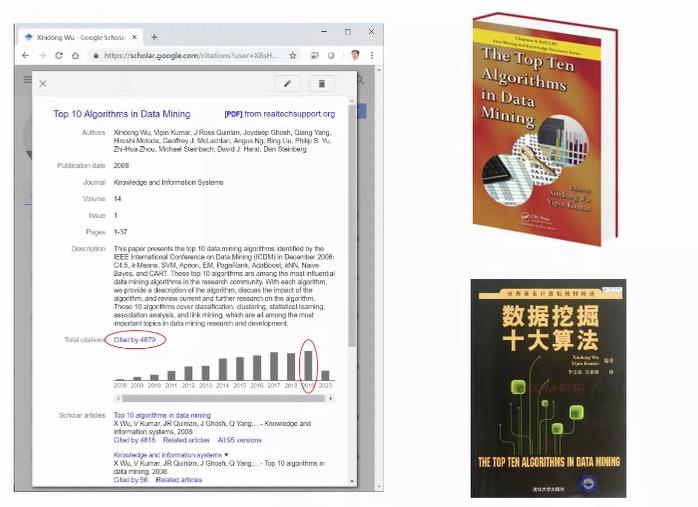
昨日,我去google scholar 搜索了一下当年的文章《Top 10 Algorithms in Data Mining》,这篇文章发表写成于2006年,发表于2008年,目前引用量已经达到了4879次。如上图所示,可以清晰的看到,其引用量还在逐年上升。以一本书的销量为例,只有当书的销量开始下滑的时候才需要重新考虑写新的版本。所以,考虑到文章与日俱增的“热度”,重新考虑Top 10算法的排名与评选为时过早。十大算法的评选在今天来看并未过时。
数据挖掘领域的现代算法

前面讲述的内容大多在2006年之前,接下来介绍我个人认为2006年之后的数据挖掘的两大方向,供大家讨论。
第一个方向是大家都会承认的是Deep Learning,因为此领域掀起了人工智能领域研究的一个热潮,也对数据挖掘领域的推动起到了不可否认的作用。上面我列了三个框架:卷积神经网络、递归神经网络、循环神经网络等给大家提供讨论的思路,因为我本人研究“逻辑”比较多,对深度学习了解不是很多,后面的报告讲者也会讨论深度学习,所以我就不展开讨论了。

第二方向,是我自己的一个工作,叫做OSFS:OnlineStreaming Feature Selection,这个工作与前面经典算法大不相同。其核心思想是针对数据来源多样性,数据分散性来把数据分成数据元。值得一提的是,OSFS不光是针对数据量,还针对数据特征的变化。例如一个数据库里面,包含的变量是X1~X20,那么经过一天的时间,可能就变成了X1~X21。所以,这样数据的特征就会变成“流”状态。
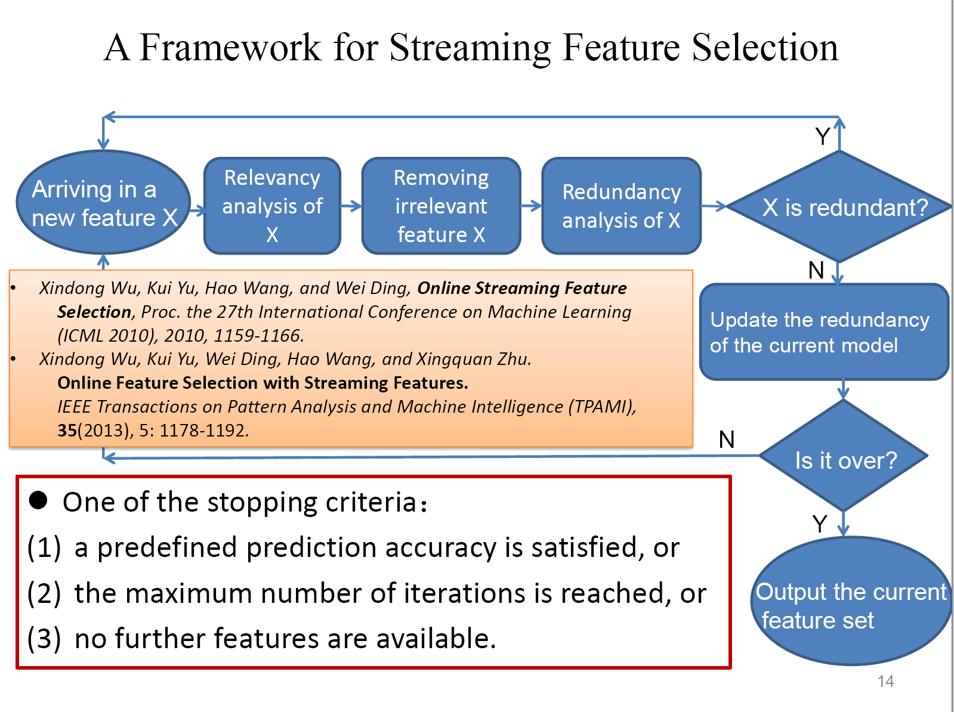
我们此类工作的大致框架如上图,给定一个新特征X,先检查其的相关性,看新特征是否能影响当下任务,如果无影响,那么抛弃,如果能够影响当下任务,那么进一步检查冗余性,即这个新特征能否用现有的特征推导?能否用现有的特征表示?如果能够表示,那么抛弃新特征,如果没有冗余性,那么将此新特征更新到模型中,从而输出新的特征集合。
可以看到这个算法框架是个闭环,其重点在于如何设定停止训练的标准。我们设定了三个标准:1.达到预期的精度;2.达到最大的迭代次数;3.没有更多的新特征可以加入。
这个方向的工作,我们最早是在2010年开始尝试,并在ICML会议上发表了一篇文章,2013年又那篇文章进行了进一步的分析,而目前此类工作可能已经有了几百篇文章。

上面是我们最初的算法思路具体细节,重点是在于对新特征的相关性分析和冗余性分析,虽然在处理新特征方面比较有新意,但是容易导致NP问题。也就是说相关性分析可以做dependency ,但一旦判定存在相关性,进行冗余性分析的时候,需要考虑所有现存特征的子集。

针对NP问题,我们在OSFS的思路上进行了创新,即设计出Fast-OSFS算法将原有的NP复杂度问题转换成多项式问题。原有的相关性分析没有改变,此算法改变的是冗余性分析。即在冗余性分析中将所有特征的子集检测转换成了马尔科夫毯。
基于此,我们也做过很多的实验,如上图所示,示例的数量在不断上升。
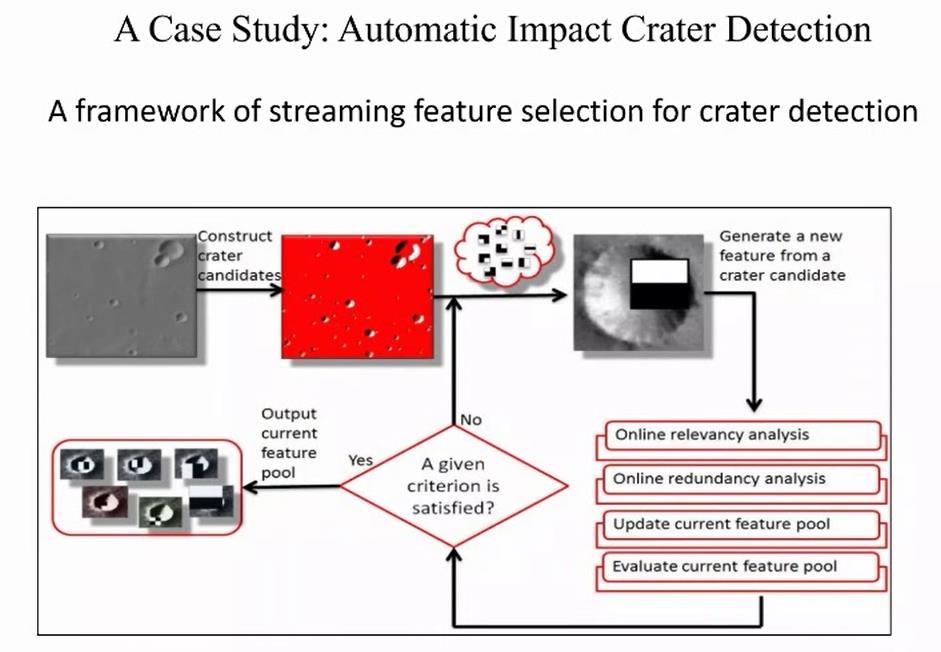
用OSFS算法我们也做了一些例子,例如对上面三张火星大图片(每张图片是37500*56250平方米)进行撞击坑检测。例子的结果我们也写到了论文中,

最后,谈一些开放问题,首先经典十大算法的排名要变么?答案是:肯定要变,因为需要更好的算法去替代历史。
再者,深度学习会不会取代经典算法?答案是:不会!深度学习是机器学习或者数据挖掘一个有力的工具,虽然很有效,但是取代不了现有经典算法。

如感兴趣明略科技产品,请点击左边【阅读原文】
点击右边【在看】分享明略科技观点
以上是关于吴信东:数据挖掘算法的经典与现代的主要内容,如果未能解决你的问题,请参考以下文章