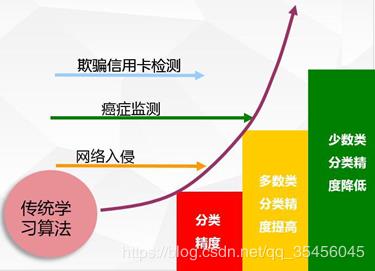
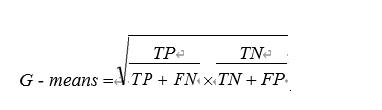
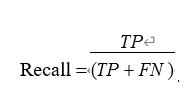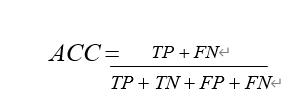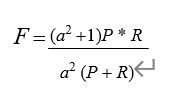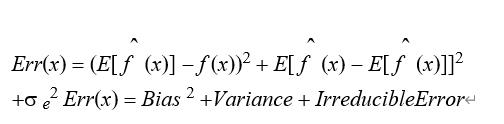作者 | 汪雯琦出品 | CSDN博客1、在 PCA 中为什么要做正交变换? PCA 的思想是将 n 维特征映射到 k 维上(k<n),这 k 维是全新的正交特征。这 k 维特征称为主成分,是重新构造出来的 k 维特征,而不是简单地从 n 维特征中去除其余 n-k 维特征。PCA 的目的是选择更少的主成分(与特征变量个数相较而言),那些选上的主成分能够解释数据集中最大方差。通过正交变换,各主成分的相对位置不发生变化,它只能改变点的实际坐标。2、给定一个数据集,这个数据集有缺失值,且这些缺失值分布在离中值有 1 个标准偏差的范围内。百分之多少的数据不会受到影响?为什么?由于数据分布在中位数附近,先假设这是一个正态分布。在一个正态分布中,约有 68%的数据位于跟平均数(或众数、中位数)1 个标准差范围内的,那样剩下的约 32%的数据是不受影响的。因此,约有 32%的数据将不受到缺失值的影响。3、给你一个癌症检测的数据集,你已经建好了分类模型,取得了96%的精度。如果不满意你的模型性能的话,你可以做些什么呢?
5、什么是 K-fold 交叉验证?K-fold 交叉验证就是把原始数据随机分成 K 个部分,在这 K 个部分中选择一个作为测试数据,剩余的 K-1 个作为训练数据。交叉验证的过程实际上是将实验重复做 K 次,每次实验都从 K 个部分中选择一个不同的部分作为测试数据,剩余的数据作为训练数据进行实验,最后把得到的 K 个实验结果平均,用于评价模型的泛化能力,从而进行模型选择。6、简述准确率(accuracy)、召回率(Recall)统计量的含义?
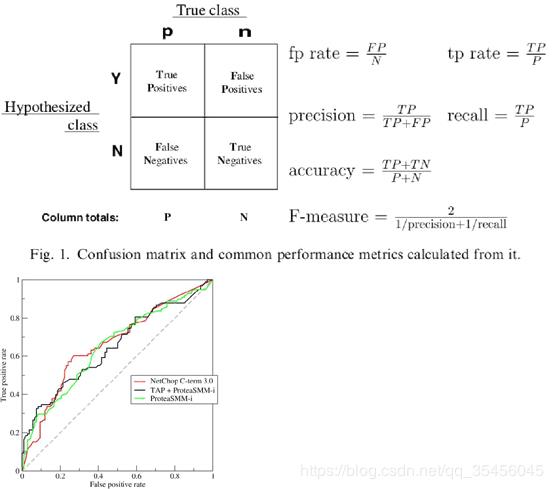
召回率(Recall)是覆盖面的度量,度量有多个正例被分为正例的比例(查全率):
准确率(accuracy)有时候准确率高并不能代表一个算法就好:
精确率(precision)表示被分为正例的示例中实际为正例的比例(查准率)。7、简述 F 值(F-Measure)统计量的含义?F-Measure 是 Precision 和 Recall 加权调和平均:
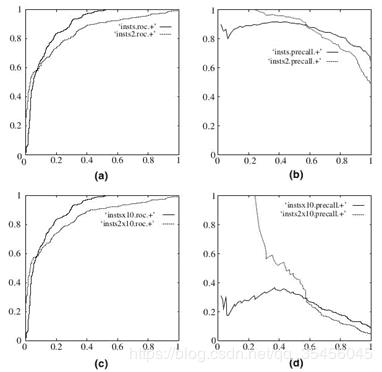
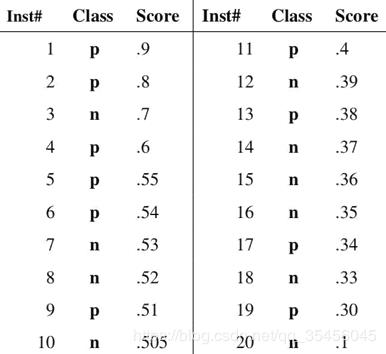
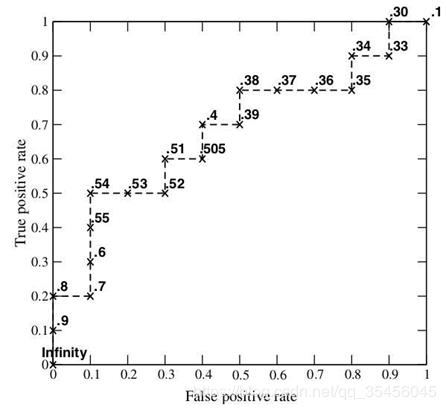
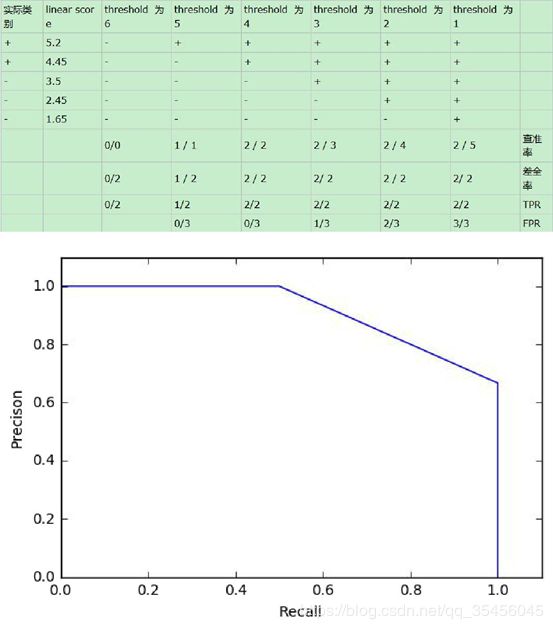
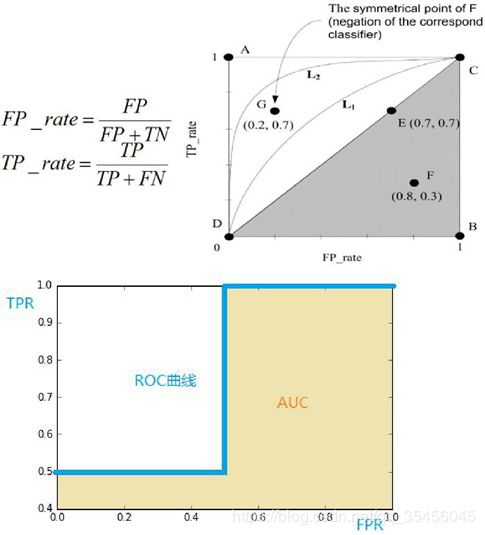
(a)和(c)为 ROC 曲线,(b)和(d)为 Precision-Recall 曲线。(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)和(d)是将测试集中负样本的数量增加到原来的 10 倍后,分类器的结果。可以明显的看出,ROC 曲线基本保持原貌,而 Precision-Recall 曲线则变化较大。9、如何画出一个 ROC 曲线?In signal detection theory, a receiver operating characteristic (ROC), or simply ROC curve, is a graphical plot which illustrates the performance of a binary classifier system as its discrimination threshold is varied。20 个测试样本,“Class”一栏表示每个测试样本真正的标签,p 表示正样本,n表示负样本),“Score”表示每个测试样本属于正样本的概率。
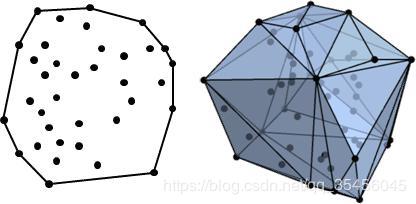
当数据是线性可分的,凸包就表示两个组数据点的外边界。一旦凸包建立,我们得到的最大间隔超平面(MMH)作为两个凸包之间的垂直平分线。MMH 是能够最大限度地分开两个组的线。18、BalanceCascad 算法和 EasyEnsemble 有什么异同?这个方法跟 EasyEnsemble 有点像,但不同的是,每次训练 adaboost 后都会扔掉已被正确分类的样本,经过不断地扔掉样本后,数据就会逐渐平衡。19、你会在时间序列数据集上使用什么交叉验证技术?是用 k 倍或LOOCV?都不是。对于时间序列问题,k 倍可能会很麻烦,因为第 4 年或第 5 年的一些模式有可能跟第 3 年的不同,而对数据集的重复采样会将分离这些趋势,我们可能最终是对过去几年的验证,这就不对了。相反,我们可以采用如下所示的 5 倍正向链接策略(1,2,3,4,5,6 代表年份):fold 1 : training [1], test [2]fold 2 : training [1 2], test [3]fold 3 : training [1 2 3], test [4]fold 4 : training [1 2 3 4], test [5]fold 5 : training [1 2 3 4 5], test [6]20、常见的过采样方法有哪些以用来应对样本不平衡问题?我们可以通过欠抽样来减少多数类样本的数量从而达到平衡的目的,同样我们也可以通过,过抽样来增加少数类样本的数量,从而达到平衡的目的。Random oversampling of minority class:通过有放回的抽样,不断的从少数类的抽取样本,不过要注意的是这个方法很容易会导致过拟合。我们通过调整抽样的数量可以控制使得 r=0.5。21、给你一个缺失值多于 30%的数据集?比方说,在 50 个变量中,有 8 个变量的缺失值都多于 30%。你对此如何处理?1.把缺失值分成单独的一类,这些缺失值说不定会包含一些趋势信息。2.我们可以毫无顾忌地删除它们。3.或者,我们可以用目标变量来检查它们的分布,如果发现任何模式,我们将保留那些缺失值并给它们一个新的分类,同时删除其他缺失值。22、什么是协同过滤算法?协同过滤 (Collaborative Filtering, 简称 CF)协同过滤一般是在海量的用户中发掘出一小部分和你品位比较类似的,在协同过滤中,这些用户成为邻居,然后根据他们喜欢的其他东西组织成一个排序的目录作为推荐给你,分 User CF 和 Item CF 两种。23、当在解决一个分类问题时,出于验证的目的,你已经将训练集随机抽样地分成训练集和验证集。你对你的模型能在未看见的数据上有好的表现非常有信心,因为你的验证精度高。但是,在得到很差的精度后,你大失所望。什么地方出了错?在做分类问题时,应该使用分层抽样而不是随机抽样。随机抽样不考虑目标类别的比例。相反,分层抽样有助于保持目标变量在所得分布样本中的分布。24、在 k-means 或 kNN,我们是用欧氏距离来计算最近的邻居之间的距离。为什么不用曼哈顿距离?我们不用曼哈顿距离,因为它只计算水平或垂直距离,有维度的限制。另一方面,欧式距离可用于任何空间的距离计算问题。因为,数据点可以存在于任何空间,欧氏距离是更可行的选择。例如:想象一下国际象棋棋盘,象或车所做的移动是由曼哈顿距离计算的,因为它们是在各自的水平和垂直方向的运动。25、考虑到机器学习有这么多算法,给定一个数据集,你如何决定使用哪一个算法?机器学习算法的选择完全取决于数据的类型。如果给定的一个数据集是线性的,线性回归是最好的选择。如果数据是图像或者音频,那么神经网络可以构建一个稳健的模型。如果该数据是非线性互相作用的的,可以用 boosting 或 bagging 算法。如果业务需求是要构建一个可以部署的模型,我们可以用回归或决策树模型(容易解释和说明),而不是黑盒算法如 SVM,GBM 等。26、什么时候正则化在机器学习中是有必要的?当模型过度拟合或者欠拟合的时候,正则化是有必要的。这个技术引入了一个成本项,用于带来目标函数的更多特征。因此,正则化是将许多变量的系数推向零,由此而降低成本项。这有助于降低模型的复杂度,使该模型可以在预测上(泛化)变得更好。27、考虑到机器学习有这么多算法,给定一个数据集,你如何决定使用哪一个算法?从数学的角度来看,任何模型出现的误差可以分为三个部分。以下是这三个部分:
偏差误差在量化平均水平之上预测值跟实际值相差多远时有用。高偏差误差意味着我们的模型表现不太好,因为没有抓到重要的趋势。另一方面,方差量化了在同一个观察上进行的预测是如何彼此不同的。高方差模型会过度拟合你的训练集,而在训练集以外的数据上表现很差。28、OLS 是用于线性回归,最大似然是用于逻辑回归。请解释以上描述。OLS 和最大似然是使用各自的回归方法来逼近未知参数(系数)值的方法。简单地说,普通最小二乘法(OLS)是线性回归中使用的方法,它是在实际值和预测值相差最小的情况下而得到这个参数的估计。最大似然性有助于选择使参数最可能产生观测数据的可能性最大化的参数值。29、一个有 1000 列和 1 百万行的训练数据集。这个数据集是基于分类问题的。你来降低该数据集的维度以减少模型计算时间。你的机器内存有限,你会怎么做?(你可以自由做各种实际操作假设)1.由于我们的 RAM 很小,首先要关闭机器上正在运行的其他程序,包括网页浏览器,以确保大部分内存可以使用。2.我们可以随机采样数据集。这意味着,我们可以创建一个较小的数据集,比如有 1000 个变量和 30 万行,然后做计算。3.为了降低维度,我们可以把数值变量和分类变量分开,同时删掉相关联的变量。对于数值变量,我们将使用相关性分析。对于分类变量,我们可以用卡方检验。4.另外我们还可以使用 PCA(主成分分析),并挑选可以解释在数据集中有最大偏差的成分。5.利用在线学习算法,如 VowpalWabbit(在 Python 中可用)是一个可能的选择。6.利用 Stochastic GradientDescent(随机梯度下降)法建立线性模型也很有帮助。7.我们也可以用我们对业务的理解来估计各预测变量对响应变量的影响大小。但是,这是一个主观的方法,如果没有找出有用的预测变量可能会导致信息的显著丢失。注意:对于第 4 点和第 5 点,请务必阅读有关在线学习算法和随机梯度下降法的内容。这些是高阶方法。30、KNN 中的 K 是如何选取的?如李航博士的一书「统计学习方法」上所说:1.如果选择较小的 K 值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K 值的减小就意味着整体模型变得复杂,容易发生过拟合;2.如果选择较大的 K 值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且 K 值的增大就意味着整体的模型变得简单。3.K=N,则完全不足取,因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的累,模型过于简单,忽略了训练实例中大量有用信息。在实际应用中,K 值一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是一部分样本做训练集,一部分做测试集)来选择最优的 K 值。31、防止过拟合的方法有哪些?过拟合的原因是算法的学习能力过强;一些假设条件(如样本独立同分布)可能是不成立的;训练样本过少不能对整个空间进行分布估计。处理方法有:a. 早停止,如在训练中多次迭代后发现模型性能没有显著提高就停止训练 ;b. 数据集扩增,原有数据增加、原有数据加随机噪声、重采样;c. 正则化 d.交叉验证 e.特征选择/特征降维。32、机器学习中为何要经常对数据做归一化?维基百科给出的解释:1)归一化后加快了梯度下降求最优解的速度;2)归一化有可能提高精度。1)归一化后加快了梯度下降求最优解的速度:如下图所示,蓝色的圈圈图代表的是两个特征的等高线。其中左图两个特征 X1 和 X2 的区间相差非常大,X1 区间是[0,2000],X2 区间是[1,5],其所形成的等高线非常尖。当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
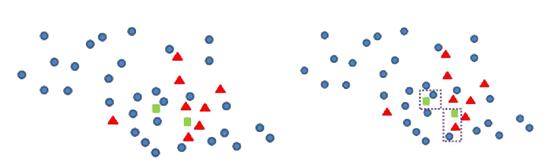
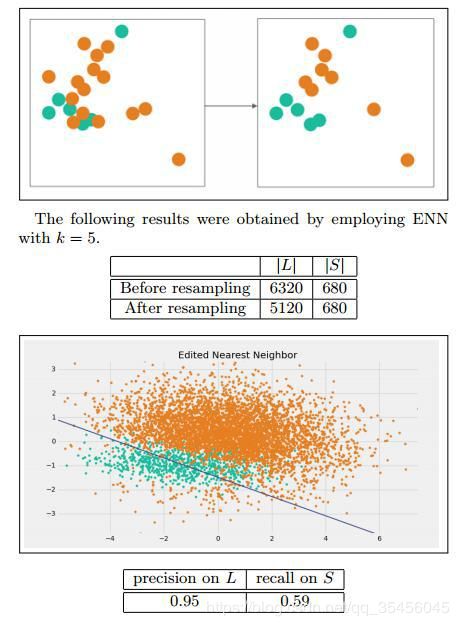
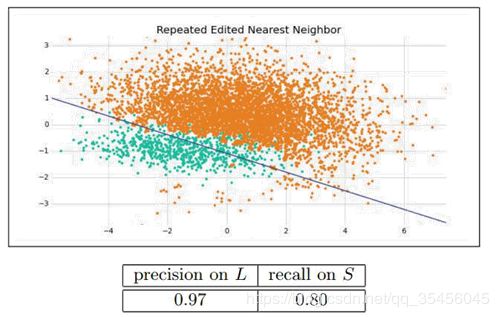
2)归一化有可能提高精度:一些分类器需要计算样本之间的距离(如欧氏距离),例如 KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。33、什么是欠采样和过采样?使用不同的数据集。有两种方法使不平衡的数据集来建立一个平衡的数据集:欠采样和过采样。欠采样是通过减少丰富类的大小来平衡数据集,当数据量足够时就该使用此方法。通过保存所有稀有类样本,并在丰富类别中随机选择与稀有类别样本相等数量的样本,可以检索平衡的新数据集以进一步建模。当数据量不足时就应该使用过采样,它尝试通过增加稀有样本的数量来平衡数据集,而不是去除丰富类别的样本的数量。通过使用重复、自举或合成少数类过采样等方法(SMOTE)来生成新的稀有样品。欠采样和过采样这两种方法相比而言,都没有绝对的优势。这两种方法的应用取决于它适用的用例和数据集本身。另外将过采样和欠采样结合起来使用也是成功的。34、不平衡数据集处理中基于数据集的应对方案有哪些?Edited Nearest Neighbor (ENN):将那些 L 类的样本,如果他的大部分 k 近邻样本都跟他自己本身的类别不一样,我们就将它删除。
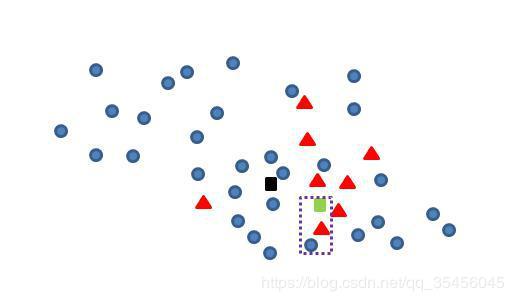
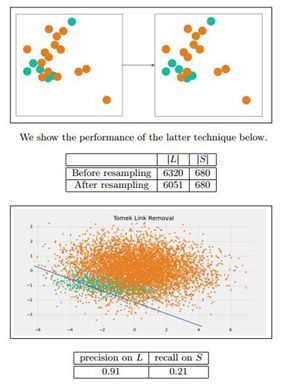
Tomek Link Removal:如果有两个不同类别的样本,它们的最近邻都是对方,也就是 A 的最近邻是 B,B 的最近邻是 A,那么 A,B 就是 Tomek link。我们要做的就是讲所有 Tomek link 都删除掉。那么一个删除 Tomek link 的方法就是,将组成 Tomek link 的两个样本,如果有一个属于多数类样本,就将该多数类样本删除掉。
35、二分类问题如何转化为一分类问题?对于二分类问题,如果正负样本分布比例极不平衡,我们可以换一个完全不同的角度来看待问题:把它看做一分类(One Class Learning)或异常检测(Novelty Detection)问题。这类方法的重点不在于捕捉类间的差别,而是为其中一类进行建模,经典的工作包括 One-class SVM 等,如下图所示:
One Class SVM 是指你的训练数据只有一类正(或者负)样本的数据, 而没有另外的一类。在这时,你需要学习的实际上你训练数据的边界。而这时不能使用最大化软边缘了,因为你没有两类的数据。所以呢,文章“Estimating the support of a high-dimensional distribution”中,Schölkopf 假设最好的边缘要远离特征空间中的原点。左边是在原始空间中的边界,可以看到有很多的边界都符合要求,但是比较靠谱的是找一个比较紧的边界(红色的)。这个目标转换到特征空间就是找一个离原点比较远的边界,同样是红色的直线。当然这些约束条件都是人为加上去的,你可以按照你自己的需要采取相应的约束条件。比如让你 data 的中心离原点最远。说明:对于正负样本极不均匀的问题,使用异常检测,或者一分类问题,也是一个思路。36、如何通过增加惩罚项来提高稀有数据的预测准确率?通过设计一个代价函数来惩罚稀有类别的错误分类而不是分类丰富类别,可以设计出许多自然泛化为稀有类别的模型。例如,调整 SVM 以惩罚稀有类别的错误分类。
37、L1 和 L2 有什么区别?L1 范数(L1 norm)是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。比如 向量 A=[1,-1,3], 那么 A 的 L1 范数为 |1|+|-1|+|3|。简单总结一下就是:L1 范数: 为 x 向量各个元素绝对值之和。L2 范数: 为 x 向量各个元素平方和的 1/2 次方,L2 范数又称 Euclidean 范数或 Frobenius范数。Lp 范数: 为 x 向量各个元素绝对值 p 次方和的 1/p 次方。在支持向量机学习过程中,L1 范数实际是一种对于成本函数求解最优的过程,因此, L1 范数正则化通过向成本函数中添加 L1 范数,使得学习得到的结果满足稀疏化,从而方便人类提取特征。L1 范数可以使权值稀疏,方便特征提取。L2 范数可以防止过拟合,提升模型的泛化能力。38、CNN 最成功的应用是在 CV,那为什么 NLP 和 Speech 的很多问题也可以用 CNN 解出来?为什么 AlphaGo 里也用了 CNN?这几个不相关的问题的相似性在哪里?CNN 通过什么手段抓住了这个共性?以上几个不相关问题的相关性在于,都存在局部与整体的关系,由低层次的特征经过组合,组成高层次的特征,并且得到不同特征之间的空间相关性。如下图:低层次的直线/曲线等特征,组合成为不同的形状,最后得到汽车的表示。CNN 抓住此共性的手段主要有四个:局部连接/权值共享/池化操作/多层次结构。局部连接使网络可以提取数据的局部特征;权值共享大大降低了网络的训练难度,一个 Filter 只提取一个特征,在整个图片(或者语音/文本) 中进行卷积;池化操作与多层次结构一起,实现了数据的降维,将低层次的局部特征组合成为较高层次的特征,从而对整个图片进行表示。39、实现对比 LSTM 结构推导,为什么比 RNN 好?推导 forget gate,input gate,cell state, hidden information 等的变化;因为 LSTM 有进有出且当前的 cell informaton 是通过 input gate 控制之后叠加的,RNN 是叠乘,因此 LSTM 可以防止梯度消失或者爆炸。40、请简要说说 EM 算法?有时候因为样本的产生和隐含变量有关(隐含变量是不能观察的),而求模型的参数时一般采用最大似然估计,由于含有了隐含变量,所以对似然函数参数求导是求不出来的,这时可以采用 EM 算法来求模型的参数的(对应模型参数个数可能有多个),EM 算法一般分为 2 步: E 步:选取一组参数,求出在该参数下隐含变量的条件概率值;M 步:结合 E 步求出的隐含变量条件概率,求出似然函数下界函数(本质上是某个期望函数)的最大值,重复上面 2 步直至收敛。原文链接:https://vicky.blog.csdn.net/article/details/104770540版权声明:本文为CSDN博主「汪雯琦」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。