腾讯后台开发工程师:怎么学习linux 命令
Posted 腾讯课堂Coding学院
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了腾讯后台开发工程师:怎么学习linux 命令相关的知识,希望对你有一定的参考价值。
来源:Coding学院(ID:ke_coding)
⊙常用命令
⊙xargs命令
⊙du命令
⊙ps命令、awk命令、sort命令、grep命令、
⊙常用工具
导读:作为一名后台开发程序员,时常要和linux系统打交道,掌握一些常用的linux命令,能够方便进行文档的处理、系统状态查看、程序问题定位等,同时能够有效地提升工作效率。在这里对用到的命令做一个记录,方便自己,同时也方便他人
1、find命令
find命令在日常工作中非常常用,主要功能是用来查找符合给定条件的文件或文件夹。
常用选项
-name 指定要查找的文件或文件夹名字,可以使用正则表达式进行模糊匹配
-perm 查找指定文件权限模式的文件或文件夹,后跟8进制文件权限数字
-mmin 查找给定分钟数作为修改时间界限的文件或文件夹。具体含义随后面所跟随的数字的正负而有区别。如后跟+10,则表示修改时间位于10分钟以前。如后跟-10,则表示修改时间位于10分钟前到当前时间这段区间内。
-amin 查找给定分钟数作为访问时间界限的文件或文件夹。后面所跟数字的具体含义同上
-cmin 查找给定分钟数作为创建时间界限的文件或文件夹。后面所跟数字的具体含义同上
-mtime 查找给定时间作为修改时间界限的文件或文件夹。单位为24小时
-atime 查找给定时间作为访问时间界限的文件或文件夹。单位为24小时
-ctime 查找给定时间作为创建时间界限的文件或文件夹。单位为24小时
-type 指定要查找的文件类型:b(块设备文件)、c(字符设备文件)、d(文件夹)、p(命名管道)、f(普通文件)、l(符号链接)、s(socket文件)
-size 指定要查找的文件大小,后跟数字及单位。关于单位:b(块,即512字节)、c(字节)、w(双字节)、k(千字节)、M、G。关于数字,前跟正负号不同有不同的含义。+10M 表示大于10M,-10M表示小于10M,10M表示等于10M
-atime -ctime –mtime中的参数n说明
跟在这些选项后面的参数n其含义比较难以理解,因此这里单独记录一下。假定给出的参数为n,并且选项为mtime,则用法有3个: 应用示例
应用示例
查找777权限的文件或文件夹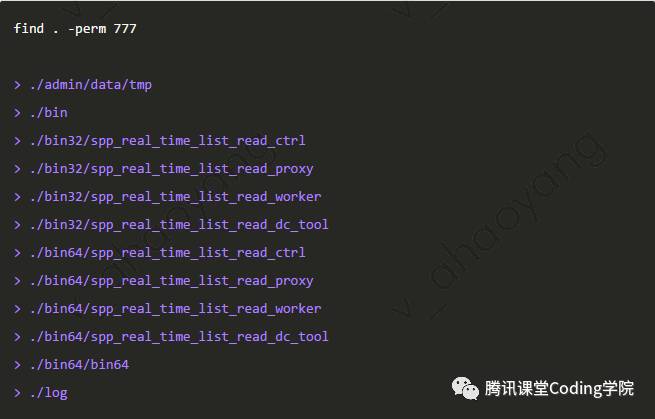 查找修改时间位于10分钟前到5分钟前这段区间内的文件
查找修改时间位于10分钟前到5分钟前这段区间内的文件 2、xargs命令
2、xargs命令
这个命令从标准输入中获取输入,来执行给定的程序。其默认执行的程序为echo。如下图所示,将当前目录下的log文件名进行了输出。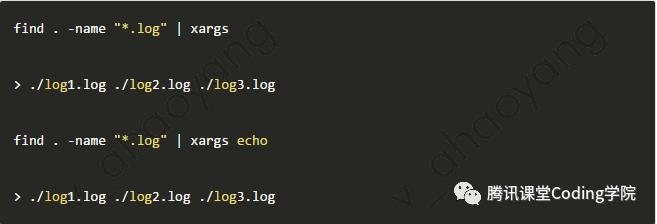 如果将该命令用于管道,则输入中所包含的换行和空白都默认将被替换为空格。具体示例如下所示:
如果将该命令用于管道,则输入中所包含的换行和空白都默认将被替换为空格。具体示例如下所示: 在此基础上,可以通过xargs的选项对获取到的数据进行重新格式化输出。
在此基础上,可以通过xargs的选项对获取到的数据进行重新格式化输出。
-n选项控制每行输出的数据量: -d选项进行字符串分割
-d选项进行字符串分割 -i或-I(大写字母i)选项用来替换获取到的每一个参数
-i或-I(大写字母i)选项用来替换获取到的每一个参数
这个2个选项很好用,针对如下示例代码:
find . -name "*.log" -print | xargs -I {} cp {} ..
这条命令的功能是通过find命令获取当前目录下的以.log结尾的文件,然后将这些文件复制到上级目录中。
xargs -I {} 用来指定采用的替换符 为{},后面的{} 将被标准输入中的参数替换,循环执行。
-i 和 -I的区别在于,-i采用默认的替换符,即{}, 而-I可以自己指定替换符。因此上面的指令等同于: 常用的命令
常用的命令
3、du命令
查看文件或目录的占用空间大小。在日常开发中,由于组内共用相同的测试机,每个人的服务都会往测试机磁盘写入一些不重要的数据,如log等。因此时常发生测试机磁盘空间不足的情况,这个时候就需要各位同学查看下自己的服务目录下所占用的空间,及时清理一些空间出来。
命令格式
du [选项][文件]
常用的选项
-h 以人类可读的方式显示大小,如以K,M,G为单位显示,提高信息的可读性
-s 只显示总大小
-c 显示多个文件或文件夹的总大小
-L<符号链接> 显示选项中所指定符号链接的源文件大小
—max-depth=1 仅显示目录下各个子目录所使用的空间,不进行递归显示
常用示例
查看某个文件的大小
查看当前文件夹及其子文件夹大小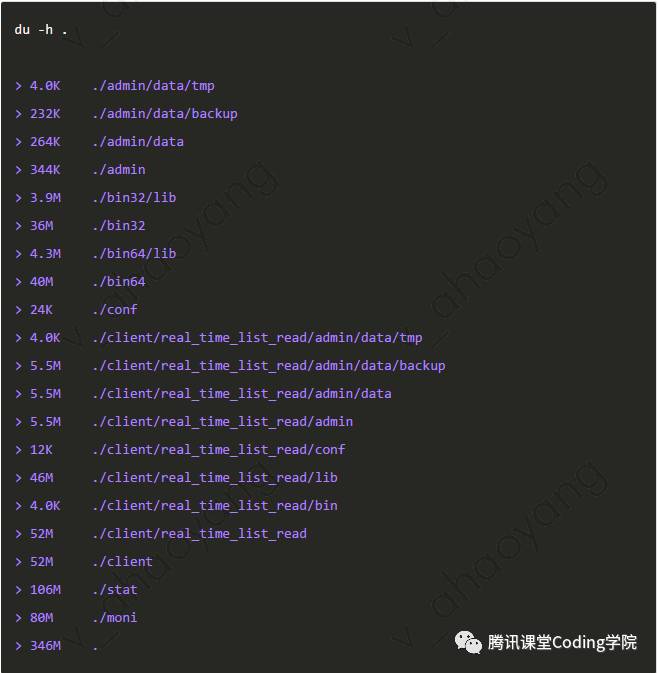 仅查看文件夹大小
仅查看文件夹大小 同时查询多个文件或文件夹的大小
同时查询多个文件或文件夹的大小 根据大小来排序(注意此处的du命令不可跟-h选项,因为-h选项会对文件大小进行格式化,这个会影响最终排序)
根据大小来排序(注意此处的du命令不可跟-h选项,因为-h选项会对文件大小进行格式化,这个会影响最终排序)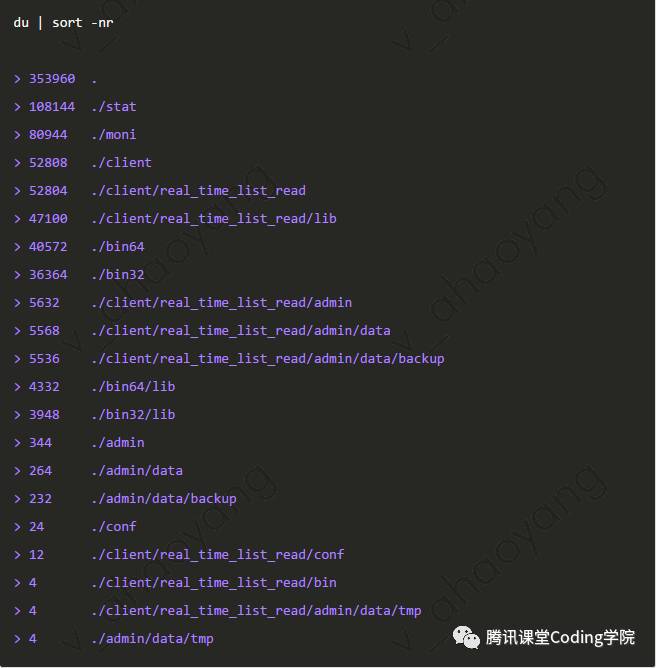 输出当前目录下各个子目录所使用的空间(只显示一层,不进行递归显示)
输出当前目录下各个子目录所使用的空间(只显示一层,不进行递归显示) 4、ps命令
4、ps命令
ps命令是Process Status的缩写,主要用来显示当前系统中正在运行的进程状态。
常用选项
-A 显示所有进程
-e 显示所有进程和A选项相同
-m 进程后面紧跟着显示线程信息
-p 后跟pid作为输入
-f 显示UID,PPIP,C与STIME栏位
-L 显示线程信息,和-f选项一起用可以显示LWP和NLWP列
-o 指定显示的格式
查看所有进程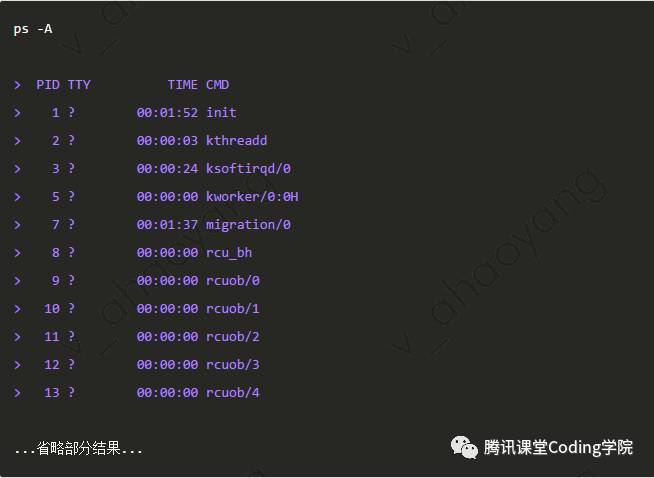
查看进程以及其子进程、线程
日常工作及问题定位中,需要查看进程以及其子进程、线程之间的关系,可以通过-eLf选项来实现,该命令的结果中,
PID为进程标识符
PPID为父进程标识符
LWP为轻量级进程,即线程标识符
CPU占用百分比
NLWP为LWP(即线程)的数量
下图中,update_notify进程id为30430,有一个子进程30431,子进程30431有14个线程,它们的LWP ID如图中LWP列所示。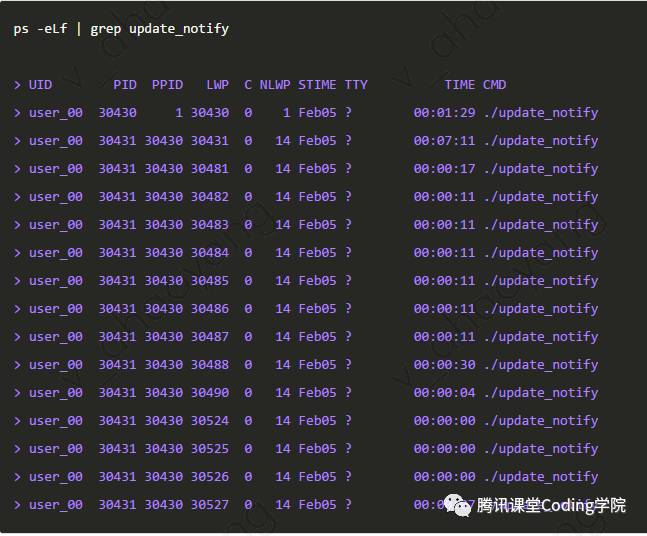 查看进程的启动时间和运行时间
查看进程的启动时间和运行时间
如下图所示,dataloader进程自2017-01-16 15:07:37启动,目前已经运行了21天4小时46分30秒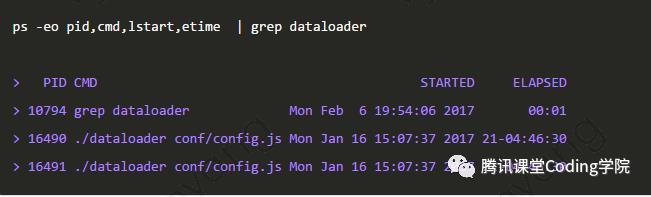 查看进程中所有线程占用的CPU时间
查看进程中所有线程占用的CPU时间
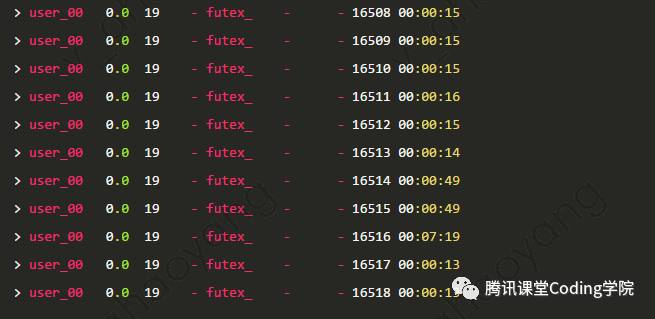
之前遇到过一个问题,一个进程中的一部分线程占用CPU过高,通过这里介绍的命令,找到占用CPU过高的线程,在运用gstack命令,查看线程的调用栈,进而定位到了问题所在,也是一个很实用的命令。如上图所示,dataloader子进程id为16491,查询这个子进程中各个线程占用的CPU时间情况如下图所示。
WCHAN表示进程正在等待的事件
下图中,每个线程占用的CPU都很低,是正常的,WCHAN这一列中的futex_是一种锁机制,可以看出大多数线程都在等待锁。hrtime则是用来返回当前的高精度时间。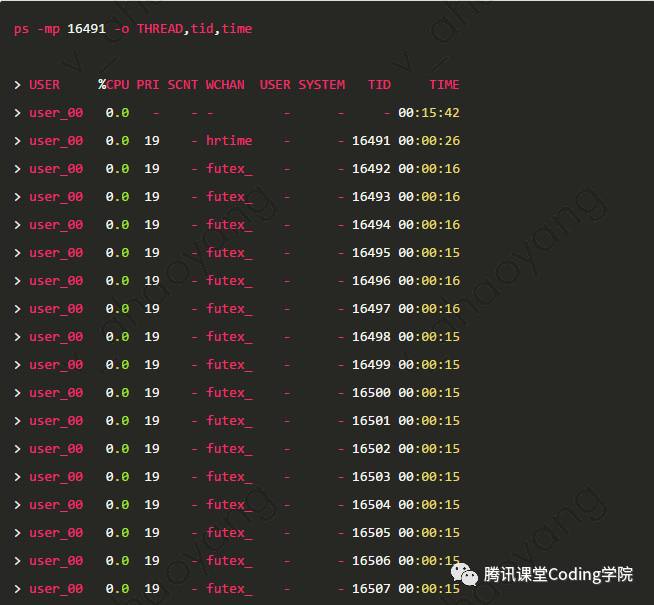
 5、awk命令
5、awk命令
awk主要是主要用来处理一些数据文件。在日常工作中常常会需要对一些文件内容进行处理,有了这个工具,就不再需要使用python甚至c++等语言编写小程序了,能够大大提高工作效率。
使用方法
awk [options] {filenames} awk -f awk-script-file [options] {filenames}
如上所示,可以直接将 处理行为写在命令行中,也可以卸载文件中,然后通过-f选项加载进来执行。
根据日常使用情况,多是直接在命令行中使用,因此这里只记录命令行的使用方式。
option格式
awk 'BEGIN{ print "start" } pattern{ commands } END{ print "end" }' file
上面的格式中option主要含有4个部分
BEGIN 代码初始化块
pattern 正则表达式
commands 需要对每一行数据执行的指令
END 代码结束块
针对BEGIN块里面的代码,在处理文件前执行一次,END块里面的代码在文件处理完之后执行一次。pattern和commands则针对文件的每一行都执行一次
BEGIN和END块 示例
如下图所示,在输出ps指令结果之前输出了start,之后输出了end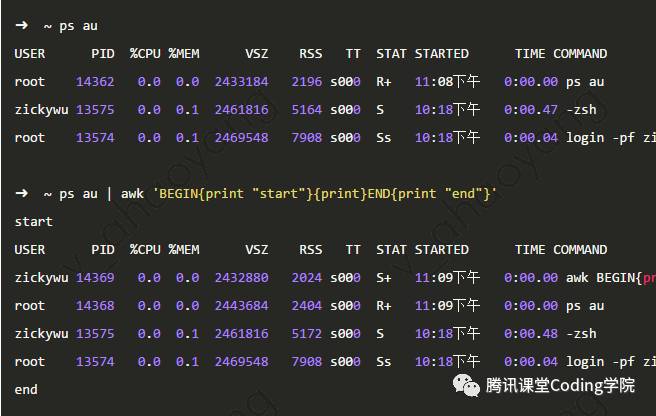 pattern示例
pattern示例
pattern中的正则表达式格式为 ’/正则表达式/‘
如下图,只显示ps结果中包含root字符串的那些行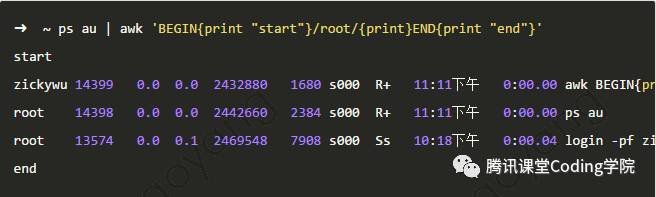 pattern中除了正则表达式外,还可以使用关系运算符。
pattern中除了正则表达式外,还可以使用关系运算符。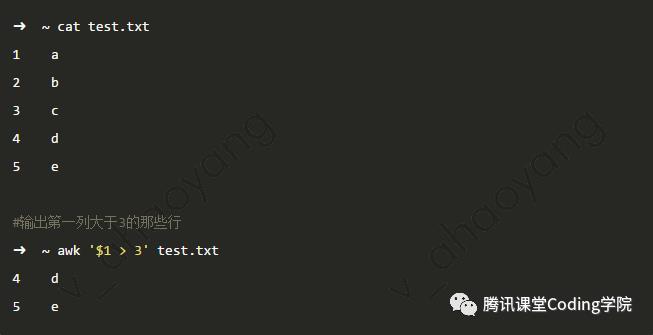 awk支持的运算符如下表所示:
awk支持的运算符如下表所示:
| 运算符 | 名称 |
|---|---|
| = += -= = /= %= ^= *= | 赋值 |
| ?: | C条件表达式 |
| || | 逻辑或 |
| && | 逻辑与 |
| ~ ~! | 匹配正则表达式和不匹配正则表达式 |
| < <= > >= != == | 关系运算符 |
| 空格 | 连接 |
| + - | 加,减 |
| * / % | 乘,除与求余 |
| + - ! | 一元加,减和逻辑非 |
| ^ *** | 求幂 |
| ++ — | 增加或减少,作为前缀或后缀 |
| $ | 字段引用 |
| in | 数组成员 |
根据上表,我们可以将正则表达式和 运算符结合使用: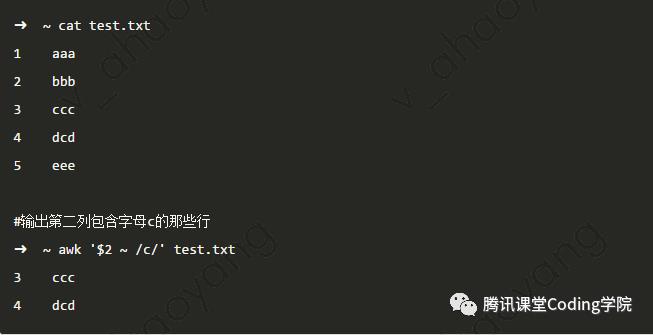 command示例
command示例
下图中,指定print $1,表示只输出第一列。类似的print $n表示输出文件中第n列,特别地,当n=0时,表示输出所有的列。输出时可以自己拼接各种字符串。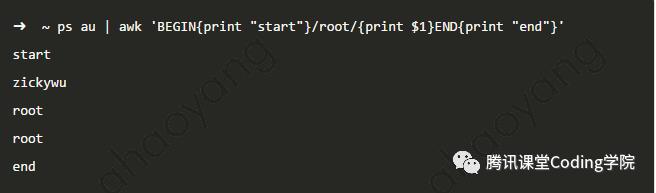 输出函数除了print之外,常用的还有printf,用法基本和C语言类似,可以进行格式化字符串输出。
输出函数除了print之外,常用的还有printf,用法基本和C语言类似,可以进行格式化字符串输出。
上面说得各个部分都是可以省略的。如下面的示例,只含有command这一部分。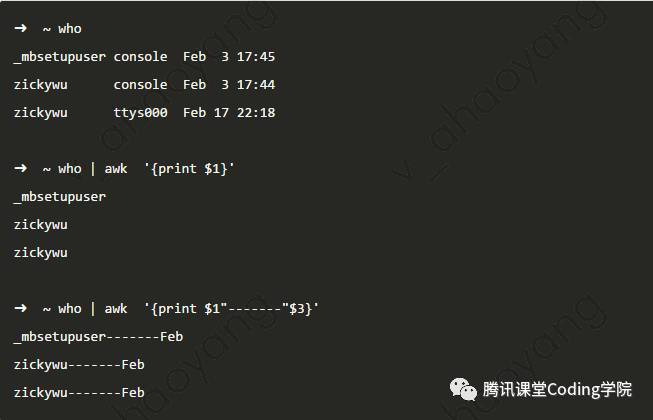 另外,awk输出指定列,默认的分隔符是”空白键” 或 “[tab]键”。可以通过-F选项指定分隔符
另外,awk输出指定列,默认的分隔符是”空白键” 或 “[tab]键”。可以通过-F选项指定分隔符
内部常量定义
awk内部定义了一些常量,可以在option里面直接使用
| 常量名 | 常量含义 |
|---|---|
| ARGC | 命令行变元个数 |
| ARGV | 命令行变元数组 |
| FILENAME | 当前输入文件名 |
| FNR | 当前文件中的记录号 |
| FS | 输入域分隔符,默认为一个空格 |
| RS | 输入记录分隔符 |
| NF | 当前记录里域个数 |
| NR | 到目前为止记录数 |
| OFS | 输出域分隔符 |
| ORS | 输出记录分隔符 |
➜ ~ echo "aa bb cc dd ee" | awk '{print NF}' 5
变量定义
awk可以自定义变量,定义方式 为使用-v选项。
➜ ~ echo | awk -v a=5 '{print a}' 5
内部函数
awk有一些自定义的函数,如length函数,求指定参数的长度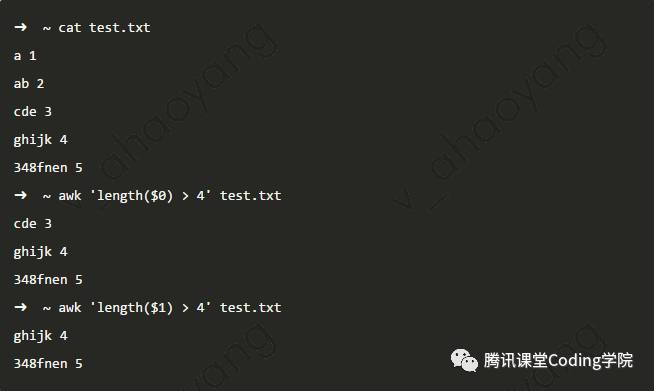 awk脚本文件的使用
awk脚本文件的使用
对于一些较为复杂的处理逻辑,直接在命令行中编辑比较不方便,因此 awk通过选项 -f 可以指定awk脚本文件,进而执行文件中的命令。如下 awk脚本文件: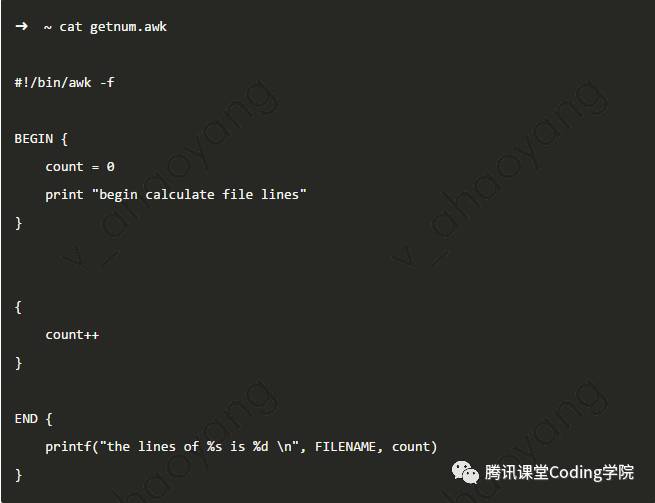 执行后,结果为:6、sort命令
执行后,结果为:6、sort命令
最近在做腾讯视频评分需求,时常要对视频分数文件进行排序处理,将结果呈现给产品同学看,因此常常要借助这个命令。毕竟一个命令就能搞定的事儿,就没必要再用编程语言写一段代码了是不。
使用方法
常用参数
| 选项 | 含义 |
|---|---|
| -t | 分隔符 |
| -u | 合并相同行 |
| -n | 按照数字大小排序 |
| -r | 反向排序 |
| -o | 结果输出到指定文件中 |
用法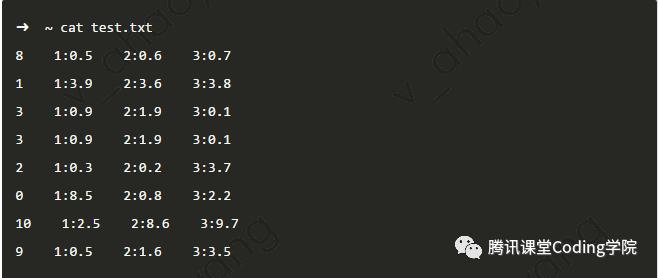 默认情况下,sort按照每行文本的ASCII码来排序。sort排序默认情况下是按照从小到大排序
默认情况下,sort按照每行文本的ASCII码来排序。sort排序默认情况下是按照从小到大排序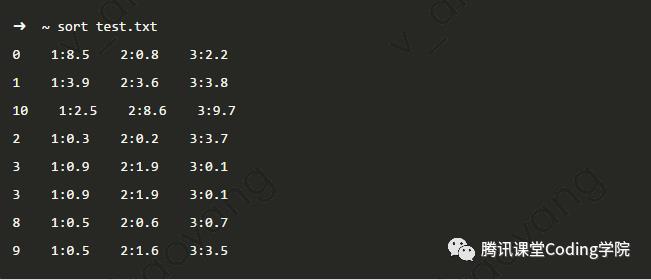 使用-u选项去重(-u只识别用-k设定的域,发现相同,就将后续相同的行都删除)
使用-u选项去重(-u只识别用-k设定的域,发现相同,就将后续相同的行都删除)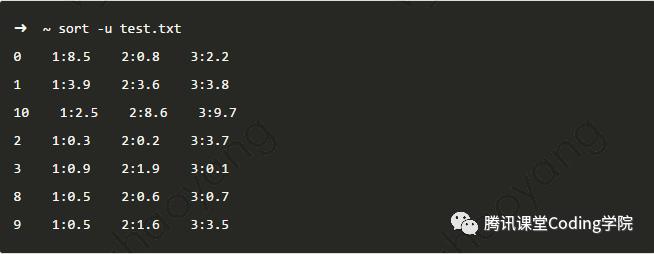 使用-n指定按照数值大小排序
使用-n指定按照数值大小排序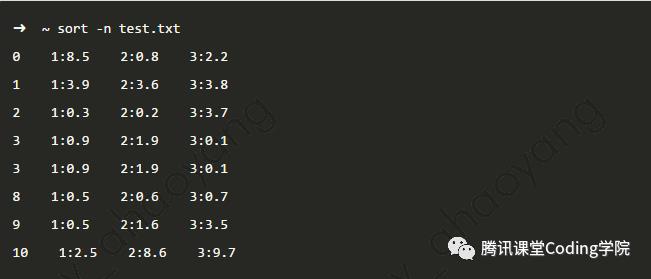 接下来要隆重介绍一下-k选项。这个选项可以指定使用哪个字段来进行排序。如上面的数据,是每条视频的各个维度的评分,第一列是视频id,后面的每列 格式为 维度id:分数。如果想按照第三个维度分数来排序,该如何实现呢?
接下来要隆重介绍一下-k选项。这个选项可以指定使用哪个字段来进行排序。如上面的数据,是每条视频的各个维度的评分,第一列是视频id,后面的每列 格式为 维度id:分数。如果想按照第三个维度分数来排序,该如何实现呢?
首先看下-k选项的格式
StartField.StartOffset,EndField.EndOffset
上面主要由4个参数,含义如下:
StartField:以当前的分隔符为基准,作为排序的字段的序号,比如针对上面的文件,sort默认的分隔符是Tab键,以该分隔符为基础,我们第三个维度在文件中 是第4个字段。
StartOffset:当前字段从第几个字符开始作为排序key。如上面的文件,第三个维度的分数是在字段内的第3个字符开始的。如果省略,则默认为1,表示从字段开头处开始作为排序的key。
EndField:排序key在第几个字段结尾。由于我们这里只对第三个维度进行排序,因此这个值还是4
EndOffset:结尾字段中的第几个字符作为结尾。如果省略,则表示一直到字段的最后一个字符处作为排序的key
那么,如何实现上面提出的问题呢,即按照第三个维度分数来排序。可以使用下面的命令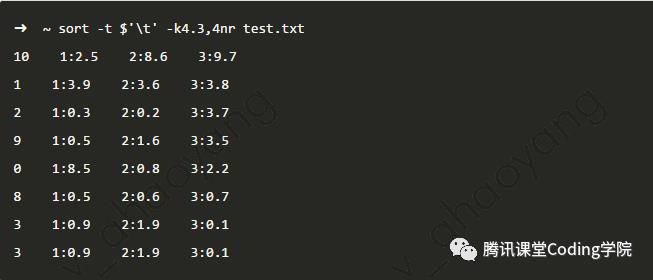 上图中,-k4.3,4 表示从第4个字段的第三个字符开始,到第4个字段的最后一个字符为止,作为排序的key。另外,上图中还同时使用了-n和-r两个选项,表示按照数值逆序排列。
上图中,-k4.3,4 表示从第4个字段的第三个字符开始,到第4个字段的最后一个字符为止,作为排序的key。另外,上图中还同时使用了-n和-r两个选项,表示按照数值逆序排列。
上图中还涉及一个技巧,在使用sort命令时,如果文件是以Tab键分割的,而命令行中又无法直接输入Tab键,则可以如上图所示使用$’\t’来输入Tab键。
7、grep命令
grep这个命令,其实就是对字符串进行正则匹配,找出需要的内容。在日常工作中也是一个极其常用的命令,不过大多数时候就只会grep xxxxx。其实这个命令能够做很多功能,这里也对常用功能做一下记录。
这个命令会读入文件的每一行进行匹配,并将匹配到的行输出。
使用方法
grep [option] pattern file
常用选项
| 选项 | 含义 |
|---|---|
| -c | 只输出匹配行的计数 |
| -v | 显示不含有匹配字符串的那些行 |
| -n | 显示匹配结果同时加上行号 |
| -i | 匹配时不区分大小写 |
| -r -R | 递归的搜索当前目录及其子目录中的文件 |
| -e | 后面接正则式,常用来指定多个正则式 |
下面例子用来打印/etc/passwd文件中包含有root字符的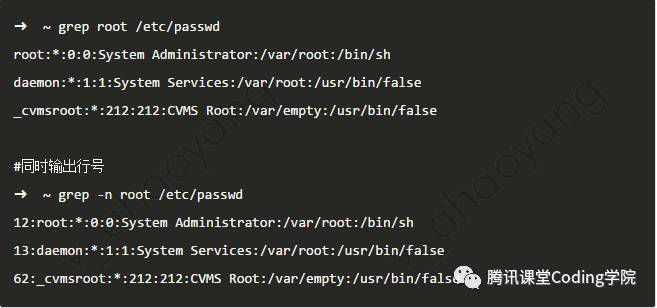 继续使用-v选项,找出包含root并且不包含false的那些行
继续使用-v选项,找出包含root并且不包含false的那些行 如上,利用管道可以轻松进行多重过滤,但如果想要找出一行中包含有root或者_wwwproxy的行呢,使用-e
如上,利用管道可以轻松进行多重过滤,但如果想要找出一行中包含有root或者_wwwproxy的行呢,使用-e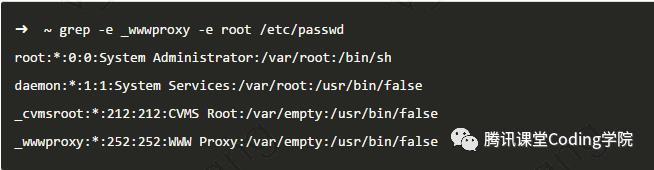 工作中经常需要在某个文件夹下面搜索包含某个字符串的文件,这个可通过-R选项来实现。如下面的例子,从test文件夹中查找包含有zickywu字符串的文件pattern
工作中经常需要在某个文件夹下面搜索包含某个字符串的文件,这个可通过-R选项来实现。如下面的例子,从test文件夹中查找包含有zickywu字符串的文件pattern 上面列出的用法都是查找给定的字符串,然而配合正则表达式,grep能够实现更加强大的功能,这里涉及到正则表达式的格式,暂略。。
上面列出的用法都是查找给定的字符串,然而配合正则表达式,grep能够实现更加强大的功能,这里涉及到正则表达式的格式,暂略。。
1、tcpdump工具
在后台日常问题定位中,tcpdump这个工具可谓是必不可少的。这个工具主要用来抓取网络上面的数据包。因为后台程序往往伴随着和前端或其他远程服务的网络交互,这个工具的出现极大的方便了网络问题的定位。一般后台服务器上面都默认安装了这个命令,这里就不介绍命令的安装了,直接切入命令的使用主题。
基本上tcpdump总的的输出格式为:系统时间 来源主机.端口 > 目标主机.端口 数据包参数
常用的选项
-c 指定抓包数量。有时候网络上面的数据包非常多,而我们进行问题定位时只需要几个包就可以了,通过这个参数可以指定抓包数量,防止抓包过多。
-A 以ASCII格式打印出所有分组,并将链路层的头最小化
-t 在输出的每一行不打印时间戳。如果我们只关注具体的包内容,而不关心具体发包收包时间,则可以通过这个选项来去掉时间戳,减少冗余信息
-w 直接将分组写入文件中,而不是不分析并打印出来。这个得到的文件可以使用wireshark等网络分析工具进行分析,十分方便。也可以由-r选项来读取。
-s 指定抓取的每个包的最大字节数,如果给定数字0,则表示抓取完整的包
-r 从指定的文件中读取包进行分析。这个文件一般是通过-w选项生成的。
-X 把包的内容同时以十六进制和ASCII码的形式输出,这个非常有用,可以用来分析包的内容来定位问题
-l 把标准输出变为行缓冲模式。 当我们希望直接在命令行窗口中看到包的内容时,可以指定这个选项。
过滤表达式介绍
这个工具除了选项外,还可以指定过滤表达式,用来过滤不需要的数据包。在进行问题定位时,往往只关注一小部分数据包,通过给定过滤表达式,能够有效的过滤掉大多数无用的数据包,这个可是抓包利器。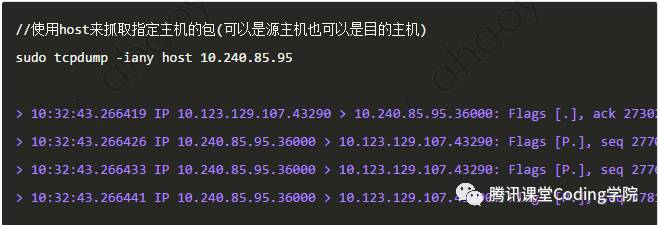
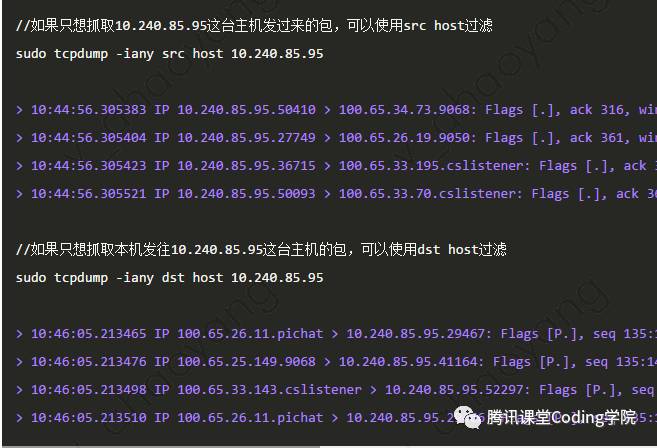 和host相对应的,有port过滤,同样也有src port 和 dst port。用法一样,这里不再赘述。
和host相对应的,有port过滤,同样也有src port 和 dst port。用法一样,这里不再赘述。
抓取指定偏移为固定值的包
tcpdump抓到的包为IP包,过滤表达式允许指定包的某一部分的值来进行过滤。语法为 协议[偏移量:长度]。长度值可以省略,默认值为1。这里的偏移量和长度均可以使用十进制或者十六进制数据 抓取分片包的第一个分片
抓取分片包的第一个分片
有时在进行抓包时,我们只关注包内应用层数据的开始部分,因此可以根据ip分片标志来过滤数据包。
这里需要注意的是,当采用协议下表偏移功能时,已经隐含的考虑到了分片的情况,比如例如, tcp[0]一定是整个完整的TCP报头的第一个字节, 而不是其中某个IP片内的TCP报文的第一个字节
抓取带有指定标志的包
针对TCP包,有许多不同的标志,如P(PSH)、R(RST)、S(SYN)、F(FIN)等,可以指定抓给定的标志的包。这里先认识一个tcpdump内置的常量tcpflags。它的值就是TCP标志的偏移量。有了它我们不需要死记TCP的标志位偏移量,方便了许多。另外,每个标志只占据一个bit,其在标志字节内的偏移量也有对应的常量,分别是tcp-push, tcp-fin, tcp-syn, tcp-rst, tcp-ack, tcp-urg等。
业界最顶尖的技术大咖/最权威的实战分享/最前沿的行业资讯/尽在腾讯课堂Coding学院
长按二维码关注Coding学院
以上是关于腾讯后台开发工程师:怎么学习linux 命令的主要内容,如果未能解决你的问题,请参考以下文章