etcd源码解读之raft协议实现
Posted 深度技术栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了etcd源码解读之raft协议实现相关的知识,希望对你有一定的参考价值。
背景:之前我曾在公司做过一套分布式job,当时也是参考的redis的raft实现,不过也只是领略到皮毛,不读相关源码真是不知其中庞大,所以在此学习下etcd的raft实现,本文内容比较长,可以当做工具文来学习相关实现。
先大概扫盲下:
raft协议流程的参与者主要分为三种:Leader(领导)、Candidate(选举参与者)、Follower(跟随者,不参与选举)。
节点的起始状态为Follower,每个节点都维持一个选举纪元,然后会等待一定时间,若时间内没收到其它节点带来的消息,则自增选举纪元后开始一轮选举向集群内其它节点发送竞选宣言,若获得1/2得票后竞选成功,若在指定时间内未获得指定票数,则选举纪元自增开始新一轮竞选。
当节点成为Leader后,会定期向集群内其它节点发送心跳,用于维持Leader身份和同步数据,若某节点在指定时间内没收到所属Leader的请求,则视为Leader失联,选举纪元自增开始新一轮选举。
当然,这只是大概流程,其中还有很多细微之处要设计,比如时间值的选取、数据如何同步、脑裂问题的防范,这也是我当初那个job频发问题的原因...
更多详细流程细节、严谨性分析请参考相关Raft分析论文,本文主要关注etcd中Raft的实现。
首先看下节点的数据结构:
EtcdServer结构存在于Server.go中,包含属性r(raftNode),代表raft参与者中的一个节点。
在server启动的过程中,会调用raftNode(etcdserver/raft.go)的start方法:
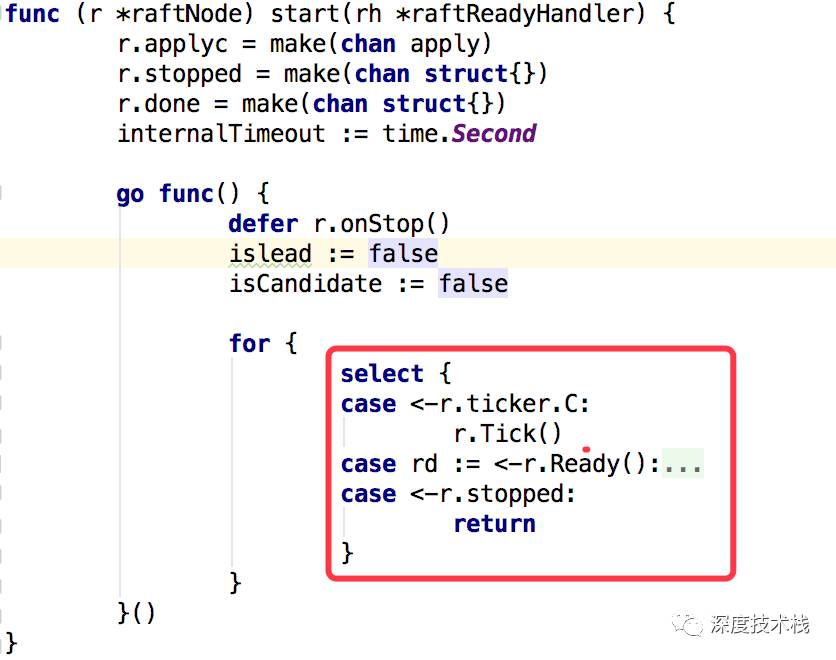
启动一个goroutine内部包了for-select结构,三个case的作用如下:
1.1通过r.ticker.C(Time类型的channel)监听时钟事件,时钟触发后将调用raftNode的Tick方法,针对raft过程中的一些计时处理的环节主要是Electiontimeouts和heartbeat timeouts,看下实现:
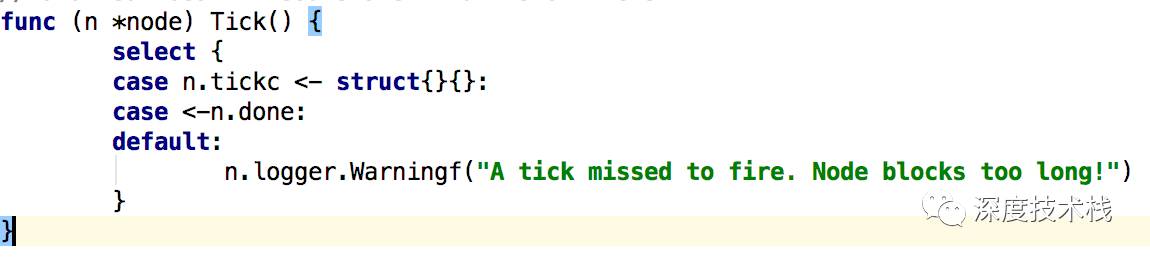
时钟事件触发后将会往n.tickcchannel中写入消息,最终消费这条消息的地方在node.go的run方法处,后面再介绍。
最后看下时钟事件channel的初始化代码:
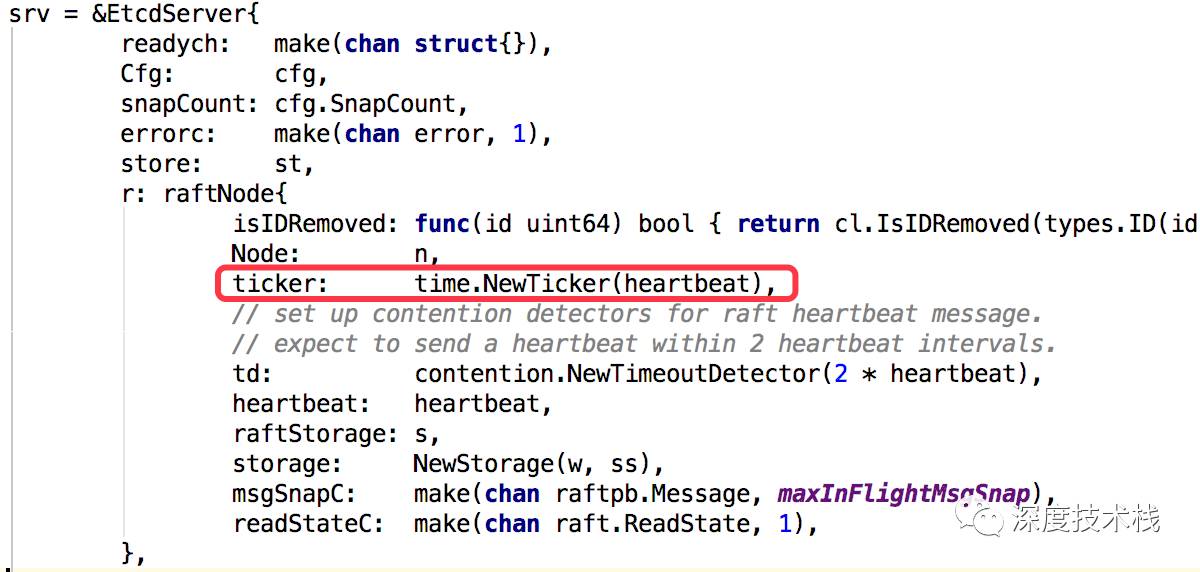
可见初始化触发时钟事件的时间间隔为heartbeat的time。
1.2监听是否有就绪消息到达,若有则发送到其它raft节点,看下r.Ready()返回的是啥:

返回的是node的readyc,这是个消息类型为Ready的channel,进去看下Ready是个什么鬼:
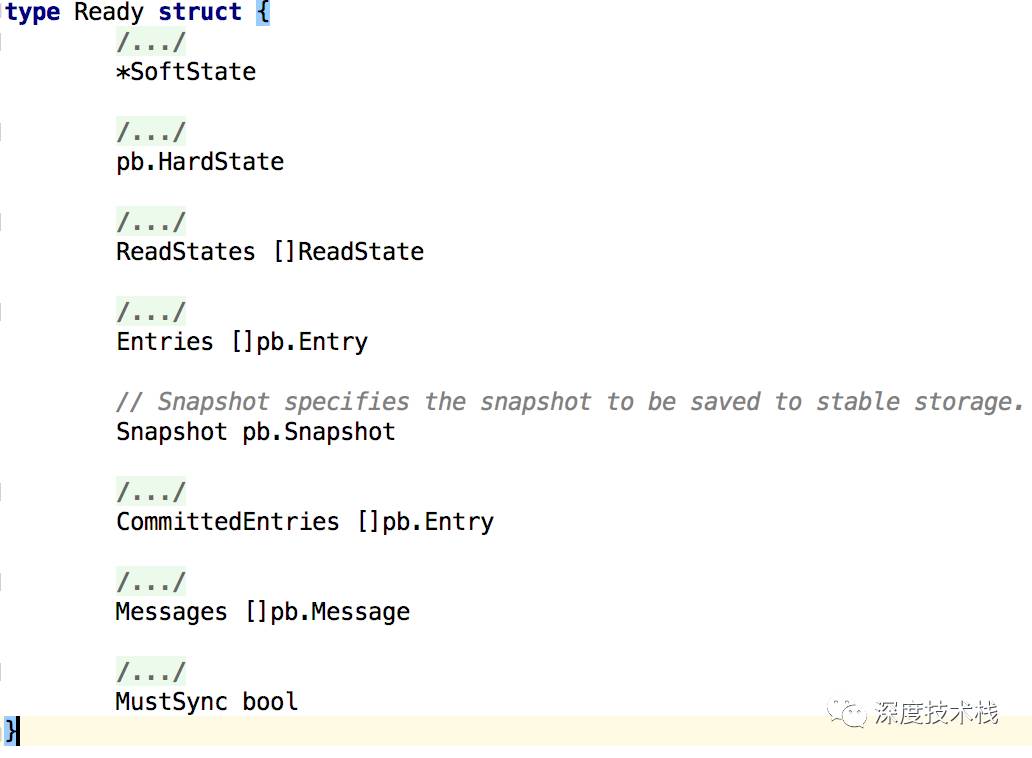
Ready是个核心数据结构,该结构体包装了所有要应用到自身、要发送到别的节点的就绪的事件具体内容。从上到下依次介绍下:
1.SoftState是个结构体匿名嵌套在Ready中,包含了2个元素,Lead代表当前term下leader的id,RaftState是个StateType类型的枚举值,代表raft过程中的身份,取值如下:
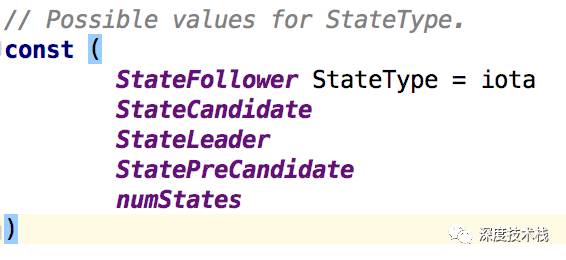
2.pb.HardState也是个匿名嵌套的结构体,代表了消息发送前的状态细节,比如commit索引值等,待消息发送后要做一些相应处理。
3.ReadStatus封装了此消息的id。
4.Entries是要在发送前存储到stablestorage的日志实例。
5.Snapshot是要存储到stablestorage的快照实例。
6.CommittedEntries是之前已经存储到stablestorage,下一步要应用到store(etcd的KV存储结构)的日志实例。
7.Messages是接下来要发送到其它节点的消息实例。
8.MustSync标识HardState和Entries写入到磁盘是否必须同步化。
哪么哪里构造了Ready对象呢?又是哪里将它写入n.readyc这个channel中的?答案在node.go的gorontinue中,第2节介绍。
1.3监听raft关闭事件。
介绍完了raftNode的初始化过程,再来介绍下node的初始化过程,node代表了etcd中一个节点,和raftNode是一对一的关系,raftNode中有匿名嵌入了node,raft交互流程相关的内容都放在raftNode中,而节点状态、IO调用、事件触发起点等入口都放在了node中,可以看到两者都在启动后起了一个for-select结构的goroutine循环处理各自负责的事件(raftNode的goroutine已经介绍过了,node的goroutine后面会讲到)。节点的起始入口在node.go的StartNode方法处:
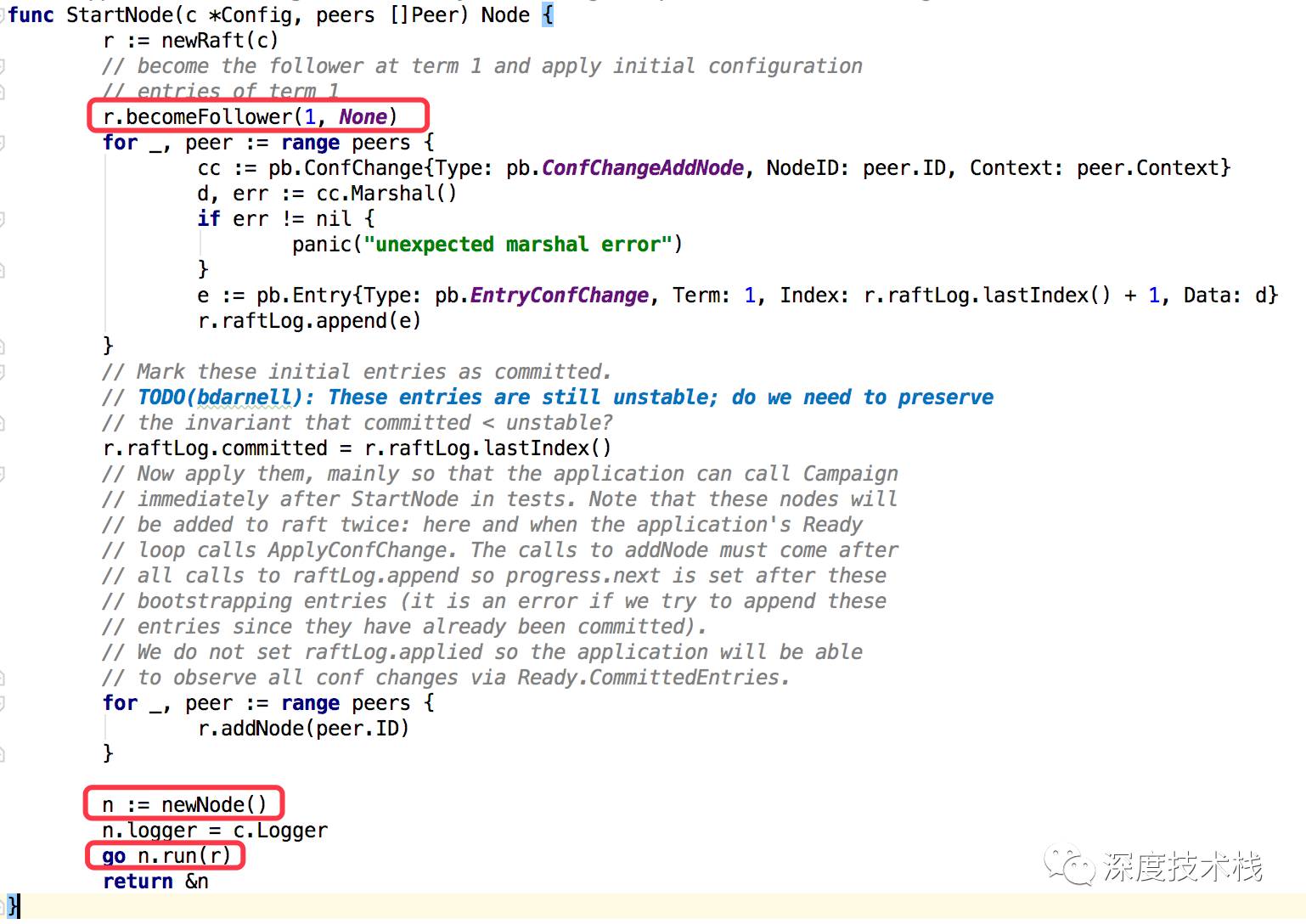
2.1初始化raftNode对象,所有关系Raft协议执行周期内的事项都被包装到了Raft对象中。
2.2初始化节点身份为Follower
2.3构造节点对象(Node)并通过一个goroutine启动
看下2.2 becomeFollower的实现(位于server.go里NewServer方法中):
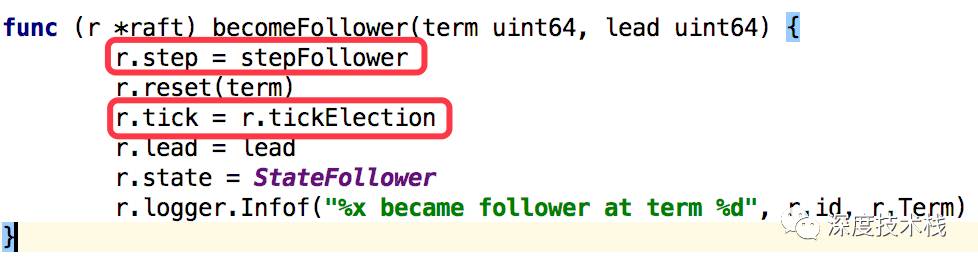
将step赋值为stepFollower方法。tick赋值为tickElection方法,这个地方很重要,接下来的时钟事件tick里就会走tickElection的逻辑。
先看下2.3中node的run方法实现,代码比较长,截重要看:
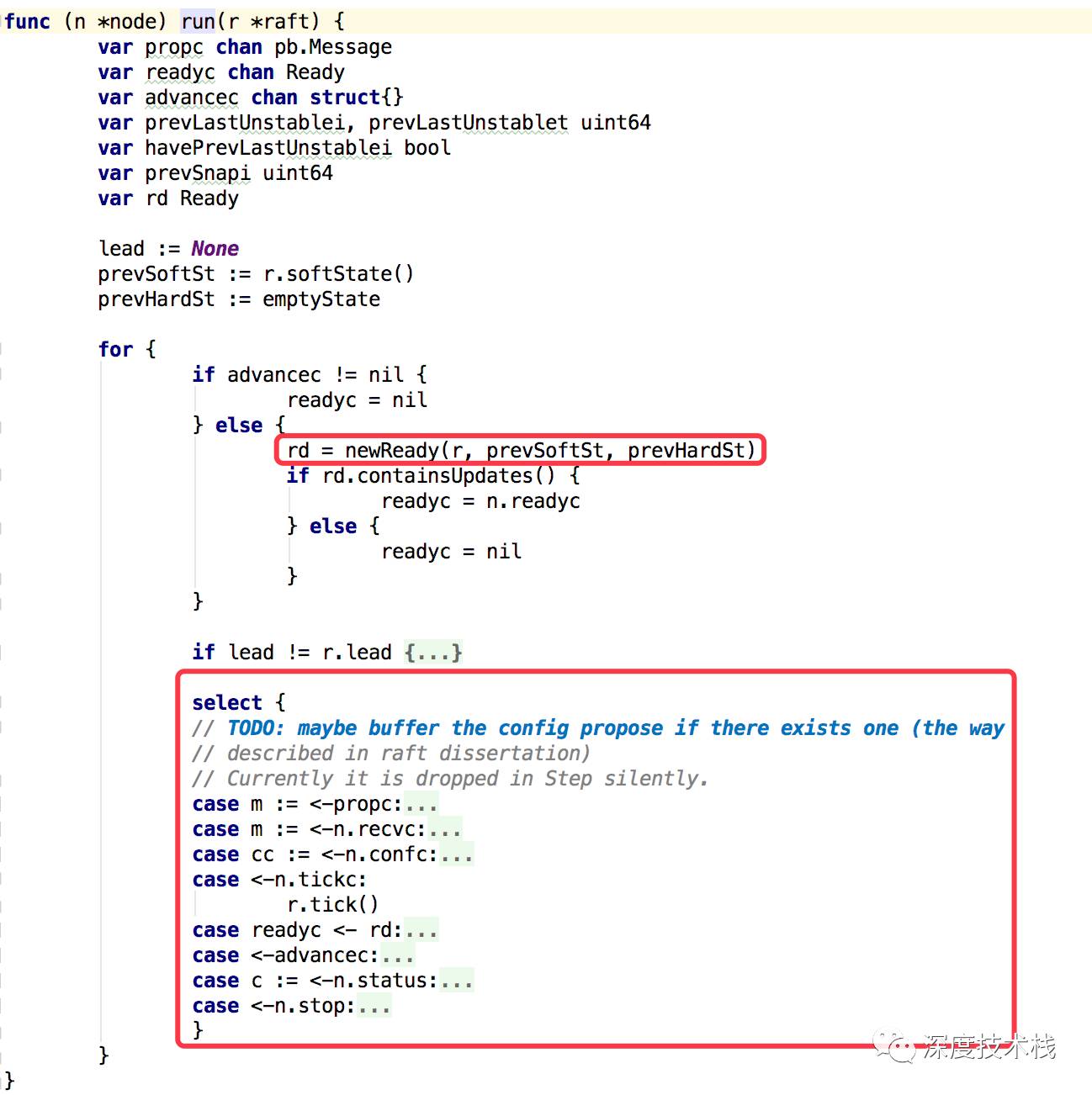
终于看到了1.2中提到的Ready对象了,看下构造过程:
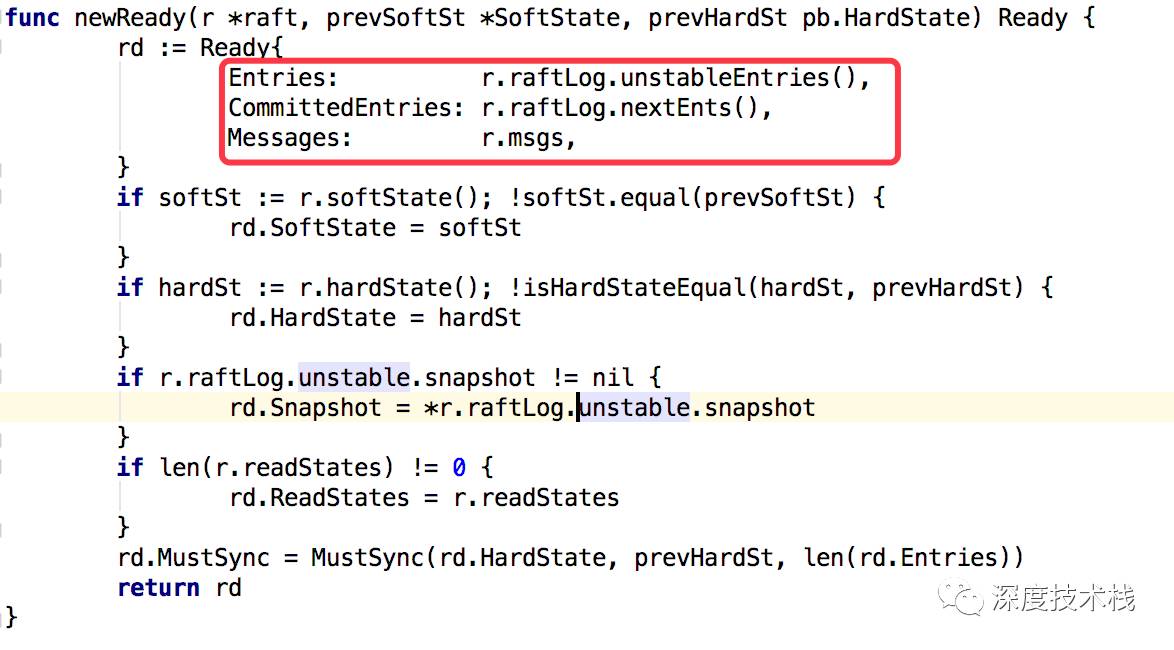 主要关注下Ready构造器里的三个小东东,后面环节至关重要。
主要关注下Ready构造器里的三个小东东,后面环节至关重要。
至此RaftNode和Node的初始化分析完毕了,那么什么触发这么多channel收到消息开始raft运作呢?答案就是时钟事件,1.1节中提到了tick事件的触发频率为heartTime,2.2节中提到了时钟事件的初始化处理函数被赋值为了tickElection(),那么我们就来看下这个函数做了什么:
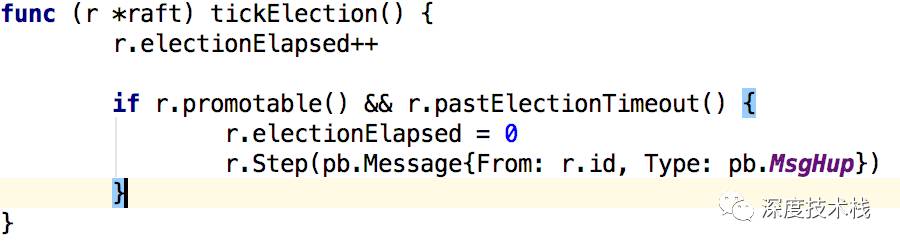
进入方法后,首先自增本阶段经历tick计数器,if里面pastElectionTimeout方法会校验electionElapsed是否达到randomizedElectionTimeout,这是个很有意思的逻辑,randomizedElectionTimeout的取值范围是[electiontimeout,2 * electiontimeout - 1]间的随机数,这就使得每个follower处于这个阶段的时间是错开的,这对于后面的投票有关键作用。而当这个逻辑计数器electionElapsed达到randomizedElectionTimeout了后,就会触发调用Step函数,并构造了一个消息类型为MsgHup的消息发送给自己,看下Step的实现逻辑,这个方法用来处理节点收到的所有消息(包括发送给自己的):
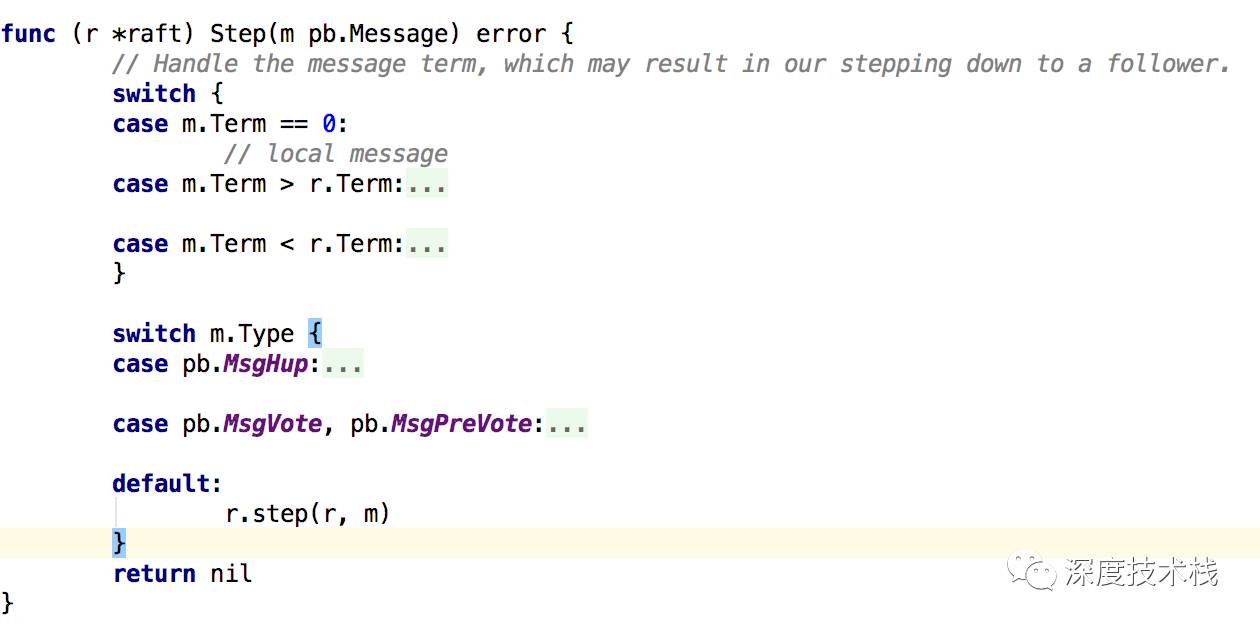
tickElection里面构造的消息是MsgHup类型的:
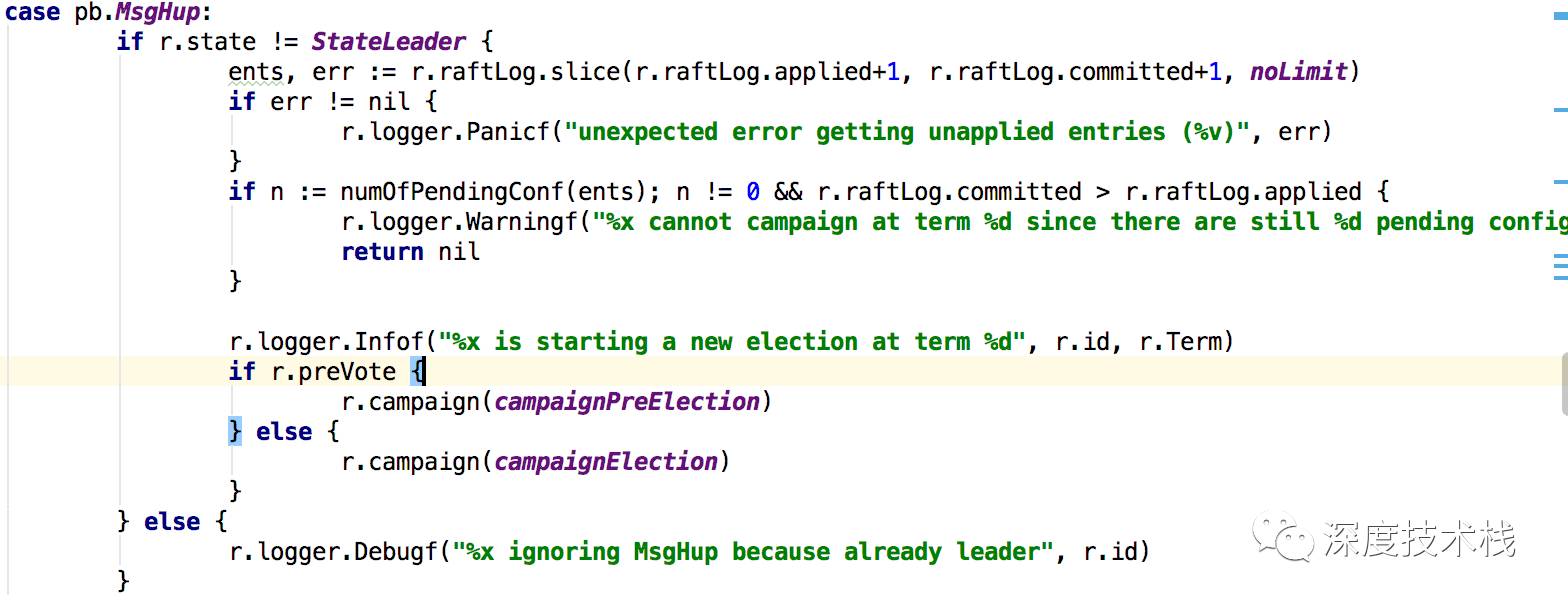
正常情况下state不应该是StateLeader状态。
3.1 检查下是否有日志还未应用到raft状态机的。
3.2 是否开启两阶段开关,若是,则发送预竞选消息给其它节点,否则执行3.3
3.3 发送竞选消息给其它节点
我们这里只讨论单阶段的情况下raft的实现。
3.1 中我所提到了的log其实就是系统应用中的binlog模式,Etcd里的binlog分为3种阶段:
1.unstable阶段,这时候只是生成、发出了消息,但是并没有获取到集群的认可。
2.commit阶段,这时候是前一个阶段的消息获得了集群二分之一参与者的认可。
3.apply阶段,将commit阶段的日志应用到状态机中。
这些log在选举阶段用不到,主要是用在etcd节点状态改变中,在选举的过程中只会去同步、恢复这些log。
而这些日志的存储也分为3部分:
1.raft协议使用的部分,全部存储在内存中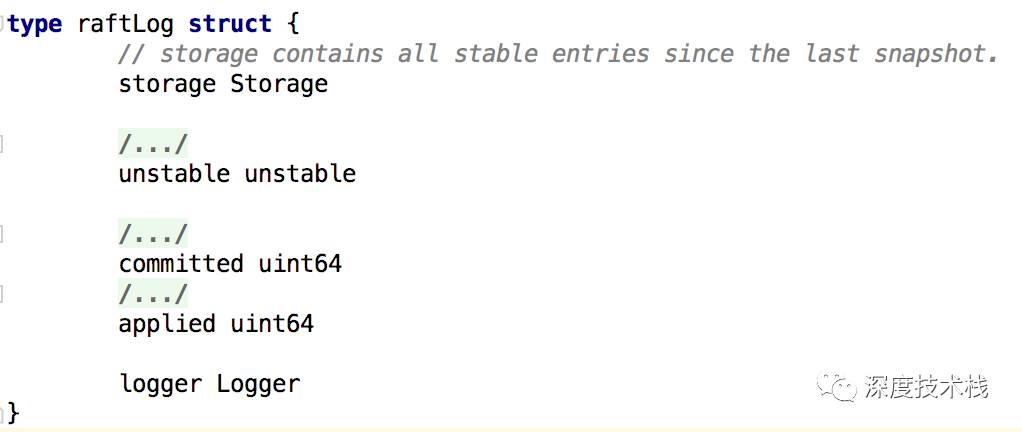
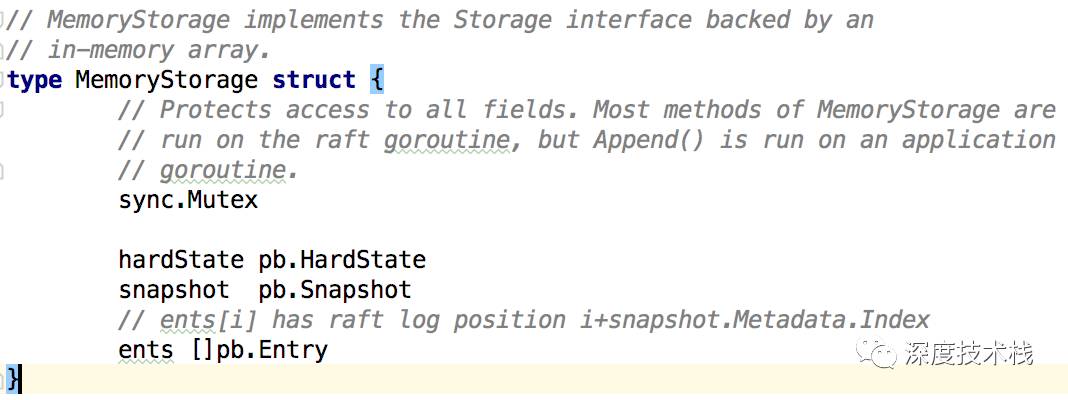
Committed、applied存放在storage中,在raftLog里面存的是索引指针,这里面的storage是MemoryStorage,由于这部分和下面的unstable是全部存储在内存中的,所以重启后会丢失,这时候就要通过后面会介绍的etcd storage结构去恢复数据。
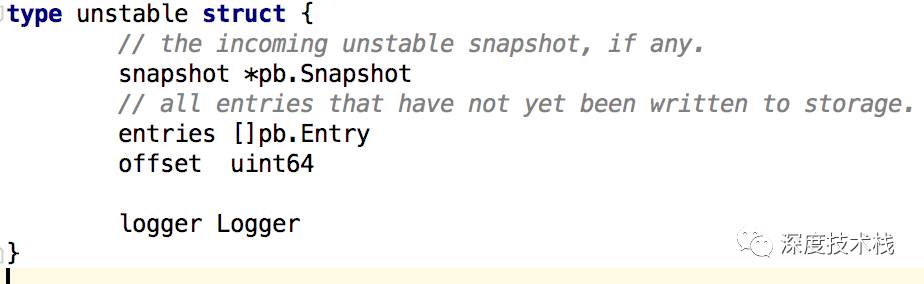
而unstable存在自身的结构中。
 2.etcd storage,etcd实现的结构,主要存储2部分,一个是binlog(WAL),一个是快照snapshot(Snapshotter)。由于这两处是落盘的,所以用于重启后恢复数据。其中binlog是跟在上一次生成快照之后的。
2.etcd storage,etcd实现的结构,主要存储2部分,一个是binlog(WAL),一个是快照snapshot(Snapshotter)。由于这两处是落盘的,所以用于重启后恢复数据。其中binlog是跟在上一次生成快照之后的。

3.etcd store,etcd的KV存储结构,主要是集群节点状态的值,本文不分析。
从3.1中我们可以看出raft不允许竞选阶段自身还存在处于2->3阶段(有消息未得到集群认可)的日志。
看下3.3中raftNode的campaign方法实现:
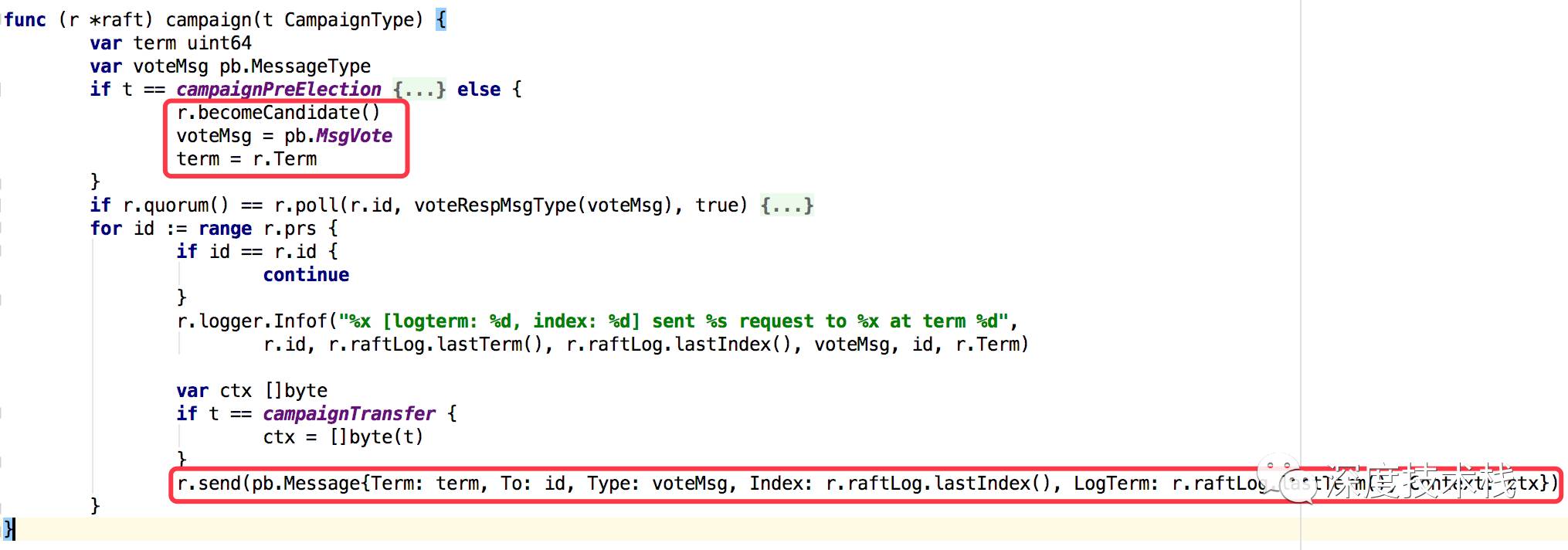
4.1 将身份由follower(参与者)转变为candidate(竞选者)
4.2 创建MsgVote类型的消息,并发送给集群内的所有节点
看下4.1中becomeCandidate的实现
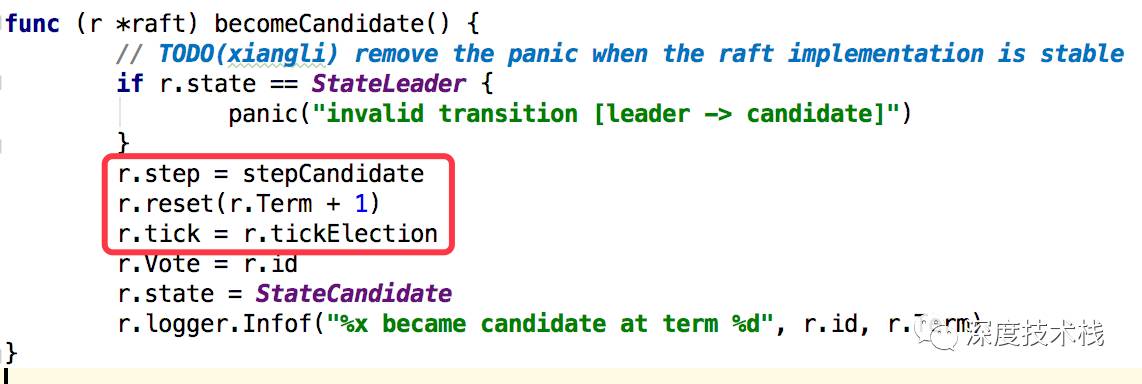
5.1 将自身的step函数定向到stepCandidate,在其它节点消息到来后会进入这个函数处理,之前为stepFollower。
5.2 重置节点选举纪元为递增值。
5.3 将自身的tick函数定向到tickElection,时钟函数触发后会执行这个函数逻辑。
看下4.2中send函数的实现:
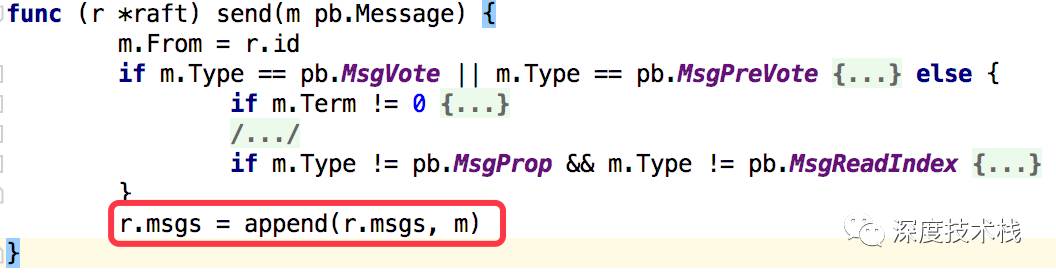
消息是放在raftnode的msgs属性中,那肯定有一个地方要从中取出来调用IO模块去发送,其实就是在2.3中node.go里node.run方法中,构建了Ready对象,对象里就包涵被赋值的msgs,并最终写到node.readyc这个channel中,看下这个case实现:
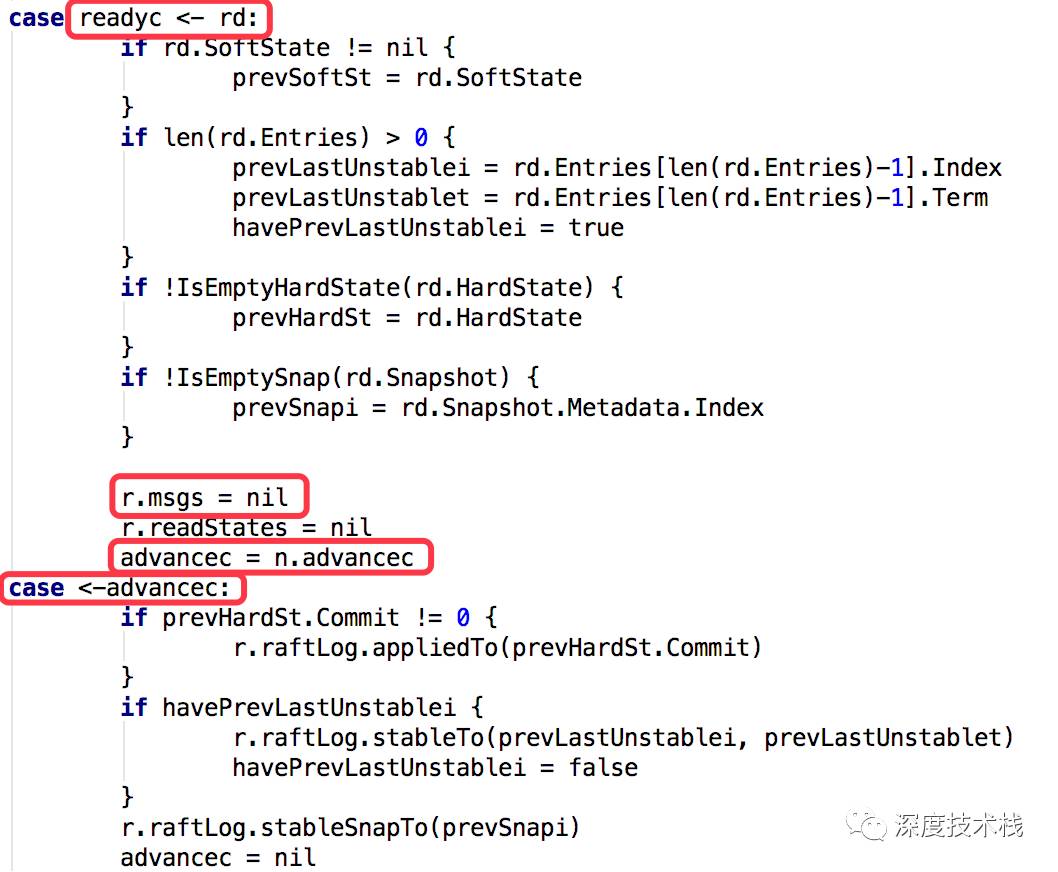
这里有一处并发,就是readyc->rd,rd不仅写入了readyc这个channel,由于之前readyc被赋值为了n.readyc:
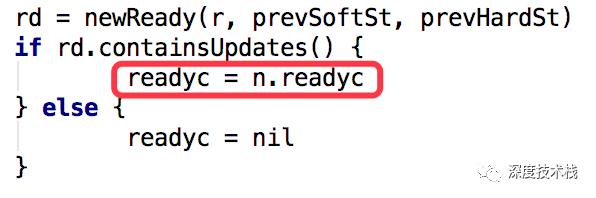
所以rd这个消息同时写入了2个channel,会触发2个地方的case被调用,一处就是上图贴的node.run里的case,这里面主要是记录一些状态,另一处很重要,是真正的send逻辑,位于raft.go中的start方法case rd := <-r.Ready()分支下,代码很长,我捡主要的说:
6.1 如果rd.Entries不为空,则append到serverstorage的WAL中,并append到raftStorage的entrys中。
6.2 如果rd.Entries不为空,则append到serverstorage的Snapshot中,并append到raftStorage的Snapshot中。
6.3 调用sendMessage发送rd.Messages消息
6.4 调用r.Advance()做后续处理
6.5 如果身份是Candidate,则要阻塞等待到apply该消息才可执行下次循环。
6.1和6.2是apply日志后的落盘备份步骤,Candidate的选举开始不会触发,这里我们主要是6.3->6.5详细分析下:
sendMessage的实现是etcd自己实现的一套异步的IO机制,最后也是调用etcd的http包实现的,本文主要研究raft的流程实现,就不进去细致分析了。
当sendMessage发送完毕后,其它node节点会受到消息。消息返回流程是node.go的Step方法->node.go的step方法-> node.go的run方法的recev通道事件触发->node.go的step方法,而其它节点如果还没触发tick事件,则身份就还是follower(前面说过,触发tick事件的时间是个范围间的随机值,所以每个节点的转换身份的时间是错开的,很大概率总会有一个节点最先触发),如果是follower,则step方法是stepFollower,如果已经变成了candidate,则step方法是stepCandidate。而这里其实还没进stepFollower就被上一层step方法内处理掉了,因为这里对于MsgVote和MsgPreVote类型消息做了处理:
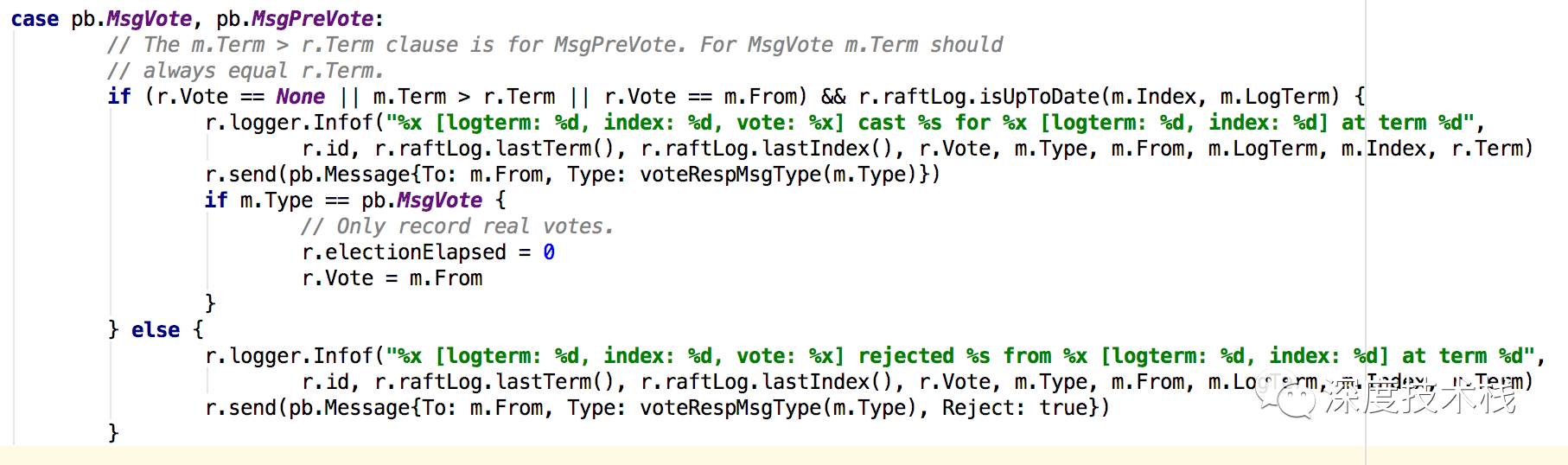
如果符合以下条件:
本节点还尚未给任何节点投过认可票
本节点的选举纪元小于等于消息源节点的选举纪元
本节点的消息索引小于等于消息源节点的消息索引
Follower会发送MsgVoteResp消息给Candidate,否则不回复任何信息。
Candidate在心跳周期内收集MsgVoteResp消息数量,当达到Quonum(二分之一参与者+1数量)后,commit该消息,升级为Leader。具体实现如下(raft.go):
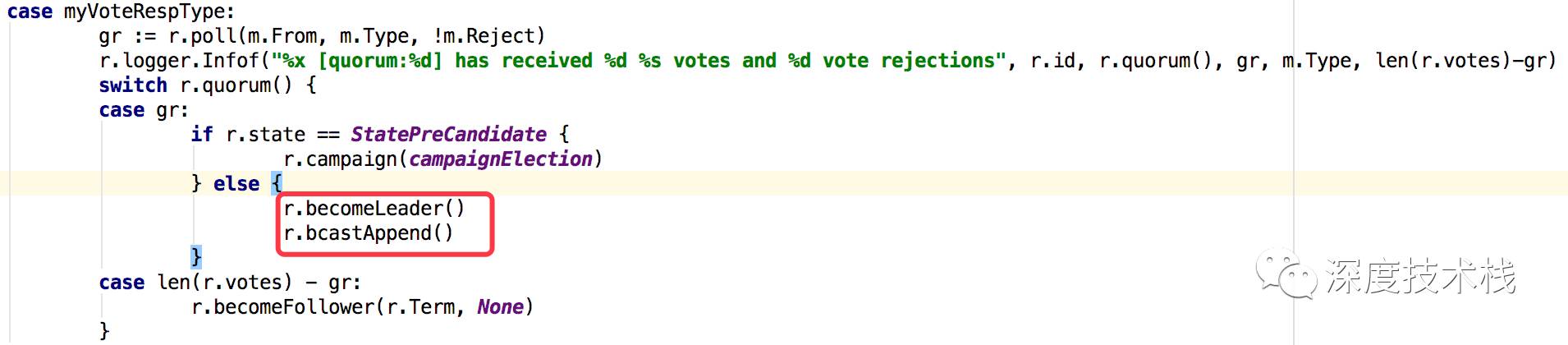
看下becomeLeader的实现:
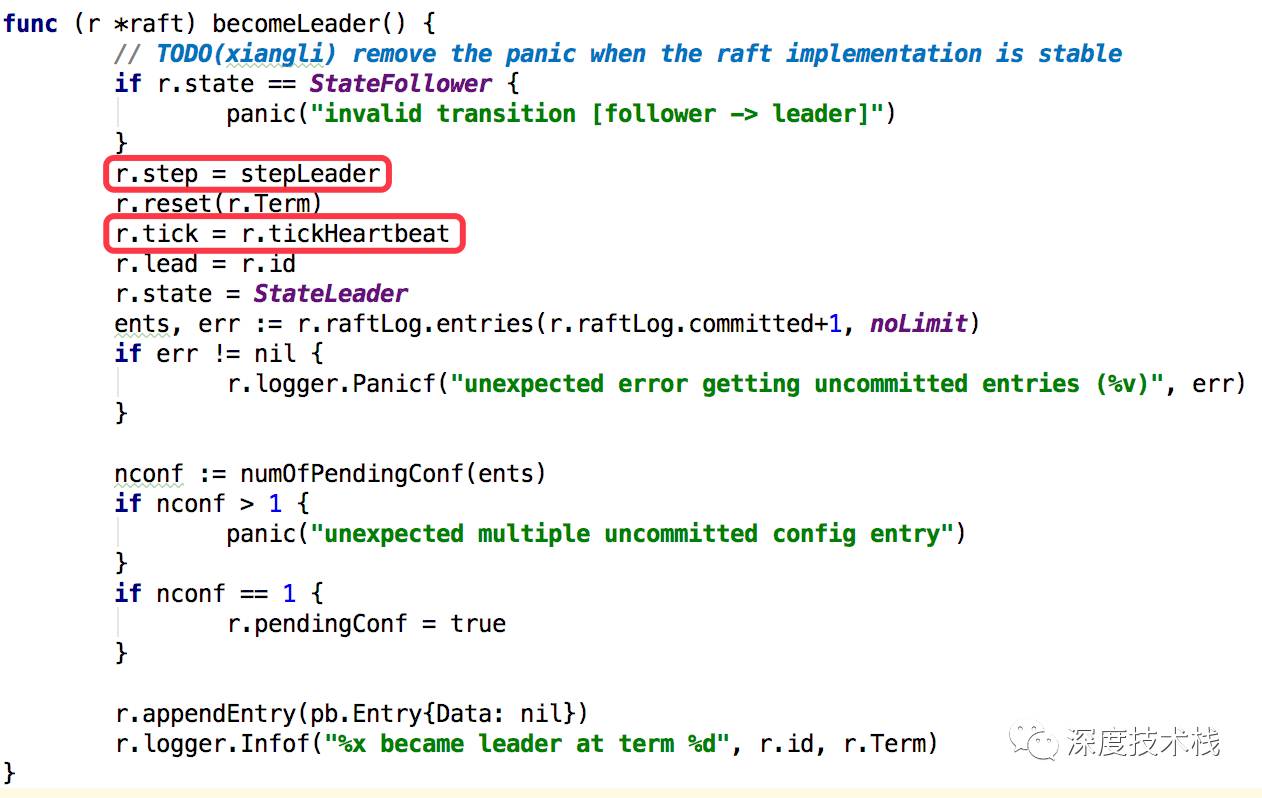
在将自身状态设置为leader之后,会调用bcastAppender去发送”登基请求”给所有集群内其他节点,最后会调用sendAppend方法去发送:
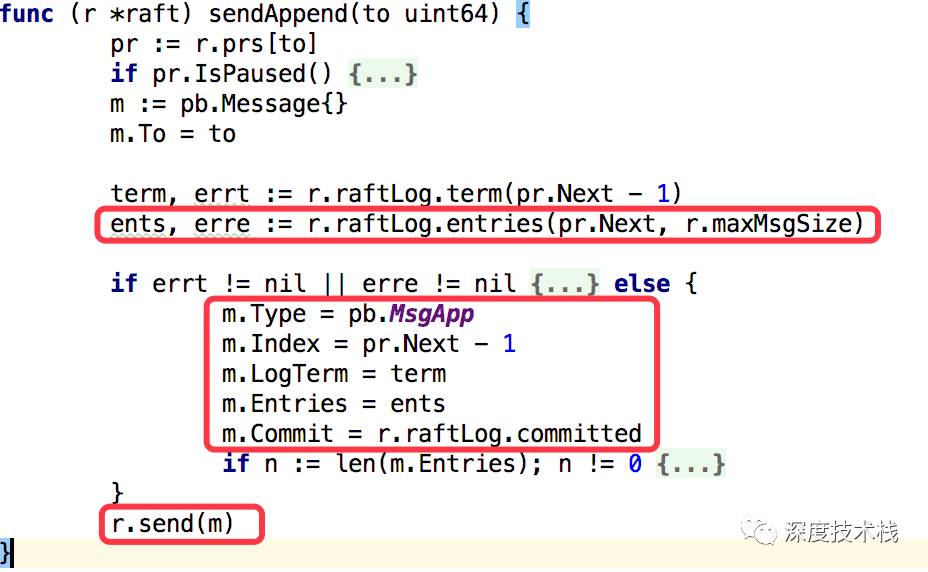
这里会取出每个节点当前的日志索引值,通过r.raftLog.entries方法去和本节点的日志索引值比较,取得该节点应该更新的entries集合,注入到消息m中,设置消息类型为MsgApp,发送出去。
看下follower收到MsgApp消息的处理,这次没在Step中被截获,消息落到了stepFollower中:
7.1 让选举逻辑计数器(就是那个会通过tick函数递增的计数器)清0,这样就不会触发该节点升级为Candidate,让它们晋升无望…下面就通过leader的心跳来清空这个计数器。否则达到时钟事件后就会被认为leader宕机。
7.2 设置leader为消息源
7.3 更新本地数据。
handleAppendEntries实现:
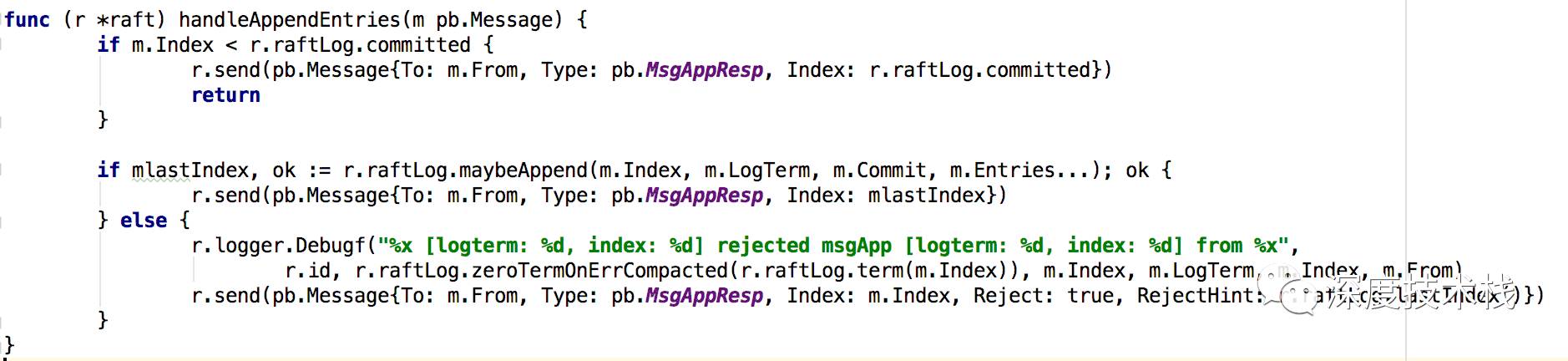
如果本地日志索引比leader还新,则直接回复MsgAppResp消息,并传过去本地日志索引值。
尝试append本地数据,里面就是调用truncateAndAppend方法写入unstable log,然后更新commit index将unstable log升级为stable log,并回复MsgAppResp消息并带回结果。
再来看下Leader收到MsgAppResp消息的处理(raft.go stepLeader方法):
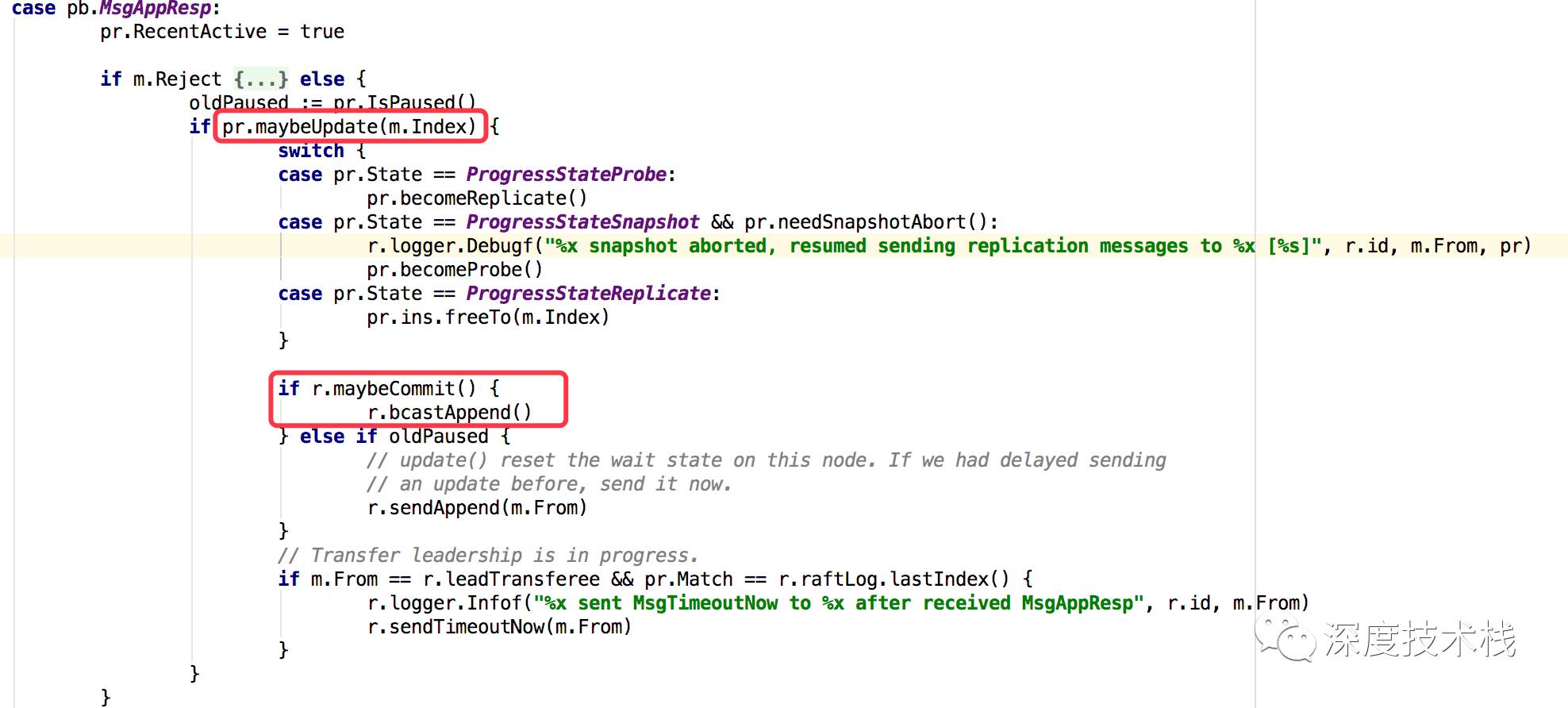 1.首先会通过maybeUpdate方法更新各个节点的index(本地会有一份process的状态缓存)。
1.首先会通过maybeUpdate方法更新各个节点的index(本地会有一份process的状态缓存)。
2.通过maybeCommit方法(里面是一个排序index,折中获取平均值与本地值对比的逻辑)确认集群内二分之一节点的commit值达到什么程度了,将这个值与本地commit值对比,更新为最大值(符合二分之一认可的就视为集群认可)。
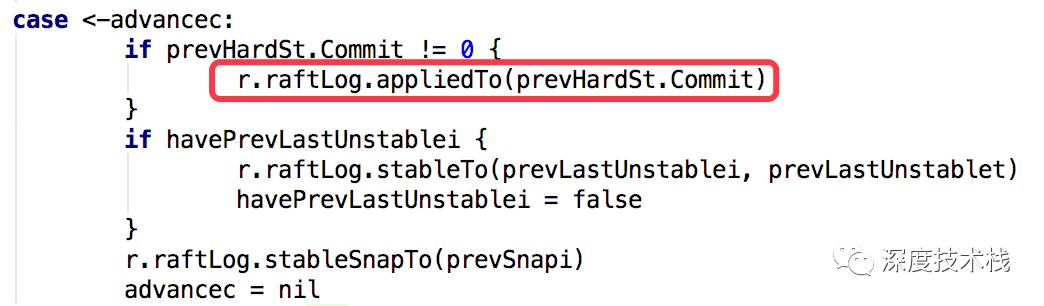
那么当commit值超过lastApply值后,要将新commit的log entries进行apply操作,操作的代码还是在node.go的run方法里(具体参考2.3中的readyc和advancec通道逻辑,当readyc中有了Ready对象后,处理完消息最终会通过r.Advance()方法获取通道并往advancec插入一条消息触发apply操作):
3.若第2步有提升commit值,则尝试用新commit值与该节点index对比获取该节点未更新的值,包成msg发送给该节点进行更新。
前面说的都是Candidate在时钟周期内收集到了1/2的集群同意,Candidate升级成为了Leader,那如果没收集齐呢?则会再次触发tickElection,重新进行下一轮选举。
那么Leader的tick函数之前看过了被赋值为了tickHeartbeat,而tickHeartbeat做了什么事情呢?
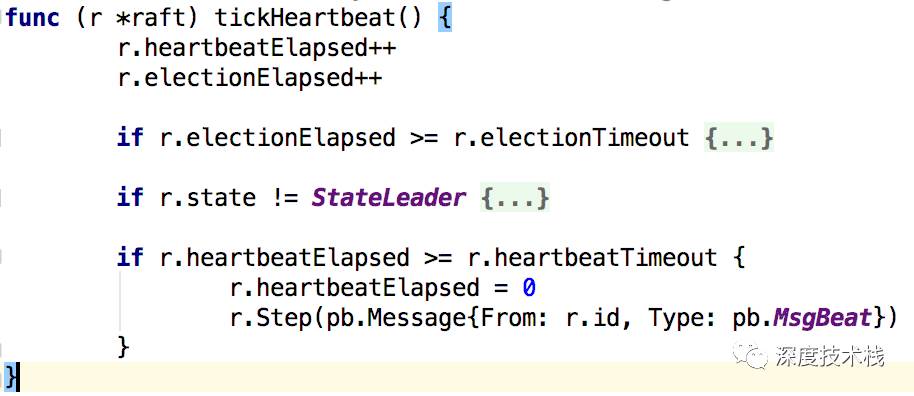
1.心跳计数器自增
2.若心跳计数器达到heartbeatTimeout则发送MsgBeat消息给集群内的其它节点维持Leader地位与同步消息。这个heartbeatTImeout在etcd中被初始化为1。所以心跳事件是1*ticktime。
MsgBeat的发送在stepLeader中case pb.MsgBeat下,最终会调用sendHeartBeat方法:
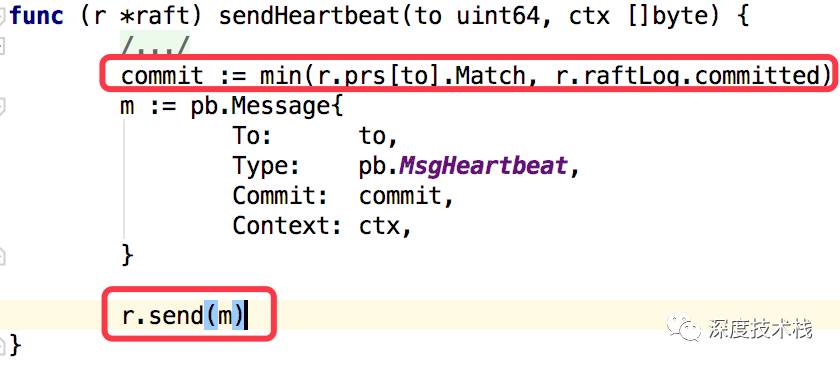
根据本地对于节点的match值和本地committed值取最小值,发送到其它节点。
看下其它节点收到心跳请求的处理函数:

1.更新本地的commit值和Leader上对于该节点认知的commit值一致
2.发送MsgHeartbeatResp消息给Leader。
那再回来看下Leader对于MsgHeartbeatResp的处理:
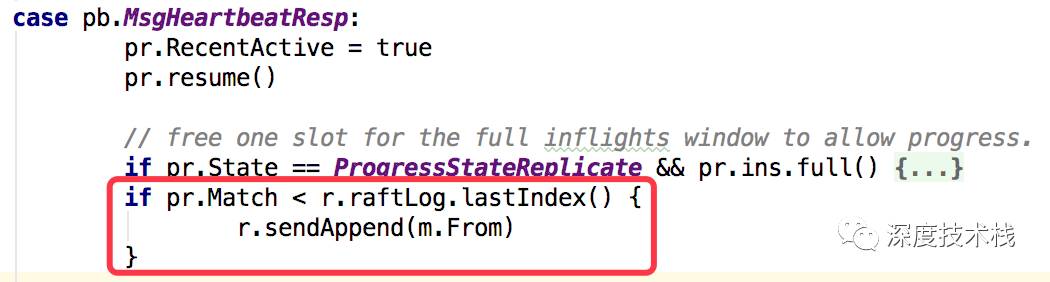
这里面会取出Leader中unstable log的最新一条的index去和Leader认知该交互节点的最新一条index(Match)进行比较,若Leader新,则发送MsgApp请求去通知该节点更新日志。发送MsgApp请求和交互的相关分析请参照前面7.3节描述。
最后再来说下当有节点状态改变(增删改节点),etcd是如何处理的,进入到node.go的ProposeConfChange方法:

看下Step的实现:
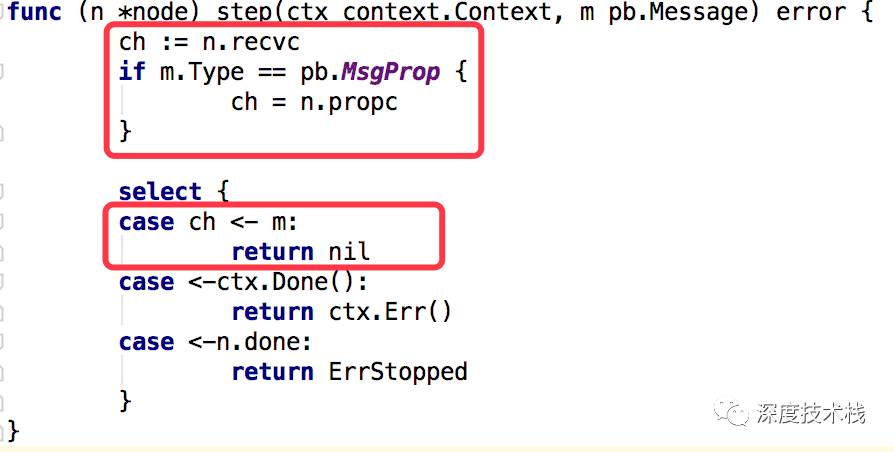
1.recvc channel是发送消息自己接受处理
2.propc channel是发送消息给其它节点处理
这里由于我们的消息是MsgProp的,所以会发送给其它节点,消费消息的地方在node.go的run方法中:
最终会进入stepLeader的case pb.MsgProp分支:
其实就是将节点改变的日志通过appendEntry方法写入本地unstable log,并调用bcastAppend方法通知集群内其它节点来同步。同步流程上面介绍过了,不再赘述。
总结:
raft维持集群角色状态的驱动者是时间,主要是2个时间,HeartbitTimeout和elemetionTimeout,前者是follower在这个时间内如果没收到leader发送来的心跳请求,则触发超时,重新进行选举leader流程以及Leader在这个时间到期后会发送心跳请求维持自身地位以及检查其他成员的日志索引。而后者是在选举过程中candidate发现达到elementionTimeout时间内没有选出新的leader,则选举纪元加一,重新选举。整个流程是在运行过程中对tick函数指针以及step函数指针动态赋值实现的,代码组织很巧妙,流程清晰。
三种日志:unstable、commit、stable,unstable是起始状态,并不受集群认可,当得到集群1/2认可后,升级为commit stable并落盘,确保数据不会丢失,之后apply到状态机中。
Raft中最经典的就是elemetionTimeout时间的选取,通过每个follower->elemetionTimeout的不同,大大降低了同时竞争竞选的可能性,我之前做的job是通过随机生成竞选得分来实现一次竞选成功的策略,但是相比于随机时间的实现,增加了很多交互的流程,交互多了就增加了出问题的可能,感觉raft的实现更加合理、巧妙。
我并没有去读etcd的KV存储结构实现,因为主要关注的是raft的实现,很多地方我也只是提了将应用到状态机,并没有去说后面如何应用、如何存储,有兴趣的读者可以进去深读。
Etcd的raft实现代码量很大,光消息类型有19种,如果只是为了了解raft实现,对其中重要的一些类型细致探索就可以了,毕竟作者团队的实现很严格,代码中很多地方的case分支我觉得都进不去,但作者都实现了,还有很多地方打了TODO自问,可见为了完美实现raft,作者花了多少的苦心…
以上是关于etcd源码解读之raft协议实现的主要内容,如果未能解决你的问题,请参考以下文章