白话分布式一致性协议 | raft协议
Posted 光与影的交替
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了白话分布式一致性协议 | raft协议相关的知识,希望对你有一定的参考价值。
在说raft协议前,先看看分布式系统的几个重要属性。
分布式系统
所谓分布式一致性,就是服务器的数据在多台服务器做了备份,当其中少数服务器挂了的时候系统还能正常运行,并且每台服务器存储的数据状态都保持一致。
分布式系统包含三个重要基本属性:
一致性(Consistency):每次读取要么获得最近写入的数据,要么获得一个错误。绝不会读到一个错误的值。
可用性(Availability):每次请求都能获得一个(非错误)响应,但不保证返回的是最新写入的数据。
分区容忍(Partition tolerance):尽管任意数量的消息被节点间的网络丢失(或延迟),系统仍继续运行。
在机器可能挂可能重启,网络延迟导致包丢失或者乱序到达的情况下,怎么保持每台机器的值保持一致呢?raft是怎么做的呢?
基于log的分布式一致性
核心思想:
如果多台机器存的指令序列一样,那么执行后得到的结果必然也一样。
那么问题就变成:如何保证每台机器存的值一样呢?
raft的方法是投票表决。如果对于一个值,即log,有多数机器同意,我们就认为这个值是对的,否则就是有问题的。同样,一个log必须送达到多数机器并被大多数通过才被接受,被接受的log会被标记为已提交状态。 
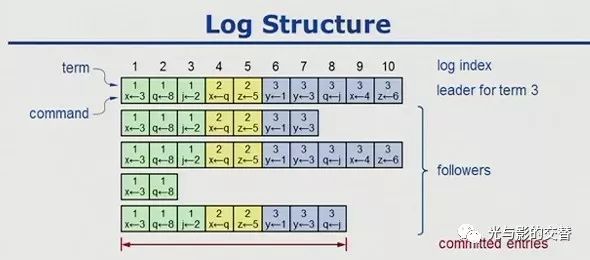
一旦log被标记为已提交状态,这条log就会被所有机器无条件接受并执行,从而保证所有的状态机状态是一致的。 
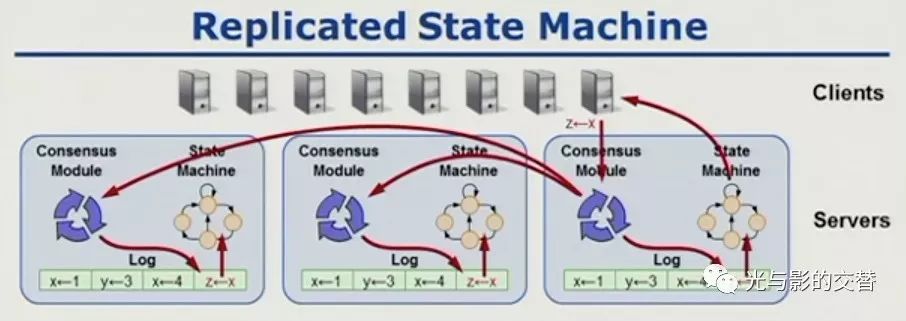
log的发送由leader来完成。为了让系统更加简单易于理解(作者认为易于理解和实现至关重要,为什么?想想paxos吧),raft规定:
只有leader可以发送指令给其他机器,其他角色只能接受。
leader只能增加log,不能修改或删除log。
当leader挂掉的时候,剩下的人就要及时发现leader挂掉,并投票选出新的leader。每个机器都会设置一个计时器,计时器的超时时间是随机的。leader会定期发送心跳包给其他机器,一旦有机器发现超过这个时间还没收到心跳,就认为leader挂了。
从leader挂了到选出新leader的这段时间被称为选举期。每一个选举期有一个任期term。发现leader挂掉的follower会变成候选人,并开始向其他机器发提议让自己做新leader。
当leader的条件很简单,谁票数过半谁就是。
这里有可能出现几个follower在很短时间内同时变成候选人的情况,如果出现票数相同的情况,则随机等待一段时间再发起一轮投票,直到投出结果为止。 
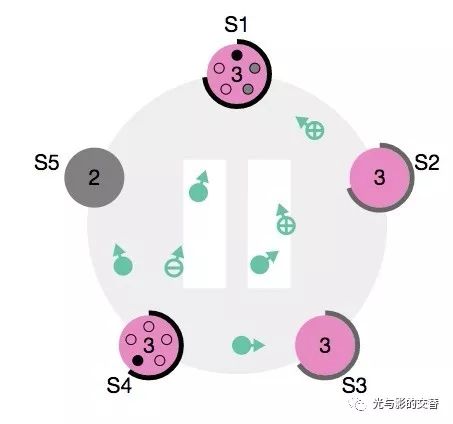
如图,原leader:S5挂了,S1,S4同时变成了candidate。
还有一种情况,在选举过程中挂掉的主又活了,那么候选人在收到心跳包后会立马结束选举变回follower。
怎么判断要投同意票还是拒绝票呢?
如果那些宕机太久或者网络问题严重导致数据有问题的机器当leader, 会导致所有机器的数据都不对。
为了避免这种情况发生,投票的机器会将候选机器发来的最后一个log的任期term和已提交log长度做比较:
term比自己小的是不合格的,因为这说明至少存在一条新leader发出的指令没有被该候选机器接收到而自己有,说明候选者数据太旧,不合格。
如果term一样,比较log长度,看看谁接收的指令多谁就更全。

比如上图。S5一张同意票也拿不到。 S4能得到S5,S2,S1的同意票。
选举的问题说完了,接下去讨论:leader如何保证follower的值和自己一样?尤其是,当某个follower的log出现错误或者丢失的时候?
每次leader在发送最新的log时,会把上个log的index和term也一起发送。如果follower发现index和term与自己的对不上,说明自己的log有问题,这种情况下leader把index减一继续,直到找到对的上的index,把该index往后所有log发给follower,删掉follower该index后面的所有log,替换成leader发给它的值。 
在这里有一个属性要注意: 如果两个logEntry的index和term一样,那么它们必然存着相同的command。为什么?
一个leader在某个term的某个log index处只可能存在一个command值,所以如果其他follower在该term内该index处的值要么为空,要么只可能存该command值。如果它存的是别的command,必然是从其他leader那里得到的,也就是说term必然不一样。
由上面我们又得到另一个属性: 如果两个logEntry的index和term一样,那么它们之前的command必然都一样。因为每一次发log给follower同时也会对前面的值做校验,保证是一致的。
现在leader就能保证follower的值和自己是一致的了。那我们如果要保证系统的一致性(safety),就只要保证leader的值永远是正确的完整的即可。
怎么证明呢?
假设leader的log是有错误的,leader2的任期在leader1的后面,那么leader1的某个已经提交的log在leader1里面,却不存在于leader2中。
由于leader从不删除或者修改log,那么这个log肯定是选举的时候就没在leader2里。
由于log是已提交的状态,说明至少有半数以上的机器里存在这条log。
由于leader2赢得了选举,所以它必然获得了半数以上的投票。
所以肯定有一个follower既包含了那条log又投票给了leader2。
由于follower投票给了leader2,说明leader2的当选时的log最起码和follower一样新,所以leader2应该包含log。这明显是矛盾的。
至此,我们得到几个结论:
leader的值永远是对的。
leader保证多数follower的值和自己是一致的。
如果多台机器存的指令序列一样,那么执行后得到的结果必然也一样。
从而得到如下结论:大多数机器的状态机是一致的且是正确的。
raft协议的核心部分到此就基本就介绍完了。
PS:图都是视频里面截取的:
https://www.youtube.com/watch?v=vYp4LYbnnW8&feature=youtu.be
以上是关于白话分布式一致性协议 | raft协议的主要内容,如果未能解决你的问题,请参考以下文章