一个Raft开源项目的结构分析
Posted 码洞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个Raft开源项目的结构分析相关的知识,希望对你有一定的参考价值。
Raft声称是一种易于理解的分布式一致性算法。有不少工程师们翻了它的论文,参考了很多资料,最后只好怀疑自己是不是智商有问题。
Raft一直以来是很多高级资深程序员技术上的天花板,捅破相当有难度。每次刚刚拿起时汹涌澎湃,过不了多久便偃旗息鼓了,有一种丧尸般的难受。渴望逃离技术舒适区时会经常经历有这种挫折。在分布式系统领域,Raft就是一道很高的门槛,迈过了这道坎后面技术的自由度就可以再上一个台阶。
Raft Paper的内容对于一个普通程序员来说不是太容易理解。选举模块还算比较简单,日志复制表面上也很好理解,快照模块也很形象。但是深入进去看细节,一头雾水是必然的。特别是对集群节点变更模块的理解更是艰难。
开源代码
github上有一个看起来还不错的开源项目,基于Netty的Raft项目的实现,是百度的工程师开源的。
https://github.com/wenweihu86/raft-java github.com
最近花了一些时间把他的代码通读了一边,发现居然都可以理解,感觉离自己造轮子更近了一步。加上之前实现过RPC框架,再撸一套Raft服务应该是可以很快变成现实了。
宏观结构
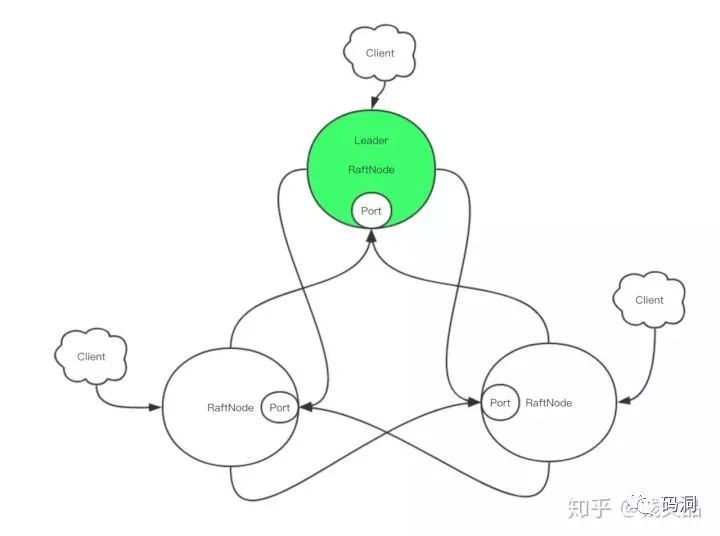
客户端可以连接任意一个节点。如果连接的不是Leader,那么发送的请求会在服务端进行转发,从当前连接的RaftNode转发到Leader进行处理。另外一种可选的设计是所有的客户端都连接到Leader,这样就避免了转发的过程,可以提升性能。
但是服务端转发也有它的好处,那就是当客户端在数据一致性要求不好的情况下,读请求可以不用转发,直接在当前的RaftNode进行处理。所以返回的数据可能不是实时的。这可以挡住大部分客户端请求,提升整体的读性能。
RaftNode的细节
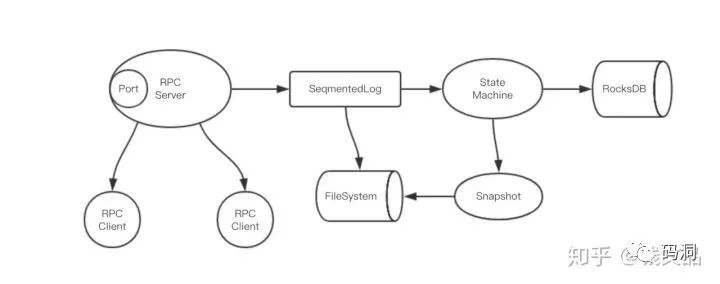
RaftNode中包含的重要组件都在这张图上了。
首先Local Server接收到请求后,立即将请求日志附加到SegmentedLog中,这个日志会实时存到文件系统中,同时内存里也会保留一份。因为作者考虑到日志文件过大可能会影响性能和安全性(具体原因未知,Redis的aof日志咋就不需要分段呢),所以对日志做了分段处理,顺序分成多个文件,所以叫SegmentedLog。
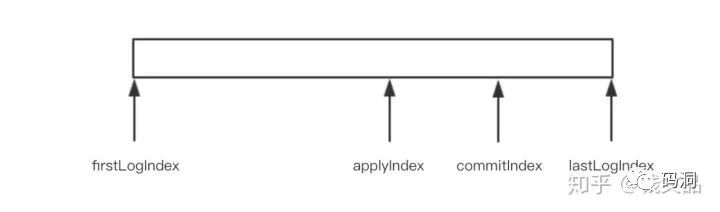
日志有四个重要的索引,分别是firstLogIndex/lastLogIndex和commitIndex/applyIndex,前两个就是当前内存中日志的开始和结束索引位置,后面两个是日志的提交索引和生效索引。之所以是用firstLogIndex而不是直接用零,是因为日志文件如果无限增长会非常庞大,Raft有策略会定时清理久远的日志,所以日志的起始位置并不是零。commitIndex指的是过半节点都成功同步的日志的最大位置,这个位置之前的日志都是安全的可以应用到状态机中。Raft会将当前已经commit的日志立即应用到状态机中,这里使用applyIndex来标识当前已经成功应用到状态机的日志索引。
该项目示例提供的状态机是RocksDB。RocksDB提供了高效的键值对存储功能。实际使用时还有很多其它选择,比如使用纯内存的kv或者使用leveldb。纯内存的缺点就是数据库的内容都在内存中,Rocksdb/Leveldb的好处就是可以落盘,减轻内存的压力,性能自然也会有所折损。
如果服务器设置了本地落盘即可返回(isAsyncWrite),那么Local Server将日志塞进SegmentedLog之后就会立即向客户端返回请求成功消息。但是这可能会导致数据安全问题。因为Raft协议要求必须等待过半服务器成功响应后才可以认为数据是安全的,才可以告知客户端请求成功。之所以提供了这样一个配置项,纯粹是为了性能考虑。分布式数据库Kafka同样也有类似的选项。是通过牺牲数据一致性来提高性能的折中方法。
正常情况下,Local Server通过一个Condition变量的await操作悬挂住当前的请求不予返回。
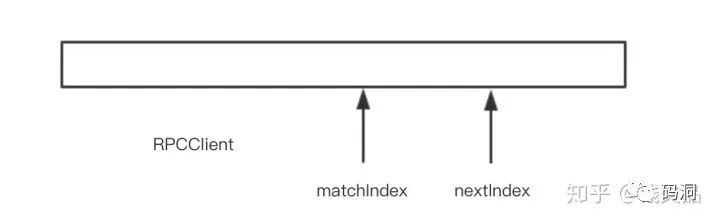
对于每个RPCClient,它也要维护日志的两个索引,一个是matchIndex表示对方节点已经成功同步的位置,可以理解为局部的commitIndex。而nextIndex就是下一个要同步的日志索引位置。随着Leader和Follower之间的消息同步,matchIndex会努力追平nextIndex。同样随着客户端的请求的连续到来,nextIndex也会持续前进。
Local Server在悬挂住用户的请求后,会立即发出一次异步日志同步操作。它会通过RPC Client向其它节点发送一个AppendEntries消息(也是心跳消息),包含当前尚未同步的所有日志数据(从commitIndex到lastLogIndex)。然后等待对方实时反馈。如果反馈成功,就可以前进当前的日志同步位置matchIndex。
matchIndex是每个RPCClient局部的位置,当有过半RPCClient的matchIndex都前进了,那么全局的commitIndex也就可以随之前进,取过半节点的matchIndex最小值即可。
commitIndex一旦前进,意味着前面的日志都已经成功提交了,那么悬挂的客户端也可以继续下去了。所以立即通过Condition变量的signalAll操作唤醒所有正在悬挂住的请求,通知它们马上给客户端响应。
注意日志同步时还得看节点日志是否落后太多,如果落后太多,通过AppendEntries这种方式同步是比较慢的,这时就是要考虑走另一条路线来同步日志,那就是snapshot快照同步。
RaftNode会定时进行快照,将当前的状态机内容序列化到文件系统中,然后清理久远的SegmentedLog日志,给Raft的请求日志瘦身。
快照同步就是Leader将最新的快照文件发送到Follower节点,Follower安装快照后成功后,Leader继续同步SegmentedLog,力图让Follower追平自己。
RaftNode启动流程
RaftNode启动的第一步是加载SegmentedLog,再加载最新的Snapshot形成状态机的初始状态。紧接着使用RPCClient去连接其它节点,开启snapshot定时任务。随之正式进入选举流程。
选举流程
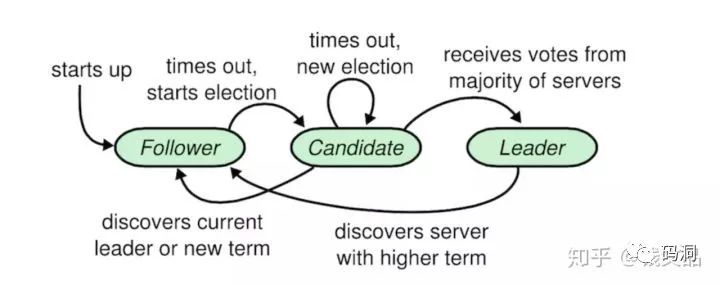
RaftNode初始是处于Follower状态,启动后立即开启一个startNewElection定时器,在这个定时器到点之前如果没有收到来自Leader的心跳消息或者其它Candidate的请求投票消息,就立即变身成为Candidate,发起新一轮选举过程。
RaftNode变成Candidate后,会向其它节点发送一个请求投票(requestVote)的消息,然后立即开启一个startElection定时器,在这个定时器到点之前RaftNode如果没有变身Follower或者Leader就会立即再次发起一轮新的选举。
RaftNode处于Candidate状态时,如果收到来自Leader的心跳消息,就会立即变身为Follower。如果发出去的投票请求得到了半数节点的成功回应,就会立即变身为Leader,并周期性地向其它节点广播心跳消息,以尽可能长期维持自己的统治地位。
当选Leader的条件
并不是任意一个节点都可以变成Leader。如果要当Leader,这个节点包含的日志必须最全。Candidate通过RequestVote消息拉票的时候,需要携带当前日志列表的lastLogIndex和相应日志的term值(尾部日志的term和index)。
其它节点需要和这两个值进行匹配,凡是没自己新的拉票请求都拒绝。简单一点说,组里最牛逼的节点才可以当领导。
日志同步
Leader发生切换的时候,新Leader的日志和Follower的日志可能会存在不一致的情形。这时Follower需要对自身的日志进行截断处理,再从截断的位置重新同步日志。Leader自身的日志是Append-Only的,它永远不会抹掉自身的任何日志。
标准的策略是Leader当选后立即向所有节点广播AppendEntries消息,携带最后一条日志的信息。Follower收到消息后和自己的日志进行比对,如果最后一条日志和自己的不匹配就回绝Leader。
Leader被打击后,就会开始回退一步,携带最后两条日志,重新向拒绝自己的Follower发送AppendEntries消息。如果Follower发现消息中两条日志的第一条还是和自己的不匹配,那就继续拒绝,然后Leader被打击后继续后退重试。如果匹配的话,那么就把消息中的日志项覆盖掉本地的日志,于是同步就成功了,一致性就实现了。
集群成员变化
集群配置变更可能是Raft算法里最复杂的一个模块。为了理解这个模块我也是费了九牛二虎之力。看了很多文章后发现这些作者们实际上都没深入理解这个集群成员变化算法,不过是把论文中说的拷贝了一遍。我相信它们最多只把Raft实现了一半,完整的整个算法如果没有对细节精致地把握那是难以写出来的。
分布式系统的一个非常头疼的问题就是同样的动作发生的时间却不一样。比如上图的集群从3个变成5个,集群的配置从OldConfig变成NewConfig,这些节点配置转变的时间并不完全一样,存在一定的偏差,于是就形成了新旧配置的叠加态。
在图中红色剪头的时间点,旧配置的集群下Server[1,2]可以选举Server1为Leader,Server3不同意没关系,过半就行。而同样的时间,新配置的集群下Server[3,4,5]则可以选举出Server5为另外一个Leader。这时候就存在多Leader并存问题。
为了避免这个问题,Raft使用单节点变更算法。一次只允许变动一个节点,并且要按顺序变更,不允许并行交叉,否则会出现混乱。如果你想从3个节点变成5个节点,那就先变成4节点,再变成5节点。变更单节点的好处是集群不会分裂,不会同时存在两个Leader。
如图所示,蓝色圈圈代表旧配置的大多数(majority),红色圈圈代码新配置的带多数。新旧配置下两个集群的大多数必然会重叠(旧配置节点数2k的大多数是k+1,新配置节点数2k+1的大多数是k+1,两个集群的大多数之和是2k+2大于集群的节点数2k+1)。这两个集群的term肯定不一样,而同一个节点不可能有两个term。所以这个重叠的节点只会属于一个大多数,最终也就只会存在一个集群,也就只有一个Leader。
集群变更操作日志不同于普通日志。普通日志要等到commit之后才可以apply到状态机,而集群变更日志在leader将日志追加持久化后,就可以立即apply。为什么要这么做,可以参考知乎孙建良的这篇文章 https://zhuanlan.zhihu.com/p/29678067,这里面精细描述了commit & reply集群变更日志带来的集群不可用的场景。
最后
文章是写完了,但是感觉还是有点懵,总觉得有很多细枝末节还没有搞清楚。另外就是刚开始以为百度实现的这个Raft应该很完善,深入了解之后发现原来还是有很多不完善之处,这个项目应该只是一个demo,不过作为学习源码使用还是很不错的。后续还得继续研究etcd的raft代码,它的代码要复杂一些,但是应该要完善很多。它具备prevote流程和Leader提交之后的no-op日志同步,这些是raft-java项目欠缺的地方所在。
以上是关于一个Raft开源项目的结构分析的主要内容,如果未能解决你的问题,请参考以下文章
读.Net Core开源项目源码:Owin Katana 的底层源码分析