Raft协议精解
Posted 码洞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Raft协议精解相关的知识,希望对你有一定的参考价值。
RaftServer的基本结构
Raft服务器支持多个客户端并发连接
一致性模块负责接收客户端的消息,追加到本地日志中
一致性模块负责复制日志到其它服务器节点
本地日志commit成功后立即应用到状态机
客户端可以直接查询本地状态机的状态
日志序列的重要变量
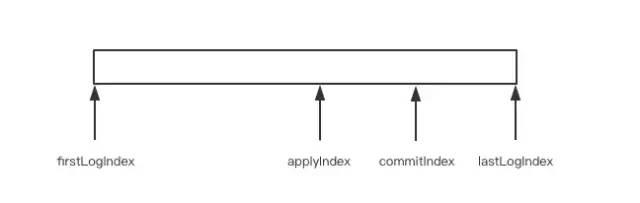
firstLogIndex/lastLogIndex标识当前日志序列的起始位置,如果日志不做压缩处理,也就是没有快照模块的话,那么firstLogIndex就是零值。
commitIndex表示当前已经提交的日志,也就是成功同步到majority的日志位置的最大值
applyIndex是已经apply到状态机的日志索引,它的值必须小于等于commitIndex,因为只有已经提交的日志才可以apply到状态机
服务器重要的状态变量

每个服务器都有自己的日志序列,日志序号索引从1开始,因为0有特殊意义,表示服务器刚刚初始化还没有包含任何日志。日志序列非常重要,是它决定了状态机的状态。
每个服务器都必须有当前的任期号,从零开始,以后逐渐单向往上递增。服务器重启后需要知道当前的任期号才可以正确的很其它节点交流,所以任期号是必须持久化的。
如果给候选节点投票了,要记录下被投票的候选节点ID。如果节点在选举期间给了一个候选人投票后突然宕机重启了,如果没有记下这个值,就很可能会重复投票,又给另一个节点投票去了。这就会导致集群存在多个Leader,也就是集群分裂。
当前已经提交的日志索引位置,服务器初始化时这个值是零表示还没有任何日志被提交。这个位置之前的所有日志都可以安全地应用到状态机中而不用当心会被覆盖。
当前已经被应用到状态机的日志索引位置,它一般和提交索引保持一致。因为一旦提交索引前进了,那么新的已经提交的日志就会立即应用到状态机中,而不应该有任何延时。
Leader需要记录自身日志和所有的Follower日志的匹配位置matchIndex。matchIndex之前的日志Leader和Follower都是一致的。同时还需要记录下一个即将需要同步给Follower的日志位置。处于matchIndex和nextIndex之间的日志就是哪些正在同步中的日志,是Leader已经向Follower发过去的AppendEntries消息还没有得到成功回应的日志列表,用一个高大上的词汇来描述那就是inflight logs。
为什么commitIndex和applyIndex可以不用持久化呢?
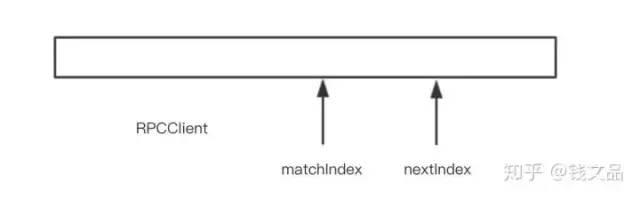
这个和日志复制的机制有关系。首先对于选举,PK的条件不是拼这两个索引值的大小,PK的是最后一条日志的任期号和日志的长度。Leader当选后进行第一次日志复制时,会和Follower进行若干次日志的匹配过程,最终可以得到Leader和各自Follower的日志匹配的matchIndex值。处于majority节点列表的matchIndex的最小值就是当前Leader的commitIndex。所以commitIndex值是完全可以动态计算出来的。 如果所有的日志都保留不截断的话,服务器重启时applyIndex应该等于零。然后重放一下所有的已经提交的日子就可以得到当前的状态机。如果日志截断有快照的话,applyIndex应该正好是日志序列的头部位置,这个位置一般是存储在快照元信息里面的,它是持久化在磁盘中的。
选举阶段候选人请求投票RPC

候选人需要携带自己的任期号,供目标节点比较。同时要提供节点ID,因为投票的节点需要记录被投票的节点ID,就是前文中的voteFor字段。
候选人需要携带自身日志序列的最后一条日志的任期和索引号,供目标节点进行日志的比较。
如果候选人的任期号比自己还小,那么就拒绝投票
如果自己在当期任期已经投票了,那么也必须拒绝投票。同一任期内不得重复投票,否则会导致多个Leader的产生,也就是集群分裂
否则比较尾部日志的任期号和索引值,如果候选人的日志更新一些,那就支持投票。否则就拒绝投票。
拒绝投票一般不是不响应投票请求,而是快速地给予一个状态为failure的响应。还需要携带投票者的任期号,以便候选人能跟上时代(更新自己的任期号)。
所谓日志的update-to-date,指的是最后一条的任期号是否更大,如果一样大的话,最后一条的日志序号是否更大。
日志复制阶段Leader的日志同步请求

日志同步需要携带Leader的任期号和Leader的节点ID。之所以要携带节点ID,是因为Follower可以告知客户端Leader是哪个节点,因为客户端第一次来连的时候可能是选择了任意一个节点。
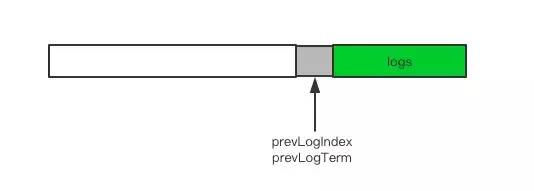
日志同步需要携带需要同步的日志列表以及日志列表前面最后一条日志的索引prevLogIndex和任期号prevLogTerm。Follower需要这两个值来和自己的本地日志进行比对。
日志同步需要携带Leader的日志提交索引值,如果这个值比本地日志的提交索引值要大,那就将本地的这个值往前进。提交索引值之前的所有日志就可以安全的apply到状态机了。
如果同步请求的任期号比Follower的任期号还小,那就直接拒绝,并带上自己的任期号,以便Leader进行跟上时代(更新自己的任期号)。
如果Follower本地日子的prevLogIndex位置处没有日志或者对应的term不匹配,那就拒绝同步。同时将日志在不匹配的位置处进行截断,后面的所有日志统统剁掉。
Leader收到了Follower的拒绝时,如果响应的任期号比Leader本身还大,那么Leader理解退职变身Follower。如果响应的任期号不超过Leader,Leader就将同步的日志列表往前挪一个位置,再重试同步请求。
Follower如果在prevLogIndex处日志的term和请求消息中的prevLogTerm匹配,那么就将消息中的日志追加到自身的日志序列上,这个时候就可以向Leader响应成功了。
Leader收到成功响应后,更新内部记录节点的matchIndex值,然后再前进全局的commitIndex值,并将最近刚刚成功提交的日志应用到状态机中。
基本规则

随意日志同步的持续进行,commitIndex也一直在前进。已经commit的日志要及时apply到状态机,applyIndex要紧跟者commitIndex往前走。以免客户端从状态机中查询数据时数据不太实时。
如果收到的任意RPC消息中任期号大于当前节点的任期号,那么立即跟新当前的任期号,并转换角色为Follower。任期号小了,意味着落伍了。原因可能是网络分区后又恢复了,例如下图中的灰色节点。
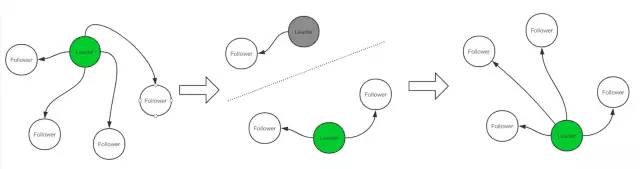
Follower是被动的,只会从candidate和leader接受RPC消息,而不是主动发出。
如果长时间收不到任何任何RPC消息,就会转变成candidate,参与选举。
节点一旦变成candidate,立即参与选举。增加自己的任期号,给自己投票,向其它节点发送RequestVote RPC消息进行拉票。
candidate收到大多数节点的投票后,立即变成Leader。
如果期间收到了其它节点发来的AppendEntries日志同步请求,立即转变成Follower。表名新的leader诞生了,选举尘埃落定。
如果选举超时没有形成多数派,那就重新开始选举过程。
Leader一旦当选,立即向其它节点同步一个心跳消息(no-op)。这是为了确保当前没有提交的日志也能尽快得到提交。Leader只会追加日志序列,刚当选时已经存在的日志序列,Leader会努力将它们同步到所有节点,如果Follower存在的日志和Leader有冲突,就会被抹平。最终Leader和Follower的日志就会完全一致。
Leader收到客户端请求后,首先追加到本地日志序列,待日志成功apply到状态机后才向客户端响应。
如果Leader当前的日志序列增长了(lastLogIndex > nextIndex),立即向所有的Follower发送日志同步消息。
如果Follower成功响应,那么就及时跟新matchIndex和nextIndex值。
如果Follower失败响应,那么递减nextIndex值重新同步。这是Leader采用后退重试法进行日志同步的细节。
如果存在majority的matchIndex前进了,Leader的本地日志序列的commitIndex和applyIndex也要跟着前进。
Leader当选后为什么要立即同步一个no-op日志?
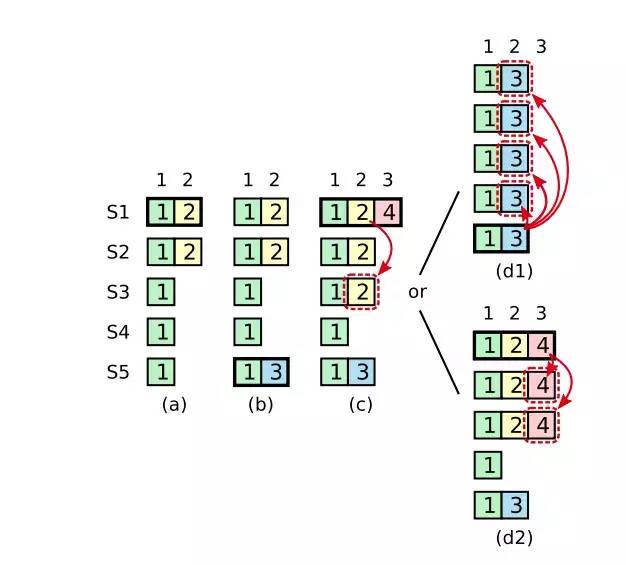
图中S1~S5为集群中的5个节点,粗线框表示当前是leader角色。每个方框表示一条日志,方框内的数字代表日志的term。 现在假设没有no-op日志,会出现什么问题
(a)图,S1为Leader,将黄色的日志2同步到了S2节点,突然就崩溃了
(b)图,S5当选,将蓝色的日志3追加到本地日志序列,又突然崩溃了
(c)图,S1重新当选,追加了一条红色的新日志4到本地,然后又开始同步往期日志,将黄色的日志2又同步到了S3.这时黄色的节点2已经同步到了majority,但是还来不及commit,又突然奔溃了。
(d1)图,S5重新当选,并开始同步往期日志,蓝色的日志3到所有的节点。结果黄色日志2被抹平了,虽然它已经被同步到了大多数节点。
遇到这种情况就会导致一条日志虽然被同步到了大多数节点,但是还有被抹去的可能。
如果我们走(d2)图,leader不去单独同步往期的日志,而是通过先同步当前任期内的红色日志4到所有节点,就不会导致黄色的节点2被抹去。因为leader会采用后退重试法来将自己的日志序列同步到所有的Follower。在尝试同步红色节点4的过程中连带黄色的节点2一起同步了。
例子中是因为S1重新当选后立即收到了客户端的指令才有了红色的日志4。但是如果Leader刚刚当选时,客户端处于闲置状态没有向Leader发送任何指令,也就没有红色的日志4,那该怎么办呢?
Raft算法要求Leader当选后立即追加一条no-op的特殊内部日志,并立即同步到其它节点。这样就可以连带往期日志一起同步了,保障了日志的安全性。
快照同步和日志压缩

当leader和follower之间的日志差异过大时,采用回退重试法同步日志效率低下。而且回退重试法要求发送的日志项包含所有不一致的日志,可能导致消息过大,导致RPC不能正常进行。
快照RPC是以chunk的形式向Follower发送日志,类似于HTTP协议的分块传送。它通过offset字段标志发送的字节偏移,通过done字段标志是否是最后一个消息块来进行分批传送。
快照RPC需要告知Follower当前的快照数据截止的日志索引,这样下次进行日志的增量同步时,从这个索引位置开始继续发送AppendEntries消息将剩下的日志追上。
快照日志处理好和当前Follower已存在的日志序列之间的关系。
如果快照日志最后一个日志项目在Follower当中已经存在,那就可以直接向Leader响应成功。因为这时快照数据是多余的。否则Follower需要将当前所有的日志序列清空,代之以快照日志进行覆盖。
快照是非常消耗资源的操作,所以Leader不能进行的太频繁。一般是等到日志序列的大小达到一个阈值后进行。快照类似于Redis的rdb操作,rdb操作完成,aof日志就可以被截断,于是日志瘦身就完成了。
同样redis的主从日志同步同raft的日志同步也是类似的。当主从日志偏移差距过大时,采用快照同步,快照同步完成后继续采用增量日志同步。
以上是关于Raft协议精解的主要内容,如果未能解决你的问题,请参考以下文章