手绘图解raft算法
Posted 互联网技术窝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手绘图解raft算法相关的知识,希望对你有一定的参考价值。
在现实的分布式系统中,不能可能保证集群中的每一台机器都是100%可用可靠的,集群中的任何机器都可能发生宕机、网络连接等问题导致集群中的某个节点不可用,这样,那个节点的数据就有可能和集群不一致,所以需要有一种机制,来保证在大多数机器都存在的情况下向外提供可靠的数据服务。这里的大多数节点指的是 集群半数以上的节点。
raft算法就是一种在分布式系统中解决集群中多节点之间数据一致性的算法。Golang生态圈中大名鼎鼎的etcd就是使用的raft算法来保持数据一致性的,与raft类似的一致性算法还有Paxos算法、Zab协议等。
其实,raft算法维持数据一致性的核心思想很简单,就是:“少数服从多数”。
leader选举
保证数据一致性,最好的方式就是只有唯一的一个节点,唯一的这个节点读,唯一的这个节点写,这样数据肯定是一致的;但是分布式架构显然不可以一个节点,于是,raft算法提出,在集群的所有节点中,需要有一个节点来充当这一个唯一的节点,在一段时间内,只有这一个节点负责读写数据,然后其他节点同步数据。这个唯一的节点叫 leader节点,其他负责同步数据的节点叫做 follower节点。在集群中,还会有其他状态的节点,例如 candidate节点,这种节点只有在选举 leader的时候才会有。 节点的 leader选举和现实生活中的选举十分类似,就是投票,集群中获票数最多的那个,就是 leader节点,所以为防止出现平局的情况(平局的情况也有解决方案,下文会说),一般在部署节点的时候,会将节点数设置为奇数(2n + 1)。
这些节点是如何选举的呢?我们先从 follower、 leader、 candidate这三种状态说起。 在集群中,有三个节点 A 、B、C。
在集群刚刚开始的时候,他们仨都是 follower。
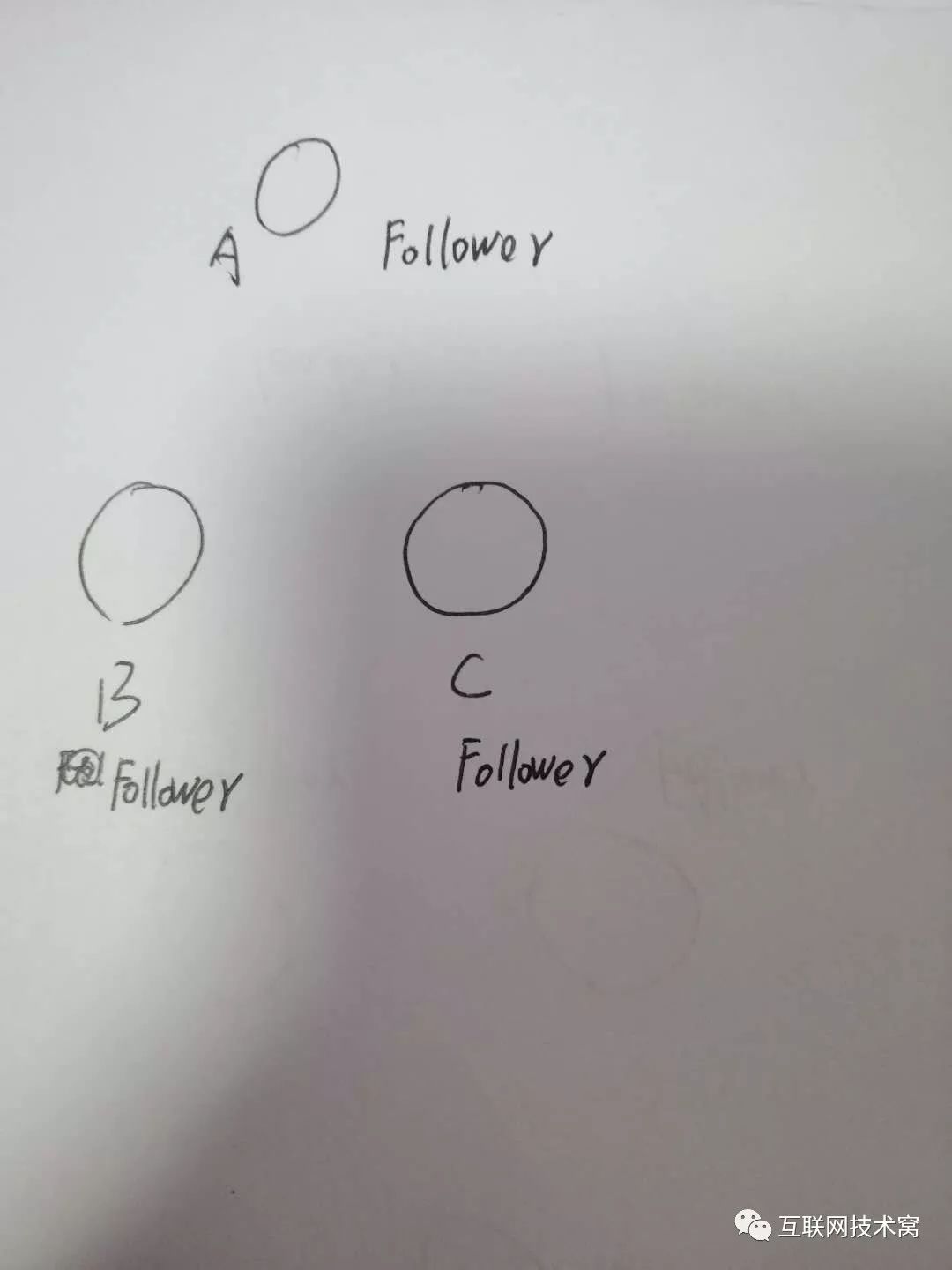
过一段时间后,A变成了 Candidate,这是要选举了!
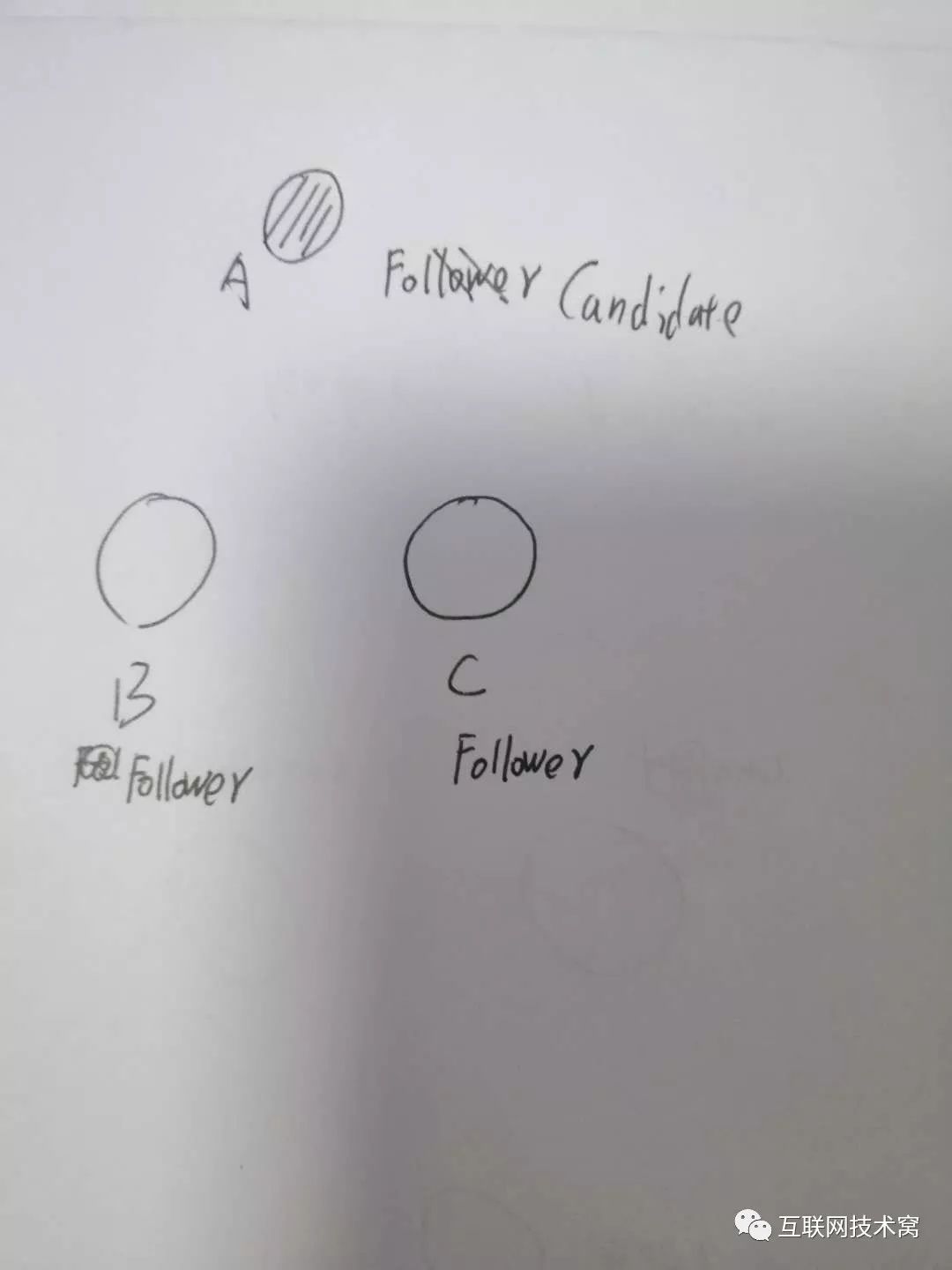
为啥A能变成 Candidate?凭啥?因为A的 election timeout到期了, election timeout是选举超时时间,集群中的每个节点都有一个 election timeout,每个节点的 election timeout都是150ms ~ 300ms之间的一个随机数。每当节点的 election timeout时间到了,就会触发节点变为 candidate状态。A的选举超时时间到了,所以A理所当然变为了 Candidate。
所以,我们知道,其实A、B、C三个节点除了有状态,还有个选举超时时间 election timeout
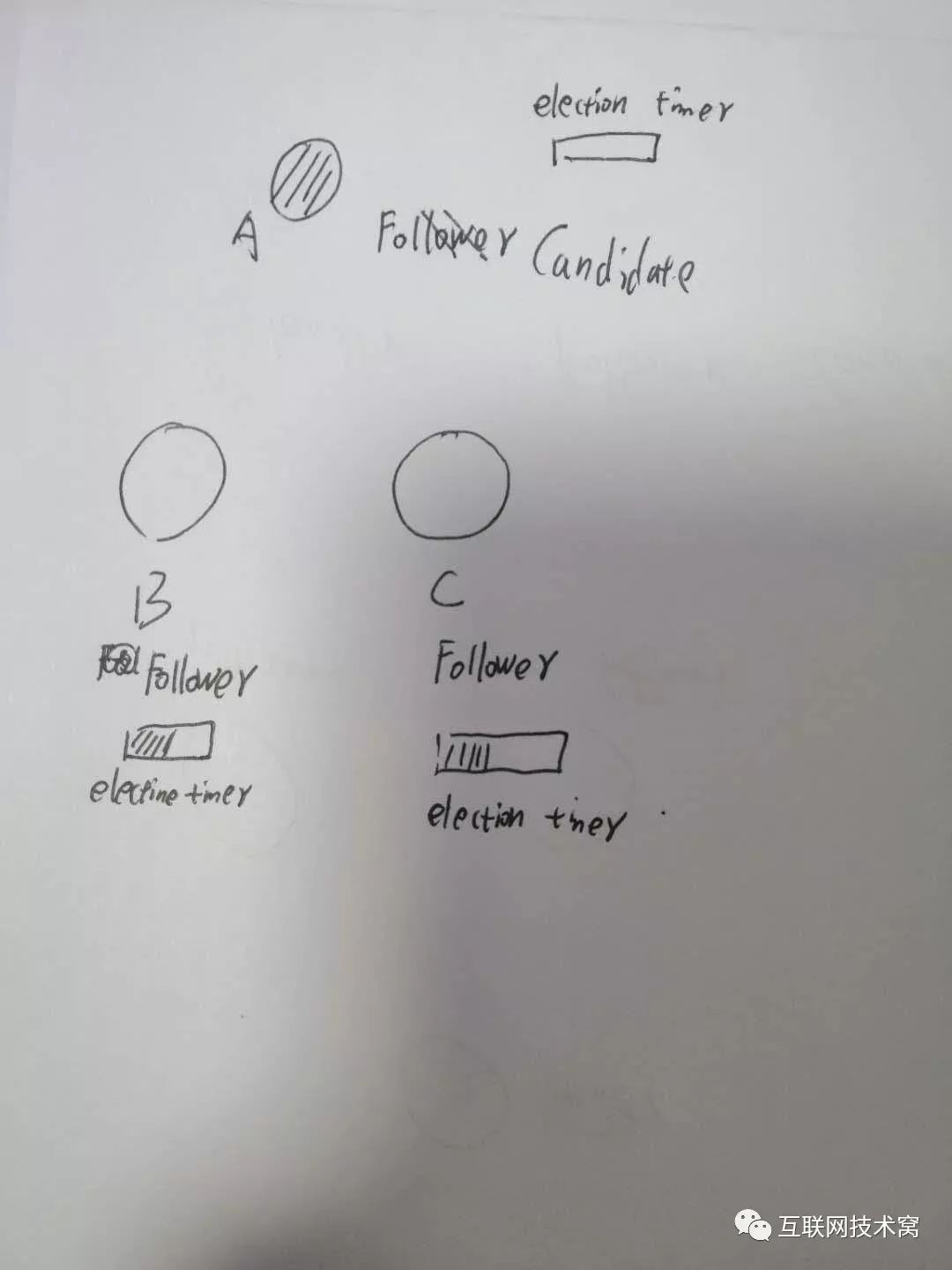
此时, candidate节点A会向整个集群发起选举投票,它会先投自己一票,然后告诉B、C 大选开始了!
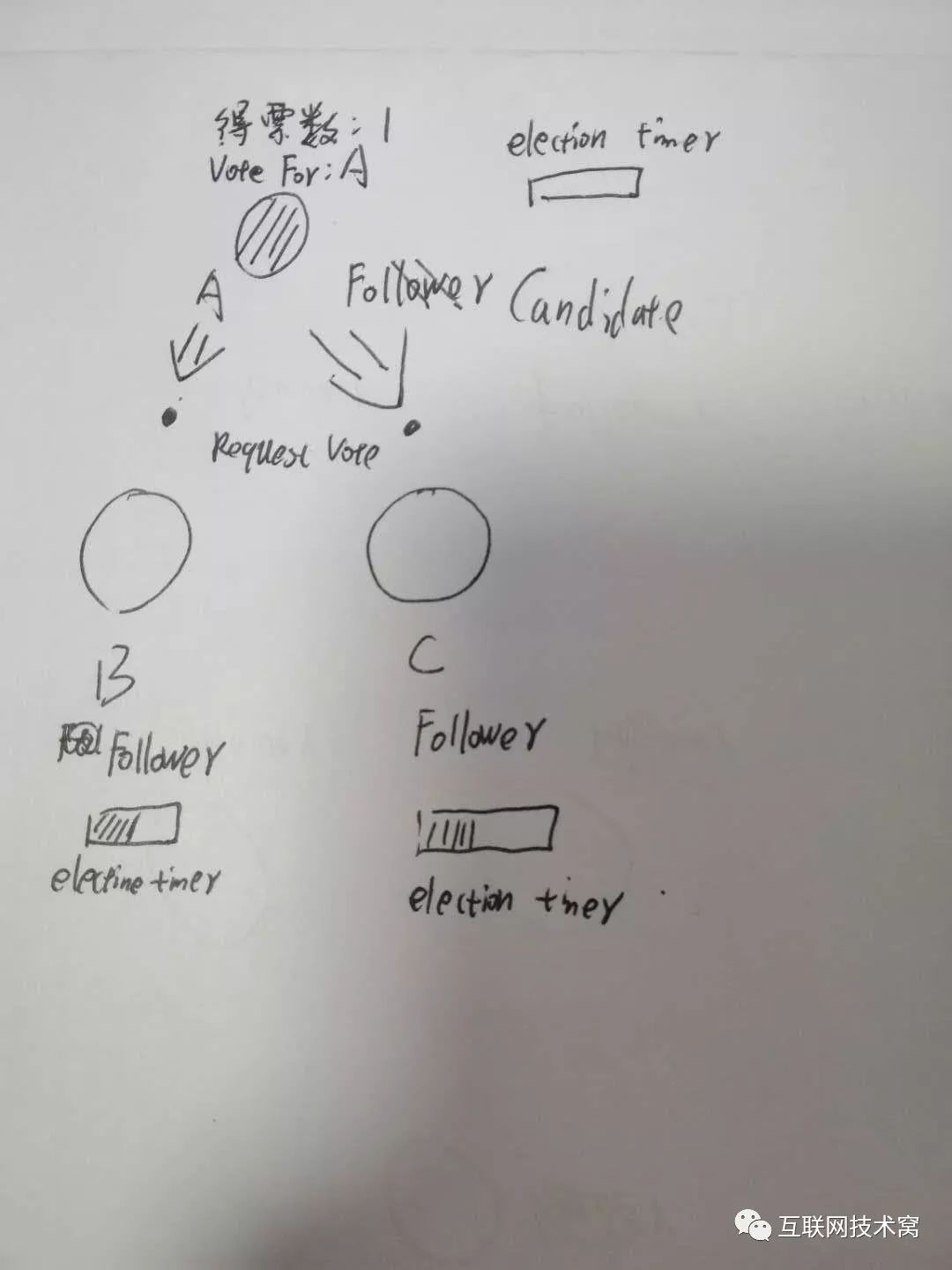
注意!只有 candidate状态的节点,才可以参加竞选变为 leader,B、C这两个follower是没有资格的! 除此之外,每个节点中还有一个字段,叫 term意思就是任期,和美国大选的第几期总统差不多一个意思,这个 term是一个全局的、连续递增的整数,每进行一次选举, term就会加一,如果 candidate赢得选举,它会当 leader直到此次任期结束。 此时,A触发了选举,它的 term应该是加一的。
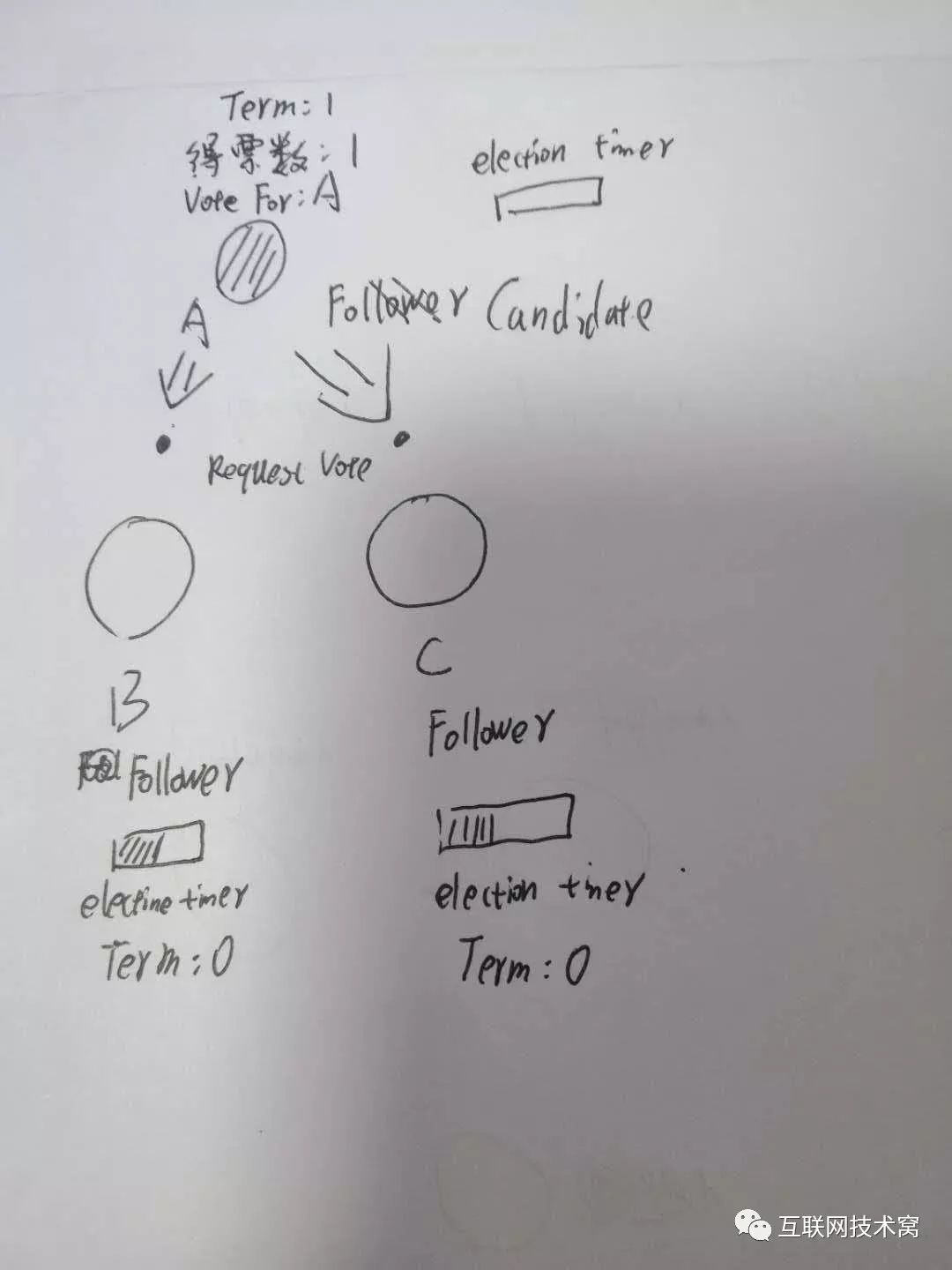
当B、C收到A发出的大选消息后,B、C开始投票,此时只有A这一个 candidate,所以理所当然发消息都只能投A。
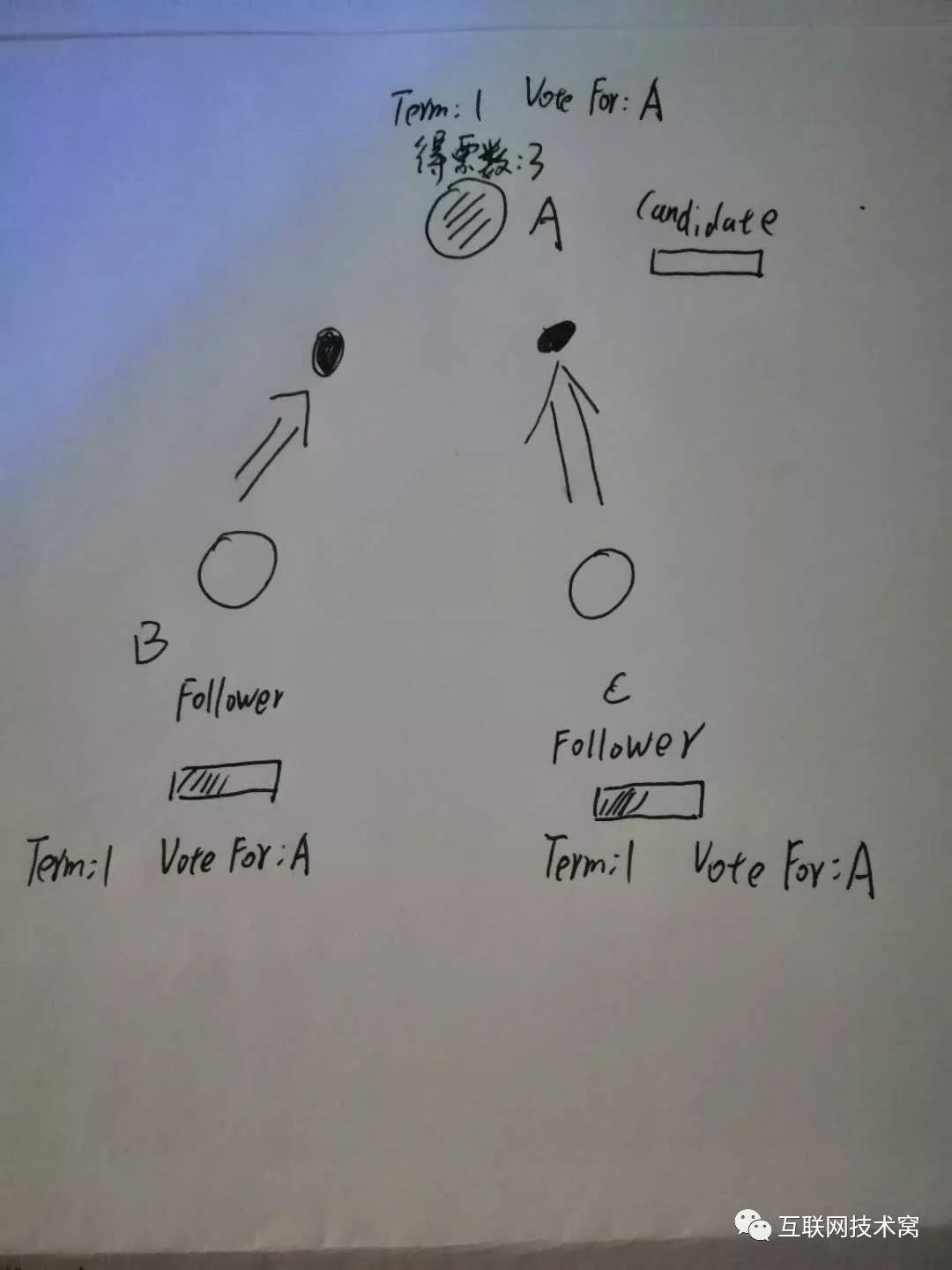
此时A当选 leader! 为了巩固自己的“统治”,防止A在任期之间其他节点因为自身 election timout而触发选举, leader节点A会不定时的向两个 follower节点B、C发送心跳消息,B和C收到心跳消息后,会重置 election timout。心跳检测时间很短,要远远小于选举超时时间 election timout。
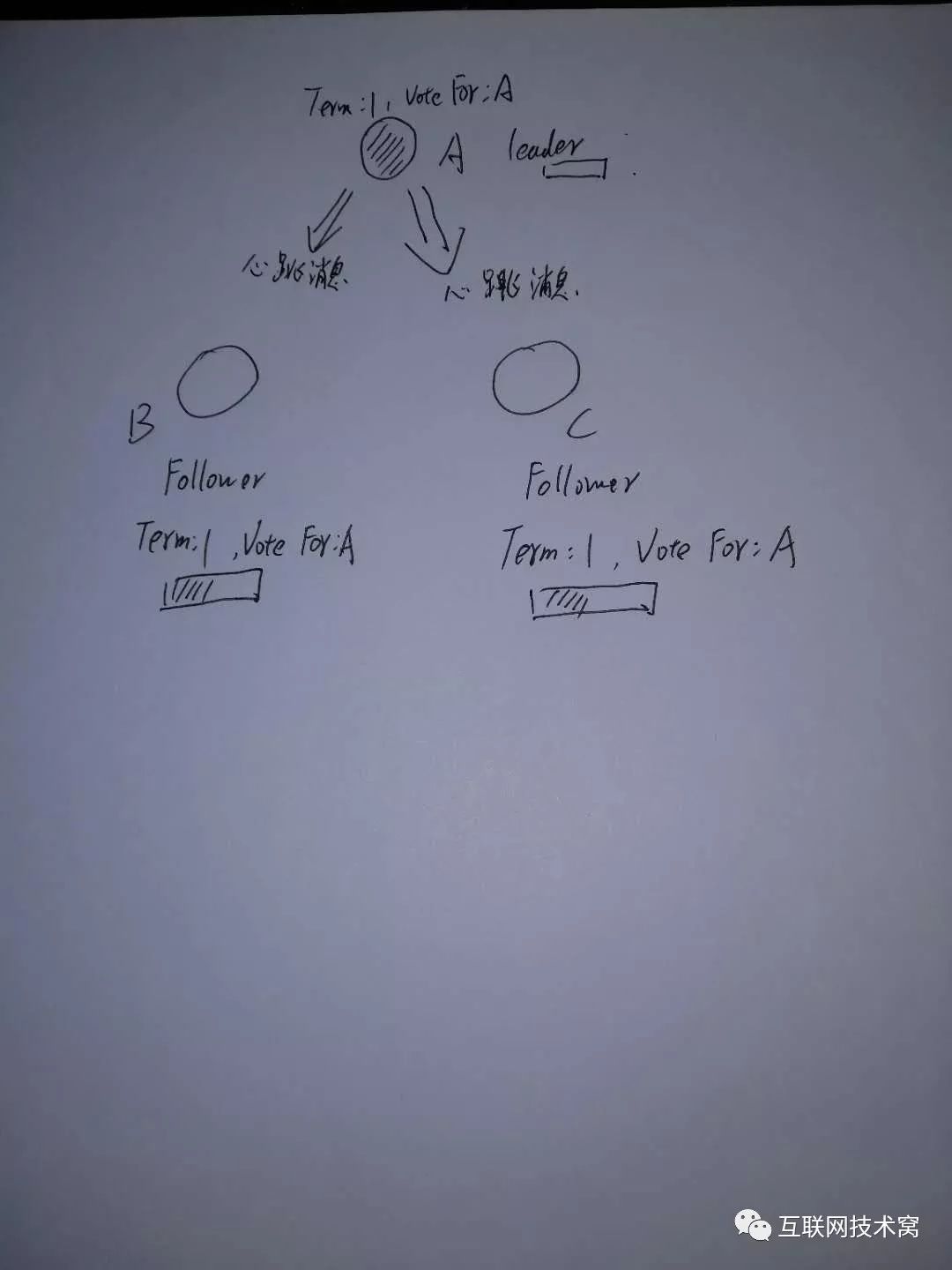
B、C收到心跳检测后,返回心跳响应,并重置超时时间 election timeout。
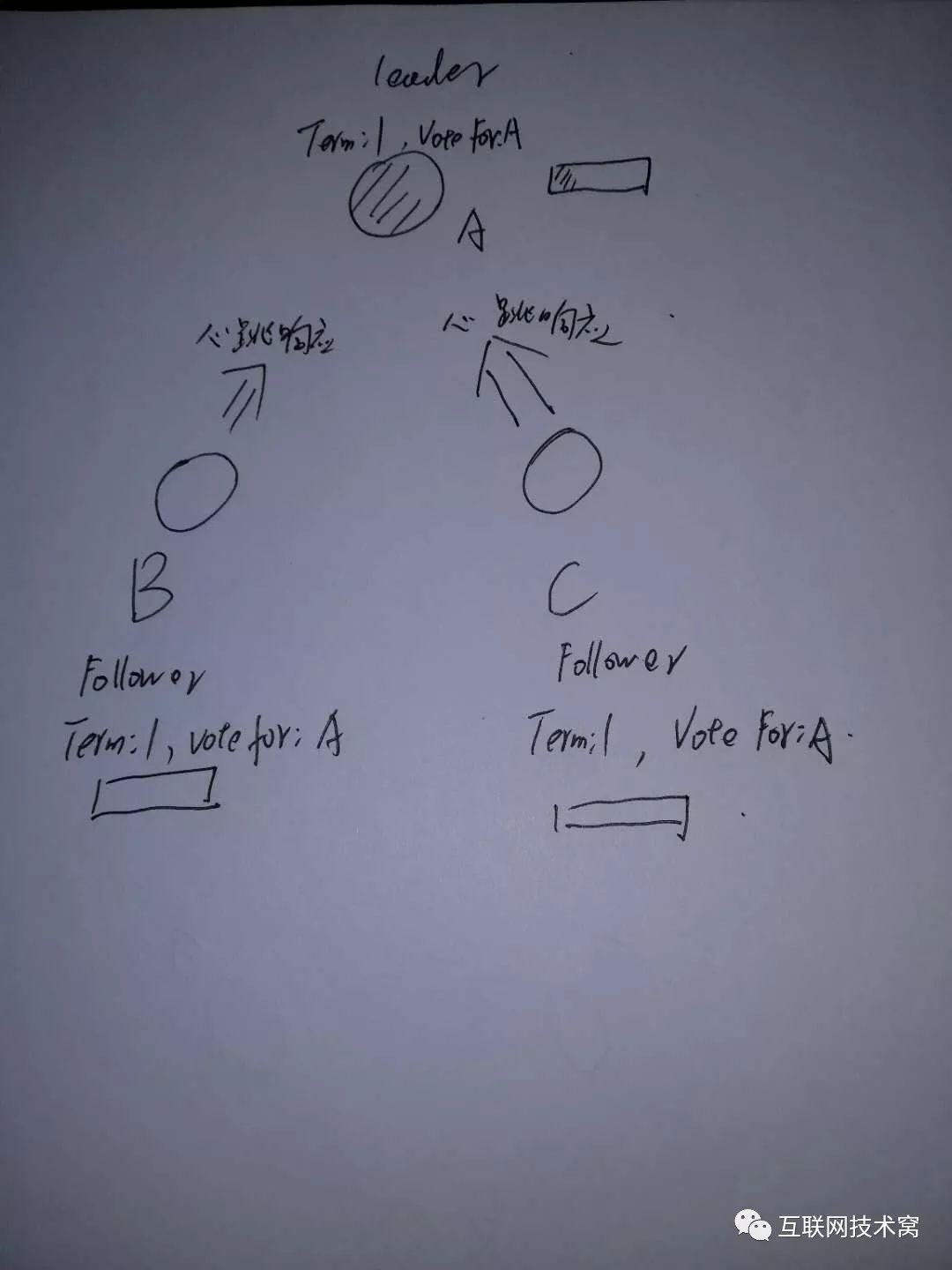
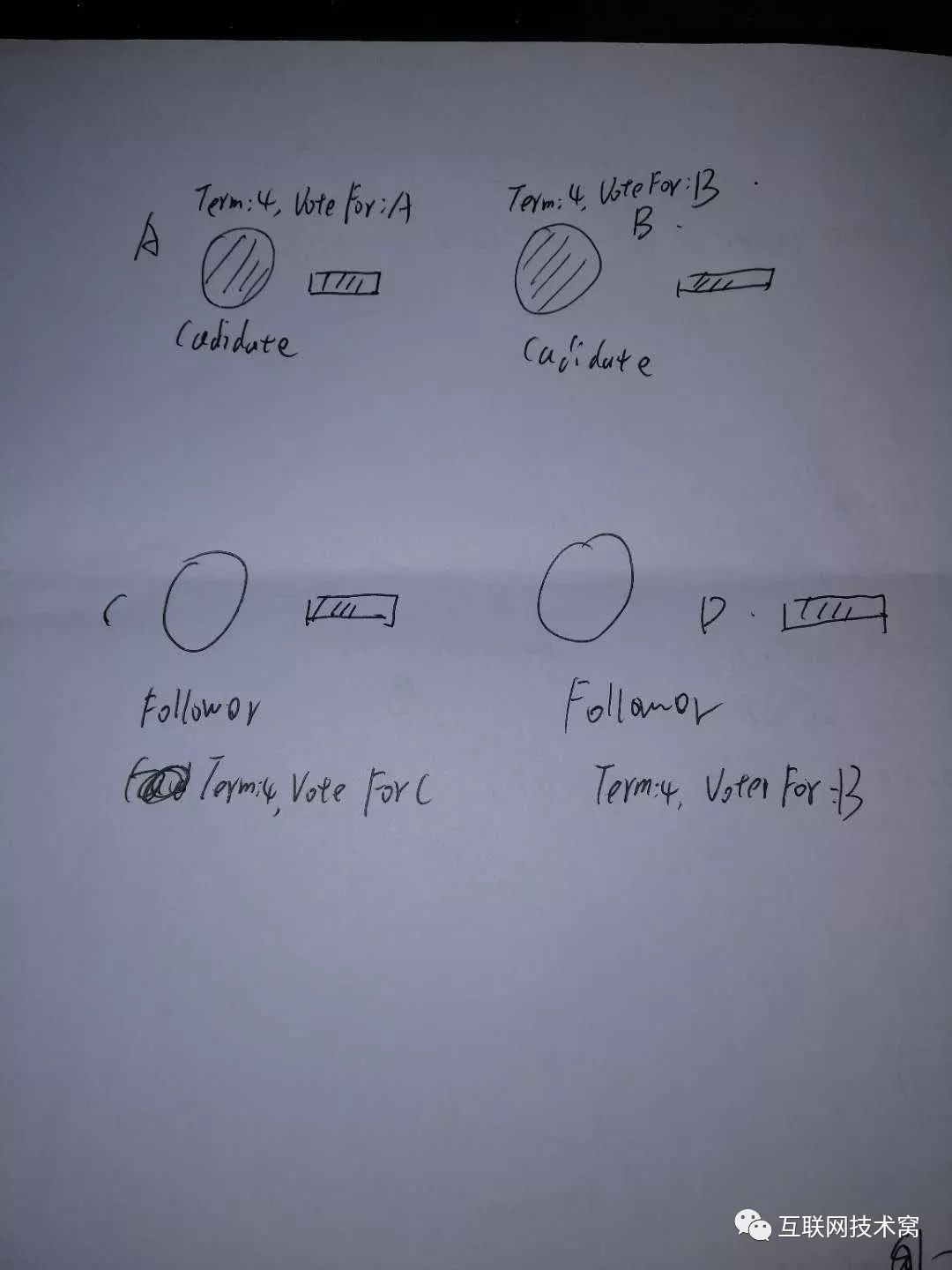
假设A发送的心跳检测消息由于网络原因例如延迟、丢包等等没有传送到B、C中的某个Follower节点,而此时这个节点刚好 election timeout,则触发选举。 C修改自身节点任期值 term为2,自身状态变为 candidate,且投自身一票后,发起选举!
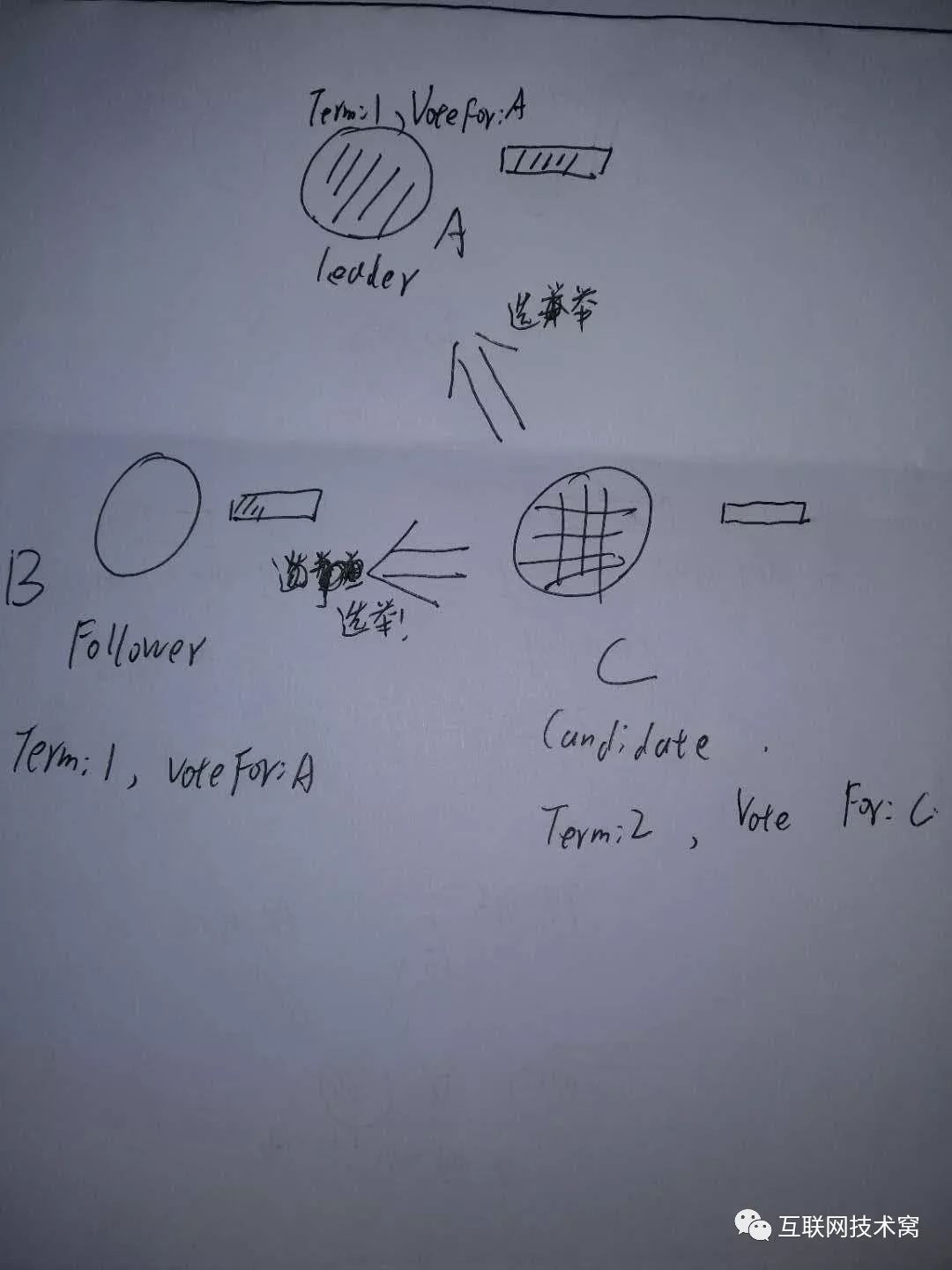
这时候,由于C的任期值 term变为2大于A的,在raft协议中,但收到任期值大于自身的节点,都会更改自身节点的term值,并切换为 Follower状态并重置 election time。 因此,这时候A由 leader直接变为 Follower!
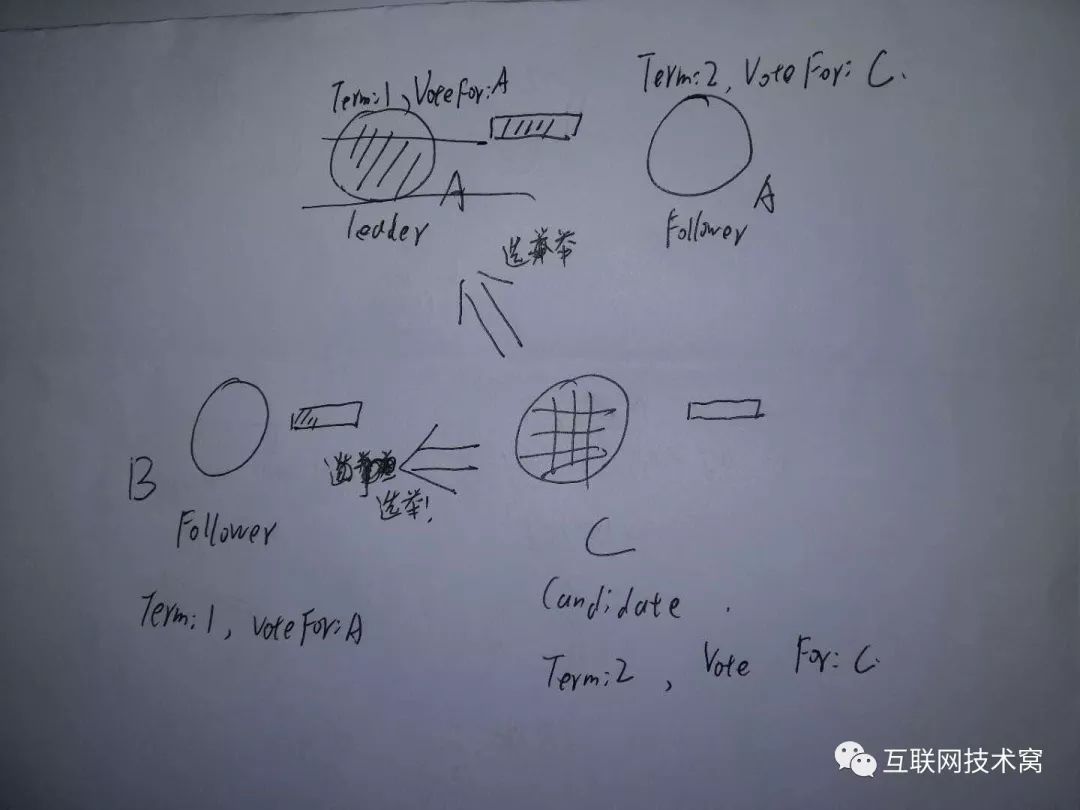
我们再来考虑一种极端情况:假设有偶数个节点,并且同时有两个节点进入 candiate状态! 例如有以下四个节点A、B、C、D。A和B同时进入了 cadidate状态并开始选举。
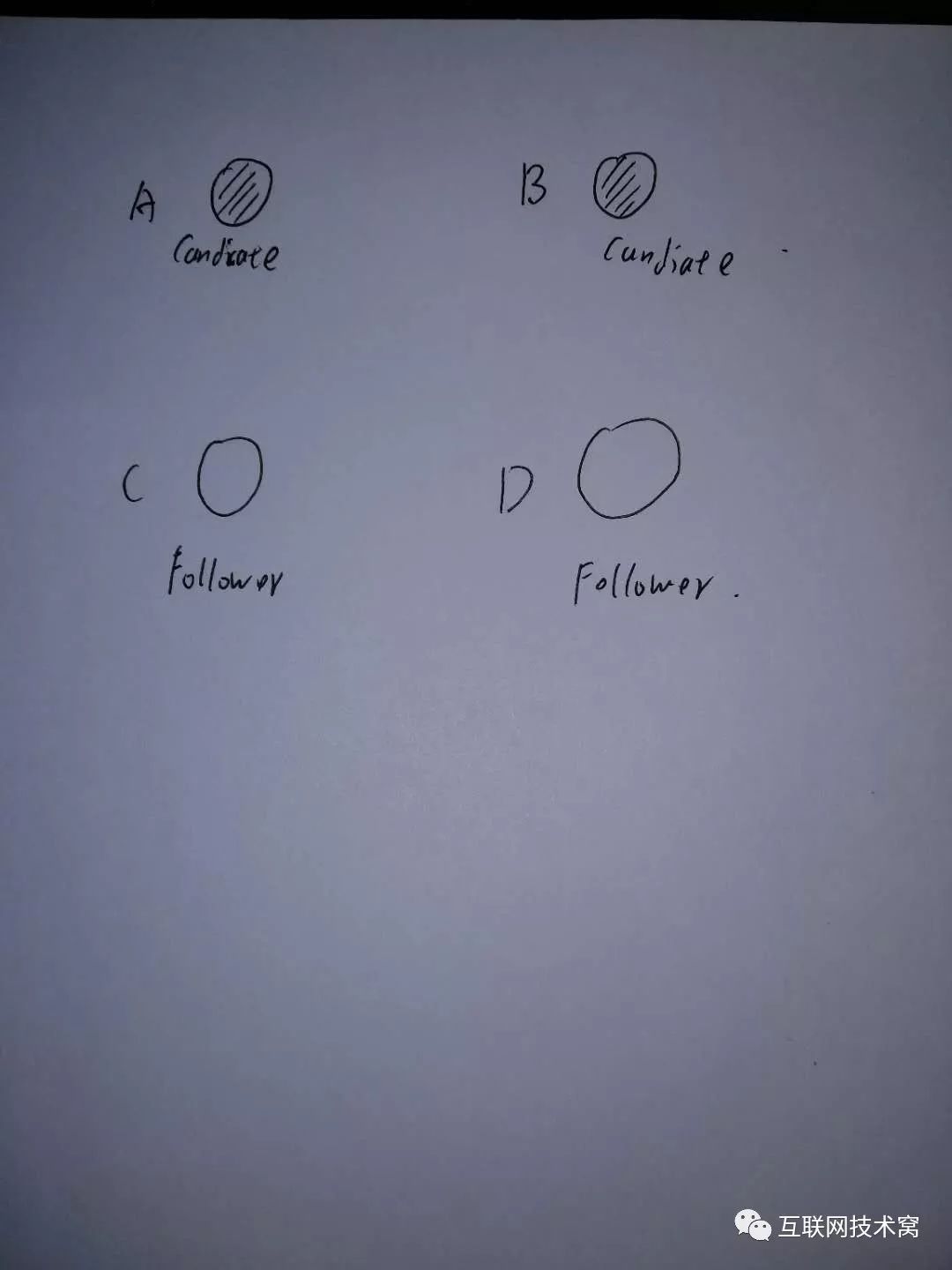
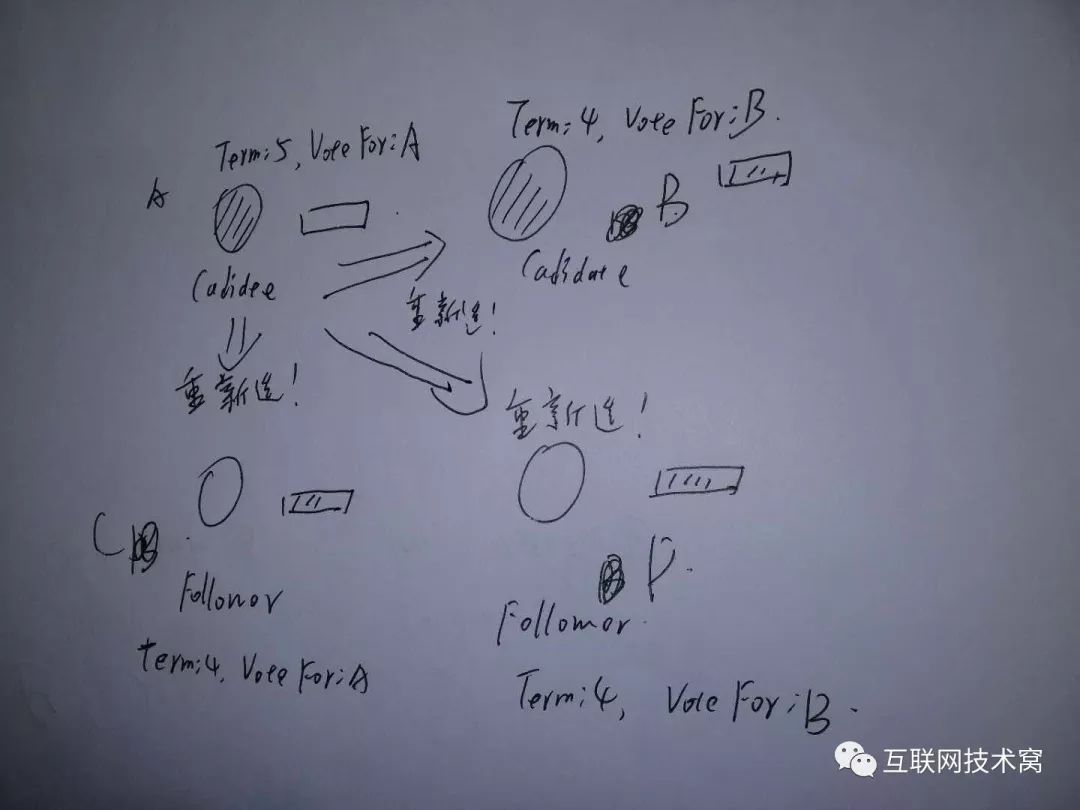
假如A和B中任意一个获得了超过半数以上的多数票,则变为leader!
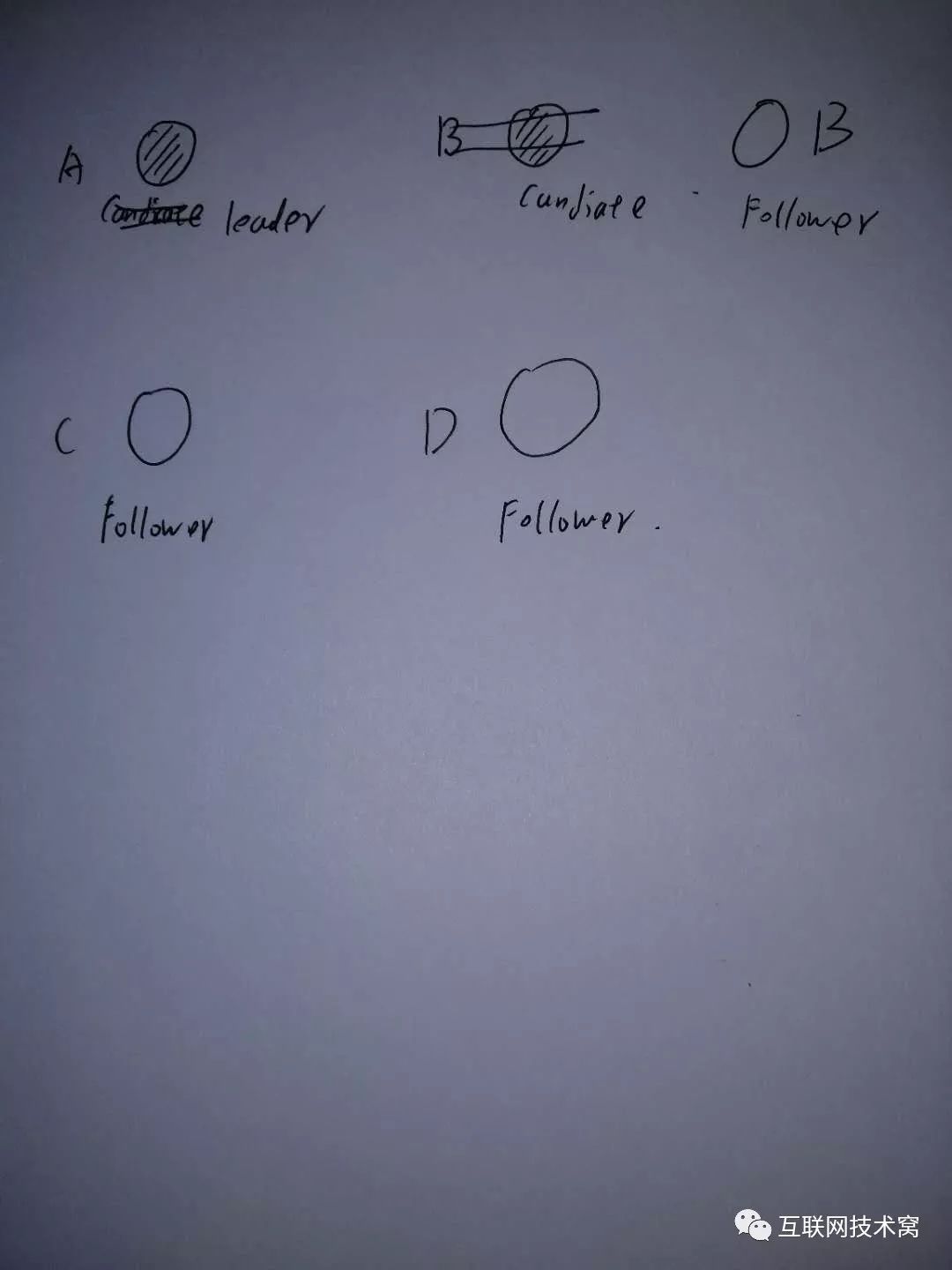
但是假如两个经过一次选举后得的票数相同或者都没有超过半数,则宣告选举失败并结束!等待A和C这两个 candidate节点中任意一个节点的 election time超时,然后发起新一轮选举。 注意:虽然票数相同或者都没有超过半数导致的选举失败了,但是任期值 term还是要叠加的! A、B票数相同,等待哪个先超时。
此时A先超时。则A发起选举,由于A term值显然是最大的,则A会最终当选为 leader。
日志复制
当 leader选出来后,无论读和写都会由 leader节点来处理。 是的,读也由 leader来处理, leader拿到请求后,再决定由哪一个节点来处理,要么将请求分发,要么自己处理;即使client端请求的是follower节点,Follower节点也会现将请求信息转给 leader,再由 leader决定由哪个节点来处理。
下面来说说写的情况: 以下有A、B、C三个节点,其中A是 leader节点
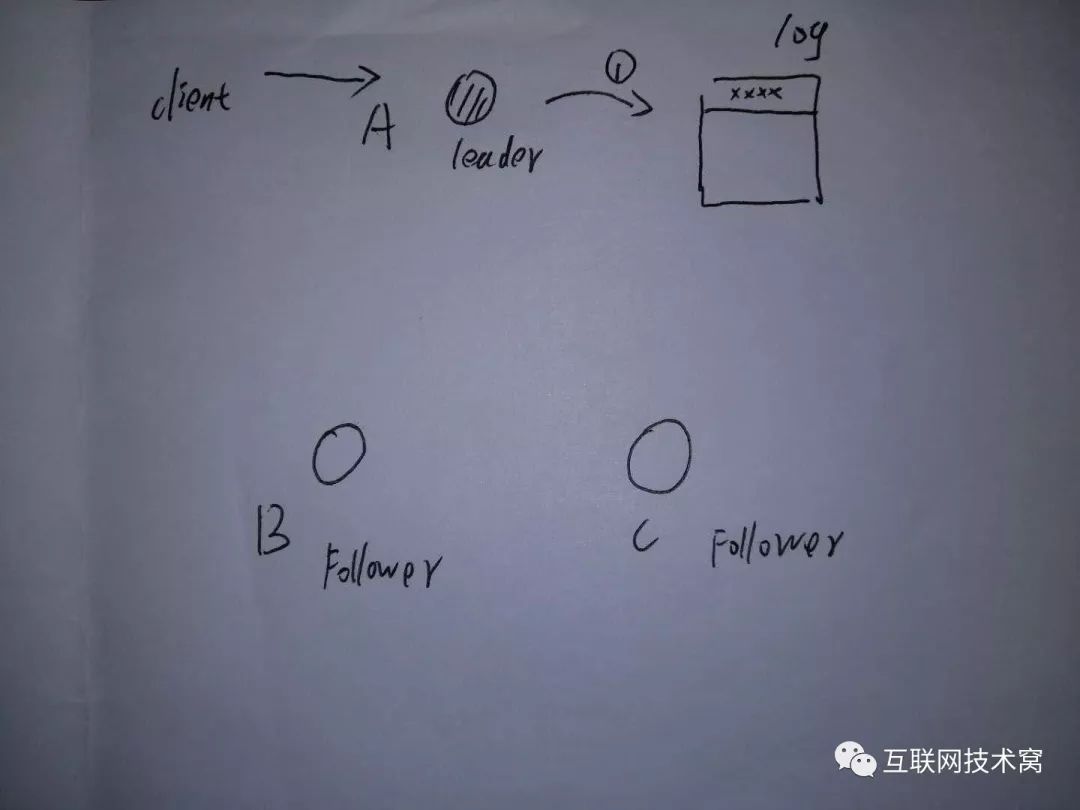
当client请求过来要求写操作的时候, leader A先把数据写在本身节点的log文件中
然后A将发 append entries消息发送给B、C节点。 注意! append entries消息其实是根据节点的不同而消息也不同的,因为集群中数据可能不一致,一味的传相同数据,显然不可以。具体怎么不一致,稍后再说。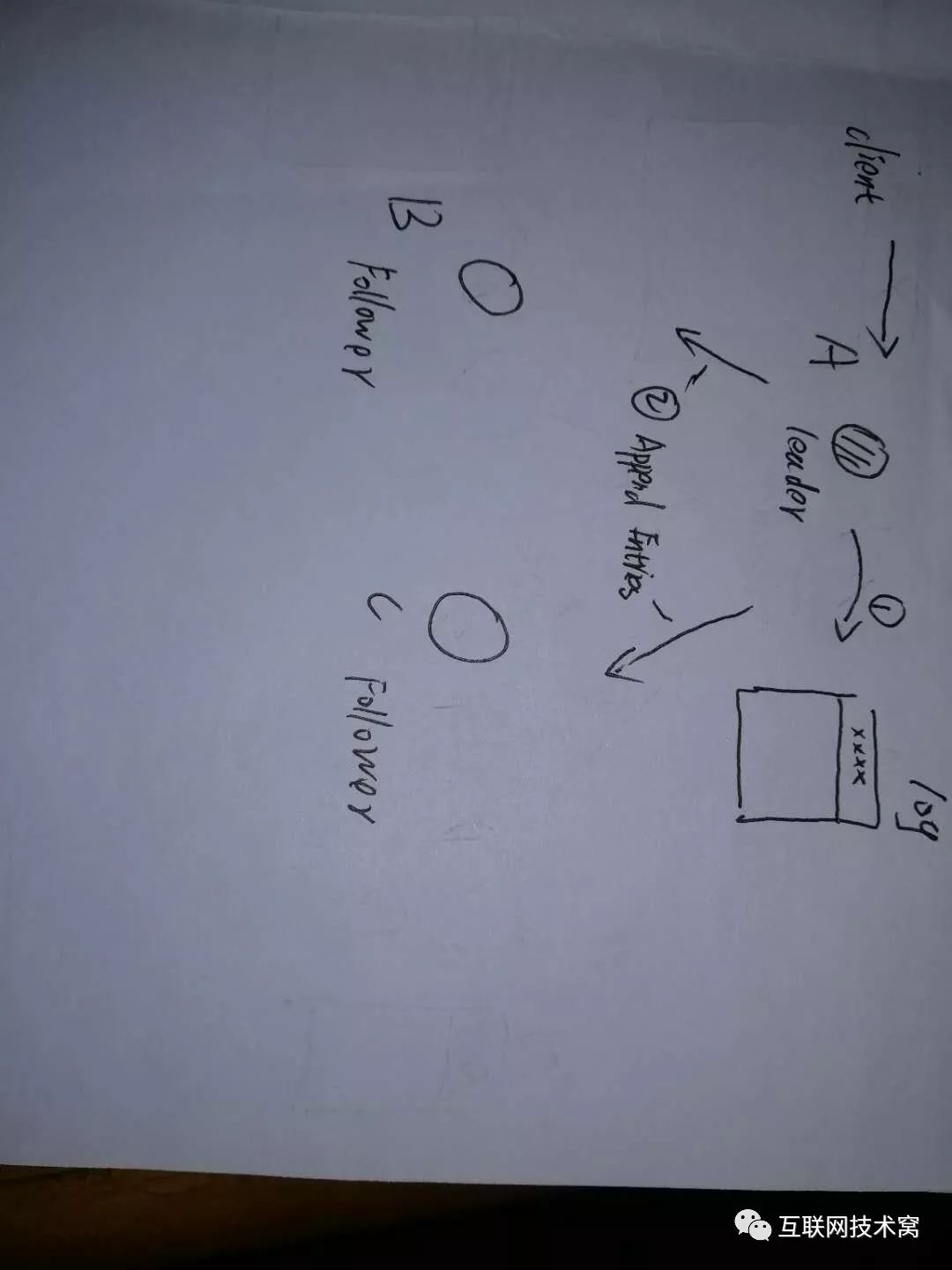
B、C再收到消息后,把数据添加到本地,然后向A发消息,告诉A已经收到。
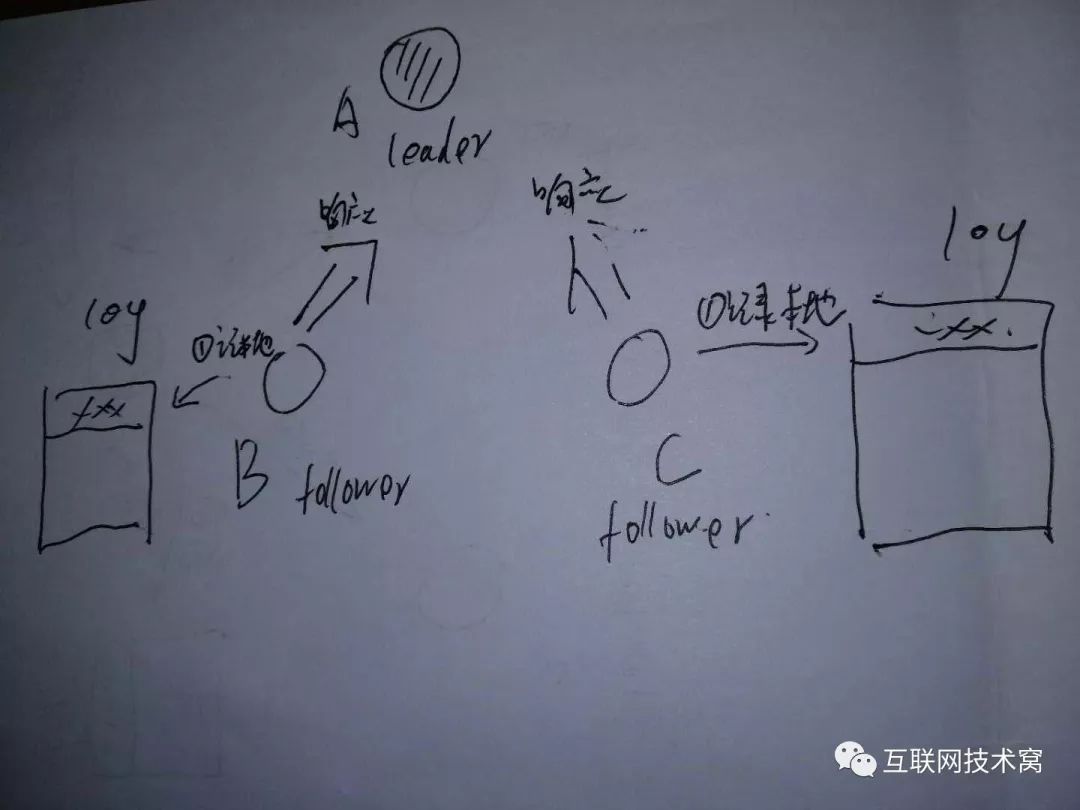
leaderA收到后,先提交记录,然后返回客户端响应。
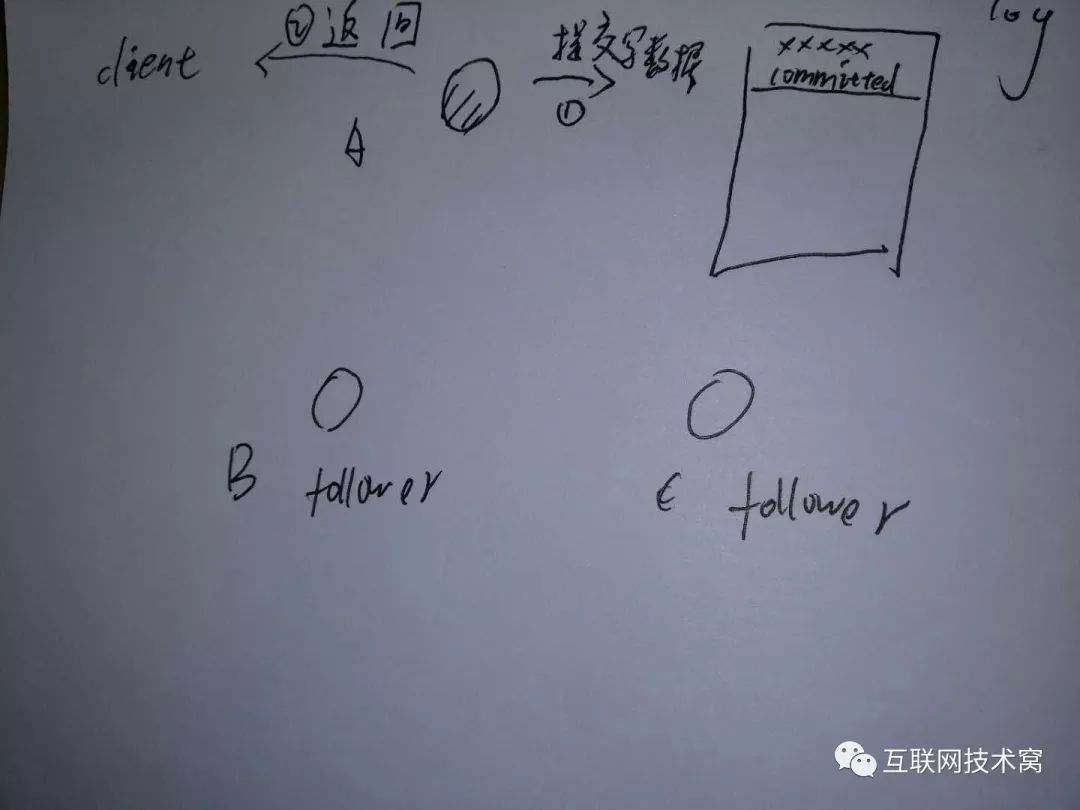
然后, leaderA继续向B、C两个follower发送写数据commit的通知。
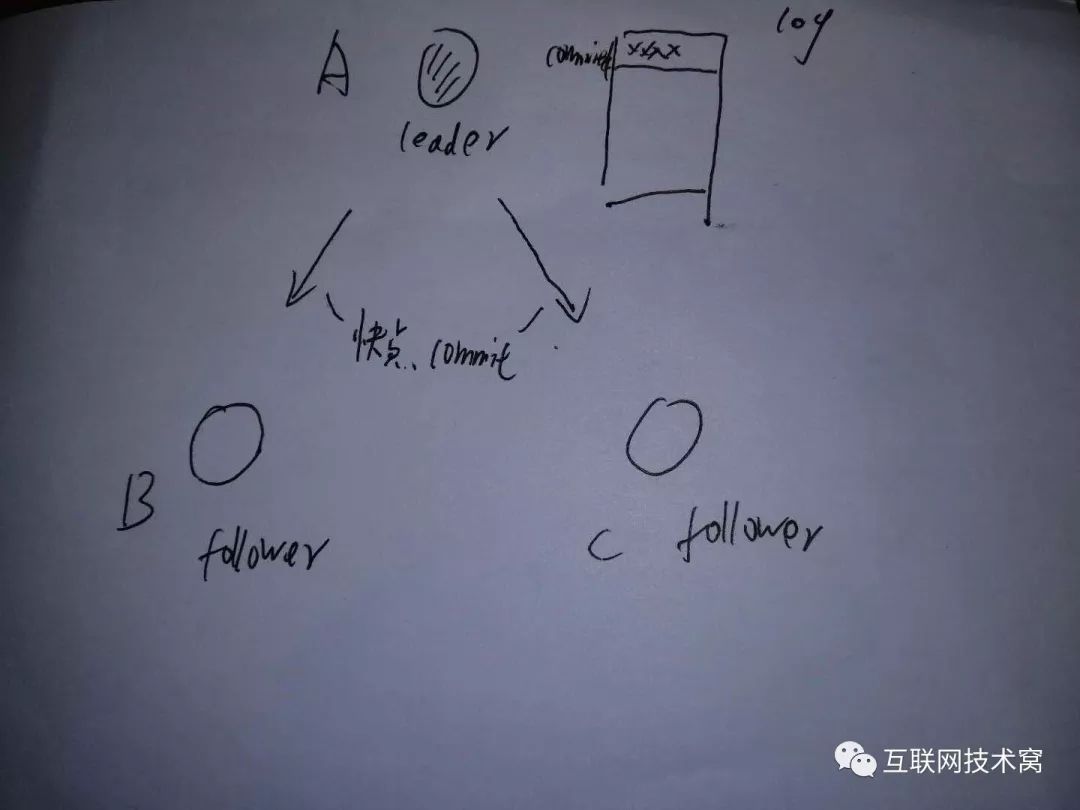
B、C两个节点收到通知后,先commit自身的log数据,然后再通知 leaderA已更新结束。
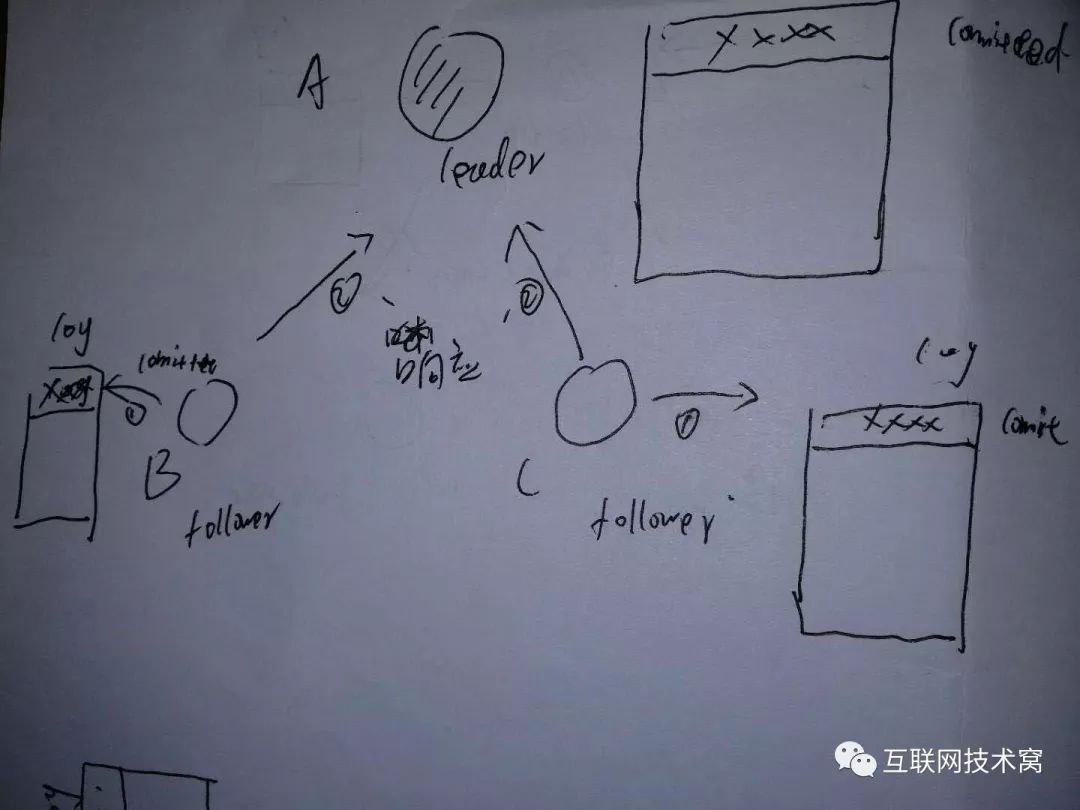
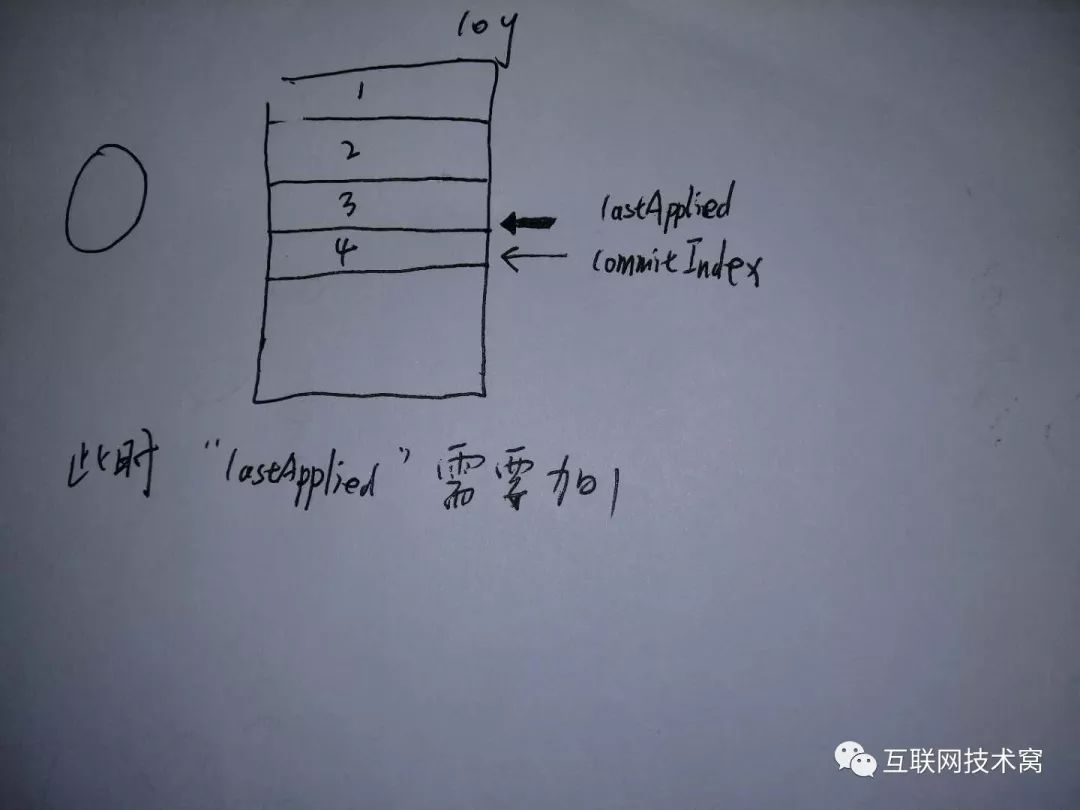
到此整个数据同步也就结束了。 每次写数据,都需要先更新,然后commit。每个节点中都有两个索引,一个是当前提交的索引值commitIndex,一个是目前数据的最后一行索引值lastApplied。
而leader节点中,除了需要存储自身节点的commitIndex和lastApplied之外,还需要知道所有 Follower的存储情况,因而 leader节点中多了一张表,这张表中记录了所有 follower节点的存储情况,这张表中有两个属性,一个属性叫 nextIndex记录的是 Follower节点没有的数据索引,需要发送 append entries的数据索引;还有一个 matchIndex记录的是 leader节点已知的, follower节点的数据。如下图所示:
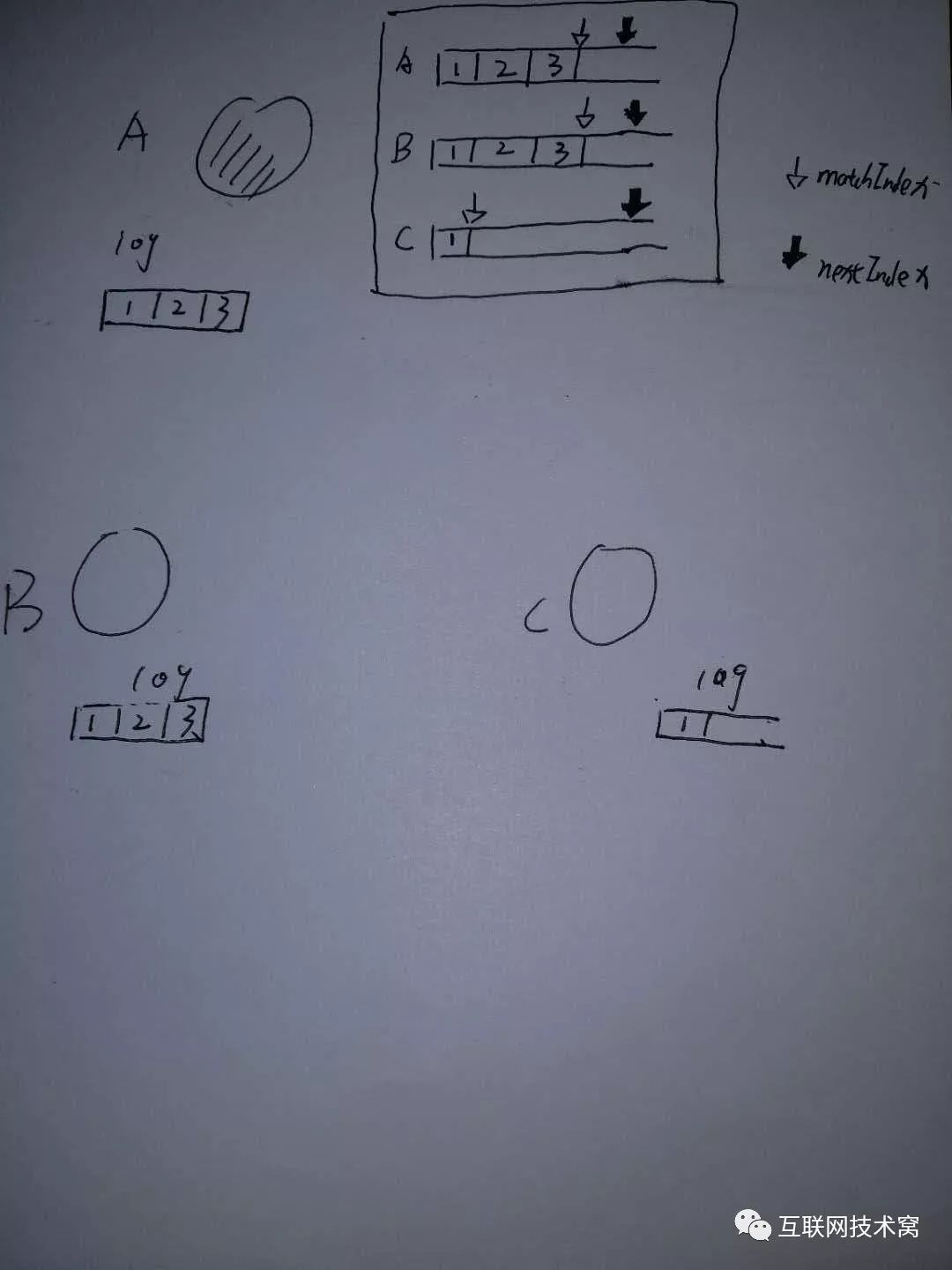
因此,当数据更新的时候, leaderA 向节点B、C发送不同的 append entries。
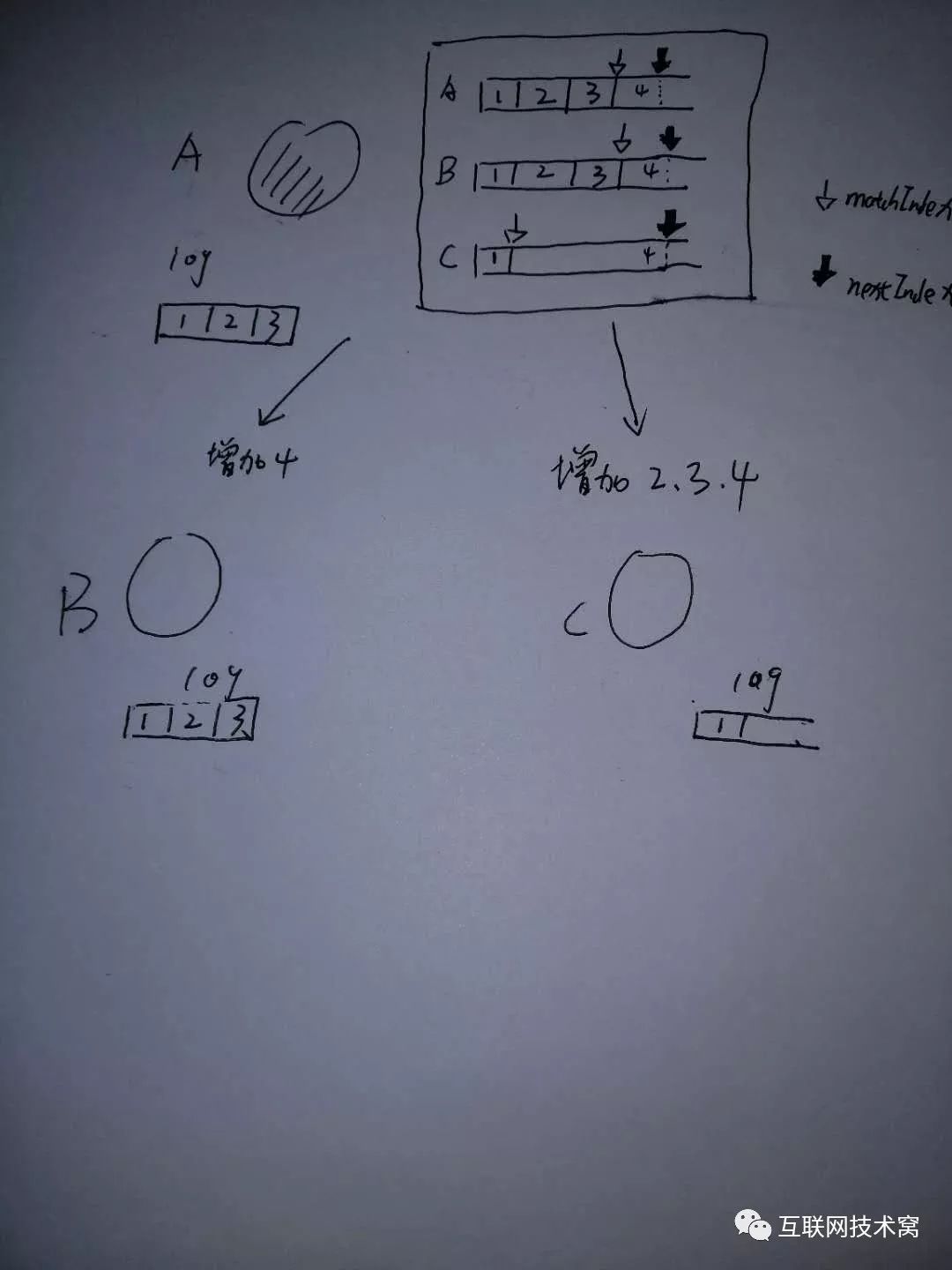
当A节点不再当leader时,其他节点并不能知道 leaderA保存的 matchIndex和 nextIndex这两个数组的数据。当其他节点成功当选为 leader节点后,会将 nextIndex全部重置为自身的 commitIndex,而 matchIndex则全部重置为0。如下图:
则, leaderB会向A和C节点发 append entries,去"补全"数据
节点收到请求后,如果存在数据,就不动直接返回,如果没有数据则缺哪个补哪个。
总结
触发选举的唯一条件是
election timeout,心跳超时等其他条件仅仅是触发了非leader节点的election timeout。节点选举的时候,
term值大的一定会力压term值小的当选leader。leader节点向follower节点中发送append entries的时候,并不是缺少1、2、3就直接发送1、2、3而是分批次,一次发送一条。1! 2! 3!三条数据,分三次发完。(怕图片误导,特此说明!)
以上是关于手绘图解raft算法的主要内容,如果未能解决你的问题,请参考以下文章