10分钟弄懂Raft算法
Posted 普通程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了10分钟弄懂Raft算法相关的知识,希望对你有一定的参考价值。
分布式系统在极大提高可用性、容错性的同时,带来了一致性问题(CAP理论)。Raft算法能够解决分布式系统环境下的一致性问题。
没有耐心看文字,就直接拉到第四章。
一、Raft算法是什么?
过去,Paxos一直是分布式协议的标准,但是Paxos难于理解,更难以实现,Google的分布式锁系统Chubby作为Paxos实现曾经遭遇到很多坑。后来斯坦福大学提出了Raft算法。
Raft是用于管理复制日志的一致性算法。它的效果相当于(multi-)Paxos,跟Paxos一样高效,但结构与Paxos不同。这使得Raft比Paxos更容易理解,也为构建实用系统提供了更好的基础。
下图是斯坦福大学的Diego Ongaro和John Ousterhout在《In Search of an Understandable Consensus Algorithm》一文(提出Raft算法的论文)中,依据Raft学习难度的实验数据绘制的。实验对象是斯坦福大学和加州大学伯克利分校的高年级本科生和研究生。这些天才也觉得Paxos很难。所以对于大多数人看不懂Paxos算法是很正常的,看不懂Raft原理也不奇怪。
二、什么是一致性(Consensus)
一致性是分布式系统容错的基本问题。一致性涉及多个服务器状态(Values)达成一致。 一旦他们就状态做出决定,该决定就是最终决定。 当大多数服务器可用时,典型的一致性算法会取得进展。例如,即使2台服务器发生故障,5台服务器的集群也可以继续运行。 如果更多服务器失败,它们将停止进展(但永远不会返回错误的结果)。
三、Raft算法
论文Raft算法介绍的章节包括6个部分,了解个大概就行,然后拉到本文后边,有个可操作的游戏辅助理解这个算法。
1、Raft基础知识
Raft集群包含多个服务器,5个服务器是比较典型的,允许系统容忍两个故障。在任何给定时间,每个服务器都处于以下三种状态之一,领导者(Leader),追随者(Follower)或候选人(Candidate)。 这几个状态见可以相互转换。
Leader:处理所有客户端交互,日志复制等,一般一次只有一个Leader
Follower:类似选民,完全被动
Candidate:类似Proposer律师,可以被选为一个新的领导人
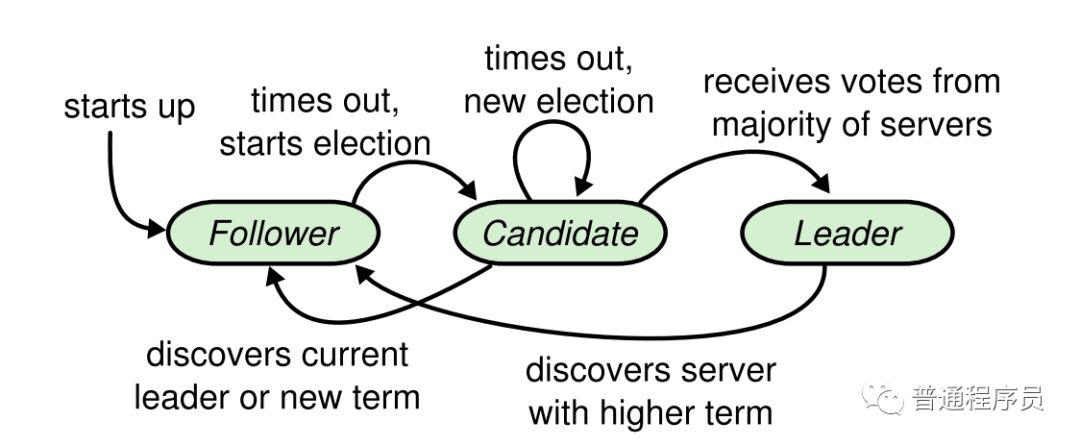
2、选举Leader
Raft使用心跳机制来触发领导者选举。 当服务器启动时,它们以Follower的身份开始。 只要服务器从Leader或Candidate接收到有效的RPC请求,服务器就会保持Follower状态。 Leader向所有Follower发送定期心跳(不带日志条目的AppendEntries RPC)以保持其权限。 如果一个Follower在称为选举超时的一段时间内没有接到任何通信,该Follower认为没有可行的领导者并开始选举新的Leader。
3、日志复制
一旦Leader当选,它就开始为客户请求提供服务。每个客户端请求包含由复制状态机执行的命令。Leader将命令作为新条目附加到其日志,然后并行地向每个其他服务器发出AppendEntries RPC以复制条目。当条目被安全地复制时,Leader将条目应用于其状态机并将该执行的结果返回给客户端。如果Follower崩溃或运行缓慢,或者网络数据包丢失,Leader将无限期地重试AppendEntries RPC(即使它已经响应客户端),直到所有Follower最终存储所有日志条目。(后边游戏中有个request命令菜单,就是模仿客户端请求的)
除了以上3点,文章还重点描述了安全、Follower和Candidate崩溃、时间和可用性三个方面。
四、可视化的Raft算法
建议用电脑浏览器打开,如果在手机微信里打开,需要选择“访问原网页”
我截了一个运行状态的截图,左侧显示五台服务器,右侧显示日志。
在服务器图标上点击鼠标右键会出现操作菜单。操作菜单对应服务节点的状态改变,其中request模拟客户端请求服务器集群执行任务,会在右边产生日志。
多操作一会,一定能够理解Raft算法是怎么运行的!
五、总结
Raft算法具备强一致、高可靠、高可用等优点,具体体现在:
强一致性:虽然所有节点的数据并非实时一致,但Raft算法保证Leader节点的数据最全,同时所有请求都由Leader处理,所以在客户端角度看是强一致性的。
高可靠性:Raft算法保证了Committed的日志不会被修改,State Matchine只应用Committed的日志,所以当客户端收到请求成功即代表数据不再改变。Committed日志在大多数节点上冗余存储,少于一半的磁盘故障数据不会丢失。
高可用性:从Raft算法原理可以看出,选举和日志同步都只需要大多数的节点正常互联即可,所以少量节点故障或网络异常不会影响系统的可用性。即使Leader故障,在选举超时到期后,集群自发选举新Leader,无需人工干预,不可用时间极小。但Leader故障时存在重复数据问题,需要业务去重或幂等性保证。
高性能:与必须将数据写到所有节点才能返回客户端成功的算法相比,Raft算法只需要大多数节点成功即可,少量节点处理缓慢不会延缓整体系统运行。
以上是关于10分钟弄懂Raft算法的主要内容,如果未能解决你的问题,请参考以下文章