详解蚂蚁金服 SOFAJRaft | 生产级高性能 Java 实现
Posted 金融级分布式架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详解蚂蚁金服 SOFAJRaft | 生产级高性能 Java 实现相关的知识,希望对你有一定的参考价值。
SOFAStack
Scalable Open Financial Architecture Stack 是蚂蚁金服自主研发的金融级分布式架构,包含了构建金融级云原生架构所需的各个组件,是在金融场景里锤炼出来的最佳实践。
本文根据 SOFA Meetup#1 北京站 现场分享整理,完整的分享 PPT 获取方式见文章底部。
前言
SOFAJRaft 是一个基于 Raft 一致性算法的生产级高性能 Java 实现,支持 MULTI-RAFT-GROUP,适用于高负载低延迟的场景。SOFAJRaft 是从百度的 braft 移植而来,做了一些优化和改进,感谢百度 braft 团队开源了如此优秀的 C++ Raft 实现。
https://github.com/alipay/sofa-jraft
之前,我们有一篇介绍 SOFAJRaft 的文章,可在文末获得链接,延续这个内容,今天的演讲分为三部分,先简要介绍 Raft 算法,然后介绍 SOFAJRaft 的设计,最后说说它的优化。

分享嘉宾:力鲲 蚂蚁金服 SOFAJRaft 核心成员
Raft 共识算法
Raft 是一种共识算法,其特点是让多个参与者针对某一件事达成完全一致:一件事,一个结论。同时对已达成一致的结论,是不可推翻的。可以举一个银行账户的例子来解释共识算法:假如由一批服务器组成一个集群来维护银行账户系统,如果有一个 Client 向集群发出“存 100 元”的指令,那么当集群返回成功应答之后,Client 再向集群发起查询时,一定能够查到被存储成功的这 100 元钱,就算有机器出现不可用情况,这 100 元的账也不可篡改。这就是共识算法要达到的效果。
Raft 算法和其他的共识算法相比,又有了如下几个不同的特性:
Strong leader:Raft 集群中最多只能有一个 Leader,日志只能从 Leader 复制到 Follower 上;
Leader election:Raft 算法采用随机选举超时时间触发选举来避免选票被瓜分的情况,保证选举的顺利完成;
Membership changes:通过两阶段的方式应对集群内成员的加入或者退出情况,在此期间并不影响集群对外的服务。
共识算法有一个很典型的应用场景就是复制状态机。Client 向复制状态机发送一系列能够在状态机上执行的命令,共识算法负责将这些命令以 Log 的形式复制给其他的状态机,这样不同的状态机只要按照完全一样的顺序来执行这些命令,就能得到一样的输出结果。所以这就需要利用共识算法保证被复制日志的内容和顺序一致。

Leader 选举
复制状态机集群在利用 Raft 算法保证一致性时,要做的第一件事情就是 Leader 选举。在讲 Leader 选举之前我们先要说一个重要的概念:Term。Term 用来将一个连续的时间轴在逻辑上切割成一个个区间,它的含义类似于“美国第 26 届总统”这个表述中的“26”。
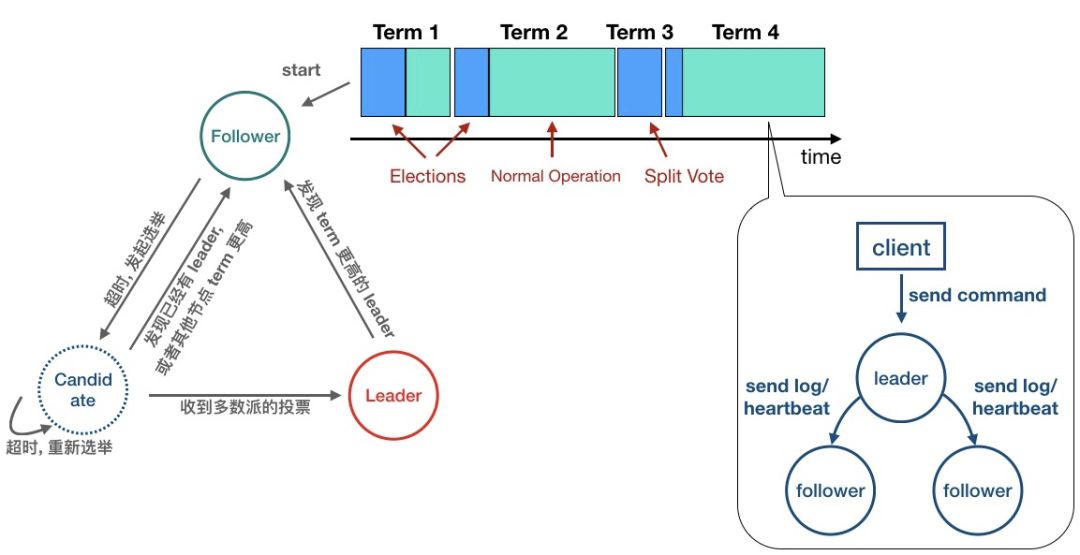
每一个 Term 期间集群要做的第一件事情就是选举 Leader。起初所有的 Server 都是 Follower 角色,如果 Follower 经过一段时间( election timeout )的等待却依然没有收到其他 Server 发来的消息时,Follower 就可以认为集群中没有可用的 Leader,遂开始准备发起选举。在发起选举的时候 Server 会从 Follower 角色转变成 Candidate,然后开始尝试竞选 Term + 1 届的 Leader,此时他会向其他的 Server 发送投票请求,当收到集群内多数机器同意其当选的应答之后,Candidate 成功当选 Leader。但是如下两种情况会让 Candidate 退回 (step down) 到 Follower,放弃竞选本届 Leader:
如果在 Candidate 等待 Servers 的投票结果期间收到了其他拥有更高 Term 的 Server 发来的投票请求;
如果在 Candidate 等待 Servers 的投票结果期间收到了其他拥有更高 Term 的 Server 发来的心跳;
当然了,当一个 Leader 发现有 Term 更高的 Leader 时也会退回到 Follower 状态。
当选举 Leader 成功之后,整个集群就可以向外提供正常读写服务了,如图所示,集群由一个 Leader 两个 Follower 组成,Leader 负责处理 Client 发起的读写请求,同时还要跟 Follower 保持心跳或者把 Log 复制给 Follower。
Log 复制
下面我们就详细说一下 Log 复制。我们之前已经说了 Log 就是 Client 发送给复制状态机的一系列命令。这里我们再举例解释一下 Log,比如我们的复制状态机要实现的是一个银行账户系统,那么这个 Log 就可以是 Client 发给账户系统的一条存钱的命令,比如“存 100 元钱”。
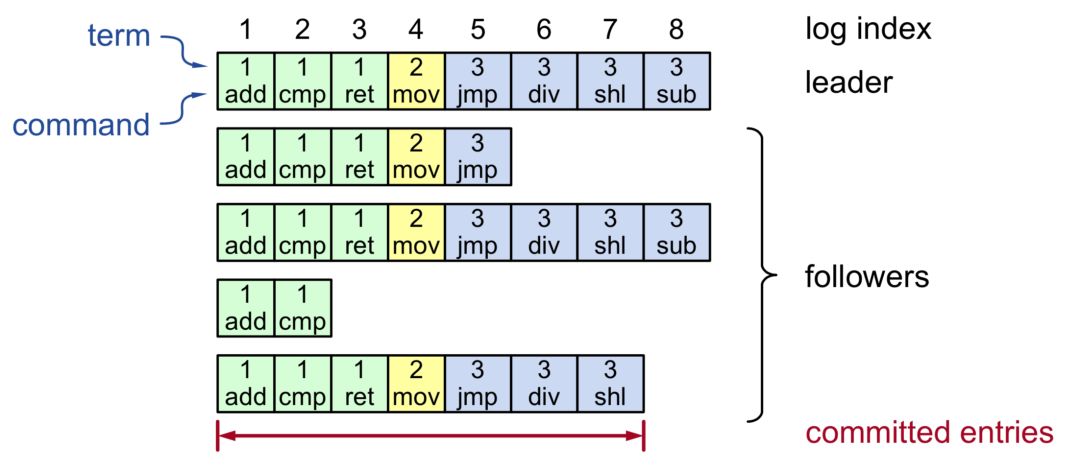
Leader 与 Follower 之间的日志复制是共识算法运用于复制状态机的重要目的,在 Raft 算法中 Log 由 TermId、LogIndex、LogValue 这三要素构成,在这张图上每一个小格代表一个 Log。当 Leader 在向 Follower 复制 Log 的时候,Follower 还需要对收到的 Log 做检查,以确保这些 Log 能和本地已有的 Log 保持连续。我们之前说了,Raft 算法是要严格保证 Log 的连续性的,所以 Follower 会拒绝无法和本地已有 Log 保持连续的复制请求,那么这种情况下就需要走 Log 恢复的流程。总之,Log 复制的目的就是要让所有的 Server 上的 Log 无论在内容上还是在顺序上都要保持完全一致,这样才能保证所有状态机执行结果一致。
目前已经有一些很优秀的对 Raft 的实现,比如 C++ 写的 braft,Go 写的 etcd,Rust 写的 TiKV。当然了,SOFAJRaft 并不是 Raft 算法的第一个 Java 实现,在我们之前已经有了很多项目。但是经过我们的评估,觉得目前还是没有一个 Raft 的 Java 实现库类能够满足蚂蚁生产环境的要求,这也是我们去写 SOFAJRaft 的主要原因。
SOFAJRaft 介绍
接下来我们介绍 SOFAJRaft。
SOFAJRaft 是基于 Raft 算法的生产级高性能 Java 实现,支持 MULTI-RAFT-GROUP。从去年 3 月开发到今年 2 月完成,并在今年 3 月开源。应用场景有 Leader 选举、分布式锁服务、高可靠的元信息管理、分布式存储系统,目前使用案例有 RheaKV,这是 SOFAJRaft 中自带的一个分布式 KV 存储,还有今天开源的 SOFA 服务注册中心中的元信息管理模块也是用到了 SOFAJRaft,除此之外还有一些内部的项目也有使用,但是因为没有开源,所以就不再详述了。

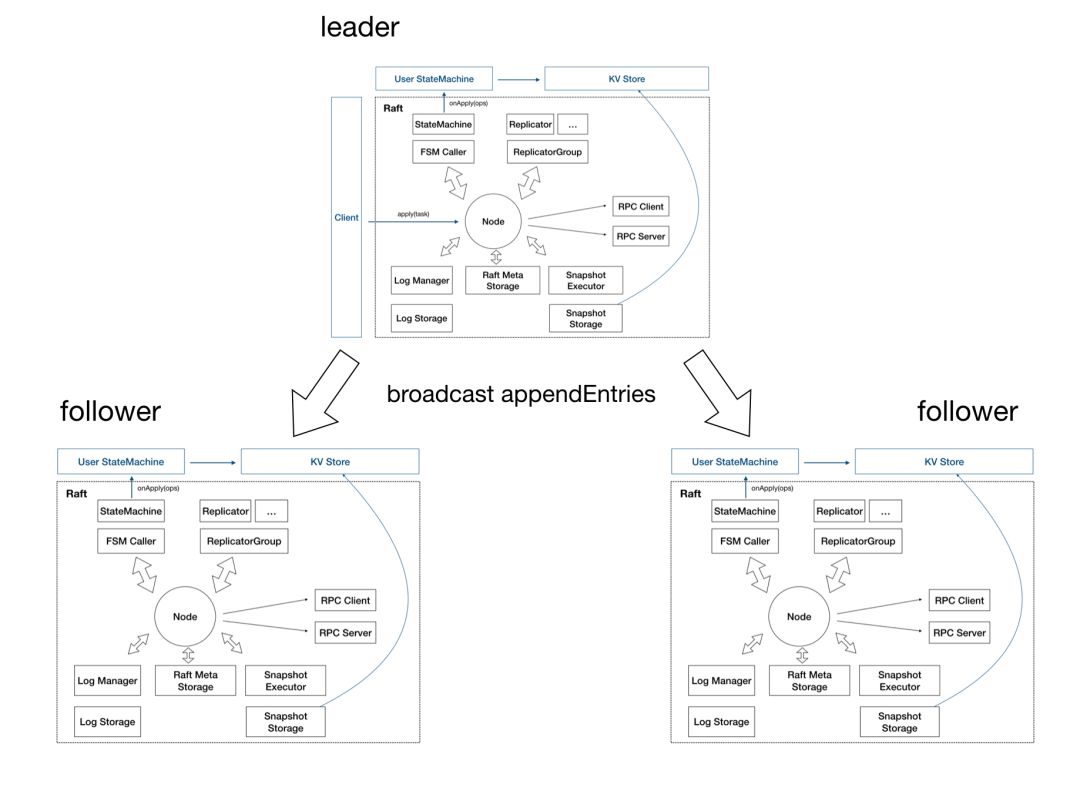
这张图就是 SOFAJRaft 的设计图,Node 代表了一个 SOFAJRaft Server 节点,这些方框代表他内部的各个模块,我们依然用之前的银行账户系统举例来说明 SOFAJRaft 的各模块是如何工作的。
当 Client 向 SOFAJRaft 发来一个“存 100 元”的命令之后,Node 的 Log 存储模块首先将这个命令以 Log 的形式存储到本地,同时 Replicator 会把这个 Log 复制给其他的 Node,Replicator 是有多个的,集群中有多少个 Follower 就会有多少个 Replicator,这样就能实现并发的日志复制。当 Node 收到集群中半数以上的 Node 返回的“复制成功” 的响应之后,就可以把这条 Log 以及之前的 Log 有序的送到状态机里去执行了。状态机是由用户来实现的,比如我们现在举的例子是银行账户系统,所以状态机执行的就是账户金额的借贷操作。如果 SOFAJRaft 在别的场景中使用,状态机就会有其他的执行方式。
Meta Storage 是用来存储记录 Raft 实现的内部状态,比如当前 Term、 投票给哪个节点等信息。
Snapshot 是快照,所谓快照就是对数据当前值的一个记录,Leader 生成快照有这么几个作用:
当有新的 Node 加入集群的时候,不用只靠日志复制、回放去和 Leader 保持数据一致,而是通过安装 Leader 的快照来跳过早期大量日志的回放;
Leader 用快照替代 Log 复制可以减少网络上的数据量;
用快照替代早期的 Log 可以节省存储空间。
刚才我们说的是一个节点内部的情况,那在 Raft Group 中至少需要 3 个节点,所以这是一个三副本的架构图。
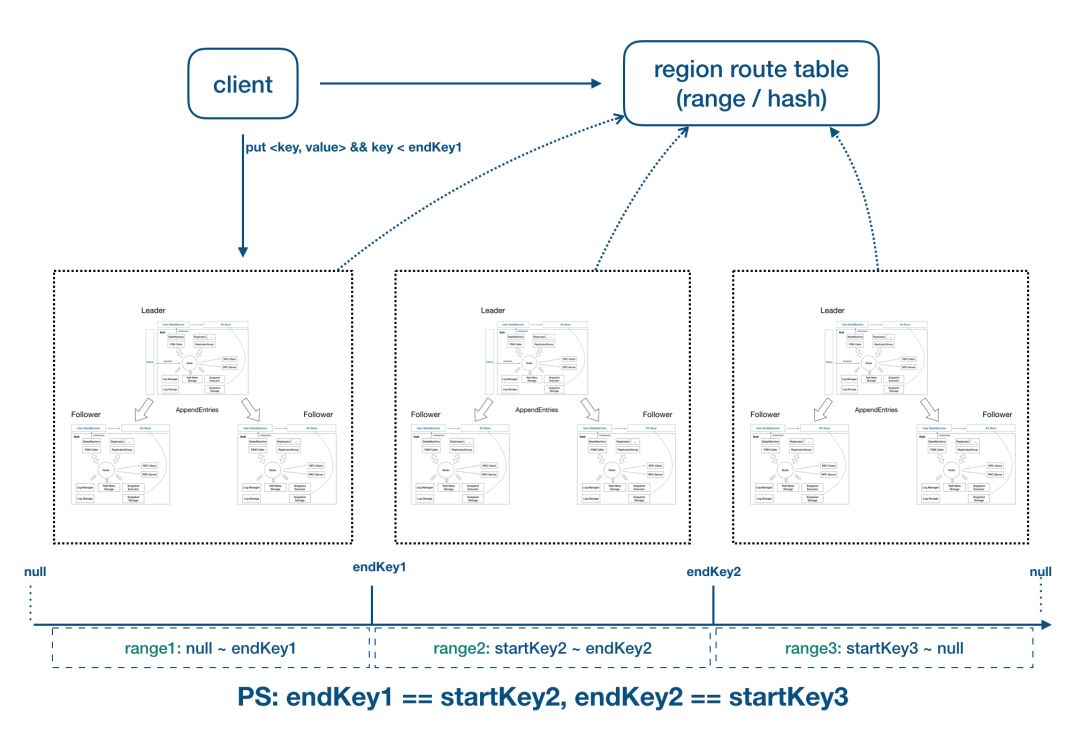
我们会因为各种各样的需求而去构建一个 Raft 集群,如果你的目标是实现一个存储系统的话,那单个 Raft 集群可能没有办法承载你所有的存储需求;如果你的目标是实现一个为用户请求提供 Service 的系统的话,因为 Raft 集群内只有 Leader 提供读写服务,所以读写也会形成单点的瓶颈。因此为了支持水平扩展,SOFAJRaft 提供了 Multi-Group 部署模式。如图所示,我们可以按某种 Key 进行分片部署,比如用户 ID,我们让 Group 1 对 [0, 10000) 的 ID 提供服务,让 Group 2 对 [10000, 20000) 的 ID 提供服务,以此类推。
SOFAJRaft 特性
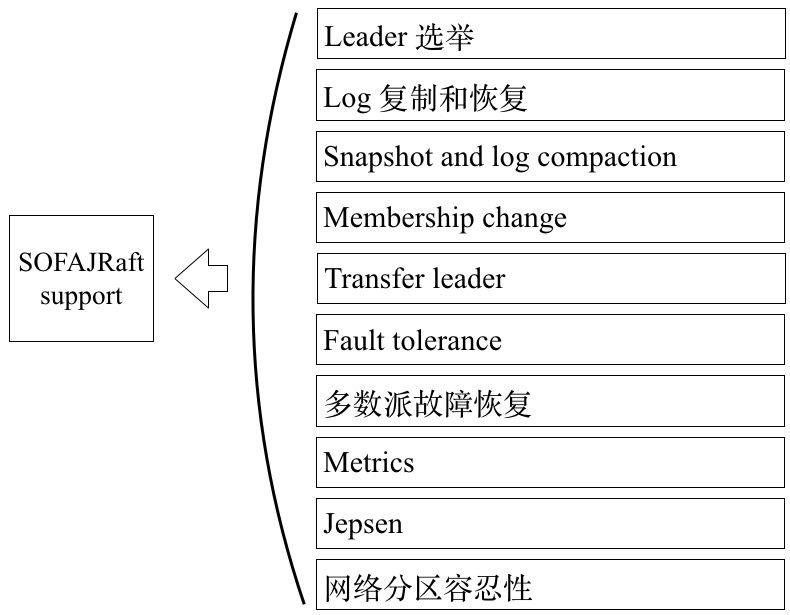
这是我们所支持的 Raft 特性,其中:
Membership change 成员管理:集群内成员的加入和退出不会影响集群对外提供服务;
Transfer leader:除了集群根据算法自动选出 Leader 之外,还支持通过指令强制指定一个节点成为 Leader。
Fault tolerance 容错性:当集群内有节点因为各种原因不能正常运行时,不会影响整个集群的正常工作。
多数派故障恢复:当集群内半数以上的节点都不能正常服务的时候,正常的做法是等待集群自动恢复,不过 SOFAJRaft 也提供了 Reset 的指令,可以让整个集群立即重建。
Metrics:SOFAJRaft 内置了基于 Metrics 类库的性能指标统计,具有丰富的性能统计指标,利用这些指标数据可以帮助用户更容易找出系统性能瓶颈。
SOFAJRaft 定位是生产级的 Raft 算法实现,所以除了几百个单元测试以及部分 Chaos 测试之外, SOFAJRaft 还使用 jepsen 这个分布式验证和故障注入测试框架模拟了很多种情况,都已验证通过:
随机分区,一大一小两个网络分区
随机增加和移除节点
随机停止和启动节点
随机 kill -9 和启动节点
随机划分为两组,互通一个中间节点,模拟分区情况
随机划分为不同的 majority 分组
网络分区包括两种,一种是非对称网络分区,一种是对称网络分区。
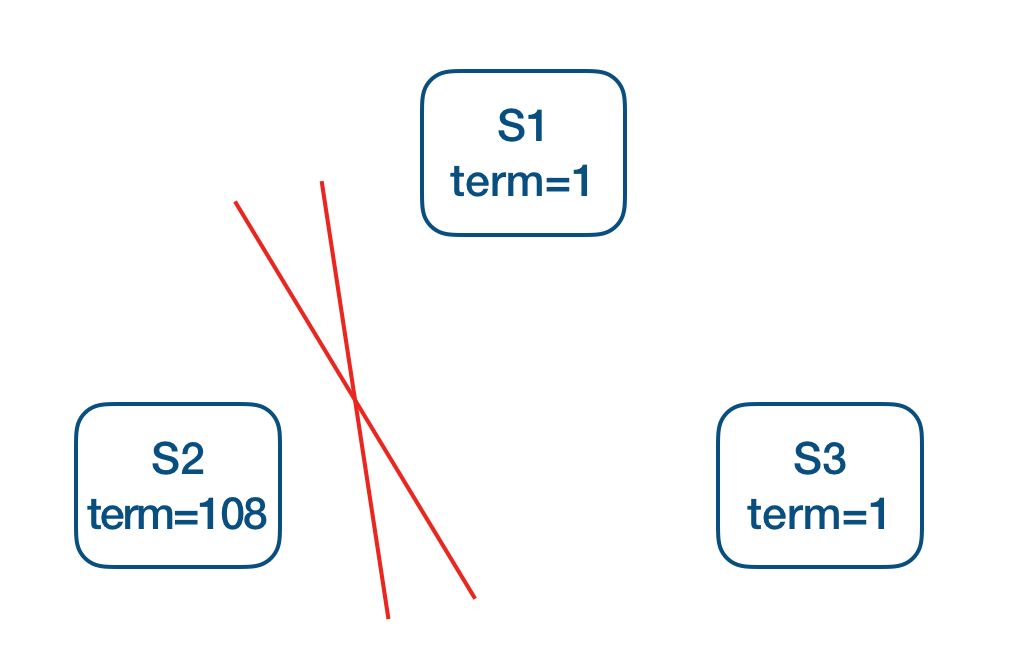
在对称网络分区中,S2 和其他节点通信中断,由于无法和 Leader 通信,导致它不断尝试竞选 Leader,这样等到网络恢复的时候,S2 由于之前的不断尝试,其 Term 已经高于 Leader 了。这会迫使 S1 退回到 Follower 状态,集群重新进行选举。为避免这种由于对称网络分区造成的不必要选举,SOFAJRaft 增加了预投票(pre-vote),一个 Follower 在发起投票前会先尝试预投票,只有超过半数的机器认可它的预投票,它才能继续发起正式投票。在上面的情况中,S2 在每次发起选举的时候会先尝试预选举,由于在预选举中它依然得不到集群内多数派的认可,所以预投票无法成功,S2 也就不会发起正式投票了,因此他的 Term 也就不会在网络分区的时候持续增加了。
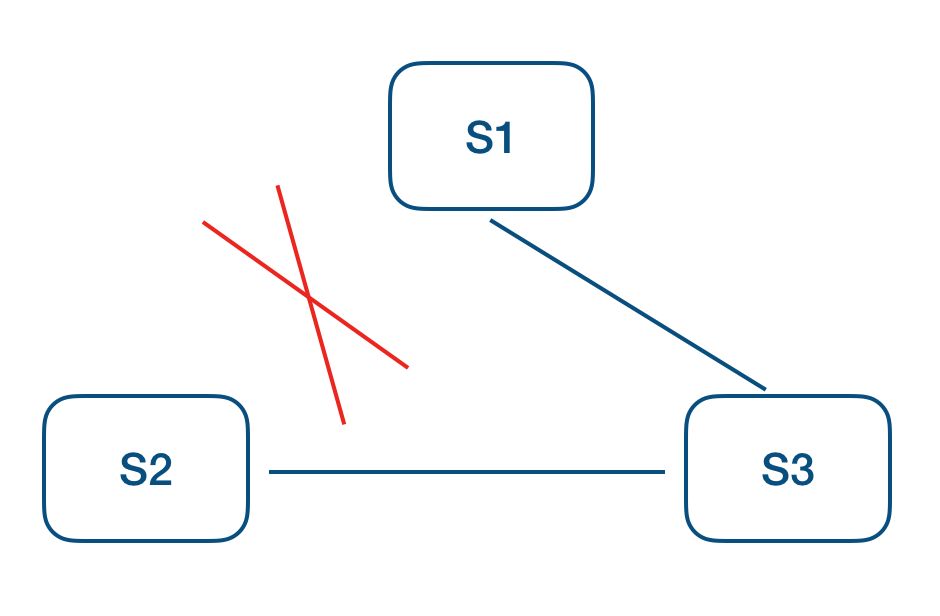
在非对称网络分区中,S2 和 Leader S1 无法通信,但是它和另一个 Follower S3 依然能够通信。在这种情况下,S2 发起预投票得到了 S3 的响应,S2 可以发起投票请求。接下来 S2 的投票请求会使得 S3 的 Term 也增加以至于超过 Leader S1(S3 收到 S2 的投票请求后,会相应把自己的 Term 提升到跟 S2 一致),因此 S3 接下来会拒绝 Leader S1 的日志复制。为解决这种情况,SOFAJRaft 在 Follower 本地维护了一个时间戳来记录收到 Leader 上一次数据更新的时间,Follower S3 只有超过 election timeout 之后才允许接收预投票请求,这样也就避免了 S2 发起投票请求。
SOFAJRaft 优化
接下来我们说一下 SOFAJRaft 的优化。
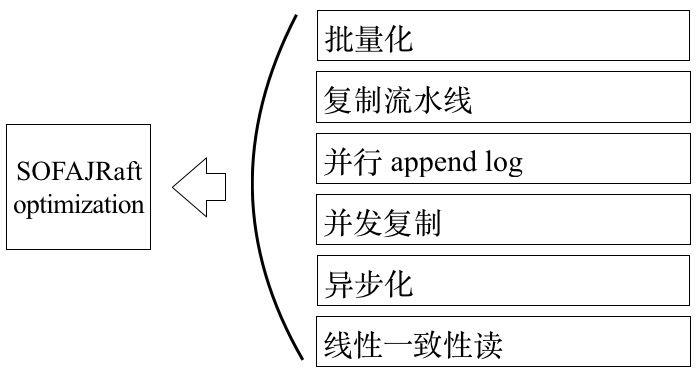
为了提供支持生产环境运行的高性能,SOFAJRaft 主要做了如下几部分的性能优化,其中:
并行 append log:在 SOFAJRaft 中 Leader 持久化 Log 和向 Followers 发送 Log 是并行的。
并发复制:Leader 向所有 Follwers 发送 Log 也是完全相互独立和并发的。
异步化:SOFAJRaft 中整个链路几乎没有任何阻塞,完全异步的,是一个完全的 Callback 编程模型。
下面我们再说说另外三项:批量化、复制流水线以及线性一致读。
批量化是性能优化最常用的手段之一。SOFAJRaft 通过批量化的手段合并 IO 请求、减少方法调用和上下文切换,具体包括批量提交 Task、批量网络发送、本地 IO 批量写入以及状态机批量应用。值得一提的是 SOFAJRaft 主要是通过 Disruptor 来实现批量的消费模型,通过这种 Ring Buffer 的方式既可以实现批量消费,又不需要为了攒批而等待。
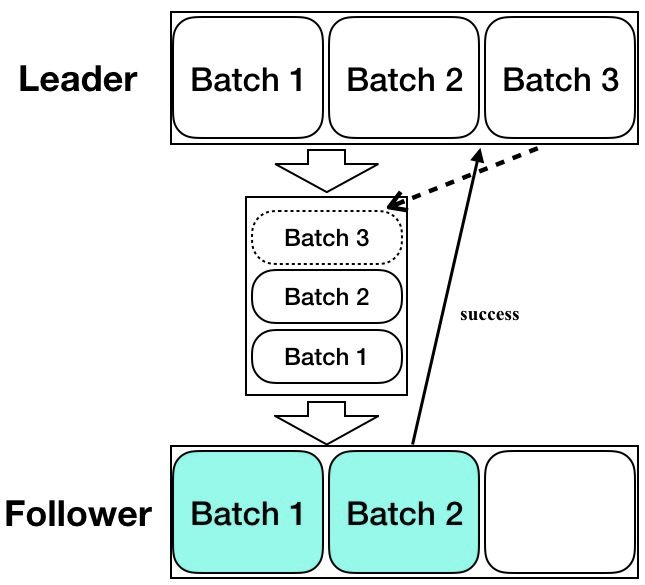
复制流水线主要是利用 Pipeline 的通信方式来提高日志复制的效率,如果 Leader 跟 Followers 节点的 Log 同步是串行 Batch 的方式,那么每个 Batch 发送之后需要等待 Batch 同步完成之后才能继续发送下一批(ping-pong), 这样会导致较长的延迟。通过 Leader 跟 Followers 节点之间的 Pipeline 复制可以有效降低更新的延迟, 提高吞吐。
什么是线性一致读呢?简单来说就是要在分布式环境中实现 Java volatile 语义的效果,也就是说当一个 Client 向集群发起写操作的请求并且得到成功响应之后,该写操作的结果要对所有后来的读请求可见。和 volatile 的区别是 volatile 是实现线程之间的可见,而 SOFAJRaft 需要实现 Server 之间的可见。实现这个目的最常规的办法是走 Raft 协议,将读请求同样按照 Log 处理,通过 Log 复制和状态机执行来得到读结果,然后再把结果返回给 Client。这种办法的缺点是需要 Log 存储、复制,这样会带来刷盘开销、存储开销、网络开销,因此在读操作很多的场景下对性能影响很大。所以 SOFAJRaft 采用 ReadIndex 来替代走 Raft 状态机的方案,简单来说就是依靠这样的原则直接从 Leader 读取结果:所有已经复制到多数派上的 Log(可视为写操作)就可以被视为安全的 Log,Leader 状态机只要按序执行到这条 Log 之后,该 Log 所体现的数据就能对 Client 可见了。具体可以分解为以下四个步骤:
Client 发起读请求;
Leader 确认最新复制到多数派的 LogIndex;
Leader 确认身份;
在 LogIndex apply 后执行读操作。
通过 ReadIndex 的优化,SOFAJRaft 已经能够达到 RPC 上限的 80%了。但是我们其实还可以再往前走一步,上面的步骤中可以看到第 3 步还是需要 Leader 通过向 Followers 发心跳来确认自己的 Leader 身份,因为 Raft 集群中的 Leader 身份随时可能发生改变。所以我们可以采用 LeaseRead 的方式把这一步 RPC 省略掉。租约可以理解为集群会给 Leader 一段租期(lease)的身份保证,在此期间 Leader 的身份不会被剥夺,这样当 Leader 收到读请求之后,如果发现租期尚未到期,就无需再通过和 Followers 通信来确认自己的 Leader 身份,这样就可以跳过第 3 步的网络通信开销。通过 LeaseRead 优化,SOFAJRaft 几乎已经能够达到 RPC 的上限。但是通过时钟维护租期本身并不是绝对的安全(时钟漂移问题),所以 SOFAJRaft 中默认配置是线性一致读,因为通常情况下线性一致读性能已足够好。
性能

这是我们性能测试的情况,测试条件如下:
3 台 16C 20G 内存的 Docker 容器作为 Server Node (3 副本)
2 ~ 8 台 8C Docker 容器 作为 Client
24 个 Raft 复制组,平均每台 Server Node 上各自有 8 个 Leader 负责读写请求,不开启 Follower 读
压测目标为 JRaft 中的 RheaKV 模块,只压测 Put、Get 两个接口,其中 get 是保证线性一致读的,Key 和 Value 大小均为 16 字节
读比例 10%,写比例 90%
可以看到在开启复制流水线之后,性能可以提升大约 30%。而当复制流水线和 Client-Batching 都开启之后,8 台 Client 能够达到 40w+ ops。
目前 SOFARaft 最新的版本是 v1.2.4,由于 Raft 算法本身也比较复杂,而且 SOFAJRaft 在实现中还做了很多优化,所以如果对今天的讲演有什么不清楚的地方,欢迎通过 SOFAJRaft wiki 继续了解更多细节,另外我们还有一个如何使用 SOFAJRaft 的示例,在 wiki 上也有详细的说明。除此之外,家纯同学写过一篇很详细的介绍文章《》,大家也可以看一看。
欢迎 Star SOFAJRaft 帮助我们改进。
文中涉及到的相关链接
https://tech.antfin.com/activities/382
https://github.com/alipay/sofa-jraft
SOFAJRaft wiki:
https://github.com/alipay/sofa-jraft/wiki
《》
欢迎加入,参与 SOFAJRaft 源码解析
本文为 SOFAJRaft 的初步介绍,主要还是希望大家对 SOFAJRaft 有一个初步的认识和了解。同时,我们开启了《剖析 | SOFAJRaft 实现原理》系列,会逐步详细介绍各个部分的代码设计和实现,预计按照如下的目录进行:
【待领取】SOFAJRaft 选举实现剖析
【待领取】SOFAJRaft 存储模块剖析
【待领取】SOFAJRaft replication-pipeline 实现剖析
【待领取】SOFAJRaft batch 优化剖析
【待领取】SOFAJRaft 线性一致读实现剖析
【待领取】SOFAJRaft snapshot 实现剖析
【待领取】SOFAJRaft-RheaKV 是如何使用 Raft 的
【待领取】SOFAJRaft-RheaKV 分布式锁实现剖析
【待领取】SOFAJRaft-RheaKV multi-raft-group 实现分析
如果有同学对以上某个主题特别感兴趣的,可以留言讨论,我们会适当根据大家的反馈调整文章的顺序,谢谢大家关注 SOFA ,关注 SOFAJRaft,我们会一直与大家一起成长的。
除了源码解析,也欢迎提交 issue 和 PR:
SOFAJRaft:https://github.com/alipay/sofa-jraft
长按关注,获取分布式架构干货
欢迎大家共同打造 SOFAStack
https://github.com/alipay
以上是关于详解蚂蚁金服 SOFAJRaft | 生产级高性能 Java 实现的主要内容,如果未能解决你的问题,请参考以下文章
蚂蚁金服开源 SOFAJRaft:生产级 Java Raft 算法库
蚂蚁金服生产级 Raft 算法库 SOFAJRaft 存储模块剖析 | SOFAJRaft 实现原理
SOFAJRaft Snapshot 原理剖析 | SOFAJRaft 实现原理