Raft 迷雾中寻支点
Posted AustinDatabases
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Raft 迷雾中寻支点相关的知识,希望对你有一定的参考价值。
Brain online
一个理论和协议,是要经过很多次推敲和验证的,所以任何的理论或协议都和应用型的理论或模型不大一样,前者的范围要广,可以通过这样的理论变化,形成一系列产品。 后者的范围窄,且可能会对比前者会经常性的改变以适应更多的需求。
先回顾一下,昨天到底说了什么,然后继续。
1 所有的服务(节点)的角色是一致的,也就是说,并不存在主从,primary standby , master slave , first second 这样的概念和形式,每个系统的节点的工作目标是一致的。
2 对服务的访问,在哪个节点都是一样的,都可以提供一样的服务,
3 在任何一个规定的时间内,一个节点负责客户和此节点的交互,而其他节点与这次访问的客户节点的信息交互,则需要这个时间内,和客户节点交互的 “负责”(并非主的概念)的那个节点来对其他节点进行信息共享。
4 服务节点在这个周期,只与这个负责的节点进行沟通,完成任务。
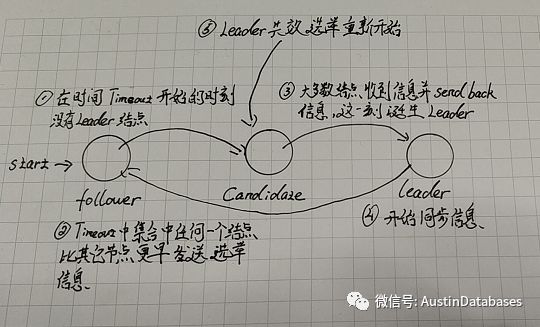
5 任何一个规定的时间段,只能有一个LEADER ,或者没有LEADER
6 所有的内部节点,要有一个统一的时间(UTC)这也是分布式系统大多数要一个 NTP 服务器,和UTC 的时间,(参见MONGODB 的分布式设计,在主键的设计,时间,以及集群的基本需求)都能体现一个分布式系统的设计要远远比一个集中的系统难度拔高的很多。
基本上,上面的信息就是一个对昨天整体的回顾。
这里还要提出一个问题,就是分布式系统对于通讯的要求,如果规定的时间设置的过长,则我们可能无法判断失效的节点,或者由于LEADER失效后,整体分布式系统的无应答时间加剧,造成信息传输的成本过大,最后的结果就是,按照这个方式设计的产品,客户基本上无法使用。
所以很多时候理论很好,但产品不好,并不是理论有问题,而是歪嘴的和尚把真经,当童谣输出了。
个人看法(各路神仙,说的不对请指正)分布式系统的关键点,在于
1 信息的传递,验证成本
2 分布式系统的时间设定
3 分布式系统的安全方面的问题
如果出了问题,则这个系统估计不会有太好的用户体验。
STOP 下面继续一些新的东西
首先,根据昨天的内容,我先问自己一个问题,这个理论中有没有让人觉得有一个地方容易忽略,但细想又觉得是一个问题。
个人看法,如果集群中得节点越多,这个问题可能不容易显现,但如果节点过少,在选举的初期,如果不凑巧,所有的节点都在同一个时间发送了选举请求怎么办? 并且收到的回执也是同一个时间,然后都各自声称自己是LEADER。
那这里这个系统就必须,在每个节点遇到这样的情况后,怎么自适应的调整自己的第下一次的TIMEOUT,并且不再会有可能再次产生这样的情况,或者在初始的时候就设定好,也是可以的(但初始的时候就设置好,总觉得哪里怪怪的)
今天试着搞清楚,RAFT 中的 Raft Log Consensus,,不过想想也是搞不清楚,这个问题很复杂。
试想几个点就能把脑子开始烧糊
1 各个节点的信息统一是通过LEADER发送的 replicated log 来保证的,那怎么来保证LEADER 发送的各个节点的版本的 repliated log 是一致的
2 各个节点不会一致保证没有问题,如果节点由于某些原因下线了,然后又启动了,主节点和这样的FOLLOWER 节点怎么进行交互 (因为部分信息在从启动的时间内并没有从LEADER 收到) 注:我们这里面不谈论很长时间的失效,这里讨论的仅仅是小时间段的失效。
3 如此这样想,那LEADER 每次发送的信息是不是要有一个记录,也就是我发送了多少记录,有多少 FOLLOWER 收到并反馈我
4 如果LEADER 失效了,下一次新的LEADER 发送的 replicated log 到底怎么标明shift leader, 或者我们就继续使用,不做变动,因为原理上标注,每个节点是平等的,那每一任LEADER 也是平等的ROLE(但实际上有这么容易吗,容易当上LEADER的节点,一定有网络传输的优势,到达其他节点更快等等优势,所以当上LEADER 并不是光靠运气)
5 如果Leader 在发送 replicated log 之前,就失效了,丢失的数据怎么办?
6 如果某个节点在一个时间段没有接受到LEADER的信息,但在下一个时间段又接受到了信息,不至于仲裁将这个节点驱逐出工作群,那缺失的数据又如何处理
以上这些仅仅是我想到的问题,实际中的问题估计成百上千。
回到日志的问题,文档中提到,每个LOG 单员应该含有一个Term(个人任务就是表示时间的东西,标明这条信息的在这个时间段的唯一性),另外信息在不断从 LEADER 中发送,则我们还需要一个标识发送LOG的数量,类似INDEX的东西。
文档里面提到,如何判断 LEADER 和 FOLLWER 的信息是否一致,除了用 TERM 和 INDEX 来保证传送包的数量和时间的一致,通知每次传递的LOG的时候,要包含上一次的传送的信息,这样一次传送信息,一箭双雕,新的信息录入了,而上一次的信息也比对了,效率比较高。
如果要我去想怎么比对上一次传输的信息在LEADER 和 FOLLOER 之间是否一致,或许我不会将两次的信息全部发送,上一次的信息的 MD5码或其他的验证码,就可以进行验证了,一个是验证的速度快,另外如果每次传输的信息长度大小不一样,给信息传输增加难度,所以找一个固定长度,好计算,极少撞库的 checksum 会更好。
Brain 又 LIMITATION 了。
想想通过一个理论,协议,搞出一套产品那是很不容易的,协议和理论仅仅给出了大方向,但如何利用理论和协议,开发出各种各样的产品,那就是另外一回事了,难度是可想而知。例如 TIDB ,几个大咖通过一些白皮书,能搞出现在这样的分布式数据库,并且是打破CAP 理论的, 重要的说四遍,打破CAP 打破CAP 打破CAP 理论的分布式数据库, SO HARD
以上是关于Raft 迷雾中寻支点的主要内容,如果未能解决你的问题,请参考以下文章