Raft算法的六个关键点(上)
Posted 武力程序猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Raft算法的六个关键点(上)相关的知识,希望对你有一定的参考价值。
“ 本文翻译自Youtube视频上Diego Ongaro讲解Raft算法的视频。有条件的同学可以点击 阅读原文 观看视频”
在开始正文之前,先分享一个讲解Raft算法的H5页面,十分生动
http://thesecretlivesofdata.com/raft/
00
—
引言:分布式系统一致性的算法分类
分为两类:
1. 对称(Symmetric)算法,无leader
所有的server平等
client可以连接任何一个server
2. 非对称(Asymmetric)算法,有leader
在某一时间点,有一个server处于leader状态,其余server接受leader的领导
client只能连接leader
Raft是一个非对称的分布式系统一致性算法,它有如下特点:
将问题分解成两步:普通操作 和 leader换届选举。
在不考虑leader改变的情况下,普通操作十分简单好理解。
相比对称算法,Raft更加的有效。
01
—
Raft算法的基本概念
Server状态分为三种:
Leader:处理Client请求
Follower:完全被动。不发送任何RPC,只响应RPC。
Candidate:用来选举新Leader
状态转换图:
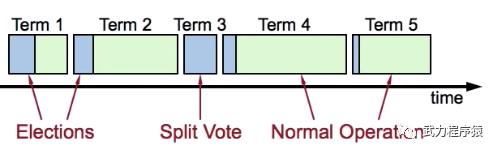
Raft中,时间按照Term去划分。每个Term分为两个部分:
Leader选举
在Leader领导下进行普通操作
每个Term最多只有1个Leader,有些Term选举过程中会分票因此没有Leader。每台server需要保存当前自己处于第几个Term
02
—
六个关键点之一:Leader选举
Server最开始的状态是Follower。Leader通过向Follower定期发送心跳来维持自己的权威,而Follower也是通过接收心跳来确保Leader存在。
如果Follower在 electionTimeout 时间内没有接收到任何心跳,那么就会开始新一轮的选举。
对于一个server来说,选举的过程是:
1. 对当前的Term值+1
2. 把自己的状态从Follower转变为Candidate,并且投自己一票。
3. 向其他所有Server发送RequestVote命令来请求他们投自己一票。如果有一些server没有response,会不断retry直到收到每一个server的response为止。
4. 在一段时间之后,server会有以下三种可能的状态:
收到超过半数server的投票。这样server会变为Leader并且立即向其他server发送心跳。
收到了别的Leader发送的RPC。这种情况下server会将自己的状态变为Follower
选举产生了分票情况,timeout之后还没有Leader产生。这种情况下server会重新进行整个选举的过程。
上述选举过程有两个保证:
Safety:选举过程最多只有一个winner。因为每个server最多投一票,且不可能有两个candidate同时获得了超过半数的票。
Liveness:选举过程会有server胜出。这一点很难保证,因为分票的情况有可能无限循环下去。Raft算法通过随机的timeout来保证了Liveness。随机的timeout,意味着有的server会“抢跑”,在别的server还没开始拉票的时候,这个server已经胜出了。
03
—
六个关键点之二:普通操作
我们仍然用如何创建replicated log这一问题来做讲解。
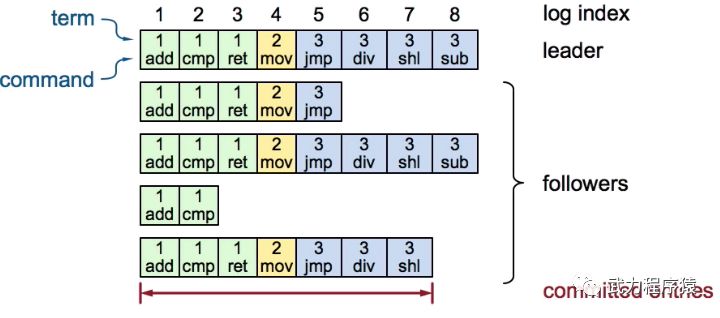
在上图中,每一行都代表一个server保存的log信息。第一行的server是Leader,其他的都是Follower。
在每个log entry里都有两部分:Term number和log信息。
如果一个entry,比如第7个,被大多数的server认可了,那么就认为这个log已经达到了commited状态。
普通操作的过程很简单:
1. Client给Leader发送消息。
2. Leader把收到的消息加入自己的log。
3. Leader为了告诉Follower这条消息,需要给所有的Follower发送AppendEntries消息,并且等待response。如果有1/2的Follower返回正确的response(加上Leader自己就组成了majority),那么这个新的消息就会被当做committed。在这个步骤中要注意四点:1)Leader只需要等待半数的response,而不是全部。2)Leader如果等不到半数的消息,会不断retry。3)Follower并不总是返回正确的response,有时会返回错误的response。4)这里的committed的定义其实是不完全的,我们会在接下来进行补充。具体的逻辑会在下一篇文章中补充。
4. 在Log被committed之后,Leader会将Log执行,并返回给Client结果。此外,Leader还会在接下来的AppendEntries消息中,告诉Follower这条log已经被committed,这样Follower就会执行这条log
Raft在普通操作过程中,保证了Log的一致性,具体是:
如果不同server上,同一个log entry下,两个log具有相同的Term number,那么
1) 两个log一定是相同的。
2) 且他们之前的log也一定是相同的。
如上图所示。index=5的log具有相同的Term=3。因此log的内容一定是相同的,而index=5之前所有的log也一定是相同的。
刚才说过,Follower收到Leader的AppendEntries消息之后,会进行自己的判断,具体来讲是:
1. Leader发送的AppendEntries消息中,额外包含了前一条log的index和Term number。
2. 当且仅Follower当前log的index和Term number,完全等同于AppendEntries中包含的log index和Term number时,Follower才会返回正确的response。
3. 在其他情况下,Follower会拒绝这个请求。
结合例子来讲,如下图所示:
在虚线之上的例子,Leader收到了Client发来的jmp log,放在了index=5的位置。Leader发送的AppendEntries中,包含了前一条log index=4,Term=2。在Follower收到了这条消息之后比较自己当前index=4的位置Term也是2,于是返回正确的response。
虚线之下的例子中,Follower就会拒绝这个请求。
想必聪明的同学在这里已经嗅到了一点数学归纳法的阴谋。。用数学归纳法的思想来看,只要Follower同意了当前Leader的AppendEntries,那么Follower中的log保证了和Leader中的log完全一致。
以上是关于Raft算法的六个关键点(上)的主要内容,如果未能解决你的问题,请参考以下文章