Raft算法的六个关键点(下)
Posted 武力程序猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Raft算法的六个关键点(下)相关的知识,希望对你有一定的参考价值。
“本文翻译自Youtube视频上Diego Ongaro讲解Raft算法的视频。有条件的同学可以点击 阅读原文 观看视频”
上周的文章对Raft算法进行了简单的介绍,并介绍了前两个关键点。本文将继续介绍余下的四个关键点。
01
—
六个关键点之三:Leader变化之后的安全性和一致性
在分布式系统中总是存在着很多的不确定。老的Leader随时可能down掉,而新的Leader随时可能进来。在这种不确定的分布式系统中,不同server的log可能会完全不同,像一团乱麻。如下图所示:
这个5台server的cluster中log几乎完全不同。这种情况是很正常的,而在这乱如麻的log中,唯一重要的log是被committed的log。在上图中,也就是S1的index1-3,S2的index1-3,S3的index1-3,S4的index1-2,S5的index1-2.
其他的log都不重要,不论接下来哪个server成了Leader,Raft算法都会使其他的Follower的log,长得跟Leader的log一样。
在这种分布式系统的一致性算法中,有一条重要的安全性原则就是:
如果一个log entry中的log被传入了状态机,那么系统中别的server不能在这个log entry中传入一个不同的值。
为了达到这一条安全性的要求,Raft保证了:
如果一个Leader认为一条log entry是committed状态,那么以后所有的Leader都会有这个log entry。
> Raft如何保证选出的新Leader包含了所有被committed的log呢?
在选举过程中,只选择 可能包含了所有commited log 的Candidate。下面描述Raft的选举规则:
Candidate在RequestVote RPC中,包含了自己最后一条log的index和Term
对于RequestVote RPC中携带的log信息,Voter只有对比过后觉得自己的最后一条log不比那条log新,才会投赞成票。否则会投反对票。
这样选出来的Leader中包含的log,会比给他投票的majority server中的log都新,或者至少不比他们的旧。
对于如下两种情况,我们要分析一下这个选举规则是怎么运行的:
Case1:Leader标记当前Term的一个log是committed
Case2:Leader标记前几轮Term的log是committed。(这是可能发生的因为Leader有可能没有标记committed就down了,两三轮之后这个Leader又活了,他要标记前几轮的log是committed)
下边具体讲述:
Case1:Leader标记当前Term的一个log是committed
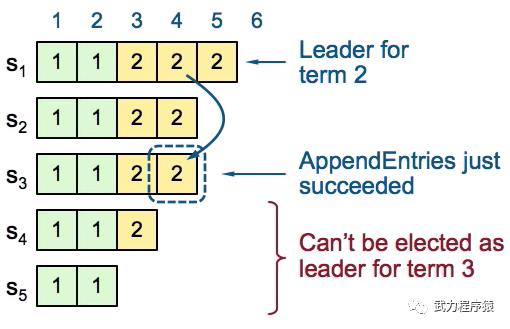
如上图所示,此时处于Term2,Leader是S1。
对于index=4,S1把log放到了S1~S3,因此S1认为index=4处的log是committed。这里没有问题。因为即使S1挂掉了,根据*选举规则*,我们可以保证S4和S5不会成为Leader,因此保证了 安全性,也就是新的Leader一定包含了所有被committed的log。
Case2:Leader标记前几轮Term的log是committed
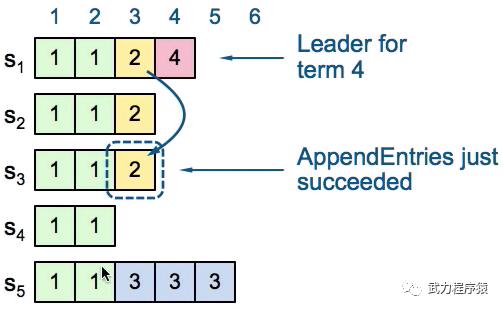
如上图所示,按顺序发生了如下事情:
1)在Term2,S1是Leader,S1把index=3处的log放到了S1和S2,因为没有放到majority机器上,因此index=3并不是committed状态。
2)在Term3,S5得到了S3~S5的投票成为了Leader。S5接收了好几个log,但是还没来得及sync到别的server。
3)很遗憾S5跪了,来到了Term4。在Term4,S1得到了S1~S4的投票成为了Leader,S1接下来将自己index=3处的log放到了S3上。
在此时,index=3&Term=2的log好像可以被S1当做是committed了。但是这样是不对的!!因为我们有可能在下一步,S5被选举成了Leader(根据选举规则这个是有可能的,票来自于S2~S4都可以)。而这个Leader并不包含被committed的index=3&Term=2的log。这样违背了我们的安全性原则。
在这种情况下,我们需要修改commited的定义。在以前,我们认为只要Leader把log放到了多数server上,这个log就是committed。现在我们要加一条:
必须有 当前Term 的一条log被放在了超过半数的server上。
加上这一条定义之后,选举规则和committed规则结合起来,保证了Raft的安全性,也就是 新Leader一定包含了所有被committed的log。
我们回到刚才的例子。在Term4,S1得到了S1~S4的投票成为了Leader,S1接下来将自己index=3处的log放到了S3上。但是我们还没有commit任何一条Term4的log,因此index=3&Term=2的log并不能commit。直到S1将一条当前Term,也就是Term4的log放到多数机器上之后,index=3&Term=2 和 index=4&Term=4的log才能被同时认为是committed。因为,一旦index=4&Term=4的log被放到多数机器上之后,根据选举规则,S5才没有了被选为Leader的可能性。
如下图所示。
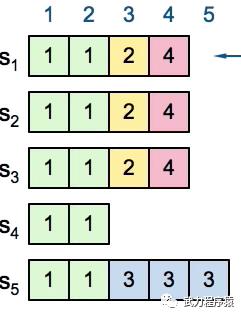
OK,我们刚才用超长的篇幅说完了安全性,安全性保证了Leader的log一定是正确的,下边来说log的一致性,也就是Follower的log和Leader的log是一样的。安全性+一致性,这样所有server上的log都是正确的了。
首先,相对于Leader,Follower的log有两种情况:缺少log或者错误的log。缺少的log可能是由于还没有来得及同步,而错误的log可能是由于前几个Term的log还没有commit。
我们在 普通操作 一节中讲到,Leader会给Follower发送AcceptEntries的RPC请求,请求中携带了上一条log的index+Term。而Follower会对比这个值是否和自己最后一条log的值一样。如果不一样,就会拒绝这个请求。
拒绝请求就意味着Follower和Leader的log不一致。Leader感知到了这种不一致,会继续检查上上一条log,上上上一条log,直到有一致的log entry。接下来从前往后重新发送AcceptEntries RPC,填上Follower缺少的log,overwrite Follower错误的log。
02
—
六个关键点之四:如何处理老Leader的回归
在分布式系统中,有一种情况就是老的Leader并没有真正地挂掉。而是仅仅在网络中被隔离了,假设它断网了。这种情况下剩下的server会选举出一个新的Leader。一段时间之后网络重归正常,老的Leader回归,他以为自己仍然是Leader,会做出一系列操作。Raft需要做的事情是制止老Leader的这种行为。
Term机制可以有效地防止这种情况发生。Raft算法中,每个RPC都会包含发送者的Term值。当server收到RPC的时候,会比较自己的Term和RPC中包含的Term。
1)如果发送者的Term比较旧,RPC会被接受者拒绝。而发送者会成为Follwer
2)如果接受者的Term比较旧,接受者会根据信息更新自己,RPC会继续被处理。
在这里,核心问题是当选举过程结束后,多数server中已经有了最新的Term值,所以老Leader回归之后就无法继续自己的Leader操作了。
03
—
六个关键点之五:和Client端交互
在Raft算法中,Client只会和Leader节点交互。而Leader节点在收到request之后,会先log下来,保证log已经被commited,然后提交给状态机执行。这些步骤都结束之后,才会将response返回给Client。
如果Leader 崩掉了,Client会发生timeout,并且重新发送request给新的Leader。
有一种情况是:Leader在sync完指令,执行完指令,但是还没有回复client的时候崩溃了!看过前几篇文章的同学还记得,Multi-Paxos保证了在上述情况下同一条指令不能执行两次。同样,Raft算法也保证了这一点。而且解决方式也是类似的:Client保存一个id,Leader判断没有执行过这个id的log,才会执行这条log。
04
—
六个关键点之六:配置改变
系统配置包括server ID,还要确定majority的确切数量。
对于一个正确的一致性算法来说,支持运行时的配置改变是必要的。这些改变包括:
1)替换的某一台server
2)增加/减少 集群中server的数量。
需要意识到的是,简单的进行配置改变是很危险的。如下图所示:
横轴代表了时间线,绿色条代表旧的配置,蓝色条代表新的配置。在某一个时间点,server 1/2用旧配置形成了majority,server 3/4/5用新配置形成了majority。这样一致性就被破坏了。
如何解决呢?非常简单。大家把握一点:
在分布式系统中做出决定都需要two-phase protocal(两阶段提交)。
Raft就是用了两阶段提交来解决这个问题的。具体而言,Raft允许新旧配置共存。在某些时刻,一些server可以是新的配置,而另一些server还是旧的配置。而在这种(joint consensus)中间状态,所有决策的做出都同时需要两部分majority的共同同意。
如上图所示,横轴是时间轴。我们按照时间轴来讲解:
1)深红色的实线:Leader初始状态是运行在只有old config的状态下,也就是C<old>。
2)深红色虚线+蓝色虚线:当Leader收到配置改变的请求后,会将C<old,new>存到自己的log里,并且发送appendEntries请求给Follower。所有收到新config的server,都会让config立即生效。在C<old,new>被committed之前,如果Leader崩掉了,含有old config的server是有可能被选成Leader的。
3)蓝色实线:在一段时间之后,如同普通的log一样,C<old,new>就会变成committed状态。在这个阶段,cluster会运行在 joint consensus状态,所有的决定都需要根据C<old,new>共同做决定,不可能有只包含old config的Leader出现了。
4)蓝色虚线+绿色虚线:Leader会做出一个config改变,试图将C<old,new>变成C<new>。Leader会将C<new>append到自己的log里,并同步到所有的Follower。在这个阶段,如果Leader崩掉了,含有new config的server是有可能被选成Leader的。
5)绿色实线:C<new>被committed,过程结束。
在以上的实现中,因为old config和new config不可能同时做出unilateral decision,所以保证了一致性。
以上是关于Raft算法的六个关键点(下)的主要内容,如果未能解决你的问题,请参考以下文章