多图详解Raft算法原理
Posted java技术coder
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多图详解Raft算法原理相关的知识,希望对你有一定的参考价值。
简介
关于Raft算法,有两篇经典的论文,一篇是《In search of an Understandable Consensus Algorithm》,这是作者最开始讲述Raft算法原理的论文,但是这篇论文太简单了,很多算法的细节没有涉及到。更详细的论文是《CONSENSUS: BRIDGING THEORY AND PRACTICE》,除了包括第一篇论文的内容以外,还加上了很多细节的描述。在我阅读完etcd raft算法库的实现之后,发现这个库的代码基本就是按照后一篇论文来写的,甚至有部分测试用例的注释里也写明了是针对这篇论文的某一个小节的情况做验证。
这篇文章做为我后续分析etcd raft算法的前导文章,将结合后一篇论文加上一些自己的演绎和理解来讲解Raft算法的原理。
算法的基本流程
Raft算法概述
Raft算法由leader节点来处理一致性问题。leader节点接收来自客户端的请求日志数据,然后同步到集群中其它节点进行复制,当日志已经同步到超过半数以上节点的时候,leader节点再通知集群中其它节点哪些日志已经被复制成功,可以提交到raft状态机中执行。
通过以上方式,Raft算法将要解决的一致性问题分为了以下几个子问题。
leader选举:集群中必须存在一个leader节点。
日志复制:leader节点接收来自客户端的请求然后将这些请求序列化成日志数据再同步到集群中其它节点。
安全性:如果某个节点已经将一条提交过的数据输入raft状态机执行了,那么其它节点不可能再将相同索引 的另一条日志数据输入到raft状态机中执行。
Raft算法需要一直保持的三个属性。
选举安全性(Election Safety):在一个任期内只能存在最多一个leader节点。
Leader节点上的日志为只添加(Leader Append-Only):leader节点永远不会删除或者覆盖本节点上面的日志数据。
日志匹配性(Log Matching):如果两个节点上的日志,在日志的某个索引上的日志数据其对应的任期号相同,那么在两个节点在这条日志之前的日志数据完全匹配。
leader完备性(Leader Completeness):如果一条日志在某个任期被提交,那么这条日志数据在leader节点上更高任期号的日志数据中都存在。
状态机安全性(State Machine Safety):如果某个节点已经将一条提交过的数据输入raft状态机执行了,那么其它节点不可能再将相同索引的另一条日志数据输入到raft状态机中执行。
Raft算法基础
在Raft算法中,一个集群里面的所有节点有以下三种状态:
Leader:领导者,一个集群里只能存在一个Leader。
Follower:跟随者,follower是被动的,一个客户端的修改数据请求如果发送到Follower上面时,会首先由Follower重定向到Leader上,
Candidate:参与者,一个节点切换到这个状态时,将开始进行一次新的选举。
每一次开始一次新的选举时,称为一个“任期”。每个任期都有一个对应的整数与之关联,称为“任期号”,任期号用单词“Term”表示,这个值是一个严格递增的整数值。
节点的状态切换状态机如下图所示。
上图中标记了状态切换的6种路径,下面做一个简单介绍,后续都会展开来详细讨论。
start up:起始状态,节点刚启动的时候自动进入的是follower状态。
times out, starts election:follower在启动之后,将开启一个选举超时的定时器,当这个定时器到期时,将切换到candidate状态发起选举。
times out, new election:进入candidate 状态之后就开始进行选举,但是如果在下一次选举超时到来之前,都还没有选出一个新的leade,那么还会保持在candidate状态重新开始一次新的选举。
receives votes from majority of servers:当candidate状态的节点,收到了超过半数的节点选票,那么将切换状态成为新的leader。
discovers current leader or new term:candidate状态的节点,如果收到了来自leader的消息,或者更高任期号的消息,都表示已经有leader了,将切换回到follower状态。
discovers server with higher term:leader状态下如果收到来自更高任期号的消息,将切换到follower状态。这种情况大多数发生在有网络分区的状态下。
如果一个candidate在一次选举中赢得leader,那么这个节点将在这个任期中担任leader的角色。但并不是每个任期号都一定对应有一个leader的,比如上面的情况3中,可能在选举超时到来之前都没有产生一个新的leader,那么此时将递增任期号开始一次新的选举。
从以上的描述可以看出,任期号在raft算法中更像一个“逻辑时钟(logic clock)”的作用,有了这个值,集群可以发现有哪些节点的状态已经过期了。每一个节点状态中都保存一个当前任期号(current term),节点在进行通信时都会带上本节点的当前任期号。如果一个节点的当前任期号小于其他节点的当前任期号,将更新其当前任期号到最新的任期号。如果一个candidate或者leader状态的节点发现自己的当前任期号已经小于其他节点了,那么将切换到follower状态。反之,如果一个节点收到的消息中带上的发送者的任期号已经过期,将拒绝这个请求。
raft节点之间通过RPC请求来互相通信,主要有以下两类RPC请求。RequestVote RPC用于candidate状态的节点进行选举之用,而AppendEntries RPC由leader节点向其他节点复制日志数据以及同步心跳数据的。
leader选举
现在来讲解leader选举的流程。
raft算法是使用心跳机制来触发leader选举的。
在节点刚开始启动时,初始状态是follower状态。一个follower状态的节点,只要一直收到来自leader或者candidate的正确RPC消息的话,将一直保持在follower状态。leader节点通过周期性的发送心跳请求(一般使用带有空数据的AppendEntries RPC来进行心跳)来维持着leader节点状态。每个follower同时还有一个选举超时(election timeout)定时器,如果在这个定时器超时之前都没有收到来自leader的心跳请求,那么follower将认为当前集群中没有leader了,将发起一次新的选举。
发起选举时,follower将递增它的任期号然后切换到candidate状态。然后通过向集群中其它节点发送RequestVote RPC请求来发起一次新的选举。一个节点将保持在该任期内的candidate状态下,直到以下情况之一发生。
该candidate节点赢得选举,即收到超过半数以上集群中其它节点的投票。
另一个节点成为了leader。
选举超时到来时没有任何一个节点成为leader。
下面来逐个分析以上几种情况。
第一种情况,如果收到了集群中半数以上节点的投票,那么此时candidate节点将成为新的leader。每个节点在一个任期中只能给一个节点投票,而且遵守“先来后到”的原则。这样就保证了,每个任期最多只有一个节点会赢得选举成为leader。但并不是每个进行选举的candidate节点都会给它投票,在后续的“选举安全性”一节中将展开讨论这个问题。当一个candidate节点赢得选举成为leader后,它将发送心跳消息给其他节点来宣告它的权威性以阻止其它节点再发起新的选举。
第二种情况,当candidate节点等待其他节点时,如果收到了来自其它节点的AppendEntries RPC请求,同时做个请求中带上的任期号不比candidate节点的小,那么说明集群中已经存在leader了,此时candidate节点将切换到follower状态;但是,如果该RPC请求的任期号比candidate节点的小,那么将拒绝该RPC请求继续保持在candidate状态。
第三种情况,一个candidate节点在选举超时到来的时候,既没有赢得也没有输掉这次选举。这种情况发生在集群节点数量为偶数个,同时有两个candidate节点进行选举,而两个节点获得的选票数量都是一样时。当选举超时到来时,如果集群中还没有一个leader存在,那么candidate节点将继续递增任期号再次发起一次新的选举。这种情况理论上可以一直无限发生下去。
为了减少第三种情况发生的概率,每个节点的选举超时时间都是随机决定的,一般在150~300毫秒之间,这样两个节点同时超时的情况就很罕见了。
以上过程用伪代码来表示如下。
节点刚启动,进入follower状态,同时创建一个超时时间在150-300毫秒之间的选举超时定时器。follower状态节点主循环:如果收到leader节点心跳:心跳标志位置1如果选举超时到期:没有收到leader节点心跳:任期号term+1,换到candidate状态。如果收到leader节点心跳:心跳标志位置空如果收到选举消息:如果当前没有给任何节点投票过 或者 消息的任期号大于当前任期号:投票给该节点否则:拒绝投票给该节点candidate状态节点主循环:向集群中其他节点发送RequestVote请求,请求中带上当前任期号term收到AppendEntries消息:如果该消息的任期号 >= 本节点任期号term:说明已经有leader,切换到follower状态否则:拒绝该消息收到其他节点应答RequestVote消息:如果数量超过集群半数以上,切换到leader状态如果选举超时到期:term+1,进行下一次的选举
日志复制的流程大体如下:
每个客户端的请求都会被重定向发送给leader,这些请求最后都会被输入到raft算法状态机中去执行。
leader在收到这些请求之后,会首先在自己的日志中添加一条新的日志条目。
在本地添加完日志之后,leader将向集群中其他节点发送AppendEntries RPC请求同步这个日志条目,当这个日志条目被成功复制之后(什么是成功复制,下面会谈到),leader节点将会将这条日志输入到raft状态机中,然后应答客户端。
Raft日志的组织形式如下图所示。
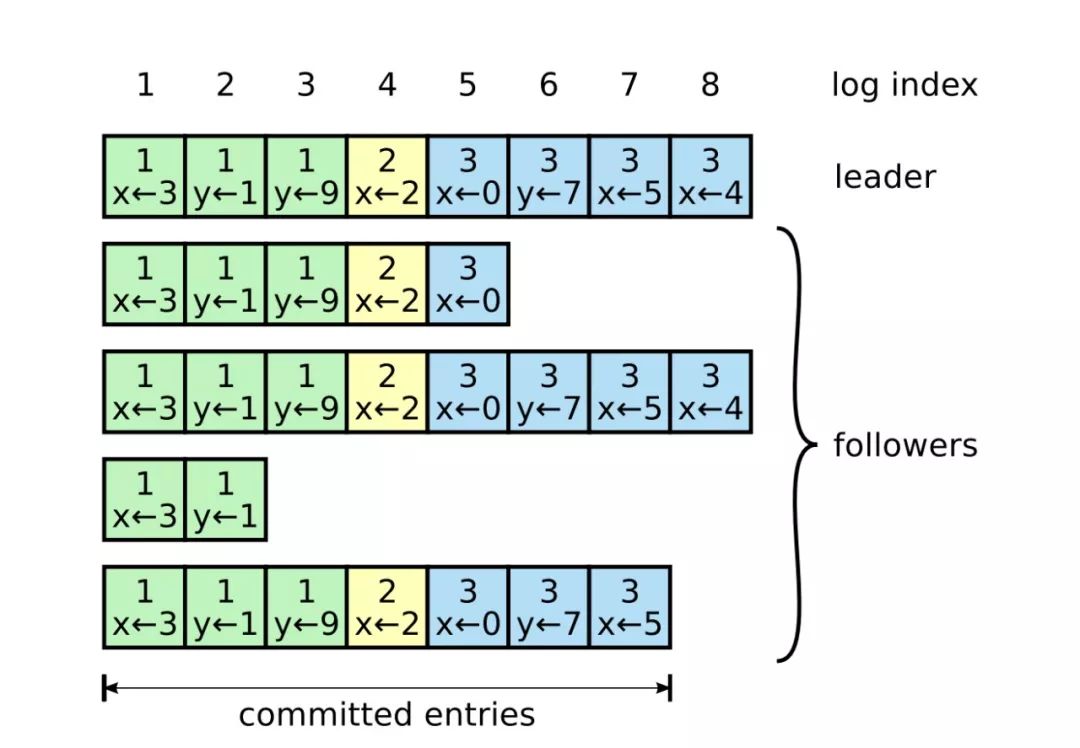
每个日志条目包含以下成员。
index:日志索引号,即图中最上方的数字,是严格递增的。
term:日志任期号,就是在每个日志条目中上方的数字,表示这条日志在哪个任期生成的。
command:日志条目中对数据进行修改的操作。
一条日志如果被leader同步到集群中超过半数的节点,那么被称为“成功复制”,这个日志条目就是“已被提交(committed)”。如果一条日志已被提交,那么在这条日志之前的所有日志条目也是被提交的,包括之前其他任期内的leader提交的日志。如上图中索引为7的日志条目之前的所有日志都是已被提交的日志。
以下面的图示来说明日志复制的流程。
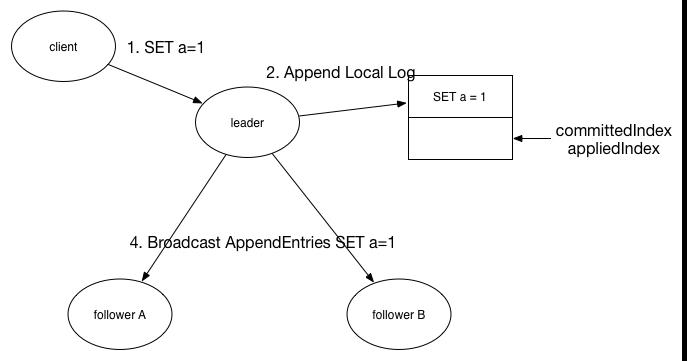
在上图中,一个请求有以下步骤。
1. 客户端发送SET a=1的命令到leader节点上。
2. leader节点在本地添加一条日志,其对应的命令为SET a=1。这里涉及到两个索引值,committedIndex存储的最后一条提交(commit)日志的索引,appliedIndex存储的是最后一条应用到状态机中的日志索引值,一条日志只有被提交了才能应用到状态机中,因此总有 committedIndex >= appliedIndex不等式成立。在这里只是添加一条日志还并没有提交,两个索引值还指向上一条日志。
3. leader节点向集群中其他节点广播AppendEntries消息,带上SET a=1命令。
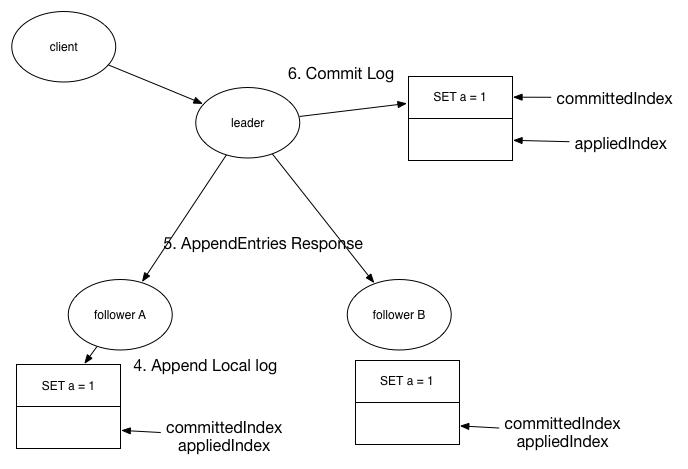
接下来继续看,上图中经历了以下步骤。
4. 收到AppendEntries请求的follower节点,同样在本地添加了一条新的日志,也还并没有提交。
5. follower节点向leader节点应答AppendEntries消息。
6. 当leader节点收到集群半数以上节点的AppendEntries请求的应答消息时,认为SET a=1命令成功复制,可以进行提交,于是修改了本地committed日志的索引指向最新的存储SET a=1的日志,而appliedIndex还是保持着上一次的值,因为还没有应用该命令到状态机中。
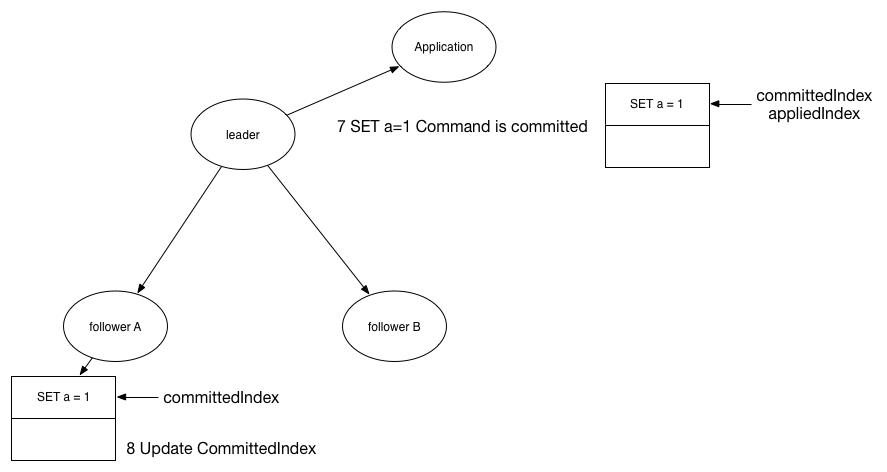
当这个命令提交完成了之后,命令就可以提交给应用层了。
7. 提交命令完成,给应用层说明这条命令已经提交。此时修改appliedIndex与committedIndex一样了。
8. leader节点在下一次给follower的AppendEntries请求中,会带上当前最新的committedIndex索引值,follower收到之后同样会修改本地日志的committedIndex索引。
需要说明的是,7和8这两个操作并没有严格的先后顺序,谁在前在后都没关系。
leader上保存着已被提交的最大日志索引信息,在每次向follower节点发送的AppendEntries RPC请求中都会带上这个索引信息,这样follower节点就知道哪个日志已经被提交了,被提交的日志将会输入Raft状态机中执行。
Raft算法保持着以下两个属性,这两个属性共同作用满足前面提到的日志匹配(LogMatch)属性:
如果两个日志条目有相同的索引号和任期号,那么这两条日志存储的是同一个指令。
如果在两个不同的日志数据中,包含有相同索引和任期号的日志条目,那么在这两个不同的日志中,位于这条日志之前的日志数据是相同的。
在正常的情况下,follower节点和leader节点的日志一直保持一致,此时AppendEntries RPC请求将不会失败。但是,当leader节点宕机时日志就可能出现不一致的情况,比如在这个leader节点宕机之前同步的数据并没有得到超过半数以上节点都复制成功了。如下图所示就是一种出现前后日志不一致的情况。
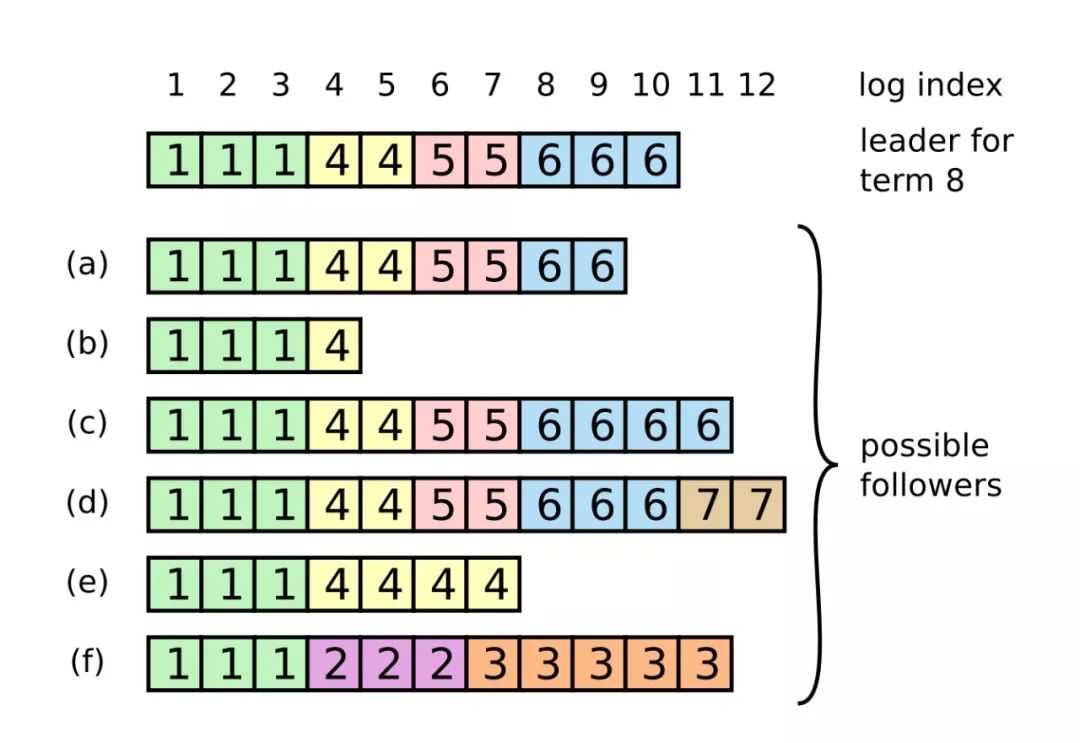
在上图中,最上面的一排数字是日志的索引,盒子中的数据是该日志对应的任期号,左边的字母表示的是a-f这几个不同的节点。图中演示了好几种节点日志与leader节点日志不一致的情况,下面说明中以二元组<任期号,索引号>来说明各个节点的日志数据情况:
leader节点:<6, 10>。
a节点:<6,9>,缺少日志。
b节点:<4,4>,任期号比leader小,因此缺少日志。
c节点:<6,11>,任期号与leader相同,但是有比leader日志索引更大的日志,这部分日志是未提交的日志。
d节点:<7,12>,任期号比leader大,这部分日志是未提交的日志。
e节点:<4,7>,任期号与索引都比leader小,因此既缺少日志,也有未提交的日志。
f节点:<3,11>,任期号比leader小,所以缺少日志,而索引比leader大,这部分日志又是未提交的日志。
在Raft算法中,解决日志数据不一致的方式是Leader节点同步日志数据到follower上,覆盖follower上与leader不一致的数据。
为了解决与follower节点同步日志的问题,leader节点中存储着两个与每个follower节点日志相关的数据。
nextIndex存储的是下一次给该节点同步日志时的日志索引。
matchIndex存储的是该节点的最大日志索引。
从以上两个索引的定义可知,在follower与leader节点之间日志复制正常的情况下,nextIndex = matchIndex + 1。但是如果出现不一致的情况,则这个等式可能不成立。每个leader节点被选举出来时,将初始化nextIndex为leader节点最后一条日志,而matchIndex为0,这么做的原因在于:leader节点将从后往前探索follower节点当前存储的日志位置,而在不知道follower节点日志位置的情况下只能置空matchIndex了。
leader节点通过AppendEntries消息来与follower之间进行日志同步的,每次给follower带过去的日志就是以nextIndex来决定,如果follower节点的日志与这个值匹配,将返回成功;否则将返回失败,同时带上本节点当前的最大日志ID,方便leader节点快速定位到follower的日志位置以下一次同步正确的日志数据,而leader节点在收到返回失败的情况下,将置nextIndex = matchIndex + 1。从上面的分析可知,在leader当前之后第一次向follower同步日志失败时,nextIndex = matchIndex + 1 = 1。
以上图的几个节点为例来说明情况。
初始状态下,leader节点将存储每个folower节点的nextIndex为10,matchIndex为0。因此在成为leader节点之后首次向follower节点同步日志数据时,将复制索引位置在10以后的日志数据,同时带上日志二元组<6,10>告知follower节点当前leader保存的follower日志状态。
a节点:由于节点的最大日志数据二元组是<6,9>,正好与leader发过来的日志<6,10>紧挨着,因此返回复制成功。
b节点:由于节点的最大日志数据二元组是<4,4>,与leader发送过来的日志数据<6,10>不匹配,将返回失败同时带上自己最后的日志索引4,leader节点在收到该拒绝消息之后,将修改保存该节点的nextIndex为matchIndex + 1即1,所以下一次leader节点将同步从索引1到10的数据给b节点。
c节点:由于节点的最大日志数据二元组是<6,11>,与leader发送过来的日志数据<6,10>不匹配,将返回失败同时带上自己最后的日志索 引11,leader节点在收到该拒绝消息之后,将修改保存该节点的nextIndex为matchIndex + 1即1,所以下一次leader节点将同步从索引1到10的数据给c节点,由于c节点上有未提交的数据,所以在第二次与leader同步完成之后,这些未提交的数据被清除。
d节点:由于节点的最大日志数据二元组是<7,12>,与leader发送过来的日志数据<6,10>不匹配,将返回失败同时带上自己最后的日志索 引11,leader节点在收到该拒绝消息之后,将修改保存该节点的nextIndex为matchIndex + 1即1,所以下一次leader节点将同步从索引1到10的数据给d节点,由于d节点上有未提交的数据,所以在第二次与leader同步完成之后,这些未提交的数据被清除。
e节点:由于节点的最大日志数据二元组是<4,7>,与leader发送过来的日志数据<6,10>不匹配,将返回失败同时带上自己最后的日志索 引11,leader节点在收到该拒绝消息之后,将修改保存该节点的nextIndex为matchIndex + 1即1,所以下一次leader节点将同步从索引1到10的数据给e节点,由于e节点上缺少的日志数据将被补齐,而多出来的未提交数据将被清除。
f节点:由于节点的最大日志数据二元组是<4,7>,与leader发送过来的日志数据<6,10>不匹配,将返回失败同时带上自己最后的日志索 引11,leader节点在收到该拒绝消息之后,将修改保存该节点的nextIndex为matchIndex + 1即1,所以下一次leader节点将同步从索引1到10的数据给f节点,由于f节点上缺少的日志数据将被补齐,而多出来的未提交数据将被清除。
安全性
前面章节已经将leader选举以及日志同步的机制介绍了,这一小节讲解安全性相关的内容。
选举限制
raft算法中,并不是所有节点都能成为leader。一个节点要成为leader,需要得到集群中半数以上节点的投票,而一个节点会投票给一个节点,其中一个充分条件是:这个进行选举的节点的日志,比本节点的日志更新。之所以要求这个条件,是为了保证每个当选的节点都有当前最新的数据。为了达到这个检查日志的目的,RequestVote RPC请求中需要带上参加选举节点的日志信息,如果节点发现选举节点的日志信息并不比自己更新,将拒绝给这个节点投票。
如果判断日志的新旧?这通过对比日志的最后一个日志条目数据来决定,首先将对比条目的任期号,任期号更大的日志数据更新;如果任期号相同,那么索引号更大的数据更新。
以上处理RequestVote请求的流程伪代码表示如下。
follower节点收到RequestVote请求:对比RequestVote请求中带上的最后一条日志数据:如果任期号比节点的最后一条数据任期号小:拒绝投票给该节点如果索引号比节点的最后一条数据索引小:拒绝投票给该节点其他情况:说明选举节点的日志信息比本节点更新,投票给该节点。
如果leader在写入但是还没有提交一条日志之前崩溃,那么这条没有提交的日志是否能提交?有几种情况需要考虑,如下图所示。
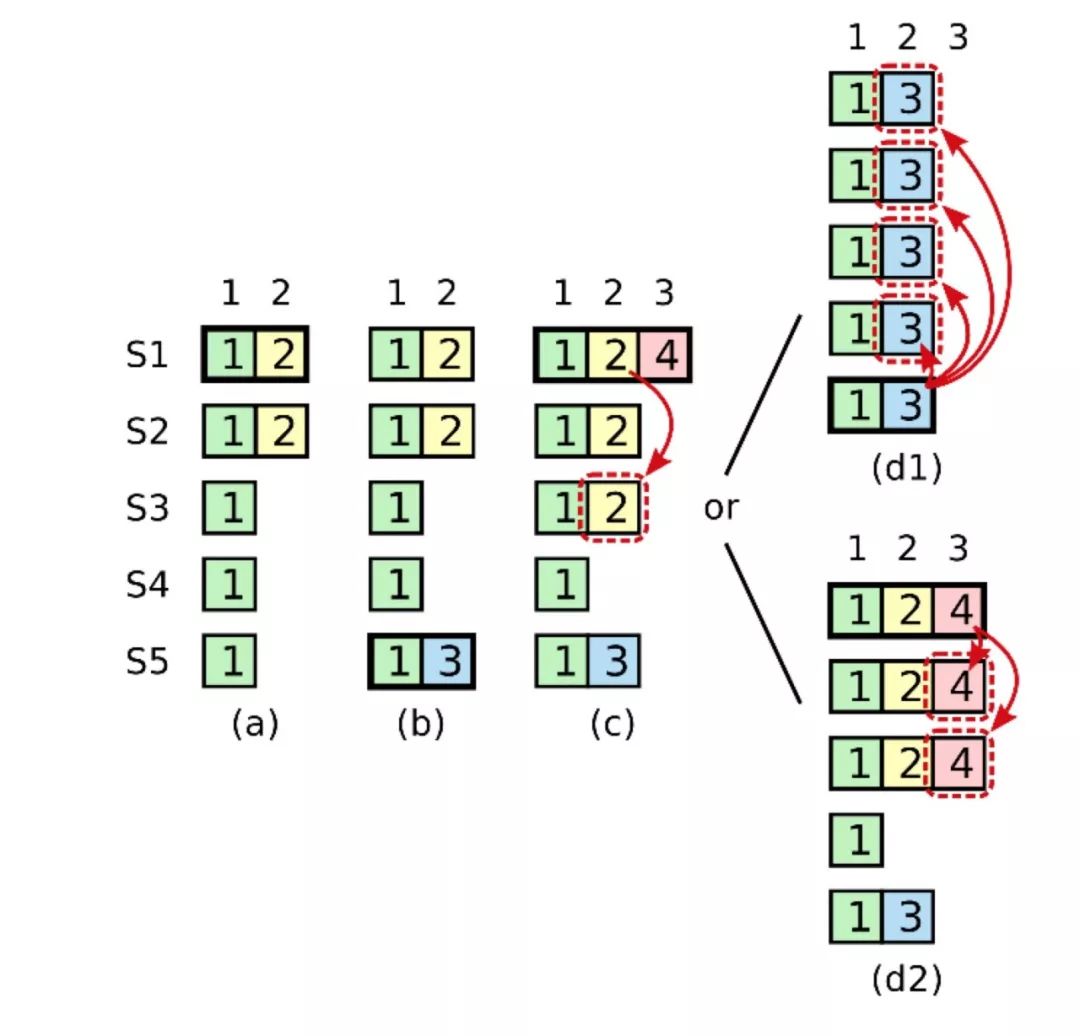
在上图中,有以下的场景变更。
情况a:s1是leader,index 2位置写入了数据2,该值只写在了s1,s2上,但是还没有被提交。
情况b: s1崩溃,s5成为新的leader,该节点在index 2上面提交了另外一个值3,但是这个值只写在了s5上面,并没有被提交。
情况c: s5崩溃,s1重新成为leader,这一次,index 2的值2写到了集群的大多数节点上。
此时可能存在以下两种情况:
情况d1: s1崩溃,s5重新成为leader(投票给s5的是s4,s2和s5自身),那么index 2上的值3这一次成功的写入到集群的半数以上节点之上,并成功提交。
情况d2: s1不崩溃,而是将index 2为2的值成功提交。
从情况d的两种场景可以看出,在index 2值为2,且已经被写入到半数以上节点的情况下,同样存在被新的leader覆盖的可能性。
由于以上的原因,对于当前任期之前任期提交的日志,并不通过判断是否已经在半数以上集群节点写入成功来作为能否提交的依据。只有当前leader任期内的日志是通过比较写入数量是否超过半数来决定是否可以提交的。
对于任期之前的日志,Raft采用的方式,是只要提交成功了当前任期的日志,那么在日志之前的日志就认为提交成功了。这也是为什么etcd-Raft代码中,在成为leader之后,需要再提交一条dummy的日志的原因–只要该日志提交成功,leader上该日志之前的日志就可以提交成功。
集群成员变更
在上面描述Raft基本算法流程中,都假设集群中的节点是稳定不变的。但是在某些情况下,需要手动改变集群的配置。
安全性
安全性是变更集群成员时首先需要考虑到的问题,任何时候都不能出现集群中存在一个以上leader的情况。为了避免出现这种情况,每次变更成员时不能一次添加或者修改超过一个节点,集群不能直接切换到新的状态,如下图所示。
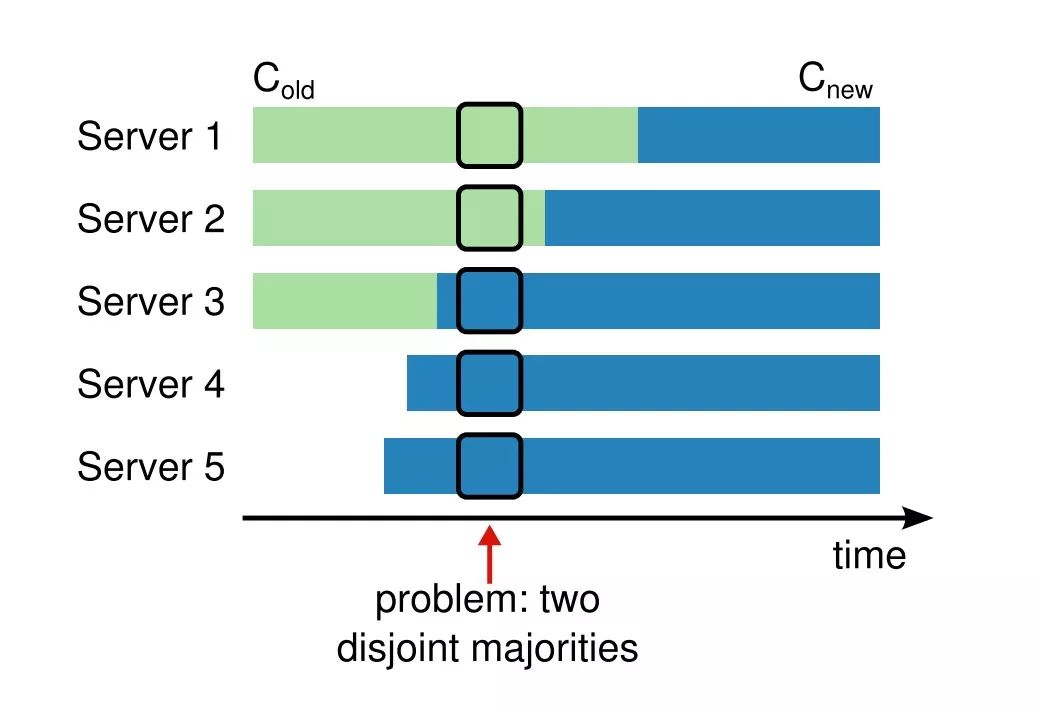
在上图中,server 1、2、3组成的是旧集群,server 4、5是准备新加入集群的节点。注意到如果直接尝试切换到新的状态,在某些时间点里,如图中所示,由于server 1、2上的配置还是旧的集群配置,那么可能这两个节点已经选定了一个leader;而server 3、4、5又是新的配置,它们也可能选定了一个leader,而这两个leader不是同一个,这就出现了集群中存在一个以上leader的情况了。
反之,下图所示是分别往奇数个以及偶数个集群节点中添加删除单个节点的场景。
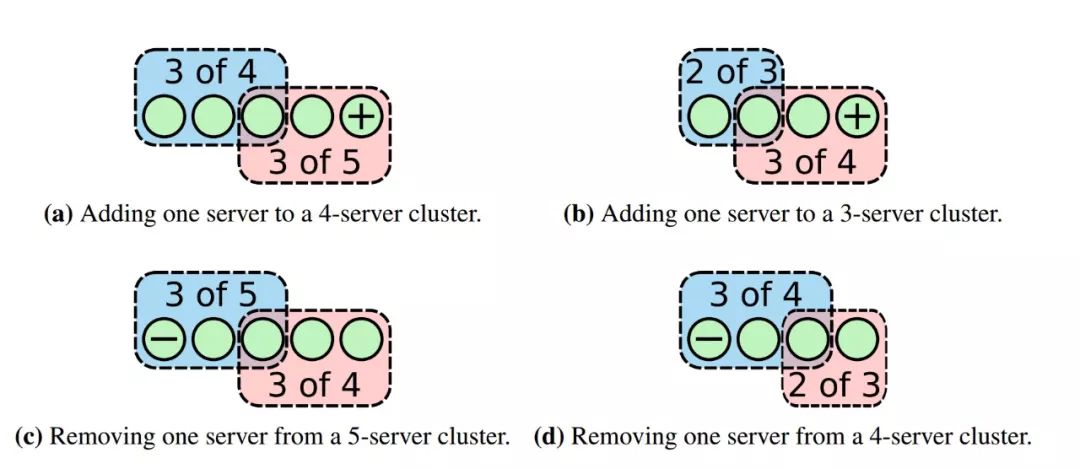
可以看到,不论旧集群节点数量是奇数还是偶数个,都不会出现同时有两个超过半数以上子集群的存在,也就不可能选出超过一个leader。
raft采用将修改集群配置的命令放在日志条目中来处理,这样做的好处是:
可以继续沿用原来的AppendEntries命令来同步日志数据,只要把修改集群的命令做为一种特殊的命令就可以了。
在这个过程中,可以继续处理客户端请求。
可用性
添加新节点到集群中
添加一个新的节点到集群时,需要考虑一种情况,即新节点可能落后当前集群日志很多的情况,在这种情况下集群出现故障的概率会大大提高,如下图所示。
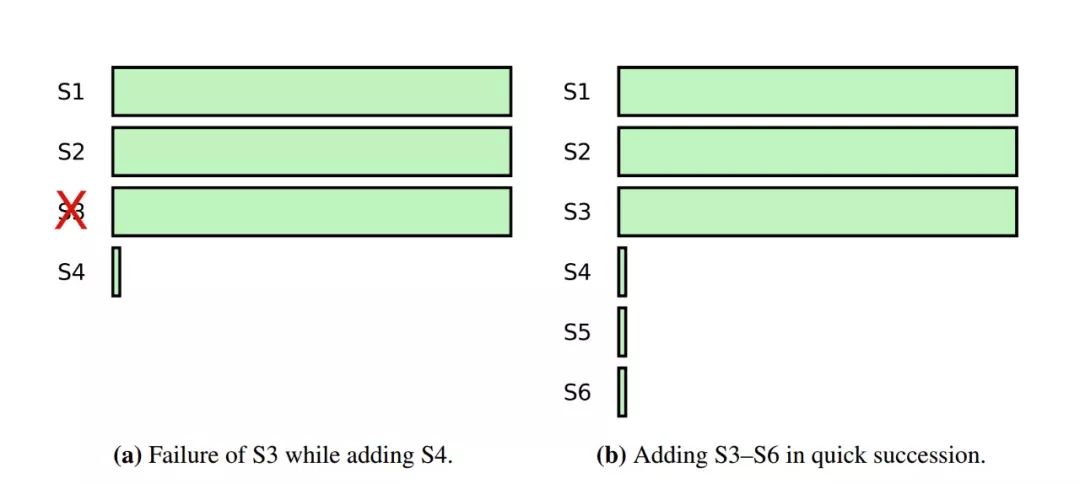
上图中的情况a中,s1、s2、s3是原有的集群节点,这时把节点s4添加进来,而s4上又什么数据都没有。如果此时s3发生故障,在集群中原来有三个节点的情况下,本来可以容忍一个节点的失败的;但是当变成四个节点的集群时,s3和s4同时不可用整个集群就不可用了。
因此Raft算法针对这种新添加进来的节点,是如下处理的。
添加进来的新节点首先将不加入到集群中,而是等待数据追上集群的进度。
leader同步数据给新节点的流程是,划分为多个轮次,每一轮同步一部分数据,而在同步的时候,leader仍然可以写入新的数据,只要等新的轮次到来继续同步就好。
以下图来说明同步数据的流程。
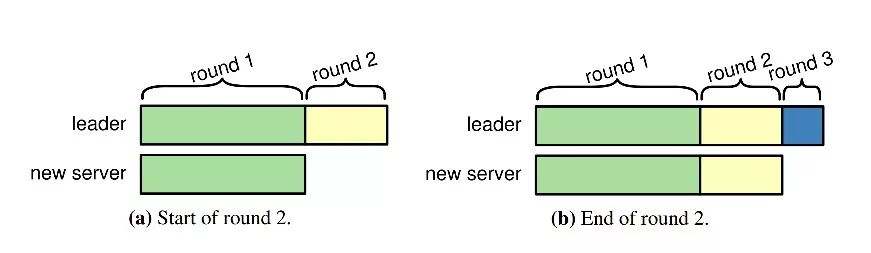
如上图中,划分为多个轮次来同步数据。比如,在第一轮同步数据时,leader的最大数据索引为10,那么第一轮就同步10之前的数据。而在同步第一轮数据的同时,leader还能继续接收新的数据,假设当同步第一轮完毕时,最大数据索引变成了20,那么第二轮将继续同步从10到20的数据。以此类推。
这个同步的轮次并不能一直持续下去,一般会有一个限制的轮次数量,比如最多同步10轮。
删除当前集群的leader节点
当需要下线当前集群的leader节点时,leader节点将发出一个变更节点配置的命令,只有在该命令被提交之后,原先的leader节点才下线,然后集群会自然有一个节点选举超时而进行新的一轮选举。
处理移出集群的节点
如果某个节点在一次配置更新之后,被移出了新的集群,但是这个节点又不知道这个情况,那么按照前面描述的Raft算法流程来说,它应该在选举超时之后,将任期号递增1,发起一次新的选举。虽然最终这个节点不会赢得选举,但是毕竟对集群运行的状态造成了干扰。而且如果这个节点一直不下线,那么上面这个发起新选举的流程就会一直持续下去。
为了解决这个问题,Raft引入了一个成为“PreVote”的流程,在这个流程中,如果一个节点要发起一次新的选举,那么首先会广播给集群中的其它所有节点,询问下当前该节点上的日志是否足以赢下选举。只有在这个PreVote阶段赢得超过半数节点肯定的情况下,才真正发起一次新的选举。
然而,PreVote并不能解决所有的问题,因为很有可能该被移除节点上的日志也是最新的。
由于以上的原因,所以不能完全依靠判断日志的方式来决定是否允许一个节点发起新一轮的选举。
Raft采用了另一种机制。如果leader节点一直保持着与其它节点的心跳消息,那么就认为leader节点是存活的,此时不允许发起一轮新的选举。这样follower节点处理RequestVote请求时,就需要加上判断,除了判断请求进行选举的节点日志是否最新以外,如果当前在一段时间内还收到过来自leader节点的心跳消息,那么也不允许发起新的选举。然而这种情况与前面描述的leader迁移的情况相悖,在leader迁移时是强制要求发起新的选举的,因此RequestVote请求的处理还要加上这种情况的判断。
总结来说,RequestVote请求的处理逻辑大致是这样的。
follower处理RequestVote请求:如果请求节点的日志不是最新的:拒绝该请求,返回如果此时是leader迁移的情况:接收该请求,返回如果最近一段时间还有收到来自leader节点的心跳消息:拒绝该请求,返回接收该请求
日志数据如果不进行压缩处理掉的话,会一直增长下去。为此Raft使用快照数据来进行日志压缩,比如针对键值a的几次操作日志a=1、删除a、a=3最后可以被压缩成为最后的结果数据即a=3。
快照数据和日志数据的组织形式如下图。
在上图中:
未压缩日志前,日志数据保存到了<3,5>的位置,而在<2,3>的位置之前的数据都已经进行提交了,所以可以针对这部分数据进行压缩。
压缩日志之后,快照文件中存放了几个值:压缩时最后一条日志的二元数据是<2,3>,而针对a的几次操作最后的值为a=3,b的值为2。
杂项
高效处理只读请求
前面已经提到过,处理一个命令时,需要经历以下流程:leader向集群中其它节点广播日志,在日志被超过半数节点应答之后,leader提交该日志,最后才应答客户端。这样的流程对于一个只读请求而言太久了,而且还涉及到日志落盘的操作,对于只读请求而言这些操作是不必要的。
但是如果不经过上面的流程,leader节点在收到一个只读请求时就直接将本节点上保存的数据应答客户端,也是不安全的,因为这可能返回已经过期的数据。一方面leader节点可能已经发生了变化,只是这个节点并不知道;另一方面可能数据也发生了改变。返回过期的数据不符合一致性要求,因此这样的做法也是不允许的。
Raft中针对只读请求是这样做处理的。
leader节点需要有当前已提交日志的信息。在前面提到过不能提交前面任期的日志条目,因此一个新leader产生之后,需要提交一条空日志,这样来确保上一个任期内的日志全部提交。
leader节点保存该只读请求到来时的commit日志索引为readIndex,
leader需要确认自己当前还是集群的leader,因为可能会由于有网络分区的原因导致leader已经被隔离出集群而不自知。为了达到这个目的,leader节点将广播一个heartbeat心跳消息给集群中其它节点,当收到半数以上节点的应答时,leader节点知道自己当前还是leader,同时readIndex索引也是当前集群日志提交的最大索引。
链接:https://www.codedump.info/post/20180921-raft/
---------- END ----------
往期精彩:
以上是关于多图详解Raft算法原理的主要内容,如果未能解决你的问题,请参考以下文章