分布式Raft算法
Posted 澳链财经
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式Raft算法相关的知识,希望对你有一定的参考价值。
简介概念
raft是一种用于管理log复制的一致性协议,它和paxos有同样功能,但是比它简单容易理解。功能:leader 选举、日志复制及安全问题。并且提供了强一致性。
原理
这里以3个节点为例每个节点都有三种状态:leader、candidate、follower,每个组有三种行为:leader election、log replication、safety。
1)leader election
当启动三个节点时,都处在candidate状态(raft有时间机制,然后发送vote信息给其他节点),当超过一半时会变成candidate,其他两个节点的状态会变为follower。所有客户端数据的交换都跟leader进行。
2)log replication
log replication保证了数据在组中的一致性。log entry是这个的核心。下图是过程
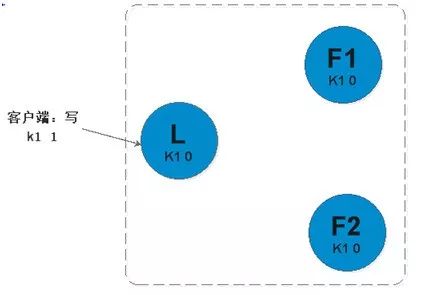
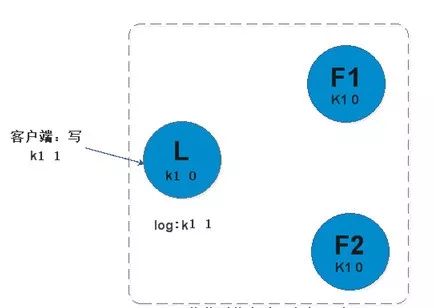
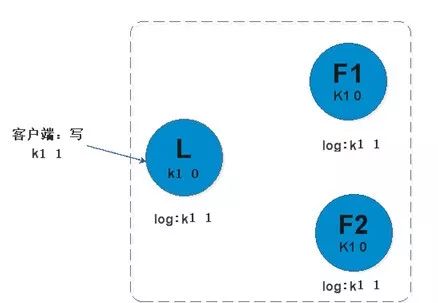
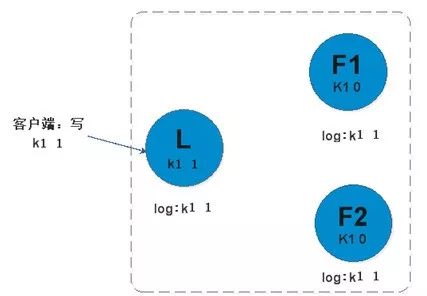
在raft协议中,这里有两个超时时间设置(它控制着选举)
election timeout:它是follower变成candicate时间。一般设置为150ms到300ms
如果选举超时,那么follower变成candicate同时新的一轮选举。首先candicate A会给自己投一票同时会向其他节点发送选我的信息,如果节点还未投票,那它会选A,同时这个节点会重置election timeout。一旦A得到的票数过一半以上,那就成为了leader,同时leader开始向followers发送Append Entries messages的操作,这个发送的时间间隔在heartbeat timeout之内。
followers然后会响应AppendEntries message。选举会继续指导一个followers停止收到heartbeats并变为candidate。
注意:如果在log replication这一过程中,发生了网络分区或者网络通信故障,使得Leader不能访问大多数Follwers了,那么Leader只能正常更新它能访问的那些Follower服务器,而大多数的服务器Follower因为没有了Leader,他们重新选举一个候选者作为Leader,然后这个Leader作为代表与外界打交道,如果外界要求其添加新的日志,这个新的Leader就按上述步骤通知大多数Followers,如果这时网络故障修复了,那么原先的Leader就变成Follower,在失联阶段这个老Leader的任何更新都不能算commit,都回滚,接受新的Leader的新的更新。
声明:来自51CTO博客作者老逗先生。
END

以上是关于分布式Raft算法的主要内容,如果未能解决你的问题,请参考以下文章