Raft算法之日志篇
Posted 程序员升级之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Raft算法之日志篇相关的知识,希望对你有一定的参考价值。
一、日志存储
每条日志存储内容如下:
term:领导人所在任期
应用操作内容:由客户端发送的请求,需要被复制状态机(replicated state machine)执行的命令,如上是一个KV系统,每一次的操作是对某个key的内容。
二、日志状态
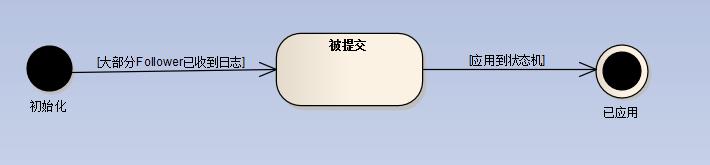
日志大概分以下几个状态:
1、初始化
即刚被加入到系统中
2、被提交
如果一条日志被多数节点收到,则该日志会被转为被提交,即可以被应用到状态机。
3、已应用
即已经应用到状态机了,可以返回给客户端了。
三、与日志相关的消息
1、AppendEntries RPC
这个消息由Leader发出,有2个作用:
A、将客户端发送的命令而产生的日志发送给Follower,从而推进日志达到一致的状态;
B、心跳,表明集群中存在Leader,不用发起选举;
第一个场景是接受客户端命令后发出,并且等大部分Follower接收到才返回给客户端;
第二个场景由Leader定时发出;
相关规则如下:
1、对于Leader
于一个追随者来说,如果上一次收到的日志索引大于将要收到的日志索引(nextIndex):通过AppendEntries RPC将 nextIndex 之后的所有日志条目发送出去
如果发送成功:将该追随者的 nextIndex和matchIndex更新
如果由于日志不一致导致AppendEntries RPC失败:nextIndex递减并且重新发送(5.3 节)
如果存在一个满足N > commitIndex和matchIndex[i] >= N并且log[N].term == currentTerm的 N,则将commitIndex赋值为 N
上面一条规则好理解,以上面的举例来说:
假设节点从上到下分别是A、B、C、D、E,当前Leader是节点A,前面说过Leader针对每一个Follower会记录nextIndex和matchIndex,我们假设最理想的情况,即A针对B记录的nextIndex是9,matchIndex是8,所以心跳消息中的nextIndex是9,B收到消息会检查nextIndex之前的日志是否在本地存在,因6-8的日志不存在,因此返回false,A因此将nextIndex回退至6才匹配上,然后将6-8的日志发送给B,并且将matchIndex和nextIndex也一并更新。
规则2比较难理解:
如果存在一个满足N > commitIndex和matchIndex[i] >= N并且log[N].term == currentTerm的 N,则将commitIndex赋值为 N
重点是加粗的内容,说简单点当前Leader不能直接提交日志的term不为自己的,即不能直接提交前任的日志,举个例子:
这是5个节点的集群,服务器编号分别是 S1-S5,最上面是日志索引,每个框内的数字表示日志的term,最底下的字母表示场景,分别为a-e。
场景a:S1是Leader,term为2,并且将index为2的日志复制到S2上;
场景b:S1挂了,S5当选为Leader,term增长为3,S5在index为2的位置上接收到了新的日志;
场景c:S5挂了,S1当选为Leader,term增长为4,S1将index为2、term为2的日志复制到了S3上,此时已经满足过半数了。
问题就在场景c:此时term为4,之前term为2的日志达到过半数了,S1是提交该日志呢还是不提交?
假如S1提交的话,则index为2、term为2的日志就被应用到状态机中了,就不可撤消了;
此时S1如果挂了,来到场景d,S5是可以被选为leader的,因为按照之前的log比对策略来说,S5的最后一个log的term是3,比S2、S3、S4的最后一个log的term都大。
一旦S5被选举为leader,即场景d,S5会复制index为2、term为3的日志到上述机器上,这时候就会造成之前S1已经提交的index为2的位置被重新覆盖,因此违背了一致性。
假如S1不提交,而是等到term4中有过半的日志了,然后再将之前的term的日志一起提交,即处于e场景,S1此时挂的话,S5就不能被选为leader了,因为S2、S3的最后一个log的term为4,比S5的3大,所以S5获取不到投票,进而S5就不可能去覆盖上述的提交。
总结下:Leader不能直接提交前任的日志,哪怕前任日志已经被多数节点收到了,而是等等当前任期的日志被大多数节点接收后做提交后,间接的提交了前任的日志。
四、其它技术细节
1、AppendEntries RPC消息参数
term:领导人的任期号
leaderId:领导人标识
prevLogIndex:前一条日志索引号
prevLogTerm:前一 条日志任期号
具体要复制的消息
laderCommitIndex:leader的commitIndex
2、Follower收到响应处理过程
首先是term的检查,这块是公共逻辑:
检查对方的term是否比自己小,如果是则返回自己的term,并返回失败 ;
如果自己的term比对方大,则不管当前什么角色变为Follower,并更新term为对方的term,并添加日志;
如果term和自己相等,则只有Follower、Candidate才变为Follower,更新Term,并添加日志,对于Leader应该返回失败。
3、关于日志太大的问题
对于1个7*24小时的服务,如果日志一直追加,最终磁盘空间肯定不够的,有问题恢复也太慢,这就生产了日照的需求,Raft算法大设计的时候就考虑到了这个问题,这个留到后面章节分析。
以上是关于Raft算法之日志篇的主要内容,如果未能解决你的问题,请参考以下文章