烧脑系列:手撕 hashicorp/raft 算法,超长文
Posted Go语言中文网
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了烧脑系列:手撕 hashicorp/raft 算法,超长文相关的知识,希望对你有一定的参考价值。
本文是第 104 期手撕 hashicrop/raft 算法的文字版,建议搭配着视频(本文文末)一起阅读。 编辑:YouEclipse
概览(00:00~01:11)
欢迎收看今天的分享,我是黄威,是一名趣头条的后端工程师.今天跟大家分享的主要是关于 raft 算法的一个工程实践,就是它用 go 语言是怎样实现的,跟大家分享一下.
首先看一下今天大概的内容,主要是 raft 协议的简介,还有选举过程和日志复制过程的简单介绍,然后是官方的动画的演示,再接着就是源码的讲解,就是hashicorp/raft这个库源码的讲解,然后剩下的就是场景的一些调试,到时候我会修改一些 hashicorp/raft 源码,修改一些日志,到时候方便大家 Debug。最后就是 QA,大概今天是这些内容。
Raft 简介(01:12~03:08)
Raft 选举的过程(03:09~05:56)
先来跟大家,简单介绍一下选举的这个过程吧:
首先是以单个节点的视角,就是说,你的一个节点,应该都是这三个角色(follower,canidate,leader)中的一个,并且是在这三个角色中变换。你的集群(节点)起来时应该是一个 follower 的一个状态,然后经过一个 timeout 时间变成 candidate (候选者),然后变成 candidate 以后,你会向其他节点发送投票的请求,如果说你收到一个 majority 或者 quorum 数量的同意投票的请求,那么你就会提升为 leader,这个 majority 或者 quorum 其实就是你节点集群中,大多数节点的数量,比如说你三个结点就是两个节点,四个的话就是三个,五个的话就是就是也是三个,这样子就是取其中大多数节点,如果说同意你的投票请求,那么你就会提升为 leader,然后 leader 会因为一些情况,比如分区啊,或者说联系不上 follower 等,还有一其他的情况,会变成 follower,这个是大概相当于你的那个一个节点,你可能会在这些状态里面来回的切换。
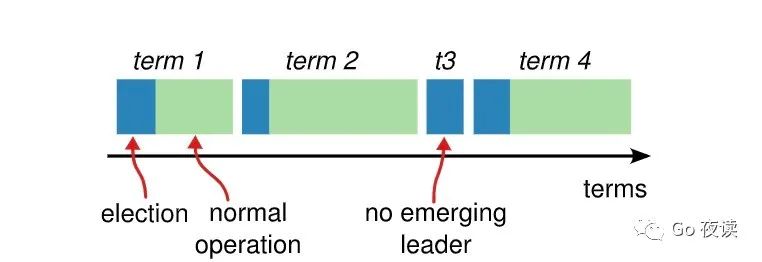
然后对于你整个集群的话,你的集群集的状态就是要么在选举,要么就是在选举完成以后正常提供服务的一个状态,蓝颜色的就是在选举,绿色就是选举完成以后,正常提供服务的状态,比如说你集群刚起来肯定在一个 term1, 选举的一个过程;选举出来以后,它就是正常服务的状态,然后到了 term2,就是可能因为某些原因,然后重新选举了,然后又选举出来,然后又重新选举 term3,term3 这里,可能这个任期没有选举出,经历了一个 timeout 的时间,我们可以看上一张图,当前的 candidate 候选者,在自己当前轮没有收到大多数节点的统一的请求,也没有收到其他 leader 对自己的一些心跳的通知,那么它会进入进入下一轮的选举,就是下面这张图的 term4,然后通过选举完成以后,然后又进入一个正常的一个状态,这个大概就是选举的一个过程。
Raft 日志复制的流程(05:56~09:18)
接下来是关于日志复制的一个流程,也跟大家简单介绍一下,首先讲一下日志的格式。
日志格式
日志格式:term + index + cmd + type
日志的格式的话是有任期,索引还有数据,cmd,还有就是 type.这里可以给大家直接看下数据结构:
hashicorp/raft/log.go
// Log entries are replicated to all members of the Raft cluster
// and form the heart of the replicated state machine.
type Log struct {
// Index holds the index of the log entry.
Index uint64
// Term holds the election term of the log entry.
Term uint64
// Type holds the type of the log entry.
Type LogType
// Data holds the log entry's type-specific data.
Data []byte
// Extensions holds an opaque byte slice of information for middleware. It
// is up to the client of the library to properly modify this as it adds
// layers and remove those layers when appropriate. This value is a part of
// the log, so very large values could cause timing issues.
//
// N.B. It is _up to the client_ to handle upgrade paths. For instance if
// using this with go-raftchunking, the client should ensure that all Raft
// peers are using a version that can handle that extension before ever
// actually triggering chunking behavior. It is sometimes sufficient to
// ensure that non-leaders are upgraded first, then the current leader is
// upgraded, but a leader changeover during this process could lead to
// trouble, so gating extension behavior via some flag in the client
// program is also a good idea.
Extensions []byte
}
你看它的定义的数据结构,其实也是一样,有 index,term,type,data,下面是扩展信息不用管。定义的这些字段上保存 log。
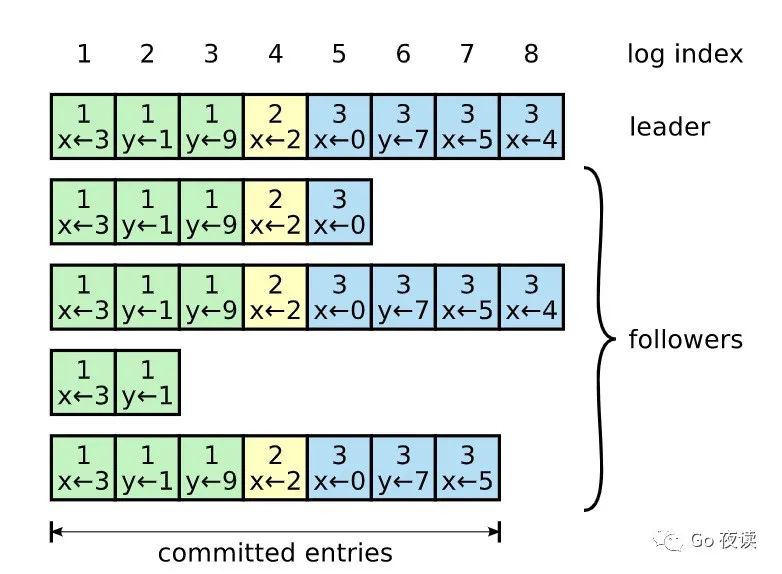
这张图上面一排是索引,索引的位置第一个位置,第二个位置,然后到一直到 100 多,下面的框里面这个数字,中间的这个数字是代表任期,比如这个第一个任期,第二个任期,第三个任期, X 等于 3,相当于是数据,就是这个论文里面,它其实是以 KV 服务来举例的,那他保存的肯定是一些 kv 的一些命令。这个就是 X 等于 3,y 等于 1, X 等于 2,第 2 个任期提交,以 4 这个位置提交的 x 等于 2,在位置 8 这个位置提交的 X=4...
这大概是一个日志的格式,并且就是说,如果说日志复制到了大多数的节点上,那么他就会提交,所以这里面这张图的话,他 1 到 4 这边 1 到 7 这个位置就是,被提交了的。
请求处理整体流程
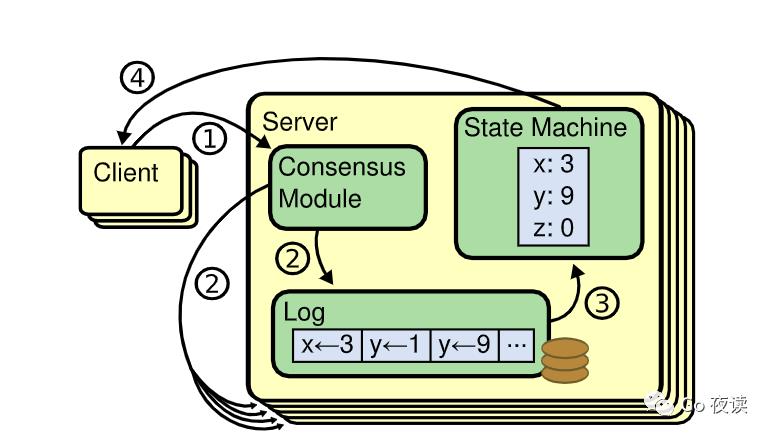
然后就是提交整体的处理流程。比如你一个客户端发送一个发送请求,发送到 leader 的服务器,然后会通过你编写的一个 raft 的模块,跟底层的 raft 的库进行交互,你先把日志存起来,然后在并行的发送给其他的节点。如果你收到大多数的成功的响应,那么你肯定就可以提交这个日志。第三步会写到状态机,然后第四步就返回给客户端,就是大于大致的一个流程.
请求处理详细流程(重点)
下面是一个详细的流程,到时候后面我们也会根据这个图来 Debug
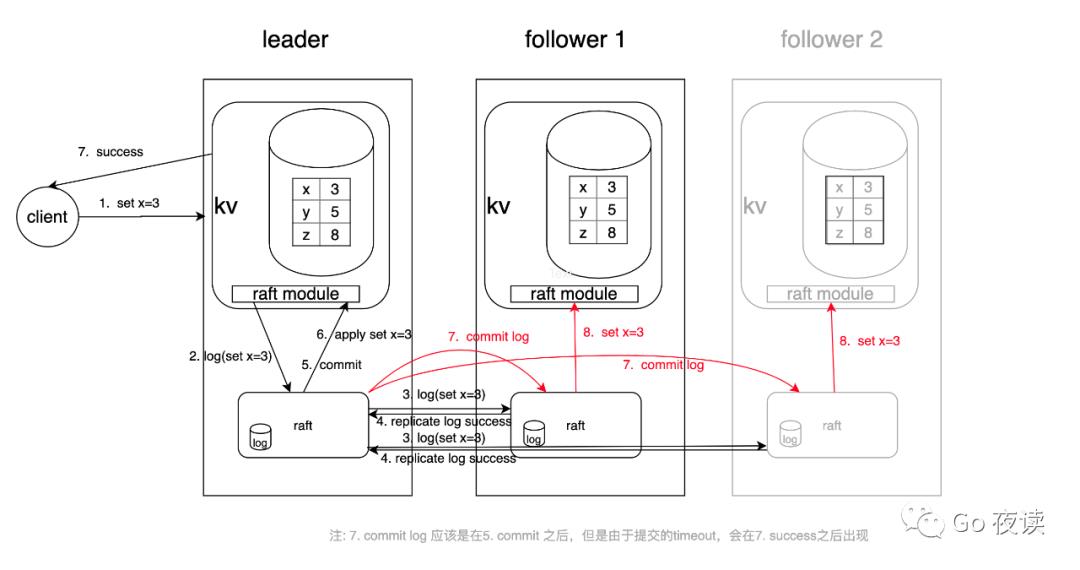
我会把这里面每一步执行的日志都会打印出来,并且会带着大家分析一下,就是打印日志每一步的上下文,这样的话大家就可以更实际地理解 raft 的实现,会有更直观的一个认识,这个图我后面再反过来跟大家讲一下。
Raft 协议动画演示(09:19~12:40)
选举和日志复制的流程的话,跟大家简单的过了一下。
这里有有两个官方的动画的演示(link1 http://thesecretlivesofdata.com/raft,link2 https://raft.github.io/#implementations),第一个图就不跟大家演示了,就直接看第二个吧。它是模拟 raft 集群的实时的状态,比如说你的集群刚起来,现在都是橘黄色,都是一个 follower 的状态。然后让他继续运行,你看它这个圈就是外层的灰色的线,它是代表一个选举超时,就是 election timeout,所以说如果 follower 没有收到 leader 的请求的话,那么他就会经历一个 timeout 自动的提升为 candidate,然后就会发送投票请求,如果说收到了大多数节点的同意的响应,那么它就会成为 leader。哪个先到 candidate 就会发送投票请求,肯定只会有一个收到大多数的节点的投票的请求,肯定不会有两个的。现在这个 S5 这个服务器变成了 leader,然后他就一直保持心跳,发送心跳的信息。我们先来给他发送一个请求,他会先写到自己的日志,然后我们再让他执行,会被发送到其他的的节点。其他的节点复制完成以后,他就可以返回给客户端请求处理成功。应该是提交信息以后。S5 第二个任期这里,现在就变成实线了,那说明他提交了,接着,它就会发送提交的信息给其它的节点,那其他节点也提交了.
我们再来看一下这个过程: 你自己复制给,其他所有的也复制,然后就自己提交,然后在其他的也提交;如果说我们把它宕掉,会发生什么呢?然后没有心跳,其他收不到,然后就会自动触发选举的流程。然后就会选举出一个新的 leader,现在是 S3,然后我们给他一个请求,也是一样的,但是现在 s2 收不到日志的,日志是落后的,但是没关系,我们把它恢复起来,然后他就会很快就会赶上来。
这个大概就是一个 raft 的选举和复制日志的一个流程动画演示。大家有兴趣啊,到时候也可以自己去看一下。
完整讲解 hashicorp/raft(12:40~28:18)
初始化
我们先从这个 main 函数里面开始吧,先看一下这个服务是怎样启动起来的,然后我们在进入 raft 的源码去看一下。
vision9527/raft-demo/main.go
func main() {
flag.Parse()
// 初始化配置
if httpAddr == "" || raftAddr == "" || raftId == "" || raftCluster == "" {
fmt.Println("config error")
os.Exit(1)
return
}
raftDir := "node/raft_" + raftId
os.MkdirAll(raftDir, 0700)
// 初始化raft
myRaft, fm, err := myraft.NewMyRaft(raftAddr, raftId, raftDir)
if err != nil {
fmt.Println("NewMyRaft error ", err)
os.Exit(1)
return
}
// 启动raft
myraft.Bootstrap(myRaft, raftId, raftAddr, raftCluster)
// 监听leader变化 (其实这个的话在实际的工程工作实际的开发中,其实应该是不常用的这里面。为了演示简单,然后用了一下)
go func() {
for leader := range myRaft.LeaderCh() {
isLeader = leader
}
}()
// 启动http server
httpServer := HttpServer{
ctx: myRaft,
fsm: fm,
}
http.HandleFunc("/set", httpServer.Set)
http.HandleFunc("/get", httpServer.Get)
http.ListenAndServe(httpAddr, nil)
// 关闭raft
shutdownFuture := myRaft.Shutdown()
if err := shutdownFuture.Error(); err != nil {
fmt.Printf("shutdown raft error:%v \n", err)
}
// 退出http server
fmt.Println("shutdown kv http server")
}
初始化一些,配置也是从命令行参数读取,然后第二个就是初始化 raft,里面就是一些 raft 初始化的信息。这个就是启动 raft,然后这个就是进行一点点变化,其实这个的话在实际的工程工作实际的开发中,其实应该是不常用的这里面。为了演示简单,然后用了一下。接着就是其中一个 httpserv,他到这里会阻塞。这里是两个 handler,一个是 set,一个是 get,set 是直接执行命令的一个入口,get 就是简单的一个 get.下面就是关闭了。正常的话应该是到这里阻塞住,如果说我也退出了,他会继续往下.
我们现在主要就是看这两部分(myraft.NewMyRaft 和 myraft.Bootstrap):
vision9527/raft-demo/myraft/my_raft.go
func NewMyRaft(raftAddr, raftId, raftDir string) (*raft.Raft, *fsm.Fsm, error) {
config := raft.DefaultConfig()
config.LocalID = raft.ServerID(raftId)
// config.HeartbeatTimeout = 1000 * time.Millisecond
// config.ElectionTimeout = 1000 * time.Millisecond
// config.CommitTimeout = 1000 * time.Millisecond
addr, err := net.ResolveTCPAddr("tcp", raftAddr)
if err != nil {
return nil, nil, err
}
transport, err := raft.NewTCPTransport(raftAddr, addr, 2, 5*time.Second, os.Stderr)
if err != nil {
return nil, nil, err
}
snapshots, err := raft.NewFileSnapshotStore(raftDir, 2, os.Stderr)
if err != nil {
return nil, nil, err
}
logStore, err := raftboltdb.NewBoltStore(filepath.Join(raftDir, "raft-log.db"))
if err != nil {
return nil, nil, err
}
stableStore, err := raftboltdb.NewBoltStore(filepath.Join(raftDir, "raft-stable.db"))
if err != nil {
return nil, nil, err
}
fm := new(fsm.Fsm)
fm.Data = make(map[string]string)
rf, err := raft.NewRaft(config, fm, logStore, stableStore, snapshots, transport)
if err != nil {
return nil, nil, err
}
return rf, fm, nil
}
hashicorp/raft/api.go
// NewRaft is used to construct a new Raft node. It takes a configuration, as well
// as implementations of various interfaces that are required. If we have any
// old state, such as snapshots, logs, peers, etc, all those will be restored
// when creating the Raft node.
func NewRaft(conf *Config, fsm FSM, logs LogStore, stable StableStore, snaps SnapshotStore, trans Transport) (*Raft, error) {
// Validate the configuration.
if err := ValidateConfig(conf); err != nil {
return nil, err
}
// Ensure we have a LogOutput.
var logger hclog.Logger
if conf.Logger != nil {
logger = conf.Logger
} else {
if conf.LogOutput == nil {
conf.LogOutput = os.Stderr
}
logger = hclog.New(&hclog.LoggerOptions{
Name: "raft",
Level: hclog.LevelFromString(conf.LogLevel),
Output: conf.LogOutput,
})
}
// Try to restore the current term.
currentTerm, err := stable.GetUint64(keyCurrentTerm)
if err != nil && err.Error() != "not found" {
return nil, fmt.Errorf("failed to load current term: %v", err)
}
// Read the index of the last log entry.
lastIndex, err := logs.LastIndex()
if err != nil {
return nil, fmt.Errorf("failed to find last log: %v", err)
}
// Get the last log entry.
var lastLog Log
if lastIndex > 0 {
if err = logs.GetLog(lastIndex, &lastLog); err != nil {
return nil, fmt.Errorf("failed to get last log at index %d: %v", lastIndex, err)
}
}
// Make sure we have a valid server address and ID.
protocolVersion := conf.ProtocolVersion
localAddr := ServerAddress(trans.LocalAddr())
localID := conf.LocalID
// TODO (slackpad) - When we deprecate protocol version 2, remove this
// along with the AddPeer() and RemovePeer() APIs.
if protocolVersion < 3 && string(localID) != string(localAddr) {
return nil, fmt.Errorf("when running with ProtocolVersion < 3, LocalID must be set to the network address")
}
// Create Raft struct.
r := &Raft{
protocolVersion: protocolVersion,
applyCh: make(chan *logFuture),
conf: *conf,
fsm: fsm,
fsmMutateCh: make(chan interface{}, 128),
fsmSnapshotCh: make(chan *reqSnapshotFuture),
leaderCh: make(chan bool, 1),
localID: localID,
localAddr: localAddr,
logger: logger,
logs: logs,
configurationChangeCh: make(chan *configurationChangeFuture),
configurations: configurations{},
rpcCh: trans.Consumer(),
snapshots: snaps,
userSnapshotCh: make(chan *userSnapshotFuture),
userRestoreCh: make(chan *userRestoreFuture),
shutdownCh: make(chan struct{}),
stable: stable,
trans: trans,
verifyCh: make(chan *verifyFuture, 64),
configurationsCh: make(chan *configurationsFuture, 8),
bootstrapCh: make(chan *bootstrapFuture),
observers: make(map[uint64]*Observer),
leadershipTransferCh: make(chan *leadershipTransferFuture, 1),
}
// Initialize as a follower.
r.setState(Follower)
// Restore the current term and the last log.
r.setCurrentTerm(currentTerm)
r.setLastLog(lastLog.Index, lastLog.Term)
// Attempt to restore a snapshot if there are any.
if err := r.restoreSnapshot(); err != nil {
return nil, err
}
// Scan through the log for any configuration change entries.
snapshotIndex, _ := r.getLastSnapshot()
for index := snapshotIndex + 1; index <= lastLog.Index; index++ {
var entry Log
if err := r.logs.GetLog(index, &entry); err != nil {
r.logger.Error("failed to get log", "index", index, "error", err)
panic(err)
}
r.processConfigurationLogEntry(&entry)
}
r.logger.Info("initial configuration",
"index", r.configurations.latestIndex,
"servers", hclog.Fmt("%+v", r.configurations.latest.Servers))
// Setup a heartbeat fast-path to avoid head-of-line
// blocking where possible. It MUST be safe for this
// to be called concurrently with a blocking RPC.
trans.SetHeartbeatHandler(r.processHeartbeat)
if conf.skipStartup {
return r, nil
}
// Start the background work.
r.goFunc(r.run)
r.goFunc(r.runFSM)
r.goFunc(r.runSnapshots)
return r, nil
}
它的启动流程的话就是先校验一下配置,然后 log 的初始化,然后是获取当前的任期,这个任期的话必须得持久化。大家可以看一下这个论文里面这张图。

这张图的话应该说是描述的就是整个 raft 的算法,就是你的数据结构要怎么样设置?然后有那些 RPC 的方法,就是投票和复制日志的 RPC 方法,你应该实现什么样的逻辑啊,在这里都有。这个(state)呢,比如说你要持久化的话,他肯定会持久化当前的任期,还有投票,这里就会取出来。这个(logs.LastIndex())是获取最新日志的索引,接着就是构造 raft 的实例。这个(r.setState(Follower))是设置角色,就是你的集群起来,肯定都是以 follower 的角色起来。这里(setCurrentTerm)设置当前任期,这个(restoreSnapshot)是从快照里面恢复一些数据。这个(processConfigurationLogEntry)是对日志里面一些配置类型的 log 进行处理。然后这里有个 SetHeartbeatHandler的 handler,这里是这样的,正常的话你的 heartbeat 应该是跟 AppendEntries RPC 是同一个 handler,但是一个问题就是说,如果说你的前面一个 AppendEntry 执行很久,然后后面 heartbeat 如果发送请求的话,可能会阻塞,所以就没有达到 heartbeat 或者 ping 的这个效果,就会有问题,所以它是单独初始化了一个 handler,然后,但是呢,他的逻辑是跟这个(AppendEntry)一样的,他们用的都是同一个方法,这个大家可以注意一下.下面就是这,里面就是 raft 算法的核心实现了。
raft 的监听事件
hashicorp/raft/raft.go
// run is a long running goroutine that runs the Raft FSM.
func (r *Raft) run() {
for {
// Check if we are doing a shutdown
select {
case <-r.shutdownCh:
// Clear the leader to prevent forwarding
r.setLeader("")
return
default:
}
// Enter into a sub-FSM
switch r.getState() {
case Follower:
r.runFollower()
case Candidate:
r.runCandidate()
case Leader:
r.runLeader()
}
}
}
我们接下来进入就是讲 raft 的监听事件,到时候如果大家看这个库的话,肯定也是以这里为入口,这里就开始 raft 的逻辑了,这是 follower 的逻辑和 candidate 的逻辑,还有 leader 的逻辑,其实比较清晰了。
我们先看 runFollower 吧,其中一个都会监听一些 channel,然后执行执行一些逻辑,
// runFollower runs the FSM for a follower.
func (r *Raft) runFollower() {
didWarn := false
r.logger.Info("entering follower state", "follower", r, "leader", r.Leader())
metrics.IncrCounter([]string{"raft", "state", "follower"}, 1)
heartbeatTimer := randomTimeout(r.conf.HeartbeatTimeout)
for r.getState() == Follower {
select {
case rpc := <-r.rpcCh:
r.processRPC(rpc)
case c := <-r.configurationChangeCh:
// Reject any operations since we are not the leader
c.respond(ErrNotLeader)
case a := <-r.applyCh:
// Reject any operations since we are not the leader
a.respond(ErrNotLeader)
case v := <-r.verifyCh:
// Reject any operations since we are not the leader
v.respond(ErrNotLeader)
case r := <-r.userRestoreCh:
// Reject any restores since we are not the leader
r.respond(ErrNotLeader)
case r := <-r.leadershipTransferCh:
// Reject any operations since we are not the leader
r.respond(ErrNotLeader)
case c := <-r.configurationsCh:
c.configurations = r.configurations.Clone()
c.respond(nil)
case b := <-r.bootstrapCh:
b.respond(r.liveBootstrap(b.configuration))
case <-heartbeatTimer:
// Restart the heartbeat timer
heartbeatTimer = randomTimeout(r.conf.HeartbeatTimeout)
// Check if we have had a successful contact
lastContact := r.LastContact()
if time.Now().Sub(lastContact) < r.conf.HeartbeatTimeout {
continue
}
// Heartbeat failed! Transition to the candidate state
lastLeader := r.Leader()
r.setLeader("")
if r.configurations.latestIndex == 0 {
if !didWarn {
r.logger.Warn("no known peers, aborting election")
didWarn = true
}
} else if r.configurations.latestIndex == r.configurations.committedIndex &&
!hasVote(r.configurations.latest, r.localID) {
if !didWarn {
r.logger.Warn("not part of stable configuration, aborting election")
didWarn = true
}
} else {
r.logger.Warn("heartbeat timeout reached, starting election", "last-leader", lastLeader)
metrics.IncrCounter([]string{"raft", "transition", "heartbeat_timeout"}, 1)
r.setState(Candidate)
return
}
case <-r.shutdownCh:
return
}
}
}
对于 follower 来说,其实最重要的两个其实就是 AppendEntries RPC 和投票请求(processRPC)。
还有一个监听的重要 channel,就是这个 heartbeatTimer,就是说说你的集群起来以后应该有一个 timeout 的时间,这个就是一个 channel,经过 timeout,它会发送一个通知。当你 check,如果说没 checkt 没过的话,他会去继续执行到下面,然后执行到这儿(r.setState(Candidate))变成一个 candidate,然后 return 退出这个函数,然后我们再回到这里,你看他就是 return 出来的。下次他进来就是 candidate。
candidate 里面有什么东西呢,其实也很简单,就是投票的一些信息,可以去看一下。
// runCandidate runs the FSM for a candidate.
func (r *Raft) runCandidate() {
r.logger.Info("entering candidate state", "node", r, "term", r.getCurrentTerm()+1)
metrics.IncrCounter([]string{"raft", "state", "candidate"}, 1)
// Start vote for us, and set a timeout
voteCh := r.electSelf()
// Make sure the leadership transfer flag is reset after each run. Having this
// flag will set the field LeadershipTransfer in a RequestVoteRequst to true,
// which will make other servers vote even though they have a leader already.
// It is important to reset that flag, because this priviledge could be abused
// otherwise.
defer func() { r.candidateFromLeadershipTransfer = false }()
electionTimer := randomTimeout(r.conf.ElectionTimeout)
// Tally the votes, need a simple majority
grantedVotes := 0
votesNeeded := r.quorumSize()
r.logger.Debug("votes", "needed", votesNeeded)
for r.getState() == Candidate {
select {
case rpc := <-r.rpcCh:
r.processRPC(rpc)
case vote := <-voteCh:
// Check if the term is greater than ours, bail
if vote.Term > r.getCurrentTerm() {
r.logger.Debug("newer term discovered, fallback to follower")
r.setState(Follower)
r.setCurrentTerm(vote.Term)
return
}
// Check if the vote is granted
if vote.Granted {
grantedVotes++
r.logger.Debug("vote granted", "from", vote.voterID, "term", vote.Term, "tally", grantedVotes)
}
// Check if we've become the leader
if grantedVotes >= votesNeeded {
r.logger.Info("election won", "tally", grantedVotes)
r.setState(Leader)
r.setLeader(r.localAddr)
return
}
case c := <-r.configurationChangeCh:
// Reject any operations since we are not the leader
c.respond(ErrNotLeader)
case a := <-r.applyCh:
// Reject any operations since we are not the leader
a.respond(ErrNotLeader)
case v := <-r.verifyCh:
// Reject any operations since we are not the leader
v.respond(ErrNotLeader)
case r := <-r.userRestoreCh:
// Reject any restores since we are not the leader
r.respond(ErrNotLeader)
case r := <-r.leadershipTransferCh:
// Reject any operations since we are not the leader
r.respond(ErrNotLeader)
case c := <-r.configurationsCh:
c.configurations = r.configurations.Clone()
c.respond(nil)
case b := <-r.bootstrapCh:
b.respond(ErrCantBootstrap)
case <-electionTimer:
// Election failed! Restart the election. We simply return,
// which will kick us back into runCandidate
r.logger.Warn("Election timeout reached, restarting election")
return
case <-r.shutdownCh:
return
}
}
}
先给自己投票(electSelf),然后并行地发送给大家,就是遍历一下当时有哪些服务器,除了自己以外,然后都发出一个,然后返回一个 chanel(voteCh),随时监听这个投票请求的结果。它也需要监听 RPC,因为它也是会收到复制日志的请求,投票的请求,会做相应的处理,并且它主要的工作就是监听这个投票的结果。如果说他的他投票结果,如果说有一个同意了,那么他就会+1,直到他大于等于他的法定人数,或者说 majority 人数的数量,它就会变成 leader,之后就会 return,下次进来他就会进入 leader 的角色。还有一个重要的 channel,就是 electionTimeout,直接 return,进入新一轮选举,还是 candidate,进入新一轮的选举,直到选成了 leader 以后。
然后进入 leader 的逻辑,其实 raft 算法里面核心的逻辑肯定都在 leader。
// runLeader runs the FSM for a leader. Do the setup here and drop into
// the leaderLoop for the hot loop.
func (r *Raft) runLeader() {
r.logger.Info("entering leader state", "leader", r)
metrics.IncrCounter([]string{"raft", "state", "leader"}, 1)
// Notify that we are the leader
overrideNotifyBool(r.leaderCh, true)
// Push to the notify channel if given
if notify := r.conf.NotifyCh; notify != nil {
select {
case notify <- true:
case <-r.shutdownCh:
}
}
// setup leader state. This is only supposed to be accessed within the
// leaderloop.
r.setupLeaderState()
// Cleanup state on step down
defer func() {
// Since we were the leader previously, we update our
// last contact time when we step down, so that we are not
// reporting a last contact time from before we were the
// leader. Otherwise, to a client it would seem our data
// is extremely stale.
r.setLastContact()
// Stop replication
for _, p := range r.leaderState.replState {
close(p.stopCh)
}
// Respond to all inflight operations
for e := r.leaderState.inflight.Front(); e != nil; e = e.Next() {
e.Value.(*logFuture).respond(ErrLeadershipLost)
}
// Respond to any pending verify requests
for future := range r.leaderState.notify {
future.respond(ErrLeadershipLost)
}
// Clear all the state
r.leaderState.commitCh = nil
r.leaderState.commitment = nil
r.leaderState.inflight = nil
r.leaderState.replState = nil
r.leaderState.notify = nil
r.leaderState.stepDown = nil
// If we are stepping down for some reason, no known leader.
// We may have stepped down due to an RPC call, which would
// provide the leader, so we cannot always blank this out.
r.leaderLock.Lock()
if r.leader == r.localAddr {
r.leader = ""
}
r.leaderLock.Unlock()
// Notify that we are not the leader
overrideNotifyBool(r.leaderCh, false)
// Push to the notify channel if given
if notify := r.conf.NotifyCh; notify != nil {
select {
case notify <- false:
case <-r.shutdownCh:
// On shutdown, make a best effort but do not block
select {
case notify <- false:
default:
}
}
}
}()
// Start a replication routine for each peer
r.startStopReplication()
// Dispatch a no-op log entry first. This gets this leader up to the latest
// possible commit index, even in the absence of client commands. This used
// to append a configuration entry instead of a noop. However, that permits
// an unbounded number of uncommitted configurations in the log. We now
// maintain that there exists at most one uncommitted configuration entry in
// any log, so we have to do proper no-ops here.
noop := &logFuture{
log: Log{
Type: LogNoop,
},
}
r.dispatchLogs([]*logFuture{noop})
// Sit in the leader loop until we step down
r.leaderLoop()
}
这个(setupLeaderState)是初始化一些 leader 的配置,然后接着就是 leader 起来起来以后,(startStopReplication)会给其他其他的每一个节点,启动一个复制的线程,就是说如果有日志复制的消息的话,会发给这些线程,会去执行发送的逻辑。这里面就是启动一个 goroutine,就是异步地启动,然后 replicate 就是整个复制的逻辑就,到时候我们也会详细的讲一下这个方法.
这个(noop)可以单独跟大家说一下,就是这个,每一个 leader 刚开始选举成功以后都会发生一个 noop 的日志,具体大家可以看一下,这个就是日志其实有很多类型,就是用应用程序需要用到一些命令,这个是一个可以操作的日志,他有什么用呢?(下面还有一些其他的日志的类型)它的作用就是其实主要是提交前面任期的 leader 没有提交的日志,这个在论文里面有有提到过。
接下来就是进入 leader 的,它的监听的一些事件,它就监听的稍微多一点, 首先他肯定也是可以监听 RPC 的(processRPC),可以接受投票,复制日志的,但是他只能接受比自己任期大的,接受以后他并不会真正的复制,他会退回到 follower 的状态.后面就是一个重要的是 commitCh,如果说有些提交的消息,会被发送到这个 channel 里,他会监听到,执行 commit 的逻辑,后面就是一个比较重要的是,就是 applyCh,客户端发送的请求会被打包成日志放到这里面来。然后他会做一个 dispatch,就是分发给其他的,刚才我们不是启动了很多复制的线程嘛,这里的话就是分发给那些其他节点。还有一个就是 lease,他会定期的检查,如果说还是没有得到大多数节点的投票,他就会退回到 follower,逻辑都比较清晰,你是哪个角色都会有相应的逻辑进行执行。
源码讲解的话,后面会根据调试的场景会再次讲解,大致启动的流程和逻辑就是这些。比如说你 New 一个 Raft 以后,刚才的逻辑已经加载进来了,但是因为他们互相之间还连不上,所以会进入这其中一段 Bootstrap,刚才我们把这个集群的信息都加载进来,它就会生成一条配置信息,然后用这个信息来启动集群,启动完成以后。然后就自动地选举出 leader,然后对外提供服务。
调试日志(28:30~58:40)
这个是 raft 的源码的讲解,那么接下来就是第二个重点,就是我们今天调试的一些场景,需要跟大家手把手地调试日志. 先编译,编译完以后,再启动,启动的话先看一下这个命令行,
./raft-demo --http_addr=127.0.0.1:7001 --raft_addr=127.0.0.1:7000 --raft_id=1 --raft_cluster=1/127.0.0.1:7000,2/127.0.0.1:8000,3/127.0.0.1:9000
调试场景(28:22~)
选举变化相关(28:22~38:38)
这里的话,我把每个场景都有一个分支都单独的切出来,到时候大家可以看一下.
先看启动场景:
集群启动后,follower 等待一个随机 election timeout 时间变成 candidate,然后发起投票,如果不能获得 majority 票数,则任期 term 会一直增加(未 pre-vote 情况)(branch: election-1)
启动以后,他会发起投票,经历了一个那个 election_timeout 的时间,然后就会到 candidate 的状态,比如说在源码里面的话,他刚开始起来是一个 follower,监听这些 channel,然后都其他 chanel 都没有消息,然后只有这个 heartbeatTimeout,会发送一个消息,他会进行 check,如果没有 leader 对他进行 heartbeat,他就会变成 candidate,然后就会触发新一轮的选举,进入 candidate 的状态,他需要两个投票才行,现在总共才只有一个。因为他根本就联系不上其他两个节点 2 和节点 3,然后就一直这样,26,27(任期),当然之前我也运行过,正常的话它是从 123456, 任期一直增加.当然这是在没有 B 投票的情况,投票其实是对这个产品的一个优化,就是说避免就这个任期一直增加,大概实现的思路就是你要联系上其他的节点,而且你要联系上,然后是能够 ping 到,然后你才会进行投票,大概是这样的一个逻辑啊,大家可以,自己去了解一下。
第二个场景,第二个场景是获得的 majority 的投票.
集群启动后,follower 等待一个随机 election timeout 时间变成 candidate,然后发起投票,获得 majority 票数的节点变成 leader (branch: election-2)
我们运行一下,你看他现在还是联系不上,我们现在再启动一个(节点),那集群里就有两个了,我们看发送投票请求,只有 3 失败了,之前 2 和 3 都失败了,就说明 2 是成功了的,正好这里的日志也印证了,比如说他现在是需要两个,然后他收到了两个,它就会进入 leader 状态,就是说他收到了大多数节点的投票,就会变成 leader。那我们看一下相关的这个逻辑。它是 follower,然后 timeout,然后就会变成 candidate,然后他会发送投票的请求,在这里(runCandidate)就会一直比较,如果说大于等于法定人数的话,那么它就会变成 leader,然后就退出,退出以后,就会执行 leader 的逻辑。
我们看第三个场景。
leader 选举成功后发送 heartbeat 保持 leader 的地位(branch: election-3)
我们把原来 raft 的数据清理一下,启动一个节点,两个节点,我马上给您起来吧。现在 leader 就是上面这个节点,选举成功以后,它会不停的给其他两个节点发送心跳的请求,leader 会给 2,3 发送心跳的信息,保持 leader 地位,其他的节点就不会触发选举。
第四个场景
leader 失去 majority 节点的 heartbeat 响应,退回到 follower(branch: election-4)
这是正常的 heartbeat 的,然后我们两个都停掉,最开始也是很正常的收到请求,后面就是一长串收不到了。失败了嘛,就降级成 follower 的状态,然后又没有其他的 leader 给他发送心跳的信息,然后就会进入 candidate 的状态。然后又发送投票信息,当然现在肯定都是失败的,然后就任期就一直增加,不停的发送投票,我看一下他是从降级的,我们直接看日志吧,到时候大家也可以像我一样看把日志打印出来,这里这样子的,他如果说比如说他联系上的是少于 quorum 的话就会变成 folowwer,我们看一下这个是哪里调用 checkleaderlease 函数的,就是刚才就是 leaderLoop 里面的 lease Channel,它会定时的去检测,如果联系上就没关系,如果联系不上的话就会降级。
这个是四个关于选举的场景,当然可能没有列举完啊,但是我觉得主要的场景其实也就是这些,大家如果根据这些打印的日志的上下文去搜一下打印日志的内容,会有更深的一些理解。
日志复制(38:38~)
后面下面就进入到我们,我们的最重要部分的日志复制。那现在就是回过回过来讲一下这个图,看一下我们详细的处理客户端请求的逻辑是什么样的
,首先看到这个图,第一步是客户端发送一个请求,发送一个命令给 leader,第二步他的服务层收到以后处理成相关的需要保存的日志数据,然后通过一致性模块,就是 raft replication 一致性模块,第三步就是并行的发送给其他的 follower,有大多数的节点,这里把它置灰了,比如说他宕机掉了,或者说他比较慢,都可以不用管它,只要有一个节点复制成功了,那么他就可以申请第五步提交,提交以后然后会执行到状态机,因为我们执行的状态机,然后都会执行完以后,然后就返回给客户端成功,然后接着就是异步地把提交的信息发送给 follower, 然后 folower 把这个命令到到状态机里面去执行。然后因为你的状态以及初始状态是一致的,然后执行作业命令也是一致的,那么到这一步呢,所以这一刻的状态机的状态肯定都是一致的,都是 358,对吧。那么你集群里面所有节点的数据都就就都保持一致。这里要注意的是就是 7,这个正常来说应该是在 5 之后,就可以把这个信息发送给其他的节点。但是由于就是我们,commit 的策略吧,它是固定一定的时间间隔,把这个提交的信息发送给其他的其他节点,所以从日志上看起来的话,会是像是在返回给客户端以后,到时候我会打印,然后大家也会看到是这样。
(第一个场景)
leader 接收客户端请求,向集群内所有节点发送复制 RPC,所有都正常响应 -> 正常 commit,然后 apply 到状态机,最后返回客户端处理成功(branch: replicate-log-1)
我先模拟客户端,发送一个请求,然后在相应的每一步都打印出来,然后 follower 收到这样的信息,这里的话,我修改了一下,我把 commitTimeout 变成了五秒,正常的话他可能没这么长,他好像原本是 1 秒.
-
第一步发送请求。 -
第二步就是进行到自己的 log 区域里了 -
第三步是两个并行的送给 follower, -
第四步就是返回,只要有一个返回,他马上就可以提交了 -
第五步是提交 leader 的日志 -
第六步是将日志实时同步到状态机。 -
第七步返回给客户端成功 -
第八步然后就是发送给客户端,提交信息,并且客户端把它更新到状态机里
接下来我跟大家可以跟踪一下这些日志打印的位置,然后大家可以看一下上下文他是如何实现的。
...
(跟着日志讲解日志复制的代码,跳转较多,文字无法充分表述,建议直接参考视频)
...
我们看第二个场景
leader 接收客户端请求,向集群内所有节点发送复制 RPC,majority 正常响应 -> 正常 commit,然后 apply 到状态机,最后返回客户端处理成功(branch: replicate-log-2)
第二个场景就是说,比如说我们三个节点,如果前两个宕掉它能够正常的对外提供服务需求吗?OK 的,你看其实也是 OK 的吧,虽然说咱这个节点宕掉了,但是其实也是 OK 的。
leader 接收客户端请求,向集群内所有节点发送复制 RPC,少于 majority 正常响应 -> 不能 commit(branch: replicate-log-3)
(第三个场景)如果把这两个都宕掉了,然后它只剩 leader,基本上就没办法处理请求了。肯定会失败。所以说节点数小于一半节点数,他就没法工作了。
总结
今天的介绍大概的内容就是这些,然后,我相信这个是分享,主要是跟大家分享一下 raft 的源码啊,还有就是原版里面具体的选举和日志复制的一个实现,大家可以根据这个打印的日志梳理一下上下文,然后又可以更清楚的了解他的一个具体的实现。好的,那这个分享大概就是这些.
QA
-
1.这个库和 ETCD 的库有什么区别?
就说一下共同点吧,就是都是 go 写的,ETCD 那个库的话,他其实只实现了 raft 核心的部分,就是那个最核心的部分的存储和网络传输,那些都交给了,就是用户自己去实现,所以你需要去实现,很多其他的那个工作量,还有一些其他的开发量,比如说保存,存储的发送,都是需要你去实现这些逻辑。但是,还是要客观,那就相当于是全套的. 一整套的你都可以用,也比较简单,可以开箱即用,并且这个 ETCD 这个 raft 库写的更抽象一点,就是把核心算法做出成了一个状态机。他的状态不断的在 ready 里面去暴露,你需要去存储,去发送信息,这个其实是最最主要的一点,就是说,如果说你需要一些高性能的,或者说你需要一些,很多优化的,我觉得可能 ETCD 库会更好一点,但是我觉得如果说你要了解 raft 的算法,去了解 raft 协议的内容,这个库更好一点。就是说工程上的话,我觉得可能那个 etcd raft 会更好点的就是实际应用。
-
2.怎么做测试?
这个我可能没有更多的经验,我觉得可能还是。就是多预想一些 case 吧,就是比如说,就是你可能自己去构造一个 case 的场景,对写对应的测试用例就可以。
-
3.三个节点,宕机两个,剩下一个不可用,怎么处理请求的强一致?
这个时候服务应该是不可用的,当然如果要强行提供查询的服务,强一致肯定是无法保证的。
-
4.客户单独请求不经过 raft 模块吗?
当然这个的话,大家可以去看一下,consul, 他其实提供了很多的一致性的模型呢,就是你可能不需要强一致性,也需要强一致性,他有不同的模型,如果不需要强一致性,那你可以不需要经过任何的模块,如果说你需要强一致性,那最简单的就是通过 raft 的模块,就是你的日志复制到了大多数节点上,那么你才给客户端返回,这个是最简单的,其他的可能还有一些更优雅或者更好的设计,这个大家可以去了解下
-
5.这个库状态机实现不需要暴露读接口吗?
对,其实这两个我觉得这三个吧,其实都是关于一致性的问题,其实都都算是一个问题吧, 其实那个 apply 那其实你也可以读,也可以写啊,都可以。
-
6.节点之间的长连接怎么建立并通信,源码在哪儿?
在这个文件(raft-demo/net_transport.go)里面,他是单独的一个模块写的,都在这里面,他怎么样做去做 RPC 的分发,接收响应都在里面,大家可以,你们可以去看一下。
-
7.第七步未成功,leader 会给 client 正常返回吗?
那肯定肯定是不会啊,不会返回的呀,你没处理成功,肯定不会。但是对 leader,其实他收不到吗?收不到就是 timeout 了,正常的话,你他客户端 timeout 了,你肯定会去执行一下你客户端的逻辑,你比如说正常的请求,就是你客户端 timeout 了,那我肯定不会,不可能认为他是执行完成或者没完成,那可能会有一些一次查询什么的,所以你的客户端会有一定的开发工作量,大概他在这这里(论文)有一些简单的简单的介绍啊,你可以看一下,客户端开发会有一些,比如说怎么样防止 重复请求,涉及到客户端一些的开发的工作量,那是肯定是不可能,肯定就不会返回成功。
超时的话,leader 肯定是反馈给一个错误,就是请求请求失败给客户端。但是他会知道是,比如说看你看这个,不是有个 timeout 的实现吗?那你肯定知道是 timeout 的失败的,那么其实对于我客户端的视角来说, timeout 其实我并不知道这个请求是处理成功还是处理,(失败了对吧?) 我不能默认他成功,也不能默认他失败,那我对于我客户端,我是不是得去查询一下之类的一些动作。失败了,客户端会反馈给他失败的,实际有没有执行的话,可能你需要去,通过业务场景去查询一下,我认为是这样子的。
-
8.你在 debug 的这个库的这个 raft 的算法你大概用了多长时间?这样也可以帮助,现在可能还没有去学,但是可能想要去学,他可以预估一下这个大概的时间?
就是首先要去看这个源码,要去做这个的 debug 的话,肯定大家要对 raft 协议有一个那个最基本的认识,就是至少这个论文我不管中文还是英文,应该有有读,过了时间的话可能跟每个人不同,以我自己的话,论文我大概前前后后大概看了有两三个月吧,也不是一直在看,就偶尔有空看一下就是,反正我是对照中英文,然后以英文为主,然后再来看。看完以后,然后就当时确实也比较懵逼吧,然后就想着是要看一下源码实现才会更深刻地理解,就找到了这个库,然后不是直接就看库,然后就看会搜一些,简单的,就像我的特约服务一样,其实别人也有写的,就像我刚才那种那种跟踪跟踪代码的方法,然后去一步一步的那个找到他的关键的逻辑,大概的话,看源码的话,其实如果你了解是了解的那个协议的话,就稍微比较快一点,我觉得可能就是可能几周吧,或者两三周我觉得差不多你就可以,你就可以看明白了。
视频回看
推荐阅读
以上是关于烧脑系列:手撕 hashicorp/raft 算法,超长文的主要内容,如果未能解决你的问题,请参考以下文章