Raft实战系列,先说说一些基本概念
Posted 占小狼的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Raft实战系列,先说说一些基本概念相关的知识,希望对你有一定的参考价值。
本文为《Raft实战》系列开篇,该系列会从原理、源码、实践三个部分为大家讲解Raft算法。
原理部分我们会结合Raft论文讲解Raft算法思路,整体分篇会遵循Raft的模块化思想,分别讲解Leader election、Log replication、Safety、Cluster membership change、Log compaction等。
源码部分我们会通过分析hashicorp/raft来学习一个工业界的Raft实现,hashicorp/raft是Consul的底层依赖。
实践部分我们会基于hashicorp/raft来实现一个简单的分布式kv存储,以此作为系列的收尾。
接下来让我们开始实战Raft~
Raft是什么?
Raft is a consensus algorithm for managing a replicated log. It produces a result equivalent to (multi-)Paxos, and it is as efficient as Paxos, but its structure is different from Paxos; this makes Raft more understandable than Paxos and also provides a better foundation for building practical systems.
——《In Search of an Understandable Consensus Algorithm》
在分布式系统中,为了消除单点提高系统可用性,通常会使用副本来进行容错,但这会带来另一个问题,即如何保证多个副本之间的一致性?
所谓的一致性并不是指集群中所有节点在任一时刻的状态必须完全一致,而是指一个目标,即让一个分布式系统看起来只有一个数据副本,并且读写操作都是原子的,这样应用层就可以忽略系统底层多个数据副本间的同步问题。也就是说,我们可以将一个强一致性(线性一致性)分布式系统当成一个整体,一旦某个客户端成功的执行了写操作,那么所有客户端都一定能读出刚刚写入的值。即使发生网络分区故障,或者少部分节点发生异常,整个集群依然能够像单机一样提供服务。
共识算法(Consensus Algorithm)就是用来做这个事情的,它保证即使在小部分(≤ (N-1)/2)节点故障的情况下,系统仍然能正常对外提供服务。共识算法通常基于状态复制机(Replicated State Machine)模型,也就是所有节点从同一个state出发,经过同样的操作log,最终达到一致的state。
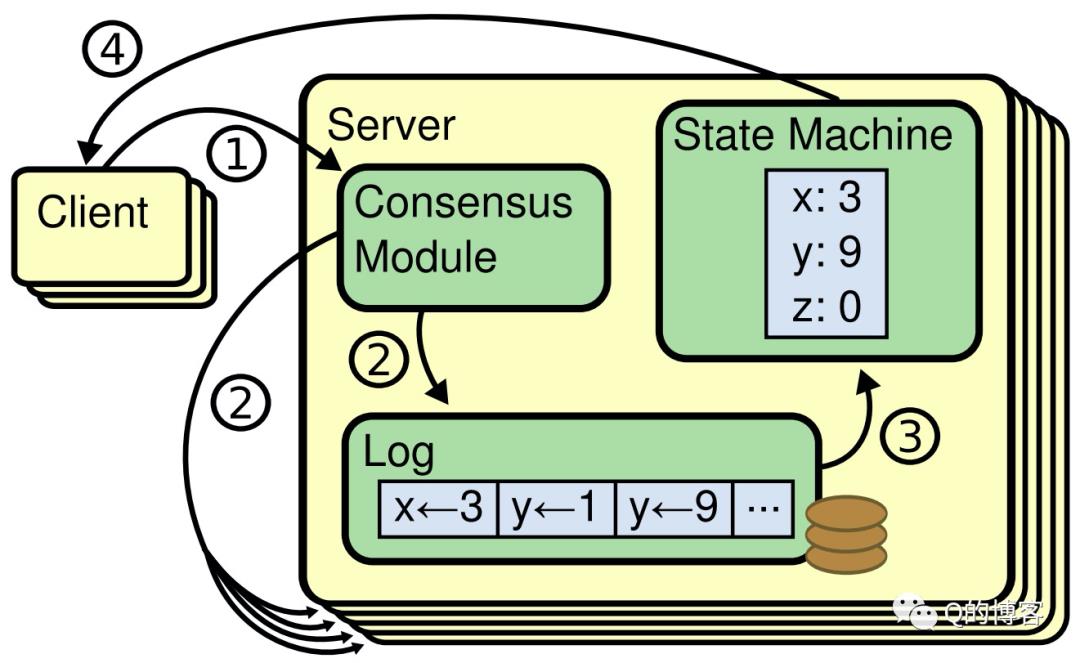
共识算法是构建强一致性分布式系统的基石,Paxos是共识算法的代表,而Raft则是其作者在博士期间研究Paxos时提出的一个变种,主要优点是容易理解、易于实现,甚至关键的部分都在论文中给出了伪代码实现。
Raft基本概念
Raft使用Quorum机制来实现共识和容错,我们将对Raft集群的操作称为提案,每当发起一个提案,必须得到大多数(> N/2)节点的同意才能提交。
Raft核心算法将一致性问题拆分为三个子问题,逐个解决,大大提升了算法的易用性:
Leader election
集群中必须存在一个leader节点。
Log replication
Leader节点负责接收客户端请求,并将请求操作序列化成日志同步。
Safety
包括leader选举限制、日志提交限制等一系列措施,来确保state machine safety。
除核心算法外还有集群成员变更、日志压缩等。
Raft集群中每个节点都处于以下三种状态之一:
Leader
所有请求的处理者,接收客户端发起的操作请求,写入本地日志后同步至集群其它节点。
Follower
请求的被动更新者,从leader接收更新请求,写入本地文件。如果客户端的操作请求发送给了follower,会首先由follower重定向给leader。
Candidate
如果follower在一定时间内没有收到leader的心跳,则判断leader可能已经故障,此时启动leader election过程,本节点切换为candidate直到选主结束。
每开始一次新的选举,称为一个term,每个term都有一个严格递增的整数与之关联。
节点的状态切换如图所示:
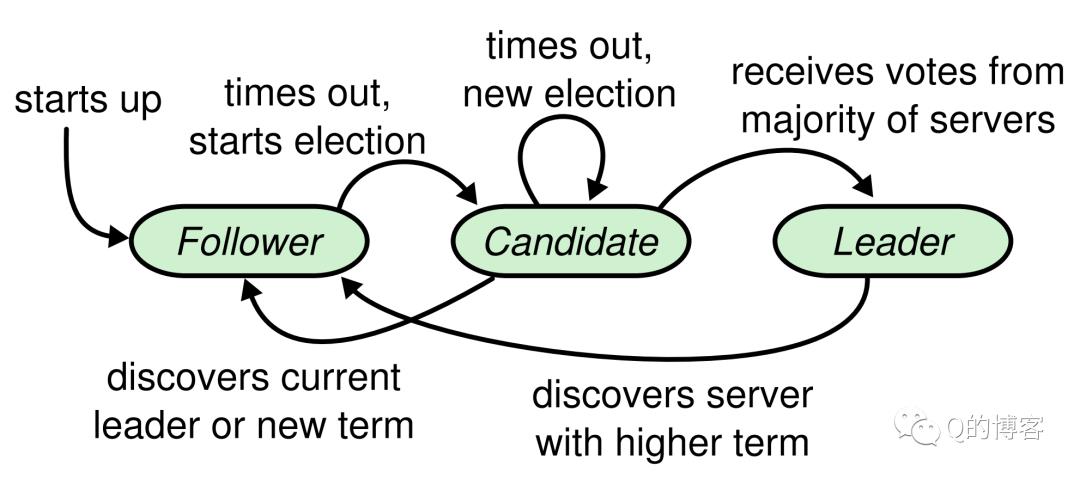
具体说明如下:
Starts up
节点刚启动时自动进入follower状态。
Times out, starts election
进去follower状态后开启一个选举定时器,到期时切换为candidate并发起选举,leader节点的心跳会部分重置这个定时器。
Times out, new election
进入candidate状态后开启一个超时定时器,如果到期时还未选出新的leader,就保持candidate状态并重新开始下一次选举。
Receives votes from majority of servers
Candidate状态节点收到半数以上选票,切换状态成为新的leader。
Discovers current leader or new term
Candidate状态节点收到leader或更高term号的消息,表示已经有leader了,切回follower。
Discovers server with higher term
Leader节点收到更高term号的消息,表示已经存在新leader了,切回follower。这种切换一般发生在网络分区时,比如旧leader宕机后恢复。
每当candidate触发leader election时都会增加term,如果一个candidate赢得选举,他将在本term中担任leader的角色,但并不是每个term都一定对应一个leader,比如上述的“times out, new election”情况(对应下图中的t3),可能在选举超时时都没有产生一个新的leader,此时将递增term号并开始一次新的选举。
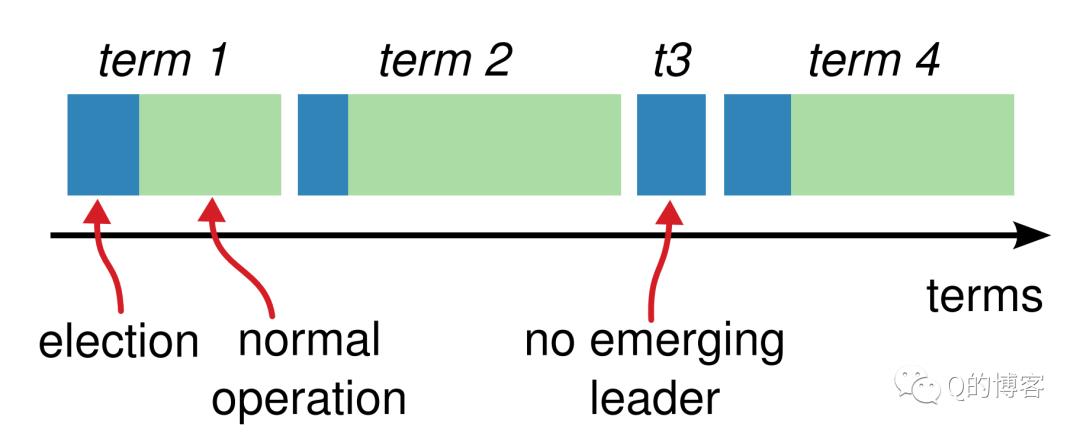
Term更像是一个逻辑时钟(logic clock)的作用,有了它,可以发现哪些节点的状态已经过期。每一个节点都保存一个current term,在通信时带上这个term号。
节点间通过RPC来通信,主要有两类RPC请求:
-
RequestVote RPCs: 用于candidate拉票选举 -
AppendEntries RPCs: 用于leader向其它节点复制日志以及同步心跳
Raft的基本概念就是这些,下一篇我们将详细介绍Leader election。
最近面试BAT,整理一份面试资料
《Java面试BAT通关手册》
,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
以上是关于Raft实战系列,先说说一些基本概念的主要内容,如果未能解决你的问题,请参考以下文章