生物信息学|药物发现中的机器学习技术
Posted BBIT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了生物信息学|药物发现中的机器学习技术相关的知识,希望对你有一定的参考价值。
论文剖析
生物信息学|药物发现中的机器学习技术(1)
///////////////
1. 摘要:
机器学习(ML)在药物发现中的持续增长,产生了令人印象深刻的结果。随着它们的使用增加,它们的局限性也变得越来越明显。这些局限性包括它们对大数据的需求、数据的稀缺性以及缺乏可解释性。也很明显的是,这些技术并不是真正自主的,即使在部署后也需要再训练。在这篇综述中,我们详细介绍了如何使用先进技术来规避这些挑战,并举例说明了药物发现和相关学科。此外,我们提出了新兴技术及其在药物发现中的潜在作用。本文提出的技术有望扩大ML在药物发现中的适用性。
2. 介绍
ML在药物发现领域的应用持续增长,促进了众多途径的研究。ML的成功体现在越来越多的制药公司,其中ML是其商业模式的核心(表1)。此外,ML也被大型制药公司用于药物发现。这样的成功证明了ML对于药物发现的必要性和实用性,也明确表明药物发现将与ML紧密联系在一起。其目标是减少药物发现的资源浪费和消除对动物实验的需要。
ML的成功在于它能够在复杂和大量数据集中识别模式。此外,ML技术(MLT)可以使用常见的编程语言开发,包括Python和R,大多数研究人员都可以访问这些语言。此外,还有一些第三方软件为不熟悉编码的研究人员提供了访问ML技术的途径,例如苹果的Create ML。尽管它们很简单,但第三方软件的能力有限。
传统的MLT在药物发现方面已经得到了深入的探索。这些技术包括有监督和无监督MLT,包括k近邻(kNN)、决策树、随机森林、支持向量机(SVM)、人工神经网络(ANN)、主成分分析(PCA)和k-means。与传统的预测算法相比,它们的吸引力在于其简单、计算简单、预测精度更高。同样,传统技术的潜在机制也可以被非计算机科学家研究人员认知地理解。例如,对于kNN,用户只需要控制一个参数,即k值,而k值决定了基于多数投票的分类搜索空间。另一个例子是支持向量机(SVM),它使用超平面结合支持向量来描绘类别,以最大化不同类别之间的距离。支持向量机受益于使用核技巧,它允许数据的非线性映射,这已被广泛用于非线性数据集。该技术也可用于PCA(核PCA;kPCA)。最近的一项研究发现,kPCA可用于改进线性模型的分类,与非线性模型的性能相当且速度很快。
尽管传统的MLT简单,但也有其缺点。kNN遭受维数诅咒,在高维空间的预测性能开始减弱。同样,当维数大于样本大小时,SVM的性能开始下降。增加随机森林中树木的数量可以提高预测精度,但大量的树木结果会产生一种对实时监控效率低下的算法。然而,对MLT的主要批评有两点,一是他们对大数据的需求,二是缺乏透明度。考虑到数据收集可能具有挑战性、昂贵和耗时,解决这些限制是必需的。此外,透明度可以促进用户对发现过程的理解,并将他们对ML理解过程的依赖降到最低。传统MLT的另一个局限性是缺乏自主性。例如,监督学习需要标记目标变量(即,要预测的变量)。此外,一旦部署,例如作为基于web的软件,它将需要后期生产维护,特别是随着数据集的发展。为了解决这些限制,研究团体采用了新技术,并取得了有希望的结果。预计这些先进技术将进一步扩大ML的应用,最终目标是在药物发现中实现人工智能(AI)。人工智能是计算机科学中寻求使用机器创造人类智能的一个广泛分支,ML是实现这一目标的核心。近年来,ML的一个子集——深度学习(deep learning),作为一种能够从大数据中获得高精度的技术,同时能够处理结构化和非结构化数据。
如前所述,ML在药物发现方面继续增长。这种增长伴随着适当的评论,讨论传统MLT和深度学习的基本原理和应用。最近还对自然语言处理进行了综述,这是一个在药物发现中受到关注的领域。在这里,我们关注的是尚未得到足够重视的先进技术,尽管这些技术具有很强的发展潜力。我们优先考虑在药物发现中使用的例子。综述的技术包括强化学习、迁移学习和多任务学习。Lo等人在其广受欢迎的关于药物发现的ML的综述中指出,具有更高可见性的技术以及防止过拟合的方法值得进一步发展。我们通过描述贝叶斯神经网络(BNN)和可解释的算法来解决他们的评论。混合量子推荐系统的出现也是我们研究的重点。
3. 先进的机器学习技术
对MTLs的一些批评包括需要大数据集和人为干预。从这些评论,先进的技术进行了研究,以解决传统的MLT的缺点,从而进一步扩大其适用性。这些先进的技术包括强化学习(RL),它弥补了与自主学习技术之间的差距;迁移学习和多任务学习,用于在缺乏大数据的情况下开发预测模型。在这里,我们提供了这些先进技术的概述,并举例说明了它们在药物发现中的应用。这些技术的总结见表2。

4. 强化学习
RL是ML的一个令人振奋的子类,在学术界和工业界都引起了兴趣。它从上世纪50年代就开始流行了,当RL模型在一场与职业人类对手的围棋比赛中获胜时,它的流行又重新开始了,在这场比赛中,以前没有任何算法能够实现这一非凡的成就。Go游戏是世界上最古老的连续游戏之一,被用作AI的基准,因为游戏中可能的配置数量被认为是250150。这远远超过了人体中蛋白质的数量和宇宙中质子的数量。
RL与有监督和无监督学习的区别在于,它是一种自主的持续学习形式。这是因为RL算法产生判断,而大多数有监督和无监督算法进行预测。RL对动态环境的快速响应能力正是它被用于游戏、机器人和金融行业交易的原因。事实上,与监督学习相比,RL在某些应用中的表现优于分类任务,但RL在最少人为干扰的情况下持续学习的能力才是理想的。
RL的概念从动物的奖赏机制中得到启发。在RL中,系统没有给出期望策略的示例。相反,RL通过接收来自其环境的强化信号,从经验上学习要采取的最佳决策。RL的主要组成部分是代理、环境、状态、目标和奖励功能。通过与环境交互来训练代理,环境可以有多种状态(即场景)。代理将为给定的状态选择一个操作,并将获得正面或负面(即惩罚)奖励。代理将继续为每个不同的状态采取行动,同时希望增加其获得的累计奖励。奖励是一个数学公式,由用户根据特定目标定义。以游戏为例,代理的目标或策略是赢得游戏,赢得游戏时将获得+1,输掉游戏时将获得-1。在金融交易的情况下,目标可以是利润最大化,因此,代理人将因采取一系列导致利润最大化的行动而获得奖励。
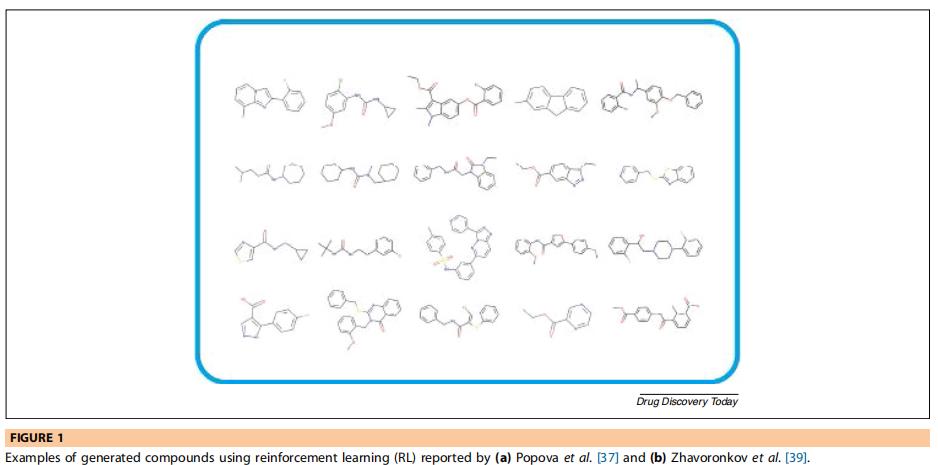
当代RL主要集中在从头分子设计或分子优化。Popova等人对药物的从头设计进行了一项结合了这两个方面的值得注意的研究(图1a)。通过这种方法,RL结合了两种深度学习技术。其中一种技术是生成模型,它起到推动者的作用,生成表面上化学上可行的分子。另一种技术,预测模型,充当了批评家的角色,它对每一个生成的分子奖励或惩罚生成模型。利用这种方法,研究人员利用CheMBL21数据库中的150万个结构,根据它们的SMILES字符串来训练生成模型。结果表明,合成了100万个化合物,其中95%的化合物通过ChemAxon的结构检查器被证实是可行的。此外,他们发现在一个单独的数据库(锌)中存在32000个从头生成的结构分子。这项研究进一步证明,通过深度RL可以获得优化的新化合物,以获得理想的物理性质、化学复杂性或生物活性。虽然研究表明RL可以被用来生成新的化合物,但是还需要进一步的工作来完善这个模型。例如,采用的策略可能无法保证药物特异性化合物。此外,这项研究使用了SMILES,尽管SMILES是一种简单而优雅的化合物表示,但在生成模型中的使用也引起了一些问题。
在另一项研究中,Zhavoronkov等人开发了一个特定化合物的从头模型:DDR1激酶抑制剂(图1b)。他们的目的是证明RL对快速鉴定有效化合物的有效性,从而证明RL可以解决药物开发的重要障碍,即缓慢开发阶段和药物选择性。在短短的46天里,作者们就能够设计、合成和完成invitro和invovo测试。然而,其中一种生成的化合物既类似于用于训练模型的化合物,也类似于现有的上市药物。因此,尽管成功地证明了RL如何加速药物发现过程,但未来的模型仍需要编码,以使新生成的化合物与输入数据和现有上市化合物不同。尽管在药学领域,RL的应用仅限于药物设计,但更广泛的医学界已经探索了该算法的其他潜力。在向个性化剂量迈进的一步中,一些基于模拟的研究探索了使用RL来提供脓毒症治疗的动态决策,麻醉药物输送控制,以及糖尿病视网膜病变的检测。RL的使用也扩展到了组学、生物成像和医学研究。RL的血管学表现如图2a所示。
原论文名称:Advanced machine-learning techniques in drug discovery
更多有趣资讯扫码关注 BBIT
以上是关于生物信息学|药物发现中的机器学习技术的主要内容,如果未能解决你的问题,请参考以下文章