机器学习 | 时间序列数据分析的15种常用的功能
Posted 沈浩老师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习 | 时间序列数据分析的15种常用的功能相关的知识,希望对你有一定的参考价值。
时间序列是相对于时间观察到的一系列数据点。在数据科学中,时间序列主要是一个独立变量,目标是使用历史数据预测未来。传统上,时间序列问题是通过ARIMA模型使用滞后和微分特征来解决的。但是,在发生意外事件时,所记录的信号显示出趋势的更多动态特性,因此仅使用这些传统方法就很难获得准确的模型。
从业人员提出了一种现代方法,即通过将时间序列转换为表格数据格式以及手动特征工程来解决机器学习问题。有许多可用的数据集可以很好地解决特定的时间序列问题。对于金融,供应链等领域的问题,基于日期和时间的功能可以在捕获趋势和理解数据方面发挥重要作用,尤其是在涉及时间序列数据时。
本文主要介绍一些可以完全基于日期和时间创建的功能。这些功能中的某些功能非常常用,并且能够在时间序列数据分析中极大的帮助到我们。
所需安装包:
1.Pandas
2.Datetime
3.Calendar
数据集来自:
http://archive.ics.uci.edu/ml/datasets/Occupancy+Detection+
数据集样本如下:
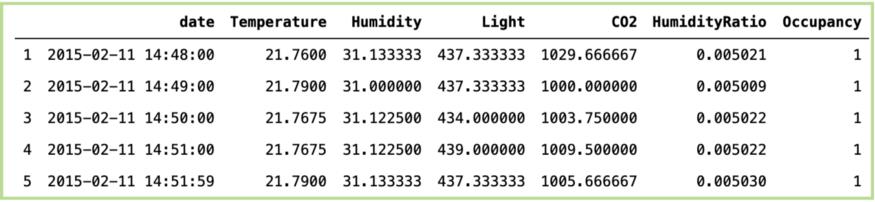
01
Date:
#Importing the package:import pandas as pd# Getting the date:data['Date'] = data['date'].dt.date# Pring the date:data['Date'].head()
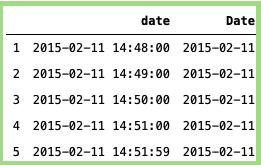
上面代码的输出
02
Time:
#Importing the package:import pandas as pd# Getting the Time:data['Time'] = data['date'].dt.time# Pring the time:data[['date','Time']].head()
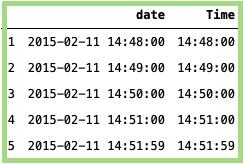
上面代码的输出
03
Hour:
#Importing the package:import pandas as pd# Getting the Hour:data['Hour'] = data['date'].dt.hour# Pring the time:data[['date','Hour']].sample(n=10)
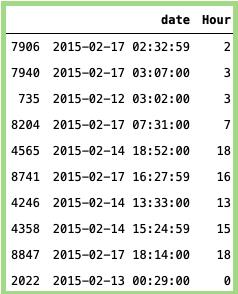
上面代码的输出
04
Minute:
#Importing the package:import pandas as pd# Getting the Minutes:data['Minute'] = data['date'].dt.minute# Pring the Minutes:data[['date','Minute']].sample(n=10)
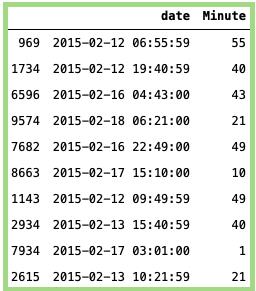
上面代码的输出
05
Second:
# Importing the package:import pandas as pd# Getting the Seconds:data['Second'] = data['date'].dt.second# Pring the Seconds:data[['date','Second']].sample(n=10)
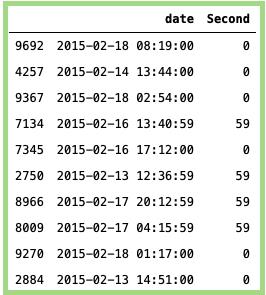
上面代码的输出
06
一年中第几周:
# Getting the week of year:data_min_temp['Week_of_year'] = data_min_temp['Date'].dt.week# Taking random samples:data_min_temp[['Date','Week_of_year']].sample(n=10)
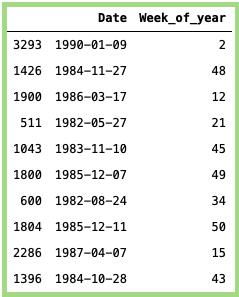
上面代码的输出
07
星期几:
# Getting the day of week:data_min_temp['day_of_week'] = data_min_temp['Date'].dt.dayofweek# Taking random samples:data_min_temp[['Date','day_of_week']].sample(n=10)
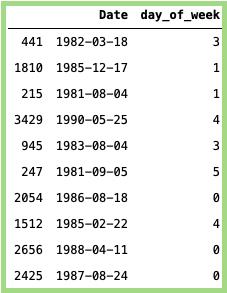
上面代码的输出
08
一年中的第几天:
# Getting the day of year:data_min_temp['day_of_year'] = data_min_temp['Date'].dt.dayofyear# Taking random sampledata_min_temp[['Date','day_of_year']].sample(n=10)
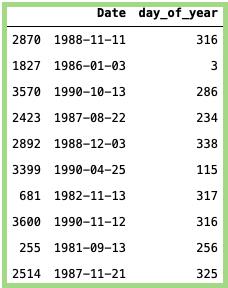
上面代码的输出
09
两日期间的天数差异:
此功能用于根据天数计算两个日期之间的时差。下面是显示从今天到过去某个x日期的示例。
#获取与今天相比的月份差异:data_min_temp [ 'days_diff_from_today' ] =(日期时间。日期时间。现在()- data_min_temp [ '日期' ])。dt。天#随机抽样:data_min_temp [[ 'Date','days_diff_from_today' ]]。样品(10)
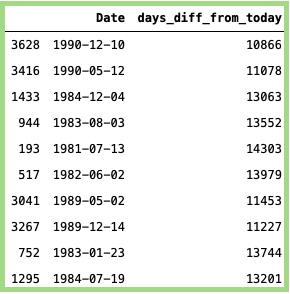
上面代码的输出
10
两日期间相隔几个月:
#获取与今天相比的月份差异:data_min_temp [ 'month_diff_from_today' ] =(日期时间。日期时间。现在()- data_min_temp [ '日期' ])。dt。天// 30#随机抽样:data_min_temp [[ 'Date','month_diff_from_today' ]]。样品(10)
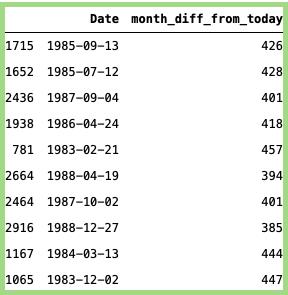
上面代码的输出
11
到月底的天数:
计算到月底为止的剩余天数。对于到月底有趋势的问题,这个功能非常有用。
#再导入一个软件包:从 日历 导入 月份范围#定义一个函数来获取月底:DEF last_day_of_month(DATE_VALUE):返回 date_value。替换(天 = monthrange(DATE_VALUE。年,DATE_VALUE。月)[ 1 ])#计算到月底的天数:data_min_temp [ 'days_to_end_of_the_month' ] = data_min_temp [ 'Date' ]。申请(拉姆达 X:(last_day_of_month(X)- X)。天)#随机抽样:data_min_temp [[ 'Date','days_to_end_of_the_month' ]]。样品(10)
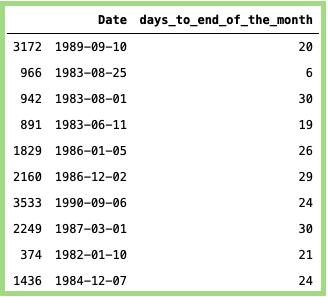
上面代码的输出
12
计算处于一年中的哪个季度:
#计算季度:data_min_temp [ 'quarter' ] = data_min_temp [ 'Date' ]。dt。25美分硬币#随机抽样:data_min_temp [[ 'Date','quarter' ]]。样品(10)
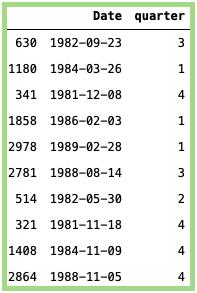
上面代码的输出
13
确定是否是该季度的开始:
#计算季度:data_min_temp [ 'is_quarter_start' ] = data_min_temp [ 'Date' ]。dt。is_quarter_start#映射值(True = 1和False = 0):data_min_temp [ 'is_quarter_start' ] = data_min_temp [ 'is_quarter_start' ]。映射({ True:1,False:0 })#随机抽样:data_min_temp [[ 'Date','is_quarter_start' ]]。样品(10)
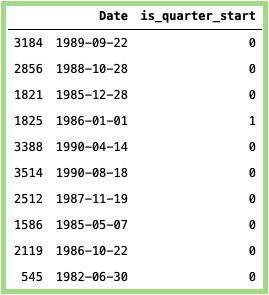
上面代码的输出
14
确定是否在该季度末:
#计算季度末:data_min_temp [ 'is_quarter_end' ] = data_min_temp [ 'Date' ]。dt。is_quarter_end#映射值(True = 1和False = 0):data_min_temp [ 'is_quarter_end' ] = data_min_temp [ 'is_quarter_end' ]。映射({ True:1,False:0 })#随机抽样:data_min_temp [[ 'Date','is_quarter_end' ]]。样品(10)
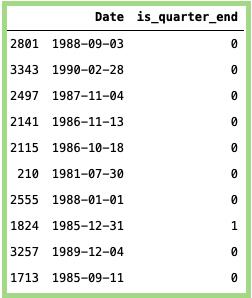
上面代码的输出
15
得到日期中的年/月/日:
#计算年份:data_min_temp [ 'year' ] = data_min_temp [ 'Date' ]。dt。年#随机抽样:data_min_temp [[ 'Date','year' ]]。样品(10)#计算月份:data_min_temp [ 'month' ] = data_min_temp [ 'Date' ]。dt。月#随机抽样:data_min_temp [[ 'Date','month' ]]。样品(10)#计算日:data_min_temp [ 'day' ] = data_min_temp [ 'Date' ]。dt。天#随机抽样:data_min_temp [[ 'Date','day' ]]。样品(10)


指导老师:

以上是关于机器学习 | 时间序列数据分析的15种常用的功能的主要内容,如果未能解决你的问题,请参考以下文章