机器学习基础:线性回归和梯度下降的初学者教程
Posted AI有道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习基础:线性回归和梯度下降的初学者教程相关的知识,希望对你有一定的参考价值。
编译 | VK
来源 | Towards Data Science
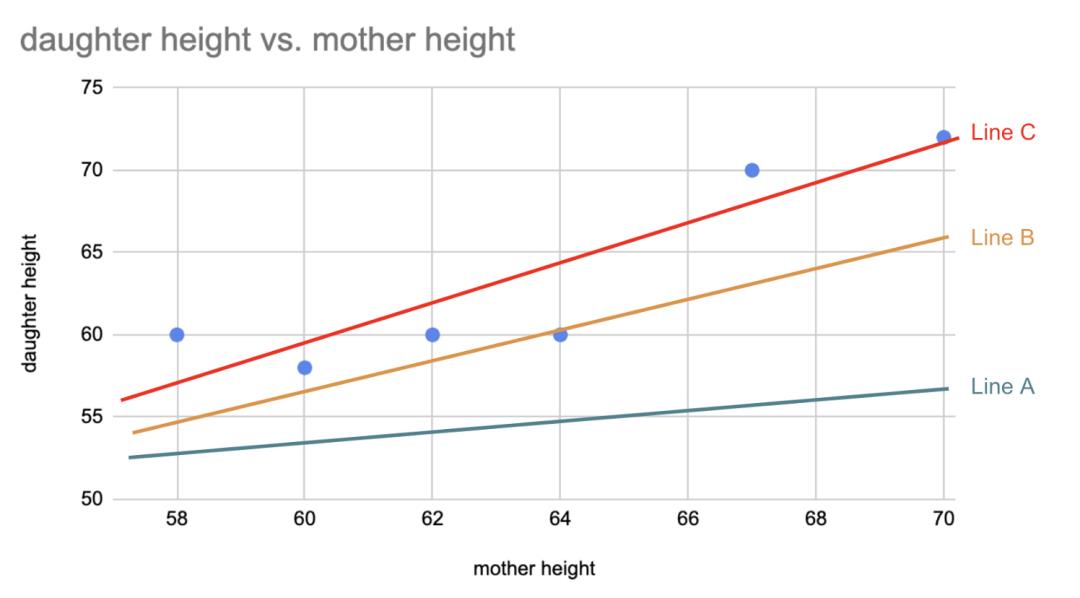
假设我们有一个虚拟的数据集,一对变量,一个母亲和她女儿的身高:
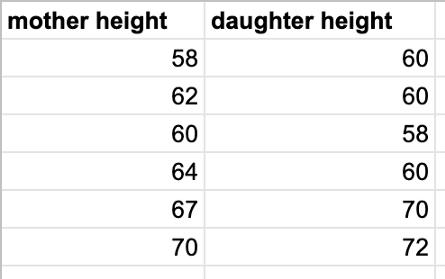
考虑到另一位母亲的身高为63,我们如何预测她女儿的身高?
方法是用线性回归。
首先,找到最合适的直线。然后用这条直线做预测。
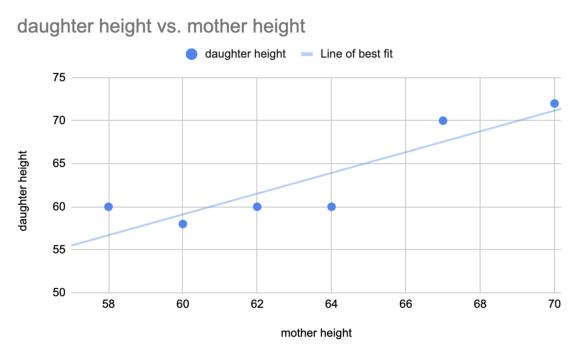
❝线性回归是寻找数据集的最佳拟合线。这条线可以用来做预测。
❞
「你如何找到最合适的?」
这就是使用梯度下降的原因。
❝梯度下降是一种找到最佳拟合线的工具
❞
在深入研究梯度下降之前,让我们先看看另一种计算最佳拟合线的方法。
「最佳拟合线的统计计算方法:」
直线可以用公式表示:y=mx+b。
回归线斜率m的公式为:
m = r * (SD of y / SD of x)
转换:x和y值之间的相关系数(r),乘以y值的标准差(SD of y)除以x值的标准偏差(SD of x)。
以上数据中母亲身高的标准差约为4.07。女儿身高的标准偏差约为5.5。这两组变量之间的相关系数约为0.89。
因此,最佳拟合线或回归线为:
y = 0.89*(5.5 / 4.07)x + b
y = 1.2x + b
我们知道回归线穿过了平均点,所以线上的一个点是(x值的平均值,y值的平均值),其中有(63.5,63.33)
63.33 = 1.2*63.5 + b
b = -12.87
因此,使用相关系数和标准差计算的回归线近似为:
y = 1.2x - 12.87
使用统计学的回归线为y=1.2x-12.87
现在,让我们来研究梯度下降。
「计算最佳拟合线的梯度下降法:」
在梯度下降中,你从一条随机线开始。然后一点一点地改变直线的参数(即斜率和y轴截距),以得到最佳拟合的直线。
你怎么知道你什么时候到达最合适的位置?
对于你尝试的每一条直线——直线A、直线B、直线C等等——你都要计算误差的平方和。如果直线B的值比直线A的误差小,那么直线B更适合,等等。
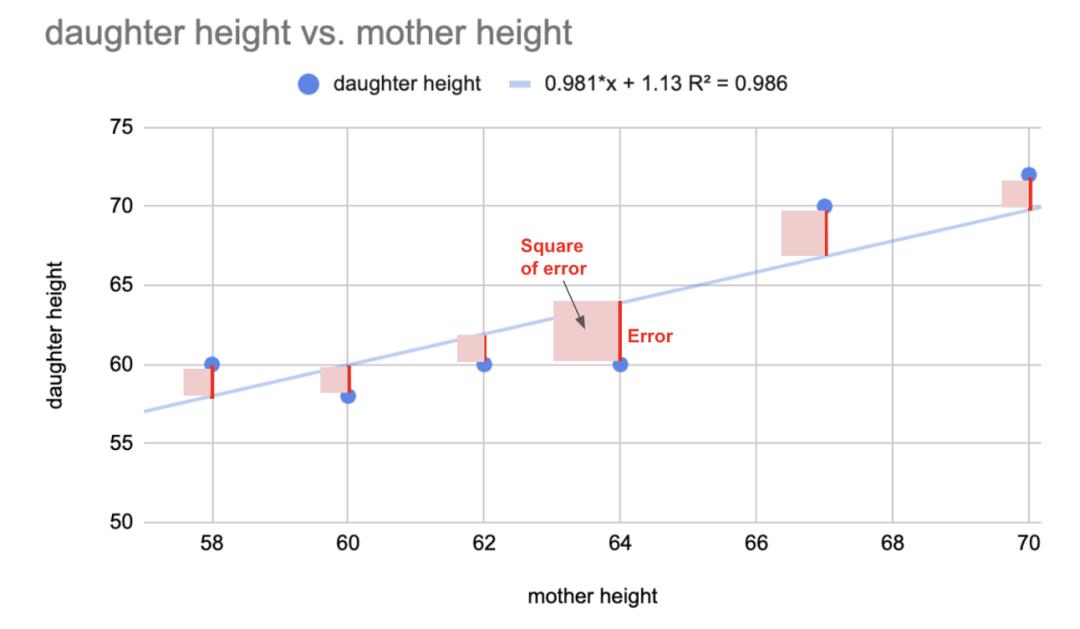
误差是你的实际值减去你的预测值。最佳拟合线使所有误差平方和最小化。在线性回归中,我们用相关系数计算出的最佳拟合线也恰好是最小平方误差线。这就是回归线被称为最小二乘回归线的原因。
❝最佳拟合线是最小二乘回归线
❞
在下面的图像中,直线C比直线B更适合,直线B比直线A更适合。
这就是梯度下降的工作原理:
你从一条随机线开始,比如说直线a,你计算这条线的误差平方和。然后,调整斜率和y轴截距。重新计算新行的误差平方和。继续调整,直到达到局部最小值,其中平方误差之和最小。
❝梯度下降法是一种通过多次迭代最小化误差平方和来逼近最小平方回归线的算法。
❞
梯度下降算法
在机器学习术语中,误差平方和称为“成本”。这个成本公式是:
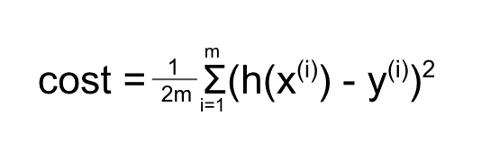
其中

因此,这个方程大致是“误差平方和”,因为它计算的是预测值减去实际值平方的总和。
1/2m是“平均”数据点数量的平方误差,这样数据点的数量就不会影响函数。为什么除以2请看这个解释(https://datascience.stackexchange.com/questions/52157/why-do-we-have-to-divide-by-2-in-the-ml-squared-error-cost-function)。
在梯度下降中,目标是使代价函数最小化。我们通过尝试不同的斜率和截距值来实现这一点。但是应该尝试哪些值以及如何改变这些值?
我们根据梯度下降公式改变它们的值,这个公式来自于对代价函数的偏导数。确切的数学公式可以在这个链接中找到:https://www.ritchieng.com/one-variable-linear-regression/
通过偏导数,得到:

这个公式计算每次迭代时θ的变化量。
α(α)被称为学习率。学习率决定了每次迭代的步骤有多大。有一个好的学习率是非常重要的,因为如果它太大,你的算法不会达到最小值,如果它太小,你的算法会花很长时间才能达到。对于我的例子,我选择alpha为0.001
总而言之,步骤如下:
-
估计θ
-
计算成本
-
调整θ
-
重复2和3,直到你达到收敛。
这是我使用梯度下降实现简单线性回归的方法。
斜率和截距都是0,0。
注:在机器学习中,我们使用θ来表示向量[y-截距,斜率]。θ=y轴截距。θ1=斜率。这就是为什么在下面的实现中将theta看作变量名。
# x = [58, 62, 60, 64, 67, 70] # 妈妈的身高
# y = [60, 60, 58, 60, 70, 72] # 女儿的身高
class LinearRegression:
def __init__(self, x_set, y_set):
self.x_set = x_set
self.y_set = y_set
self.alpha = 0.0001 # alpha 是学习率
def get_theta(self, theta):
intercept, slope = theta
intercept_gradient = 0
slope_gradient = 0
m = len(self.y_set)
for i in range(0, len(self.y_set)):
x_val = self.x_set[i]
y_val = self.y_set[i]
y_predicted = self.get_prediction(slope, intercept, x_val)
intercept_gradient += (y_predicted - y_val)
slope_gradient += (y_predicted - y_val) * x_val
new_intercept = intercept - self.alpha * intercept_gradient
new_slope = slope - self.alpha * (1/m) * slope_gradient
return [new_intercept, new_slope]
def get_prediction(self, slope, intercept, x_val):
return slope * x_val + intercept
def calc_cost(self, theta):
intercept, slope = theta
sum = 0
for i in range(0, len(self.y_set)):
x_val = self.x_set[i]
y_val = self.y_set[i]
y_predicted = self.get_prediction(slope, intercept, x_val)
diff_sq = (y_predicted - y_val) ** 2
sum += diff_sq
cost = sum / (2*len(self.y_set))
return cost
def iterate(self):
num_iteration = 0
current_cost = None
current_theta = [0, 0] # 初始化为0
while num_iteration < 500:
if num_iteration % 10 == 0:
print('current iteration: ', num_iteration)
print('current cost: ', current_cost)
print('current theta: ', current_theta)
new_cost = self.calc_cost(current_theta)
current_cost = new_cost
new_theta = self.get_theta(current_theta)
current_theta = new_theta
num_iteration += 1
print(f'After {num_iteration}, total cost is {current_cost}. Theta is {current_theta}')
使用这个算法和上面的母女身高数据集,经过500次迭代,我得到了3.4的成本。
500次迭代后的方程为y=0.998x+0.078。实际回归线为y=1.2x-12.87,成本约为3.1。
用[0,0]作为[y-截距,斜率]的初始值,得到y=1.2x-12.87是不切实际的。为了在没有大量迭代的情况下接近这个目标,你必须从一个更好的初始值开始。
例如,[-10,1]在不到10次迭代后,大约得到y=1.153x-10,成本为3.1。
在机器学习领域,调整学习率和初始估计等参数是比较常见的做法。
这就是线性回归中梯度下降的要点。
❝梯度下降法是一种通过多次迭代最小化误差平方和来逼近最小平方回归线的算法。
❞
到目前为止,我已经讨论过简单线性回归,其中只有1个自变量(即一组x值)。理论上,梯度下降可以处理n个变量。
我已经重构了我以前的算法来处理下面的n个维度。
import numpy as np
class LinearRegression:
def __init__(self, dataset):
self.dataset = dataset
self.alpha = 0.0001 # alpha 是学习率
def get_theta(self, theta):
num_params = len(self.dataset[0])
new_gradients = [0] * num_params
m = len(self.dataset)
for i in range(0, len(self.dataset)):
predicted = self.get_prediction(theta, self.dataset[i])
actual = self.dataset[i][-1]
for j in range(0, num_params):
x_j = 1 if j == 0 else self.dataset[i][j - 1]
new_gradients[j] += (predicted - actual) * x_j
new_theta = [0] * num_params
for j in range(0, num_params):
new_theta[j] = theta[j] - self.alpha * (1/m) * new_gradients[j]
return new_theta
def get_prediction(self, theta, data_point):
# 使用点乘
# y = mx + b 可以重写为 [b m] dot [1 x]
# [b m] 是参数
# 代入x的值
values = [0]*len(data_point)
for i in range(0, len(values)):
values[i] = 1 if i == 0 else data_point[i-1]
prediction = np.dot(theta, values)
return prediction
def calc_cost(self, theta):
sum = 0
for i in range(0, len(self.dataset)):
predicted = self.get_prediction(theta, self.dataset[i])
actual = self.dataset[i][-1]
diff_sq = (predicted - actual) ** 2
sum += diff_sq
cost = sum / (2*len(self.dataset))
return cost
def iterate(self):
num_iteration = 0
current_cost = None
current_theta = [0] * len(self.dataset[0]) # initialize to 0
while num_iteration < 500:
if num_iteration % 10 == 0:
print('current iteration: ', num_iteration)
print('current cost: ', current_cost)
print('current theta: ', current_theta)
new_cost = self.calc_cost(current_theta)
current_cost = new_cost
new_theta = self.get_theta(current_theta)
current_theta = new_theta
num_iteration += 1
print(f'After {num_iteration}, total cost is {current_cost}. Theta is {current_theta}')
一切都是一样的,唯一的例外是不用mx+b(即斜率乘以变量x加y截距)来获得预测值,而是进行矩阵乘法。参见上述的def get_prediction。
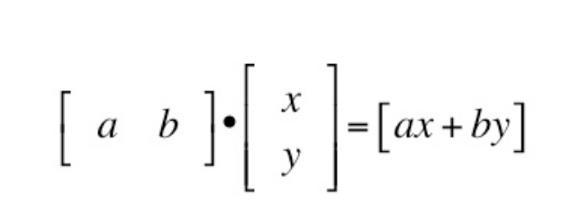
使用点积,你的算法可以接受n个变量来计算预测。
推荐阅读
(点击标题可跳转阅读)
重磅!
AI有道年度技术文章电子版PDF来啦!
扫描下方二维码,添加 AI有道小助手微信,可申请入群,并获得2020完整技术文章合集PDF(一定要备注:入群 + 地点 + 学校/公司。例如:入群+上海+复旦。
长按扫码,申请入群
(添加人数较多,请耐心等待)
感谢你的分享,点赞,在看三连

以上是关于机器学习基础:线性回归和梯度下降的初学者教程的主要内容,如果未能解决你的问题,请参考以下文章