实践中学到的最重要的机器学习经验!
Posted Python遇见机器学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实践中学到的最重要的机器学习经验!相关的知识,希望对你有一定的参考价值。
设为“星标”,第一时间知晓最新干货~
文 | 微调 源 | 知乎问答
今天我们讨论一个很有实际意义的问题:你在实践中学到的最重要的机器学习经验是什么?以下回答来自知乎优秀答主微调。
1.永远保持怀疑
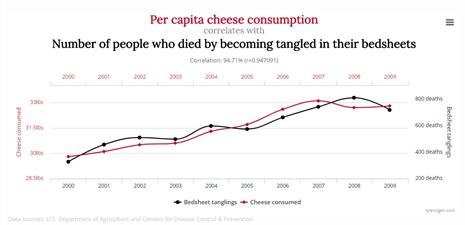
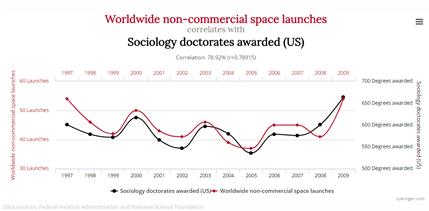
机器学习是最容易得到错误结论的一种解决方案。和编程、做表格、或者纯粹的数学建模不同,机器学习是由数据驱动,并有很强的黑箱性。因此很多时候容易得出似是而非的结论。举个最简单的例子:伪相关/虚假相关(spurious correlation),两个变量很容易看起来有很强的相关(参看图1和2),然而这仅仅是偶然。因此当机器学习模型很轻松就达到很好的效果时,比如百分之百的正确率,你要警惕。除了过拟合以外,你很有可能包含了某个不该使用的强特征,甚至把标签y也当做特征使用了。
2.寻找“最小预测单元”,避免追求通过一个模型预测多个目标
最清晰易懂,且容易证明正误的模型就是目标明确的模型。我们得知业务需求以后,尽量把预测范围控制好,不要被同时实现多个目标所诱惑。
举例,如果客户的需要是预测明天的天气,那就做一个纯粹的天气预测模型,不要瞻前顾后的想要同时预测湿度、温度等相关但不是根本的问题。你想要通过单个模型得到的结论越多,往往建模和调参就越复杂。从单一问题入手,再逐步扩展,甚至将知识迁移,都是可以的。
3.简单有效的模型最好,不要完全弃用“人为规则”
首先不要为了使用模型而创造问题:机器学习的目标是解决问题。因此,从简单到复杂模型的“进化”才是比较合理的方案。比如如果能用监督,就监督学习。退而求其次才选择半监督或者无监督。
另一个经验是,如果一个问题有现成的规则,不要完全弃用,也不要追求用机器学习模型彻底替代规则。可以从半自动模型到自动模型进行“升级“,这可以理解为迭代过程。比如在机器学习模型不成熟、数据量不够的时候,仅当模型评分高且符合人为规则时才使用其预测结果,置信度低的预测结果依然使用规则预测或者人为验证。等到数据量和数据质量上去了,再逐步替换或者舍弃人为规则。
升级进化是锦上添花,不是雪中送炭。在商业上,我们告诉客户这叫做“混合系统”Hybrid System,但机器学习上这个叫“主动学习”(active learning)。
4.考虑的数据的依赖性(dependency)
数据往往有时序或者空间上的相关性。如果不考虑时空依赖性,问题往往会得到简化,但可能有严重偏差。如果需要考虑时间与空间上的依赖性,优先从简单的角度入手。
举个简单的例子,图2和图3中的数据如果不考虑时空依赖性,都会导致错误的理解。解决机器学习问题,如果在不确定数据的结构关系时,有限假设不存在依赖。如果效果不好,再换用更复杂的,可以处理依赖性的模型。
5.从回归到分类、从全部数据到部分数据、从连续到离散
5.1. 在特定情况下,因为条件限制,我们的回归模型效果不好或者要求的精度比较低,可以把回归问题转化为分类问题。
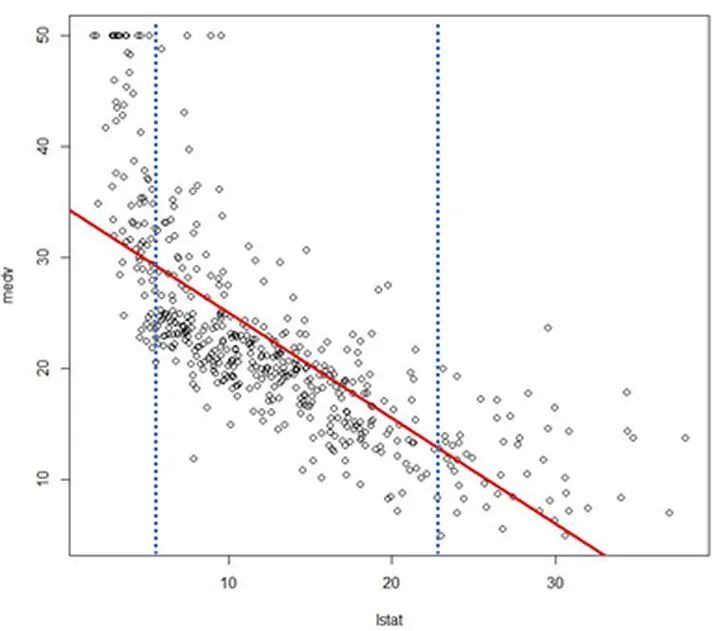
5.2. 同理,如果数据的质量不连贯,我们可以大胆的抛弃掉一部分数据。比如下图中所描述的情况,抛弃掉一部分数据可以增强中间区段的模型拟合能力。当然,由精简数据后得到的模型不该被用于预测抛弃数据段。
5.3. 如果需要,对于特征也可以做离散化。连续变量:变量在特定区间内有无限个可能取值,如股票的价格。离散变量:变量在特定区间内的可选取值有限,比如{红、蓝、黄}三种颜色。从数学角度看,连续变量往往可以被离散化,从而转为离散变量。这种转化可以依赖于固定区间,或者固定密度,甚至是变化的条件。将连续变量离散化适合广义线性模型,如逻辑回归,而不适合树模型或者神经网络。连续特征离散化的优点:
-
降低噪音对模型的干扰,提高鲁棒性。假设一个特征的正常范围是[0,1],那么明显异常的值,如100,不会造成大的扰动 -
在特征离散化以后,模型过拟合的风险一定程度上也得到了降低 -
一般经过转化后,编码可以使用独热编码(one-hot encoding),得到一个稀疏的表示,方便进行矩阵计算
此处的重点是:部分价值 >>毫无价值。将预测范围缩小后,预测效果往往能有大幅度的提高。将数据分割后单独处理,预测效果往往也有提升。而数据离散化可以有效的提高某些模型的能力。
6. 数据比模型更重要,但数据不是越多越好
机器学习模型的表现高度依赖于数据量 [6],选择对的模型至少其次,巧妇难为无米之炊。数据重要性 >> 模型重要性。
但数据不是越多越好,随机数据中也可能因为巧合而存在某种关联。就像上文中提到的虚假相关的例子。Freedman在1989年做过的模拟实验 [5]中发现,即使数据全是由噪音构成,在适当的处理后,也能发现数据中显著的相关性:
-
6个特征显著 -
对回归的做F-test的P值远小于0.05,即回归存在统计学意义
以此为例,统计学检验显著不代表模型真的有意义。一般来说,需要先确认数据的来源性,其次要确认显著的特征是否正常,最后需要反复试验来验证。最重要的是,要依据人为经验选取可能有关的数据,这建立在对问题的深入理解上。
7. 模型选择、评估与调试
模型选择是建立在对于问题的理解上,一般是启发式(heuristic),也就是基于经验所确定的。
-
优先选取符合问题假设的模型。如朴素贝叶斯假设特征间的独立同分布,而逻辑回归就没有这么强的假设 -
优先选取简单模型,循序渐进 -
优先选取对于数据预处理要求低的模型,如可以处理缺失值,不需要进行数值化转化的模型。比如xgboost或者lightbgm等 -
用迭代的思路选择模型,先选择大方向,再微调。在模型选择时可以使用工具包的默认值,确定了大概模型后再进行参数调整
同时,评估模型时,每次仅选择一个标准,比如召回率、ROC或者准确度,同时优化多个目标是很复杂的:
-
可以用 可视化来直观对比算法间的优劣 -
控制模型中的随机性,保证评估有意义,如选用固定的参数(如 random_state=42) -
用相同的数据集来训练、测试不同的模型 -
善用交叉验证,尤其当数据集较小的时候 -
如果有必要,也可以使用统计学检验
除此之外,还需要考虑到运算开销的问题。训练不同的模型运算开销差别很大,要根据资源和时间决定。在资源有限的前提下,可以选择模型表现相对较差但运算开销小的方法。
8. 总结出一套适合自己的“套路”
开始一个机器学习项目以前,值得思考几个“小问题”:
-
确定要预测的目标,找到项目痛点,不追求同时预测多个目标 -
确定解决问题的框架,优先使用监督学习,用无监督发掘新思路 -
结合已有的规则,尝试融合机器学习模型和人为规则 -
如果可能,优先尝试分类任务,也可以尝试将回归转为分类 -
从易到难,确定尝试哪些机器学习模型 -
要解决的问题是否对于“时空”存在依赖性,如果可以回避依赖性,可以先试试简单模型 -
如果发现使用全部数据效果不好,可以尝试抛弃部分数据或分段处理
在做数据工程时,应该考虑到的一些问题:
-
数据并非越多越好,多余的无关特征会因为伪相关、巧合而影响模型 -
对数据做相关性分析的时候,善用可视化可以一目了然的发现问题 -
对于高度相关的特征,移除或者合并前要三思,可能并不会提高模型能力 -
如果选用了线性模型,可能需要对特征进行离散化 -
对于大部分模型来说,归一化或者标准化是必不可少的步骤,至少“无害” -
如果问题较为复杂,尽量选择非线性的鲁棒性强的模型:
在模型选择与评估时,考虑到一些问题:
-
根据要解决的问题和对数据的理解,大致决定出模型的搜索范围,如尝试SVM,逻辑回归,随机森林,xgboost。如资源允许,可扩大模型候选名单 -
根据要解决的问题和对数据的理解,决定模型的评估标准。虽然我们建议选择单一的评估标准进行对比,但推荐计算所有可能的评估标准 -
根据具体问题中的数据量大小,以及模型稳定性,决定是否使用交叉验证 -
结合参数搜索、交叉验证方法,通过选定的评估标准从候选模型中找到表现最好的模型 -
对上一步中的所选模型进行微调 -
迭代以上步骤直到找到最优的模型
还有很多摔过的坑,吃过的苦,有限于篇幅就不展开了。如果只允许我说一条我学到的最重要的经验,那一定是:保持独立思考的能力,不要别人说什么/书上说什么/论文里写什么,你就相信什么。毕竟在机器学习的世界里,我们每个人都是“民科”:)
来源:知乎问答https://www.zhihu.com/question/46301335/answer/317361262
重磅!
Python遇见机器学习交流群已成立!
额外赠送福利资源! 邱锡鹏深度学习与神经网络,pytorch官方中文教程,利用Python进行数据分析,机器学习学习笔记,pandas官方文档中文版,effective java(中文版)等20项福利资源
获取方式:进入群后点开群公告即可领取下载链接
注意:请大家添加时修改备注为
[学校/公司 + 姓名 + 方向]
例如 —— 哈工大+张三+对话系统。
号主,微商等广告请自觉绕道。谢谢!

推荐阅读
•
•
•
•
•
•
•
•
•
•
以上是关于实践中学到的最重要的机器学习经验!的主要内容,如果未能解决你的问题,请参考以下文章
Python 机器学习 | 超参数优化 黑盒(Black-Box)非凸优化技术实践