机器学习笔记 | 第1周(中英混合)
Posted up your sleeve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习笔记 | 第1周(中英混合)相关的知识,希望对你有一定的参考价值。
本文是学习coursera上的吴恩达机器学习课程后的个人学习笔记,其中有些地方个人认为用英语更好理解,或者是不需要翻译成中文,看懂了就行的地方就会直接引用吴恩达教授的阅读材料。
注意:本系列文章主要目标是梳理机器学习中的主要脉络,理解并建立关于机器学习相关重要知识点的大框架,因此部分课程知识点不会全部罗列在文章中。
什么是机器学习(Machine Learning)?
关于机器学习有两种定义,一种是由Arthur Samuel提出的,旧的非正式的定义,另一种是由Tom Mitchell提出的更现代化定义:
"A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E."
E = the experience of playing many games of checkers
T = the task of playing checkers.
P = the probability that the program will win the next game.
机器学习是指一种计算机程序被称为可以从经验E中学习关于某类任务T和性能评估P,如果它使用的任务T性能被P所衡量,那么它将随着经验E的提高而提高。
个人理解,机器学习就是让计算机像人类的学习方式一样进行学习的程序,例如,人类是通过经验感知进而通过理性思考学习到新的知识,所以机器学习就是使用某种算法让计算机可以根据已有的数据学习到某些有用的东西,这个过程中,已有数据称为经验E,学习到有用的东西称为任务T,这个程序它的预测正确的概率,也就是这个程序的学习效果称为P。
通常地,机器学习可以被分为两类,监督学习和无监督学习。
监督学习Supervised Learning
监督学习是指我们数据集中的每个样本都有相应的“正确答案”,再根据这些样本做出预测。监督学习包括回归问题和分类问题。
回归问题是通过回归来推出一个连续的输出(如房价预测),分类问题目标是推出一组离散的结果(如肿瘤与乳腺癌预测)。
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output.
Supervised learning problems are categorized into "regression" and "classification" problems. In a regression problem, we are trying to predict results within a continuous output, meaning that we are trying to map input variables to some continuous function. In a classification problem, we are instead trying to predict results in a discrete output. In other words, we are trying to map input variables into discrete categories.
Example 1:
Given data about the size of houses on the real estate market, try to predict their price. Price as a function of size is a continuous output, so this is a regression problem.
We could turn this example into a classification problem by instead making our output about whether the house "sells for more or less than the asking price." Here we are classifying the houses based on price into two discrete categories.
Example 2:
(a) Regression - Given a picture of a person, we have to predict their age on the basis of the given picture
(b) Classification - Given a patient with a tumor, we have to predict whether the tumor is malignant or benign.
无监督学习Unsupervised Learning
无监督学习中我们已知的数据是没有任何标签,只是一个单纯的数据集,问如何从数据中找到某种结构。
针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。这是一个,那是另一个,二者不同,无监督学习算法可能会把这些数据分成两个不同的簇,这就叫聚类算法。聚类算法是无监督学习中最经典的算法。
简单来说,无监督学习就是最原始的数据集,通过学习算法找出这些数据中隐含的特征。它并不提供数据的预测结果。
Unsupervised learning allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don't necessarily know the effect of the variables.
We can derive this structure by clustering the data based on relationships among the variables in the data.
With unsupervised learning there is no feedback based on the prediction results.
Example:
Clustering: Take a collection of 1,000,000 different genes, and find a way to automatically group these genes into groups that are somehow similar or related by different variables, such as lifespan, location, roles, and so on.
Non-clustering: The "Cocktail Party Algorithm", allows you to find structure in a chaotic environment. (i.e. identifying individual voices and music from a mesh of sounds at a cocktail party).
单变量线性回归
Model Representation模型表述
对于只有一个特征/输入变量的问题称为单变量线性回归问题,它的假设函数形式如下:
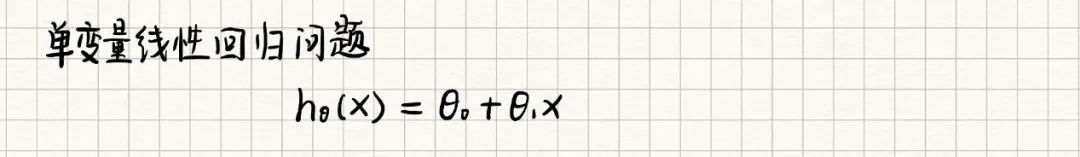
Cost Function 代价函数
我们使用代价函数来衡量假设函数的精确度,即通过求假设函数计算的y值和实际y值的平均差。这个函数又可以称为平方误差函数或是平方误差函数(MSE)。
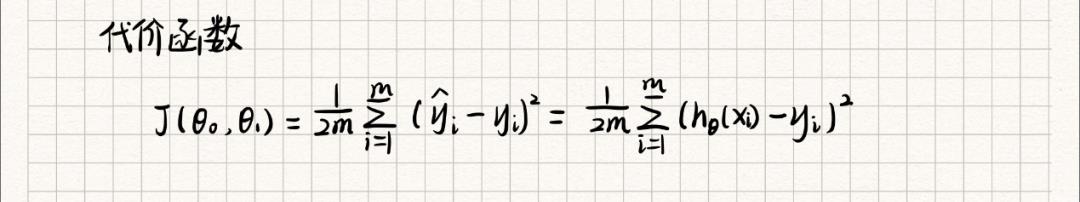
梯度下降
前面已经提到了代价函数就是通过计算假设函数预测的y值和实际y值之间的平均差,所以代价函数值越小,就说明我们的假设函数预测结果越好,因此,我们的目标就是要求一个最小的代价函数值。
那么,应该怎么去求呢?因为代价函数值其实是与参数值选取有关,所以,我们要求的问题就是选取合适的参数使得代价函数值最小。
其中一个方法就是使用梯度下降法。它是一个用来求函数最小值的算法,具体思想为随机选择一个参数的组合,计算代价函数,然后寻找下一个能让代价函数值下降最多的参数组合。持续这么做直到找到一个局部最小值(local minimum)。
注意,在使用梯度下降算法时,参数的更新是同步更新的。
梯度回归的线性回归
线性代数回顾(比较基础,略)
以上是关于机器学习笔记 | 第1周(中英混合)的主要内容,如果未能解决你的问题,请参考以下文章