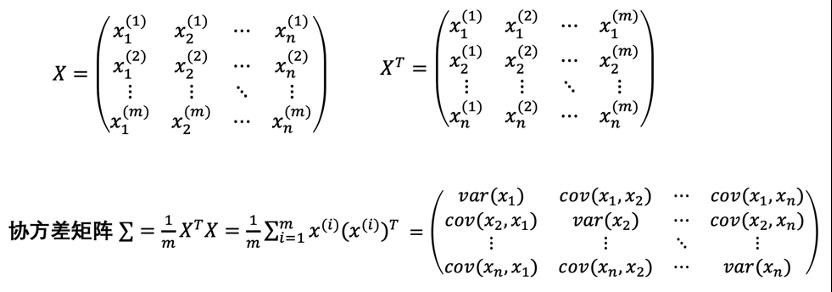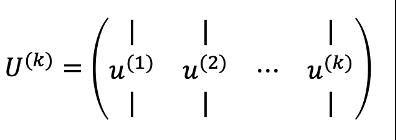机器学习丨PCA降维的经典算法
Posted 爱数据原统计网
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习丨PCA降维的经典算法相关的知识,希望对你有一定的参考价值。
在机器学习的领域中,我们对原始数据进行特征提取,经常会得到高维度的特
征向量。
在这些多特征的高维空间中,会包含一些冗余和噪声。
所以我们希望通过降维的方式来寻找数据内
部的特性,提升特征表达能力,降低模型的训练成本。
PCA是一种
降维的经典算法,属于
线性、非监督、全局
的降维方法。
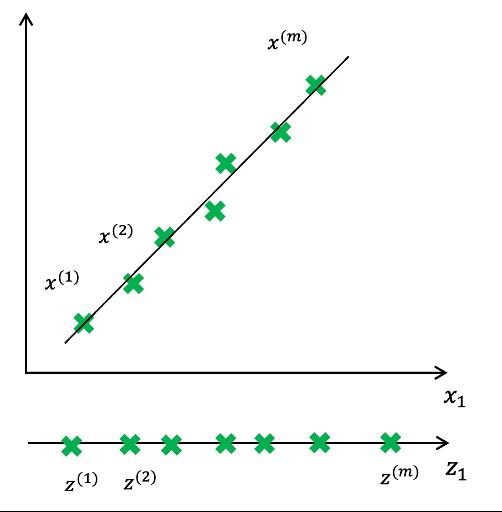
PCA的原理是线性映射,简单的说就是将高维空间数据投影到低维空间上,然后将数据包含信息量大的主成分保留下来,忽略掉对数据描述不重要的次要信息。
而对于正交属性空间中的样本,如何用一个超平面对所有样本进行恰当合适的表达呢?若存在这样的超平面,应该具有两种性质:
所有样本点到超平面的距离最近
样本点在这个超平面的投影尽可能分开
以上两种性质便是主成分分析的两种等价的推导,即PCA最小平方误差理论和PCA最大方差理论,本篇主要为大家介绍最大方差理论。
PCA的降维操作是选取数据离散程度最大的方向(方差最大的方向)作为第一主成分,第二主成分选择方差次大的方向,并且与第一个主成分正交。不算重复这个过程直到找到k个主成分。
数据点分布在主成分方向上的离散程度最大,且主成分向量彼此之间正交;
对样本进行平移使其重心在原点,并且消除不同特征数值大小的影响,转换为统一量纲:
协方差是对两个随机变量联合分布线性相关程度的一种度量;
② 数据点在特征向量上投影的方差,为对应的特征值,选择特征值大的特征向量,就是选择点投影方差大的方向,即是具有高信息量的主成分;次佳投影方向位于最佳投影方向的正交空间,是第二大特征值对应的特征向量,以此类推;
4、选取k个最大大特征值对应的特征向量,即是k个主成分
U是协方差矩阵所有的特征向量构成的矩阵,对应的特征值满足:λ1>λ2>⋯>λn,同时使其满足在主成分向量上投影的方差和占总方差的99%或者95%以上,即确定了k的选取。
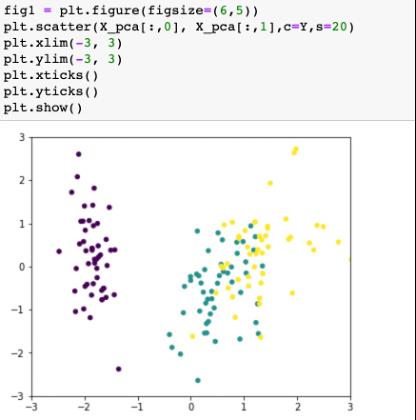
3、读取特征、标签列,并进行中心化归一化,选取主成分个数,前2个主成分的方差和>95%
4、将降维后特征可视化,横纵坐标代表两个主成分,颜色代表结果标签分类,即可根据主成分进行后续分析、建模
以上PCA主成分分析就讲完了,本文进行了样本点在超平面的投影尽可能分开的推导原理阐述,大家感兴趣的可以研究另一种等价推导,即样本点到超平面的距离最近。
![机器学习丨PCA降维的经典算法]() 爱数据原统计网推荐搜索
爱数据原统计网推荐搜索