机器学习如何增强“客户细分”?
Posted 知否问答
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习如何增强“客户细分”?相关的知识,希望对你有一定的参考价值。
点击蓝字
营销团队必须解决的主要挑战之一是以最小化“每次获得成本”(CPA)并增加投资回报率的方式来分配资源。通过细分,即根据客户的行为或特征将客户分为不同组的过程,机器学习可以做到这一点。
对于商家来说,似乎优点颇多。
客户细分可以帮助减少营销活动中的浪费。如果知道哪些客户彼此相似,则可以更好地将广告系列定位到合适的人群。
客户细分还可以帮助完成其他营销任务,例如产品推荐,商品定价和制定销售策略。
客户细分以前是一项艰巨且耗时的任务,需要数小时的时间手动浏览不同的表并查询数据,以期待找到将客户分组的方法。但是近年来,由于机器学习和人工智能算法可以发现数据的统计规律,因此客户细分变得更加容易。机器学习模型可以处理客户数据并发现各种功能的重复模式。在许多情况下,机器学习算法可以帮助市场分析师找到通过直觉和手动检查数据很难发现的客户群。
客户细分是人工智能和人类直觉相结合如何创造出大于其各个部分总和的完美示例。
k均值聚类算法
机器学习算法具有不同的风格,每种都适合特定类型的任务。在适合客户细分的算法中,有k均值聚类。
K-均值聚类是一种无监督的机器学习算法。无监督算法不需要真实值或标记数据来评估其性能。k均值聚类背后的想法非常简单:将数据排列到更相似的聚类中。
例如,如果客户数据包括年龄,收入和支出得分,则配置良好的k均值模型可以帮助将客户分为属性相互靠近的组。在这种设置下,集群之间的相似性是通过计算客户的年龄,收入和消费得分之间的差异来衡量的。
训练k均值模型时,可以指定要将数据划分为的簇数也就是k值。该模型从随机放置的质心开始,质心确定每个群集的中心。该模型将遍历训练数据,并将其分配给质心更接近它们的聚类。对所有训练实例进行分类后,将质心的参数重新调整为位于其聚类的中心。重复相同的过程,将训练实例重新分配给微调的质心,并根据数据点的重新排列对质心进行重新调整。某一时刻,模型将收敛,对数据进行迭代将不会导致训练实例切换群集和质心改变参数。

确定正确的客户群数量
成功使用k均值机器学习算法的关键之一是确定聚类的数量。尽管模型可以在您提供的任意数量的群集上收敛,但并非每种配置都适用。在某些情况下,数据的快速可视化可以揭示模型应包含的群集的逻辑数量。例如,在下图中,训练数据具有两个特征(x1和x2),将它们映射到散点图上会发现四个易于识别的群集。
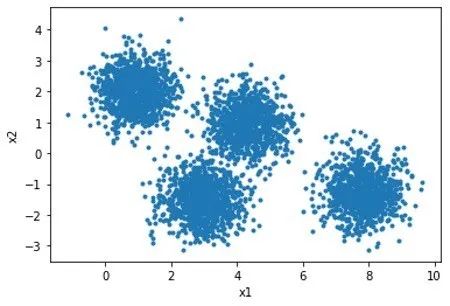
当问题具有三个特征(例如x1,x2,x3)时,数据在3D空间中可视化,因为在3D空间中很难发现集群。除了三个特征之外,不可能可视化一幅图像中的所有特征,并且您需要使用其他技巧,例如使用散点图矩阵来可视化不同特征对的相关性。
可以帮助确定群集数量的另一个技巧是降维,这是一种机器学习技术,可以检查数据点中的相关性并删除虚假的或包含较少信息的特征。降维可以简化问题空间,并使查看数据和发现聚类机会变得更加容易。
但是在许多情况下,即使使用上述技术,簇的数量也不明显。在这些情况下,必须尝试不同数量的群集,直到找到最佳群集为止。
但是,如何找到最佳K值?可以通过惯性来比较K均值模型,惯性是指群集中的实例与其质心之间的平均距离。通常,惯性较低的模型更连贯。但是仅靠惯性还不足以评估机器学习模型的性能。增加簇的数量将始终减少实例与其簇质心之间的距离。而且,当每个实例成为其自己的群集时,惯性将降为零。当然,我们不希望拥有一个为每个客户分配一个集群的机器学习模型。
一种找到最佳簇数的有效技术是肘方法,您可以逐渐增加机器学习模型,直到找到添加更多簇不会导致惯性显着下降的地步。这被称为机器学习模型的弯头。肘部方法通过比较添加群集与减少惯性的方式,找到了k均值机器学习模型的最有效配置。
使用k均值聚类和客户群
经过训练后,机器学习模型可以通过测量新客户到每个群集质心的距离来确定新客户所属的细分市场。有很多领域可以使用它。
例如,当获得新客户时,希望向他们提供产品推荐。训练好的机器学习模型将帮助确定客户的细分市场以及与该细分市场相关的最常见产品;在产品营销中,聚类算法将帮助重新调整广告系列。例如,可以从属于不同细分市场的随机客户样本开始一个广告系列。投放广告系列一段时间后,可以检查哪些细分受众群的响应速度更快,并优化广告系列,使其仅针对那些细分受众群的成员展示广告。或者,可以运行广告系列的多个版本,并使用机器学习根据客户对不同广告系列的响应对客户进行细分。
K-均值聚类是一种快速有效的机器学习算法。但它不是魔术棒,它可以快速将数据转变成合理的客户群。必须首先定义营销活动的设置以及与之相关的功能类型。例如,如果广告系列定位于特定的区域,则地理位置将不是一个相关功能,因此最好过滤该特定区域的数据。
在某些情况下,可能希望包括其他信息,例如他们过去购买的产品。在这种情况下,将需要创建一个客户产品矩阵,该表以客户为行,项目为列,以及在每个客户和项目的交点处购买的项目数。如果乘积的数量太多,则可以考虑创建一个embedding,其中乘积以多维矢量空间中的值表示。
总体而言,机器学习是营销和客户细分中非常有效的工具。它可能不会很快取代人类的判断力和直觉,但可以帮助将人类的努力扩大到以前不可能的水平。
关键词 机器学习 客户细分 k均值聚类算法
欢迎关注 知否问答 推送新鲜科技,直连趣味技术,展示创意想法,呈现稀罕观点
以上是关于机器学习如何增强“客户细分”?的主要内容,如果未能解决你的问题,请参考以下文章