道富:机器学习选股,能信吗?
Posted 量化投资与机器学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了道富:机器学习选股,能信吗?相关的知识,希望对你有一定的参考价值。
编译:QIML编辑部
解读介绍
希望大家能有收获
数据和方法
我们最终的目标是构建投资组合,所以我们用机器学习的模型去预测股票未来的收益率,然后基于预测的收益率高低,再选择股票构建投资组合。
输入-因子(X)
股票:出于流动性的考虑,我们选取了标普500成分股
时间范围:1992年12月-2020年9月
输入变量(X):主要基于公司特征及市场环境两个维度选取了多个指标,如下表1,为了避免异常值的影响,我们把除行业属性以外所有的指标转换成了横截面的排序值。
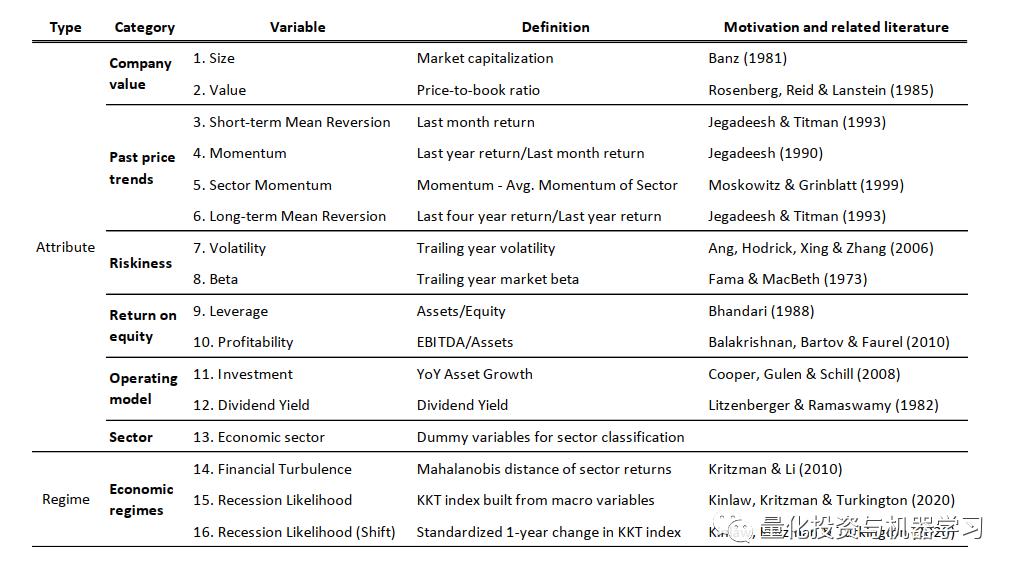
输出-目标(Y)
我们尝试了多种不同的预测目标:
1、每只股票下个月的绝对收益率;(作为基准模型)
2、基于CAMP模型的超额收益率;
3、基于六因子模型(Fama五因子及动量因子)的超额收益率;
在以上2、3的超额收益了计算时,我们使用过去1年的滚动时间窗口。
模型和训练
按照模型的复杂度,分别选取了以下模型:
1、OLS
2、LASSO
3、Random Forest
4、Boosted Trees
5、Neural Network
训练集:1992-2014
测试集:2015-2020
什么是Model Fingerprints?
Li et al.(2020)提出了基于Model Fingerprints(以下简称MF)解释机器学习模型的框架。MF能够量化出每个变量及变量的相互作用对模型预测效果的贡献。在MF的框架下,一个模型的预测效果被切分为以下几个部分来解释:
1、Linear Prediction Effect: 各个因子线性部分的贡献(如x1,x2)
2、Nonliear Prediction Effect: 各因子非线性部分的贡献(如x1的平方)
3、Interaction Prediction Effect:各因子之间相互作用的贡献(如x1*x2)
关于Model Fingerprints的具体解释,我们会基于Li et al.(2020)的论文在下一篇推文中,详细介绍。
基准模型的测试结果
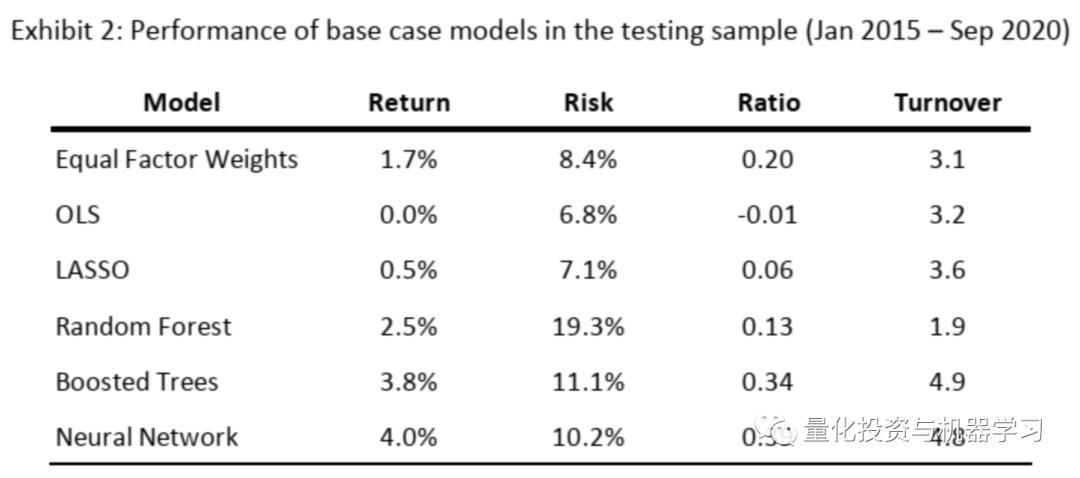
在这一小节,我们来看一下基准模型的测试结果,我们首先用1992-2014年的数据对模型进行训练,一旦模型确定后,在测试集中并不对模型的参数进行修改。在测试数据中,每个月根据模型的预测结果,做多前20%的股票,同时做空后20%的股票。每个股票的权重设置为等权。
表2中给出了不同模型的测试效果。其中‘Equal Factor Weights’模型是仅对表1的12个公司特征的因子(不包括行业属性因子)求滚动均值后并等权加权后进行排序选股的模型。尽管该模型非常简单,但它的表现还是大幅优于OLS和LASSO等线性模型。对于其他更复杂的模型,Random Forest有着最低的换手率和最高的风险,但相比线性模型,Random Forest更能发现不同因子子集所带来的增量信息。而Boosted Trees和neural networks的整体效果最优,但换手也更高,主要是因子这两类模型能够发现不同因子间非线性及相互结合带来的增量信息。
解释
我们现在运用ML的方法解释各个模型的结果,我们没有给出线性回归模型的ML分析,因为线性回归模型的ML全部来自于因子的线性关系,对于非线性和因子间的交互作用(Interactions)都为0。还有需要注意的是,以下的分析结果都来自于训练数据集。
Boosted Trees和Neural Network学到的线性信息比较相似,大部分来自Value和Momentum两个因子。而Random Forest学习到的线性信息大部分来自于Volatility和Beta这类偏风险的因子。Boosted Trees能够学习到更多的非线性信息,而Neural Network则能学到最多的因子交互作用带来的信息。我们也可以发现Turbulence、Recession这类市场环境类的信息,本身带来的线性及非线性信息比较有限,主要是跟其他因子发生交互作用后带来的增量信息(如Neural Network中所示)。
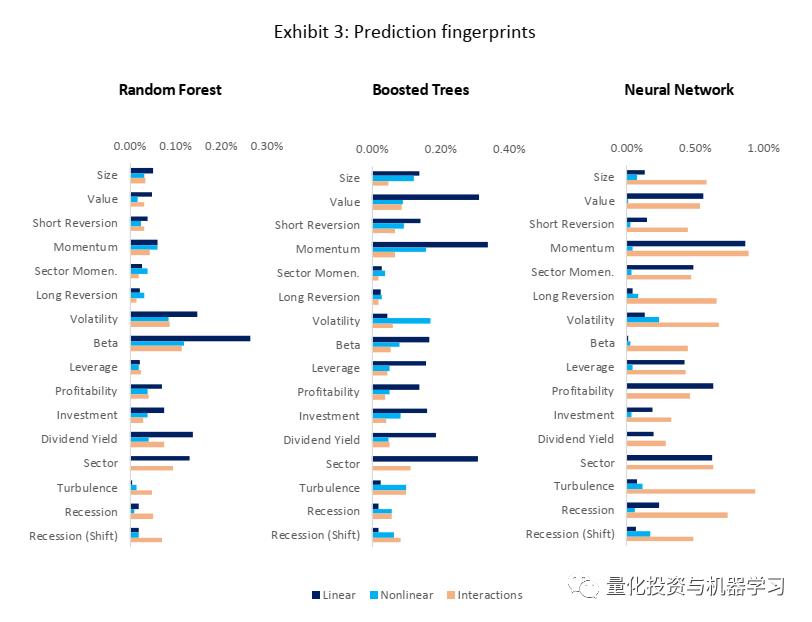
以上结果也显示,Short Reversion(短期反转)的因子的效果并不是特别有效,这与Gu et al.(2000)的结果有很大的区别,一个比较可能的原因是短期反转的因子在小市值的股票上有更明显的效果,但本次测试的股票池是标普500,所以从可投资性的角度,短期反转比不是一个有效的因子。
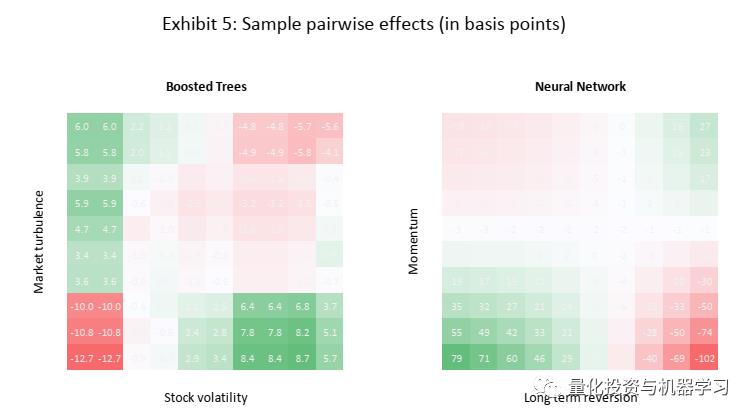
我们继续探索因子间的交互作用带来的有效增量信息,表4分别给出了三个模型最有效的三个因子交互的组合。Random Forest主要结合了Recession和beta、Volatility。Boost Trees和Neural Network都主要结合了Turbulence和常用的Size、Value及Momentum等因子。

通过下图5我们也可以发现,在市场波动较大时,Boosted Trees更青睐于低波动的股票,当市场波动低的时候更青睐高波动的股票。从右图可以看出,Neural Network非常坚定的选取低Momentum,高Long Reversion的股票。
下图6,左右分别展示了Neural Network模型构建的组合,在测试及训练样本中分别来自线性、非线性及交互作用的收益(加总起来就是总收益)。在测试集中,收益主要来自于非线性及交互作用,且两者之间在关键时刻有对冲的效果,平滑了整体收益。而在测试样本中,线性的收益表现与训练集中有很大的差别,说明线性的超参数在测试集中已经不再有效。
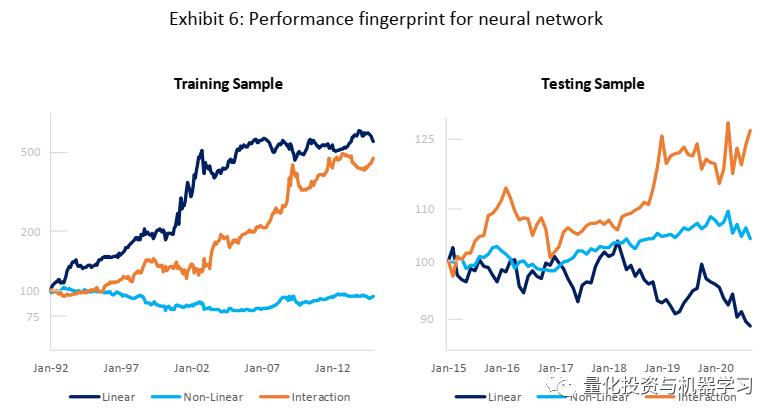
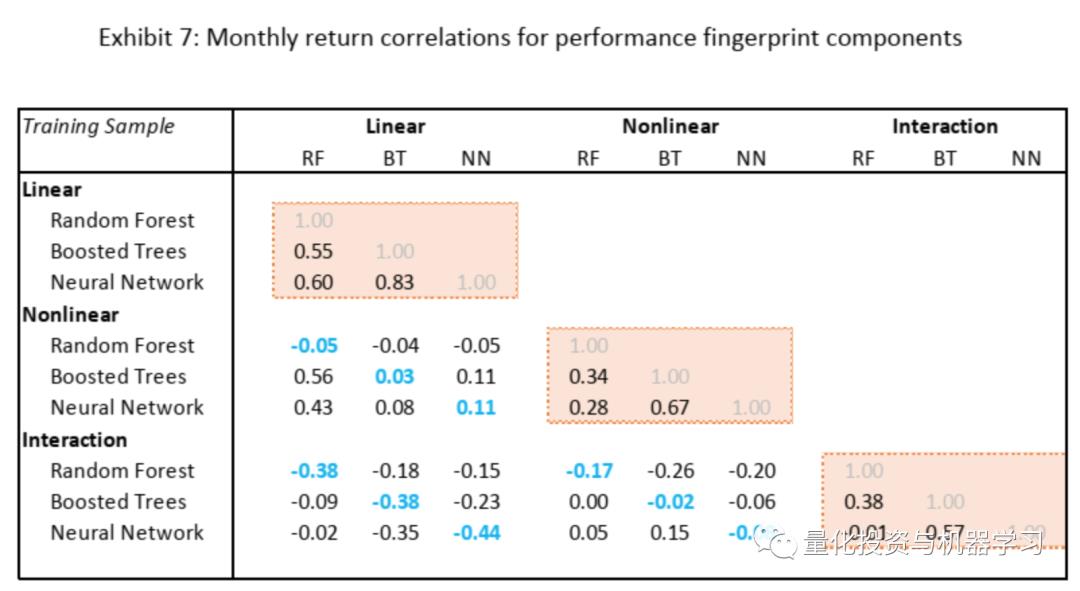
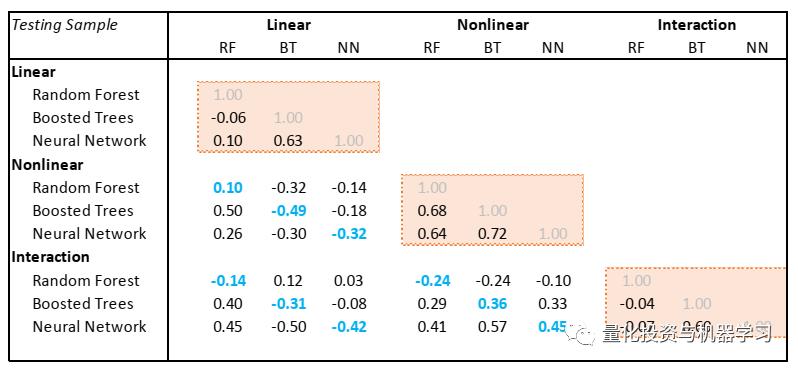
表7展示了各个模型,线性、非线性及交互作用各部分收益之间的相关性。我们可以发现在训练集内,所有三个模型线性收益部分的相关性都非常高。Booted Trees和Neural Networks的非线性及交互部分的收益率相关性也比较高。说明这些模型选了许多相同的股票,或至少具有相似特征的股票。而对于每个模型,非线性(及交互作用)与线性部分的相关性大部分(除了Random Forest)都为负的,说明非线性及交互作用多多少少扮演了线性部分对冲的角色。
不同预测目标的测试结果
不同的预测目标的设定,代表了不同的策略逻辑。比如我们不相信市场择时,那我们就可以将预测目标从总收益变为超额收益。或者我们不希望有过多的交易成本,那么预测的目标也可以从短期收益切换为长期收益。接下来,我们看一下,不同预测目标下模型的效果有什么变化。
我们使用了两种不同的超额收益的定义:CAPM及六因子模型;同时也采用了两个不同的预测时间:1个月和12个月。从下图(8)可以发现,在样本外测试集中,Equal Factor Weights模型中,以12个月Total Return为预测目标的模型表现最佳。对于其他模型,都是以1个月的CAPM超额收益为预测目标的模型表现最佳。相比较简单的线性模型,复杂的机器学习模型整体的表现都比较领先。但相比要与其他论文,这个领先的幅度并不是特别大。最主要的原因,是我们对模型增加了可实施及可解释性的约束。
下图给出了基于12个月CAPM超额收益预测目标的各模型的MF分析,Neural Network能够更多的挖掘因子间的Interaction。比如Momentum在Random Forest与Boosted Trees中收益的贡献不显著,但在Neural Network模型中,其Interaction部分贡献了很大收益,说明动量因子大部分情况下需要和其他因子进行结合才能发挥作用。
总结
从一个投资者的角度,复杂的模型必须是可投资、可解释且有意义的。基于这个出发点,此次实证研究做了以下限制,首先是基于流动性高的标普500成分股进行选股,其次输入的变量也局限在有实际可解释意义的因子中。最后我们用MF的方法去解释各个因子在模型收益的贡献。只有清楚的知道收益的来源,及模型的逻辑我们才能放心的在实际投资中进行应用。
内容:
INVESTABLE AND INTERPRETABLE MACHINE LEARNING FOR EQUITIES
参考文献:
Li, Y., Turkington, D. and Yazdani, A., 2020. “Beyond The Black Box: An Intuitive Approach to Prediction with Machine Learning.” The Journal of Financial Data Science, Vol. 2, No. 3
以上是关于道富:机器学习选股,能信吗?的主要内容,如果未能解决你的问题,请参考以下文章