自动驾驶的智慧之眼——感知
Posted 智车科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动驾驶的智慧之眼——感知相关的知识,希望对你有一定的参考价值。
本文从行业现状、常用传感器、深度学习与感知、展望四个方面详细解析自动驾驶感知环节。
自动驾驶感知的实现需要软硬件结合,本文从传感器和算法的角度带大家来了解一下自动驾驶的感知。首先看一下自动驾驶目前的行业现状。
行业现状
自动驾驶是目前发展最为迅猛的产业之一,十年之前,消费者就接触过“定速巡航(ACC)”这个功能,而现在ACC功能几乎成为量产车型的标配。目前量产乘用车市场正在专注于L2.5或L3功能的实现,如车道居中辅助(LKA)、主动紧急制动(AEB)、交通拥堵辅助(TJA);而创业公司和研究机构则专注于L4或L5等级的技术研发,并且也取得了非常大的进展,如全自动代客泊车、点到点的无人驾驶出租车、仓库到仓库的无人驾驶货车等。
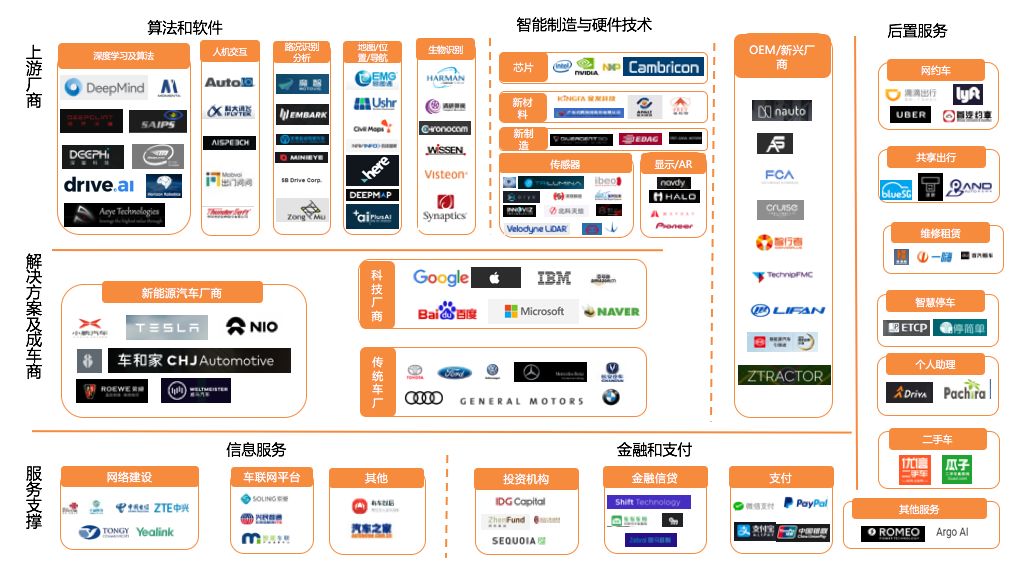
(该图片来源于创业邦)
自动驾驶迅猛发展的背后到底有哪些力量在推动呢?
两个方面:一是消费者的诉求;二是科技的发展。
首先看消费者的诉求
汽车已经越来越融入到老百姓的生活中,行车安全是消费者最为关心的问题之一,目前老年人占据了用户人群的一大部分,已经变的越来越不能忽视,有调查报告指出有93%的交通事故都是由人为操作失误引起,由此可见,消费者尤其是操作不够灵活的老年人群体对行车安全的诉求越来越强。另外车辆是一个安全舒适的生活延伸,不再是让人疲惫不堪的驾驶环境,车辆的智能化可以使消费者从驾车中解放出来。
再来看科技的发展,科技的发展包括硬件和软件的发展
首先硬件性能得到了全面提升。一方面,芯片算力能耗比巨幅提升。前几年,芯片算例不足或是能耗太高,导致用在车上时实时性很难保证,因此这成为了智能汽车发展的重要瓶颈,最近芯片行业已经得到了大力的发展,以Mobieye为例,从2010年发布eq1平台到今年发布eq4平台,提出eq5平台。8年时间,他们芯片每瓦的算力提升了80多倍,给无人驾驶技术的发展提供了无限的可能。另外,传统传感器得到优化,新型传感器不断研发。传统传感器如摄像头、毫米波雷达、超声波雷达,或新型的传感器如激光雷达等。在性能提高的同时,它们的制作成本也控制的越来越好。
芯片和传感器性能的提升为自动驾驶的快速发展做好了充分的准备。
其次软件算法不断推陈出新。提到软件,不得不提深度学习,深度学习相比于传统的机器学习,很好的实现了端到端感知。有业内人士形象的形容深度学习的感知:只需要给自动驾驶系统一张封面的图像,它就能反馈出方向盘这时候有个转角。当然这个形容有待讨论,但是不得不说深度学习的出现对自动驾驶系统所要求的自动化、一体化的完整性都带来了很大的帮助。
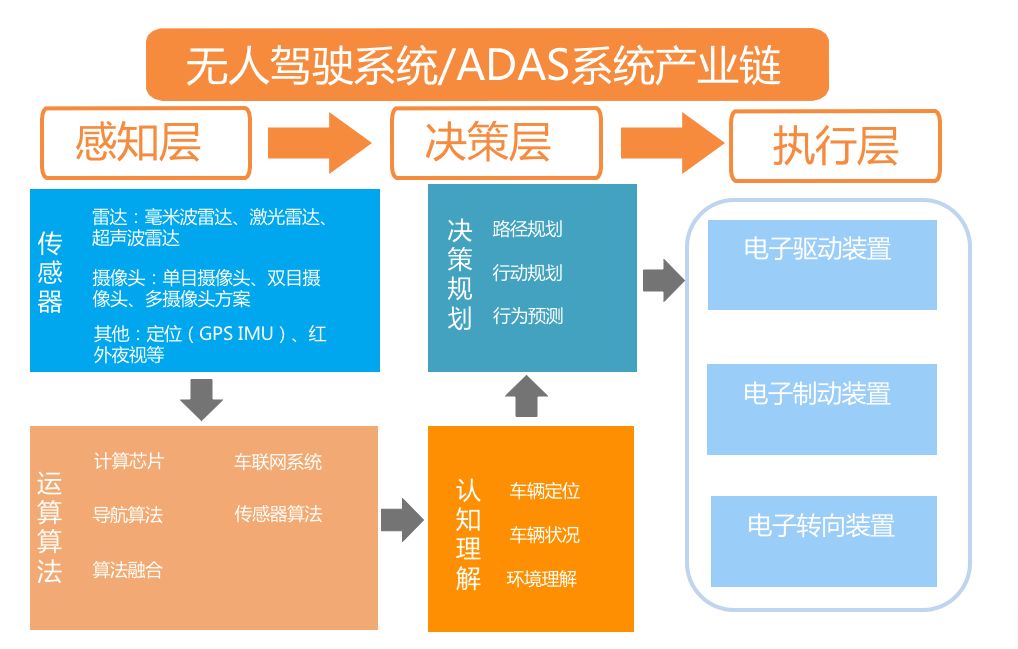
感知是自动驾驶的第一环,是车辆和环境交互的纽带。一个自动驾驶系统的整体上表现好坏,很大程度上都取决于感知系统的做的好坏。
讲到感知,首先不得不讲到传感器。传感器是自动驾驶感知环节中最主要的工具,我们必需对传感器能够提供的数据类型、适用的工况以及局限性都非常了解和熟悉,才能让算法工程师更好的适配传感器所采集和提供的数据写出更好的算法,自动驾驶的传感器主要分为以下四种。
常用传感器简介

高清摄像头
摄像头一般提供的RGB数据,没有深度信息,虽然可以利用双目摄像头做一些深度信息,或者用算法基于单目摄像头做一个深度信息的融合,但是在实际使用过程中误差是很大的,而且单目摄像头在每次使用前都需要做一次标定,非常麻烦,因此业界一般只使用摄像头的RGB的信息。
摄像头有两个比较重要的参数信息,一个是解析度,解析度越高,能提供的细节信息越多;另一个是FOA,FOA直接决定了自动驾驶的摄像头感知视野的宽窄。
摄像头工作的时候,对光照的条件要求比较高,需要一个好的稳定的光照条件,那什么是不好的光照条件呢?举个例子,当载有摄像头的车辆进入隧道的时候,曝光不足,出隧道的时候会发生曝光过度,如此一来,呈现画面上就没有太多的细节信息,这就对于感知算法来说会造成很大的困扰。
目前基于摄像头的感知已经发展的比较成熟,比如特斯拉的Autopilot,它的车道线识别是完全基于摄像头来做的,并且在很多的工况下都会有很好的表现。
毫米波雷达
毫米波雷达是一个基于多普勒效应的传感器,它可以检测物体的距离、距离变化率和放向信息,毫米波雷达原始数据采用的是极坐标,因此它的速度是镜像的速度,优势是对雨、雾、灰尘等的穿头性特别强,而且因为工作原理不会受到光照条件的影响。因此毫米波雷达是一个可全天时工作的传感器。
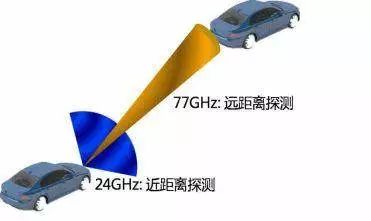
毫米波雷达的主要参数是频率,频率越高,探测距离就会越远,主要频率是24GHZ和77GHZ,目前也有公司在研发79GHZ频率的毫米波雷达;频率越高的另一个好处是带宽就会越大,分辨率就会越好,分辨率定义为,比如说我这边有两个物体,这两个物体隔开多远毫米波雷达就会认为它们是两个物体。比如像24GHZ的分辨率为60厘米左右,77GHZ的分辨率可以到20厘米左右。像77GHZ的远距离探测的毫米波雷达一般放在车前保险杠附近,作用是对前方障碍物的检测;24GHZ的毫米波雷达一般会放在汽车的左右侧或后侧,主要做盲区的检测。
毫米波雷达简要总结:
数据类型
距离、径向速度、方位
采用极坐标
主要参数
频率高——探测距离远
频率高——带宽大,分辨率好
适用工况
穿透雾、烟、灰尘能力强
具有全天候、全天时特点
主要应用
盲区监测——变到辅助
前车车距监测——ACC、AEB
超声波雷达
超声波雷达的测量原理其实非常简单,主要通过测量发出超声波到超声波碰到物体弹回来接收后的时间差来计算物体与车辆之间的距离。
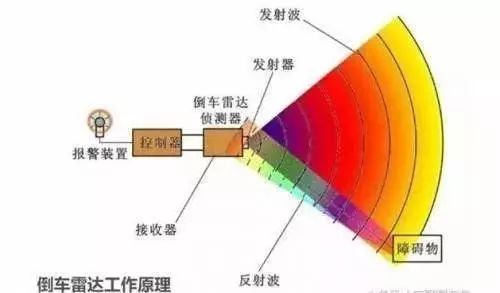
基于此原理会带来一些误差,因为这样传播的介质是空气,我们知道空气在不同的天气条件(如雨、雾天等)下,对超声波传播的波速都有影响,而且超声波雷达传播的波速本身就比较慢,因此在车辆高速行驶的时候,它测量的实时性会比较差,而且如果测量距离较远的情况下超声波雷达的回拨信号较弱,就会带来一系列的问题,一方面是误差大、另一方面是方向性的信息会比较糟糕。
超声波雷达的好处是体积小、售价低,因此超声波雷达一般会被用在低速、短距离的场景下使用,如倒车。
超声波雷达总结
数据类型
与障碍物的距离
主要参数
频率高——灵敏度高,但FOV小
适用工况
短距离低速测距(0.1-3米)
距离远——误差大、方向性不佳
车速高——波速慢,实时性差
主要应用
低速短——距倒车雷达
激光雷达
激光雷达它的数据是点云数据,是可以描绘3D信息的点云数据。点云是一个一个点,每个点都有自己(x,y,z)的空间坐标信息,还有它的反射率和方向的信息。

激光雷达有两款形式分为固态激光雷达和机械式激光雷达。它们的区分主要看激光发射器是固定的还是运动式的。
传统的机械式激光雷达是把激光发射器和接收器安装在一个装置上,该装置是可以整体旋转的,每旋转一圈就会完成对周围信息的一次扫描,缺点是体积较大、活动的部件较多,因此它的使用寿命较低和也不好维护,另一个缺点是机械式激光雷达在出厂的时候发射点再出厂的时候就已经做在里面的,因此角分辨率后期不能通过一些算法去做调整。

机械式激光雷达
相比之下,固态激光雷达的出现就很好的解决了这方面的问题。固态激光雷达的发射源和接收器都是固定在一个装置内不动的,它会通过一系列的方法把激光导向空间的各个方向,实现对周围空间的扫描,方法一般分为Flash、OPA和MEMS。

固态激光雷达
Flash激光雷达目前还处在研究的初步阶段,我们可以把它想象成一个探头,往四周各个方向发射,并且接收各个方向返回来的激光信号,这样的原理会自身存在固有的一些问题,比如它的能量会随着距离的增加衰退的非常快,所以有效监测距离一般只在小几十米左右。但是如果加大它的能量就会对人眼造成伤害。目前激光雷达的工程样机都非常少,还处在初步的阶段。
OPA激光雷达是相控阵原理,它是做了非常多的激光发射头,把激光发射头排列成一个阵,然后我们通过调节不同激光发射头在发射激光的时候的相位差,实现激光方向的导向。 OPA运用相干原理(类似的是两圈水波相互叠加后,有的方向会相互抵消,有的会相互增强),采用多个光源组成阵列,通过控制各光源发光时间差,合成具有特定方向的主光束。然后再加以控制,主光束便可以实现对不同方向的扫描。
MEMS激光雷达在激光发射头前面做了很小的一个微震的镜片,通过这个镜片的旋转抖动把激光导向各个方向。
现在业界OPA和MEMS都是比较成熟的激光雷达解决方案,目前它们的角分辨率最好的目前已经可以做到0.01°。
受益于工作原理,激光雷达受雨天、雾天、雾霾天的影响是比较小的。虽然在雨天虽然在点数上会有一些点的缺失,在雾霾天时,空间上会有一些噪点,但是都可以通过一些简单的算法把这些问题解决。激光雷达在自动驾驶中扮演了非常重要的角色。
激光雷达小总结:
固态激光雷达
工作原理:激光的发射源和接收器固定,采用Flash、OPA、MEMS的方法控制激光束方向,进行空间扫描。
特点
体积较小
角分辨率较高可达0.01°
角分辨率与扫描频率可调
探测距离一般,约100米
横向FOV较小,约100米
机械式激光雷达
工作原理:激光的发射源和接收器都固定在一个部件上整体旋转
特点
体积一般较大
活动部件多,工作寿命不佳
角分辨率不高,约0.9°,且不可调
探测距离较远,约200米
可360度全方位扫描
数据类型
(x,y,z,r)点云数据
主要参数
角分辨率-点云更稠密,更能体现物体特征
有效探测距离
扫描频率
适用工况
不收光照条件影响,全天时
非极端气象条件均可用
主要应用
目标识别与分类、目标跟踪
可行驶区域分割、车道线识别
SLAM高精自定位
说完传感器,接下来我们就要想办法从传感器中提取到对我们有用的信息,这个时候就是算法需要登场的时候了。说到算法,这里重点讲一下深度学习。
深度学习与感知
深度学习可以实现端到端的感知效果。什么叫端到端?

举个例子,比如说我这边有张图,我们想做一个抠图,把图上的一个人抠出来,传统的CV的方法,无论是基于图割、最小割还是随机场的算法,都需要标一下这张图的前景还有后景分别是什么,而且跑完算法之后会发现算法分错了还得需要提供额外的信息进一步区分前景和后景,这就说明算法在运行的时候需要进行非常多的人为干预;然而深度学习可以被理解为全自动的算法,可以在没有人干预的情况下完成一个算法的流程,这是深度学习相较于传统机器学习最大的优势所在。
深度学习的模型是由不同的计算层构成的,所谓的计算层是由自身的一个参数,它把自身的参数和收到的数据做一个简单的数学计算,然后再把计算结果传输给下一层,这就完成了这一层的工作,每一层都有不同的职责,比如说,直观解释来讲,像卷积层,可以理解为它是把图像信息做了一个提取;像池化层,它是数据做了一个降维处理,保留了有效的信息,同时把数据的体积做了一个剪裁;像激活层,可以理解为对有效信息的一个过滤,它把无效信息给滤走,它是模仿人脑的神经元,对数据的非线性的计算处理;像全连接层,大家可以理解为,把之前提取的高层的信息做了一个整合,帮助模型做整个判断。
深度学习是有监督学习的一种,说到训练,就要看两个东西,一个是叫做ground-truth,是我们希望模型达到的最理想值;还有一个就是提供给它的数据。
我们是如何训练的呢?我会通过比较ground-truth和这个模型自己计算出的一个结果,我们会量化的计算一个误差值,这个误差值就是我们的一个损失值,我们通过调整模型的参数把这个损失值降到最低就会完成模型的一个训练。
那如何调整参数呢?我们可以想象一下一个凹函数它是由很多自变量构成,它的因变量就是损失值,把损失值往零去优化的一个方法就是梯度下降的方法,这也是深度学习中优化每一层的方法。
那深度学习有很多层,层与层之间是如何优化的呢?这时候我们就会采用偏微分里面的一个链式法则,把每一层的梯度不断地往前传,这样一个链式的流程就会实现反向传播深度学习的训练。
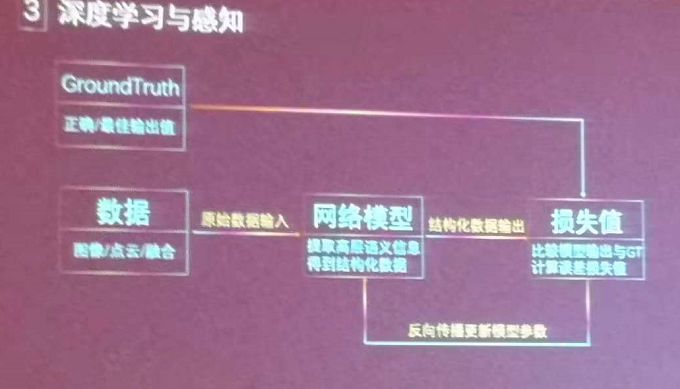
深度学习为什么可以做到端到端的模型?因为数学的输入量和最终的输出量是可以做自己的自定义的,从数据的输入到模型的输出之间它是由一系列的数学表达式相连接,它就是可以使用这种反向传播的模式进行优化的。所以这也就是深度学习能够实现端到端的原因。
虽然深度学习能实现非常棒的端到端的感知能力,实际上业界在使用深度学习的时候也发现了一系列的问题。下面主要列举三个例子,一块讨论一下业界和学术界目前遇到的这些问题以及业界和学术界的差异化,以及业界解决问题的方法。
学术界VS业界
数据前融合
学术界为了体现算法的先进性,他们会尽量采用尽量少的数据,去拟合出尽可能多的信息。举个例子,很多研究论文都会集中于说我通过一张图片就可以拟合出它的深度信息,可以做一个车辆三维姿态的估计,实际上对于业界来讲,会认为这样来做误差会比较大,比较好的拟合的结果误差可能在1米左右。
1米是什么概念呢?想象一下,汽车在路上以60千米/小时行驶的时候,没有0.1秒车子就会驶过1.6米左右,因此我们会觉得这个误差比较大。作为业界来讲,希望如果有的信息能够用传感器做一个准确的测量的话,宁愿多装一个传感器,而不是用算法去拟合,因为业界觉得数据的可靠性是最重要的。
这就会牵扯到业界会把不同的传感器都会做一个数据的前融合。所谓的数据前融合就是把数据送到算法,得出一个结构化数据之前,我们在原始数据上做一个前融合,业界会把激光雷达数据和摄像头数据做一个前融合,这样激光雷达的点云数据从原先的四维数据(x,y,z,r)变为7维数据。融合的好处是原始数据中有一个非常精确的三维的信息,并且对材料本身的一些信息,如反射率、颜色等也得到了一个信息的补充。
有人可能会问,这样融合时候,计算量会不会增加很多?实际上并不会。因为,首先从深度学习的角度来讲,你的数据的维度是多少就等同于你的数据的通道数是多少,通道数量对模型的前一两层并不会增加很大的计算量。而且作为深度学习来说,我们有很多的技巧来减少该计算量,比如说,我们可以做一些池化的处理、可以做一些一对一的卷积降维的处理,而且这些数据在进入深度学习运算之前,会做一些栅格化的处理,这样一来就会有效地控制好数据计算量的增幅。而我们得到的信息就会丰富很多。
数据后融合
所谓的数据后融合就是把不同传感器的算法的数据结构化处理后再做一个融合,这点学术界并不感兴趣,因为后融合一般很难体现他们算法的先进性。
这里举一个核心区域分割的例子

学术界一般采用的是像素集语义分割的方式对行驶区域的查找,像素集语义分割就是把图像上的无论是路面还是车,每一个像素都打上标签,这样一来就会有一系列的问题,比如说,上图中,可行驶区域边缘分割的并不是特别光滑,而且在收到光照的干扰的情况下边缘会出现明显的分类的错误,虽然非常多的论文和研究机构在说如何改进这一点,但是这的确是目前扔然存在的一个问题。
这时候业界会如何保证算法的鲁棒性呢?这时业界会采用另一个传感器来做同一件事情,两个传感器所产生的数据进行比较。之所以这样来做是为了尽量减少做同一件事情的时候的关联性。这样通过两种不同方法得出的同样的数据作比较的时候才会有互相做检查的安全的意义。
数据后融合的方法,如上图右侧,我们会看到点的数据,这里的算法并没有牵扯到深度学习,它是取一个点,然后对这个点取一大一小两个半径,通过两个半径再找两个平面,然后再计算这两个平面的法向量,再把这两个法向量做一个差。对于每个点都做这样一个操作之后就会得到一个路面几何信息变化率的数据,这个计算并不会增加额外的计算量,因为它并不像深度学习又要跑一个很庞大的网络,只是基于纸质运算所得到一个数据,而这样得到的数据是通过另一种方法来的,它跟基于图像得到的结构化数据的关联性几乎是没有的,这样是一种比较保险的做法。
自适应模块化网络架构
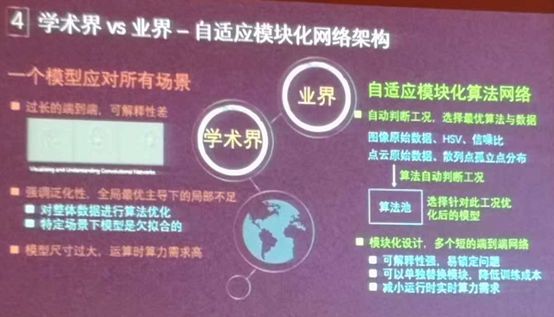
对于学术界只是想证明自己算法的优越性,希望通过一个模型应对所有场景,导致的结果是过长的端到端,可解释性会差;另外强调泛化性,全局最优主导下的局部不足;还有模型尺寸过大,参数过多,对运算力的需求会很高。
因为自动驾驶在实际使用的过程中,场景变化并不会特别的频繁,所以很多时候希望说我有一个模型可以很好的应对当前的情况,而不是说我有一个大的模型可以很好的应对所有的情况。
在业界如何解决这些问题呢?这里采用了自适应模块化算法网络,所谓的自适应是指当前传感器感受到的一些初步的信息先做一个场景的判断,可以快速的判断出这是白天还是晚上,下雨还是起雾,然后通过场景的判断之后,再到算法池里面去选择一个合适的专门训练过的模型,再通过这个模型进行计算感知。第一步做判断并不会额外增加更多的计算量,并且用到的信息也不多。然后将这些数据送到算法池,选择针对此工况优化后的模型。
模块化的设计,是多个短的端到端的网络有以下三个好处:易锁定问题、不需要过一遍完整的网络所以可降低训练成本、减小运行时实时算例需求。
展望
从V2X的角度去想,单辆车的感知不仅对自身是有益的同时也对周围其他车辆也是有益的,因为我们可以把路上行驶的每一辆车都看作是一个个传感器,可以把自己感知到的结构化数据实时传输到云端,这样能够帮助整个智能生态化环境的构建。
举两个例子,一个是相同目的地的车辆可以自然的形成一个实时的车队,只要前车做一个感知,后车做一个跟车,这样就会很轻松的完成一个自动驾驶车队的情况;另外一个就是一些大城市会面对交通的早晚高峰,此前有人提出了潮汐车道来解决此问题,但是目前的做法还是不够高效,如果能够达到一个车联网的状态的话,未来车道未必需要标上这样反向性的箭头了,因为可以适时动态的调整车流及方向,可以增大路面的利用率。

推荐阅读
▼
▎本文根据2018中国智能车大会上广汽研究院高翔博士演讲整理,智车科技(IV_Technology)整理编辑,转载请注明来源。
以上是关于自动驾驶的智慧之眼——感知的主要内容,如果未能解决你的问题,请参考以下文章