R语言系列第二期:②R编程函数数据输入等功能
Posted 生信发文助手
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言系列第二期:②R编程函数数据输入等功能相关的知识,希望对你有一定的参考价值。
在上一部分里,我们为大家介绍了R的会话管理和作图系统。链接:
在这个部分里,我们来了解一下R编程过程以及外部数据的导入。
1. R编程
我们之前接触了许多的函数,包括计算函数,作图函数,数据处理函数等等,其实有许多我们想要完成的过程,在R内置的函数里并不一定能够找到,而且从长远来看,使用R工作的主要方面和魅力所在就是创建属于自己的R函数。
我们以下面的函数为例,是上一个部分的例子,直方图和正态曲线的叠加,我们来尝试一个函数来解决它:
> hist.with.normal<-function(x,xlab=deparse(substitute(x)),...)
+ {
+ h<-hist(x,plot=F,...)
+ s<-sd(x)
+ m<-mean(x)
+ ylim<-range(0,h$density,dnorm(0,sd=s))
+ hist(x,freq=F,ylim=ylim,xlab=xlab,...)
+ curve(dnorm(x,m,s),add=T)
+ }
这样我们的函数就建立完成了,随后可以调用我们所编写的函数:
> hist.with.normal(rnorm(100))
#Tips:创建函数默认 函数名<-function(x,变量,...){内部的变量和数据}。
在这里注意下,xlab是一个默认变量,如果在使用函数时,不输入此变量的值,那默认为函数中调用的值,这里是取x的文字形式。比如说在调用的时候括号里是 (rnorm(1000)),那么横轴就会显示 “rnorm(1000)”。同时最后一个参数“...”可以使得函数可以增加参数,在调用的时候将参数传递给hist函数。
流程控制
目前,我们已经了解了简单表达式的赋值和函数的创建,但是作为一种语言软件,条件执行和循环结构才是R的灵魂。比如:
> y<-12345
> x<-y/2
> while(abs(x*x-y)>1e-10) x<-(x+y/x)/2
> x
[1] 111.1081
> x^2
[1] 12345
#Tips:这里while(condition) expression 结构,表示只要条件为真就执行后面的表达式。这个判断在表达式之前,所以可能发生计算一次也没有进行的情况。
同样一个算法的变体,只是判断出现在了循环尾,即先计算后判断:
> repeat{
+ x<-(x+y/x)/2
+ if (abs(x*x-y)<1e-10) break
+ }
> x
[1] 111.1081
这里出现了三个其他的流程控制结构:(a)复合表达式,几个表达式在花括号中放在一起;(b)条件执行的if结构;(c)break表达式,它会中断闭合的循环。
其实,使用更多的是for循环结构,它对一组固定的值集进行循环,如下例所示,他在单位区间上画了幂曲线。
> x<-seq(0,1,.05)
> plot(x,x,ylab="y",type="l")
> for(j in 2:8) lines(x,x^j)
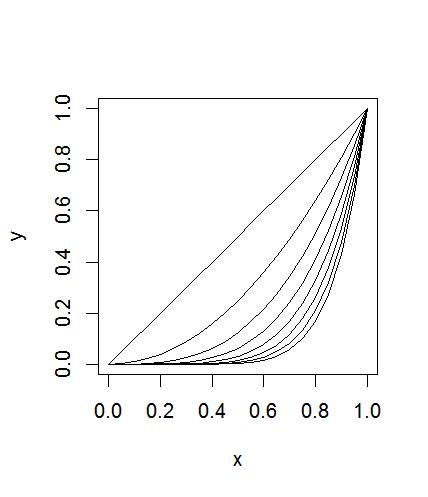
#Tips:type=“l”不是“1”,第二条语句是建立一条过原点斜率是1的直线,并且确定了整体的轴线。下面循环变量j,它依次取出在lines调用中使用的给定序列的值,然后下面就是分别做(x,x2),(x,x3)...的曲线。
2. 数据输入
有的时候可能我们需要输入海量的数据,而我们在录入的时候特别费时,即便数据本身不大,使用c(...)输入也已经变得很不方便了,因此导入外部数据就变成了一种便捷的方式。
#TIPS:我们大部分例子使用的数据集都包含在ISwR包中,你可以通过library(ISwR)获取。如果你想运用导入数据的方式创建数据集的话你必须处理数据文件的格式,使得数据能够被正确地识别。
#Tips:如果通过library(ISwR)获取包时显示错误: 找不到对象'ISwr',那么你需要安装ISwR包,install.packages("ISwR"),并且你的R版本要满足3.4.4以后的版本,因为ISwR是用R版本3.4.4来创建的。
① 读取外部文件
在R中读取数据最方便的方法是通过read.table()函数。它需要数据满足“ASCII”格式,就是一种用Windows记事本或任何其他纯文本编辑器创建的“无格式平面文件”。
read.table()读取的结果是一个数据框,所得数据的每一行包含来自一个对象(类似SAS里的观测)的所有数据,以特殊的顺序,用空格或其他的分隔符分开。文件的第一行可能包含一个给出变量名称的标头信息,推荐采取保留的标头。
在R的ISwR包中含有一个Thuesen等人收集的心室圆周缩短速率与空腹血糖相比较的例子,我们这里利用这个数据集进行演示。首先展示一下数据结构。
> thuesen
blood.glucose short.velocity
1 15.3 1.76
2 10.8 1.34
3 8.1 1.27
4 19.5 1.47
5 7.2 1.27
6 5.3 1.49
7 9.3 1.31
8 11.1 1.09
9 7.5 1.18
10 12.2 1.22
11 6.7 1.25
12 5.2 1.19
13 19.0 1.95
14 15.1 1.28
15 6.7 1.52
16 8.6 NA
17 4.2 1.12
18 10.3 1.37
19 12.5 1.19
20 16.1 1.05
21 13.3 1.32
22 4.9 1.03
23 8.8 1.12
24 9.5 1.70
我们可以把这一段数据剔除序号放入到新建的文本文件thuesen中,并把它放入到我们的某个固定位置。
#Tips:把数据输入文件,可以使用windows记事本或者其他任何文本编辑器。
#Tips:我们假设thuesen文件存放到了F盘的根目录下。
随后我们在R中输入这个文本:
> thuesen.new<-read.table("F:/thuesen.txt",header=T)
> thuesen.new
我们可以看到thuesen.new输出结果跟thuesen原始数据是一样的。
当读取因子变量时,最简单的办法是使用文本形式对它们进行编码。read.table()函数自动检测一个向量是字符向量还是数值向量,前者会转换成一个因子。例如,secretin内置数据集从文件中读取的开头如下:
> head(secretin)
gluc person time repl time20plus time.comb
1 92 A pre a pre pre
2 93 A pre b pre pre
3 84 A 20 a 20+ 20
4 88 A 20 b 20+ 20
5 88 A 30 a 20+ 30+
6 90 A 30 b 20+ 30+
这个文件也可以直接用read.table()读取,除了文件名字之外不需要其他参数。
> secr<-read.table("F:/secretin.txt",header=T)
> head(secr)
#Tips:像这样读取因子或许很方便,但是也有缺陷,各个水平的顺序是按字母排序的。如果不想要这样的结果,那么就需要对水平进行处理,变量进行重编码,处理因子。
> levels(secr$time)
[1] "20" "30" "60" "90" "pre"
② read.table()进一步探讨
当然,read.table()不止有这两个参数,它有很多选项可以控制输入,这里列举三个比较常用的参数。
l 字段分隔符:我们可以使用sep来指定分隔符,当使用了非空白符的分隔符时,两个数据间必须有一个精确地分隔符,并且两个连续的分隔符表示之间有一个缺失值。而默认条件下,需要具体代码表示缺失,也可以使用“ ”的形式。
l NA字符串:我们可以通过na.strings来指定哪些字符串来表示缺失。可以由几个不同的字符串组成。对于来自SAS的输出文档,可以使用na.strings=”.”。
l 不等字段计数:如果不是所有的行包含了相同数目的值,通常会别认为是错误的(除了标题行)。fill和flush参数可以用来处理不同长度的行。
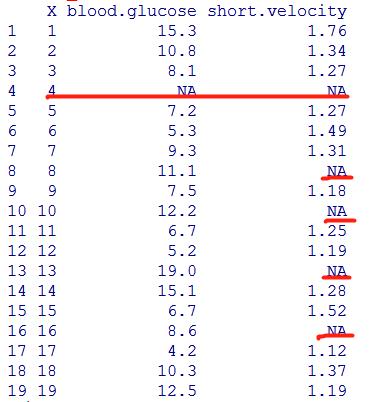
我们利用thuesen的改编形式文件read_table来完成这部分的例子(可以自己更改thuesen中的数据,用自己的方式尝试如下的代码):
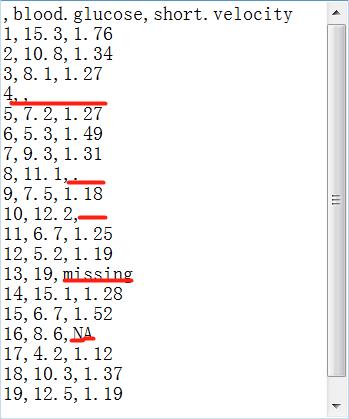
> read_table<-read.table("F:/read_table.txt",header=T,sep=",",na.string=c(".","missing"," ","NA"),fill=T)
> read_table
③ 其他程序接口
有的时候你希望R能够跟其他的统计软件或者电子表格之间相互读取数据。当然可以把其他软件或电子表格的数据回退到文本文档,然后在输入到R中使用,然而R是可以直接读入很多种类型的数据的。
read.table()有很多的变形,read.csv()和read.csv2()都是用来处理csv文件的,前者假定字段是由逗号“,”分隔,后一个由分号“;”分隔但是用逗号“,”做小数点(在欧洲语言格式常见)。这两种格式都默认header=T,还有read.delim和read.delim2,用于读取制表符(默认Tab-delimited)分隔的文件。
> read_csv=read.csv("F:/read_csv.csv")
R所带的foreign包是我们实现数据交互的重要的包,它包含读取多种格式文档的程序,包括来自SPSS(.SAV格式 read.spss())、SAS(read.ssd())、EPI-INFO、STATA、SYSTAT、Minitab中的文档。(read.ssd()用起来比较麻烦,不演示了,也不推荐使用)
> read_spss=read.spss("F:/spss.sav")
#Tips:有很多方法导入spss和sas文件,比如.sav的spss文件还可以用Hmisc包中的spss.get()函数导入。sas文件可以用misc包中的sas.get(),以及sas7bdat包中的read.sas7bdat()。
#Tips:同理如果出现:Error in library(sas7bdat) : 不存在叫‘sas7bdat’这个名字的程辑包。那么先安装包,然后加载。
> read_sas<-read.sas7bdat("F:/rad.sas7bdat")
还有一种便利的方法是从系统剪贴板中读取。比如说,在电子表格中选中一个矩形区域,复制,然后在R中使用
> read.table("clipboard",header=T)
其实最好的方式就是转换成不易出错的table或者csv的形式传输数据。不过随着R的更新,越来越多的便利方法会帮助我们实现软件之间的联合使用。
系列二的内容就到此结束了,这个系列帮助我们进一步了解了R的运行环境和风格,以及与外界软件文件的交互,下一个部分我们会为大家带来统计图表的绘制,敬请期待。
参考资料:
1.《Introductory Statistics with R Second Edition》 Peter Dalgaard著
2.《R语言初学者指南》人民邮电出版社 Brian Dennis著
3. Vicky的小笔记本《blooming for you》by Vicky
生信发文助手
多点好看,少点脱发
以上是关于R语言系列第二期:②R编程函数数据输入等功能的主要内容,如果未能解决你的问题,请参考以下文章