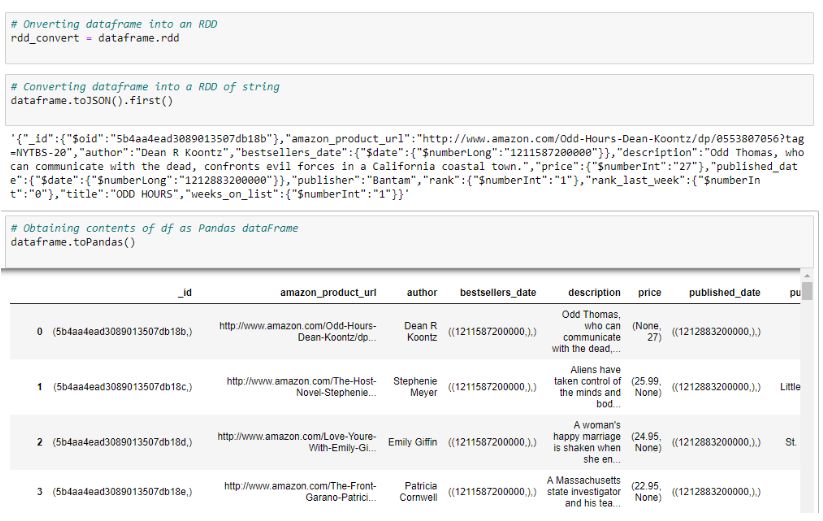
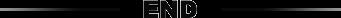5、查询 查询操作可被用于多种目的,比如用“select”选择列中子集,用“when”添加条件,用“like”筛选列内容。接下来将举例一些最常用的操作。完整的查询操作列表请看Apache Spark文档。 5.1、“Select”操作 可以通过属性(“author”)或索引(dataframe[‘author’])来获取列。 #Show all entries in title columndataframe.select("author").show(10)#Show all entries in title, author, rank, price columnsdataframe.select("author", "title", "rank", "price").show(10)
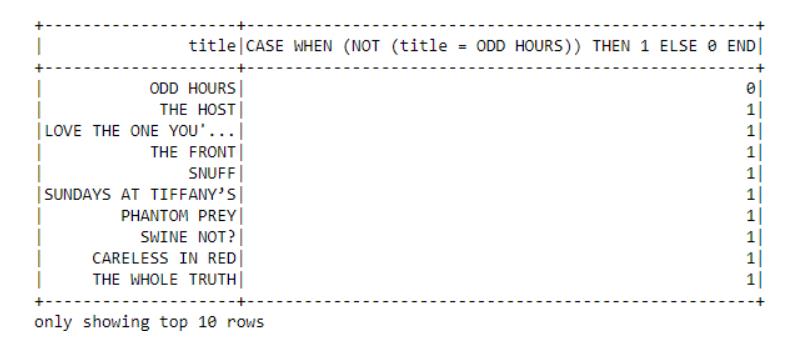
第一个结果表格展示了“author”列的查询结果,第二个结果表格展示多列查询。5.2、“When”操作 在第一个例子中,“title”列被选中并添加了一个“when”条件。 # Show title and assign 0 or 1 depending on titledataframe.select("title",when(dataframe.title != 'ODD HOURS',1).otherwise(0)).show(10)
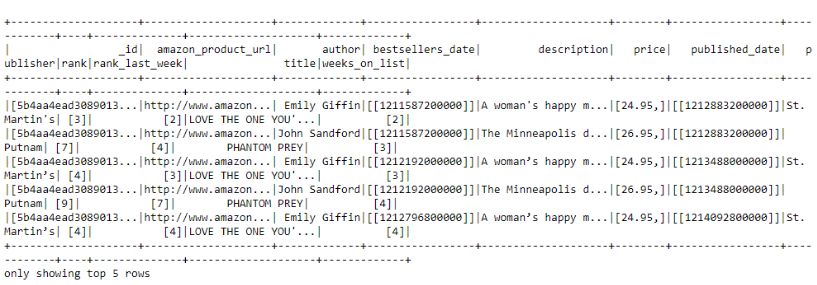
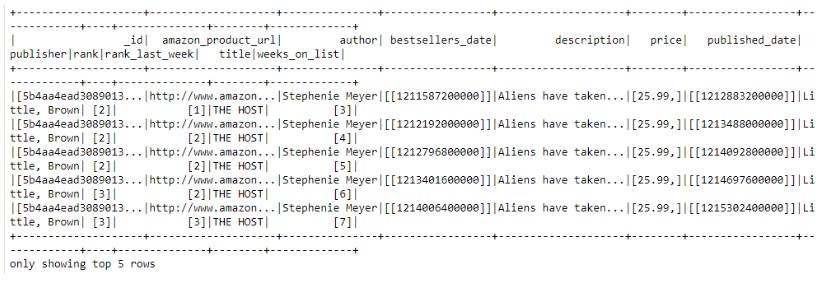
展示特定条件下的10行数据 在第二个例子中,应用“isin”操作而不是“when”,它也可用于定义一些针对行的条件。 # Show rows with specified authors if in the given optionsdataframe [dataframe.author.isin("John Sandford","Emily Giffin")].show(5)
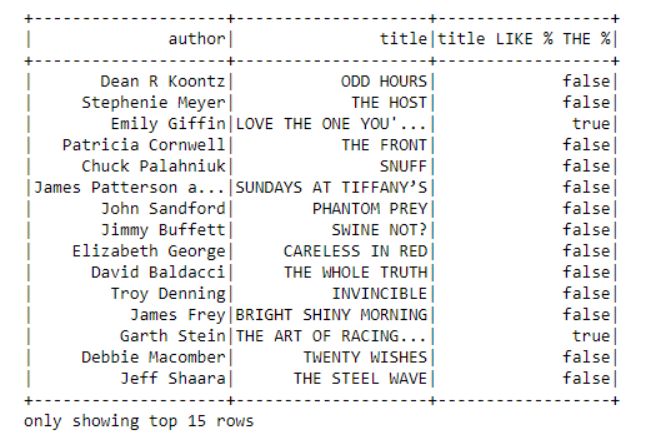
5行特定条件下的结果集5.3、“Like”操作 在“Like”函数括号中,%操作符用来筛选出所有含有单词“THE”的标题。如果我们寻求的这个条件是精确匹配的,则不应使用%算符。 # Show author and title is TRUE if title has " THE " word in titlesdataframe.select("author", "title",dataframe.title.like("% THE %")).show(15)
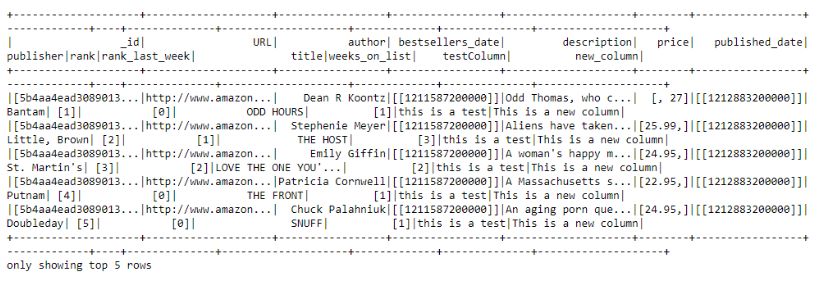
分别显示子字符串为(1,3),(3,6),(1,6)的结果6、增加,修改和删除列 在DataFrame API中同样有数据处理函数。接下来,你可以找到增加/修改/删除列操作的例子。 6.1、增加列 # Lit() is required while we are creating columns with exactvalues.dataframe = dataframe.withColumn('new_column',F.lit('This is a new column'))display(dataframe)
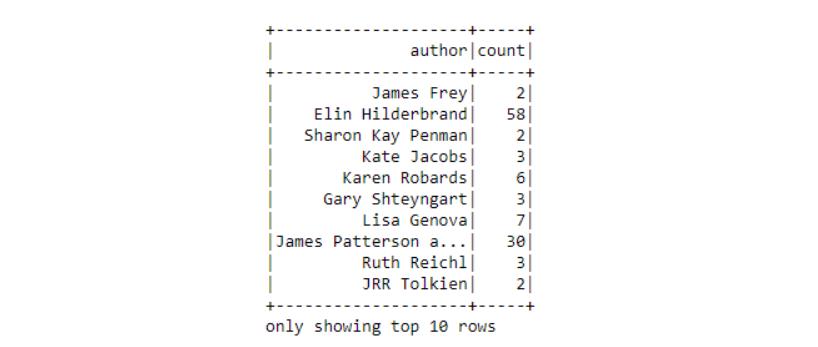
“publisher”和“published_date”列用两种不同的方法移除。 7、数据审阅 存在几种类型的函数来进行数据审阅。接下来,你可以找到一些常用函数。想了解更多则需访问Apache Spark doc。 # Returns dataframe column names and data typesdataframe.dtypes# Displays the content of dataframedataframe.show()# Return first n rowsdataframe.head()# Returns first rowdataframe.first()# Return first n rowsdataframe.take(5)# Computes summary statisticsdataframe.describe().show()# Returns columns of dataframedataframe.columns# Counts the number of rows in dataframedataframe.count()# Counts the number of distinct rows in dataframedataframe.distinct().count()# Prints plans including physical and logicaldataframe.explain(4) 8、“GroupBy”操作 通过GroupBy()函数,将数据列根据指定函数进行聚合。 # Group by author, count the books of the authors in the groupsdataframe.groupBy("author").count().show(10)
作者被以出版书籍的数量分组9、“Filter”操作 通过使用filter()函数,在函数内添加条件参数应用筛选。这个函数区分大小写。 # Filtering entries of title# Only keeps records having value 'THE HOST'dataframe.filter(dataframe["title"] == 'THE HOST').show(5)
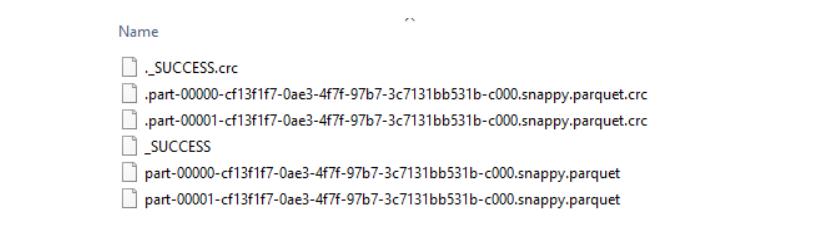
标题列经筛选后仅存在有“THE HOST”的内容,并显示5个结果。 10、缺失和替换值 对每个数据集,经常需要在数据预处理阶段将已存在的值替换,丢弃不必要的列,并填充缺失值。pyspark.sql.DataFrameNaFunction库帮助我们在这一方面处理数据。举例如下。 # Replacing null valuesdataframe.na.fill()dataFrame.fillna()dataFrameNaFunctions.fill()# Returning new dataframe restricting rows with null valuesdataframe.na.drop()dataFrame.dropna()dataFrameNaFunctions.drop()# Return new dataframe replacing one value with anotherdataframe.na.replace(5, 15)dataFrame.replace()dataFrameNaFunctions.replace() 11、重分区 在RDD(弹性分布数据集)中增加或减少现有分区的级别是可行的。使用repartition(self,numPartitions)可以实现分区增加,这使得新的RDD获得相同/更高的分区数。分区缩减可以用coalesce(self, numPartitions, shuffle=False)函数进行处理,这使得新的RDD有一个减少了的分区数(它是一个确定的值)。请访问Apache Spark doc获得更多信息。 # Dataframe with 10 partitionsdataframe.repartition(10).rdd.getNumPartitions()# Dataframe with 1 partitiondataframe.coalesce(1).rdd.getNumPartitions() 12、嵌入式运行SQL查询 原始SQL查询也可通过在我们SparkSession中的“sql”操作来使用,这种SQL查询的运行是嵌入式的,返回一个DataFrame格式的结果集。请访问Apache Spark doc获得更详细的信息。 # Registering a tabledataframe.registerTempTable("df")sc.sql("select * from df").show(3)sc.sql("select \ CASE WHEN description LIKE '%love%' THEN 'Love_Theme' \ WHEN description LIKE '%hate%' THEN 'Hate_Theme' \ WHEN description LIKE '%happy%' THEN 'Happiness_Theme' \ WHEN description LIKE '%anger%' THEN 'Anger_Theme' \ WHEN description LIKE '%horror%' THEN 'Horror_Theme' \ WHEN description LIKE '%death%' THEN 'Criminal_Theme' \ WHEN description LIKE '%detective%' THEN 'Mystery_Theme' \ ELSE 'Other_Themes' \ END Themes \ from df").groupBy('Themes').count().show() 13、输出 13.1、数据结构 DataFrame API以RDD作为基础,把SQL查询语句转换为低层的RDD函数。通过使用.rdd操作,一个数据框架可被转换为RDD,也可以把Spark Dataframe转换为RDD和Pandas格式的字符串同样可行。 # Converting dataframe into an RDDrdd_convert = dataframe.rdd# Converting dataframe into a RDD of stringdataframe.toJSON().first()# Obtaining contents of df as PandasdataFramedataframe.toPandas()
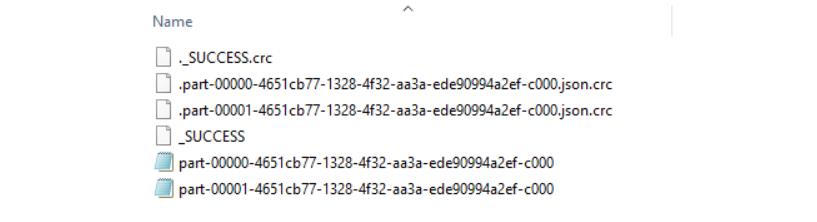
不同数据结构的结果 13.2、写并保存在文件中 任何像数据框架一样可以加载进入我们代码的数据源类型都可以被轻易转换和保存在其他类型文件中,包括.parquet和.json。请访问Apache Spark doc寻求更多保存、加载、写函数的细节。 # Write & Save File in .parquet formatdataframe.select("author", "title", "rank", "description") \.write \.save("Rankings_Descriptions.parquet")
当.write.save()函数被处理时,可看到Parquet文件已创建。# Write & Save File in .json formatdataframe.select("author", "title") \.write \.save("Authors_Titles.json",format="json")
当.write.save()函数被处理时,可看到JSON文件已创建。 13.3、停止SparkSession Spark会话可以通过运行stop()函数被停止,如下。 # End Spark Sessionsc.stop() 代码和Jupyter Notebook可以在我的GitHub上找到。 欢迎提问和评论!参考文献: 1. http://spark.apache.org/docs/latest/2. https://docs.anaconda.com/anaconda/ 原文标题:PySpark and SparkSQL BasicsHow to implement Spark with Python Programming原文链接:https://towardsdatascience.com/pyspark-and-sparksql-basics-6cb4bf967e53