大数据炒作?对于数据分析师意味着什么!
Posted i小码哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据炒作?对于数据分析师意味着什么!相关的知识,希望对你有一定的参考价值。
大数据从无人谈及,到现在的大肆炒作,到底什么才是大数据,对于数据分析师,它有意味着什么?本文将为您解答。
我用Google搜索了一下“Big Data”,得到了19,600,000个结果……而使用同样的词语,在两年前你几乎搜索不到什么内容,而现在大数据的内容被大肆炒作,内容多得让人眼花缭乱。而这些内容主要是来自IBM、麦肯锡和O’Reilly ,大多数文章都是基于营销目的的夸夸其谈,对真实的情况并不了解,有些观点甚至是完全错误的。我问自己…… 大数据之于数据分析师,它意味着什么呢?
如下图所示,谷歌趋势显示,与“网站分析”(web analytics)和”商业智能”(business intelligence)较为平稳的搜索曲线相比,“大数据”(big data)的搜索量迎来了火箭式的大幅度增长。
01 大数据 – 炒作
Gartner把“大数据”的发展阶段定位在“社交电视”和“移动机器人”之间,正向着中部期望的高峰点迈进,而现在是达到较为成熟的阶段前的二至五年。这种定位有着其合理性。各种奏唱着“大数据”颂歌的产品数量正在迅速增长,大众媒体也进入了“大数据”主题的论辩中,比如纽约时报的“大数据的时代“,以及一系列在福布斯上发布的题为” 大数据技术评估检查表“的文章。
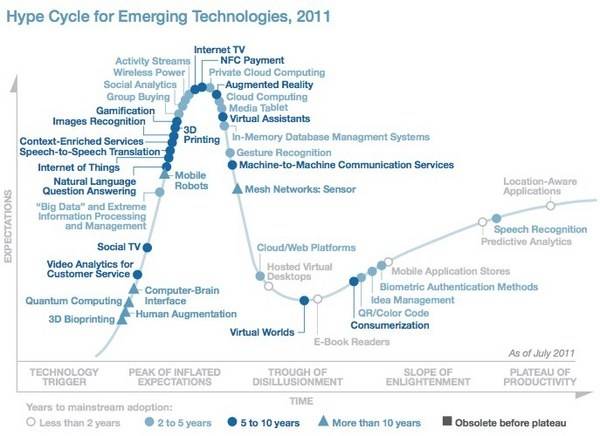
进步的一面体现在,大数据的概念正在促使内部组织的文化发生转变,对过时的“商务智能”形成挑战,并促进了“分析”意识的提升。
基于大数据的创新技术可以很容易地被应用到类似数据分析的各种环境中。值得一提的是,企业组织通过应用先进的业务分析,业务将变得更广泛、更复杂,价值也更高,而传统的网站分析受到的关注将会有所减弱。
02 大数据 – 定义
什么是“大数据”,目前并没有统一的定义。维基百科提供的定义有些拙劣,也不完整:“ 大数据,指的是所涉及的数据量规模巨大到无法通过主流的工具,在合理的时间内撷取、管理、处理、并整理成为人们所能解读的信息 “。
IBM 提供了一个充分的简单易懂的概述:
大数据有以下三个特点:大批量(Volume)、高速度(Velocity)和多样化(Variety) 。
大批量 – 大数据体积庞大。企业里到处充斥着数据,信息动不动就达到了TB级,甚至是PB级。
高速度 – 大数据通常对时间敏感。为了最大限度地发挥其业务价值,大数据必须及时使用起来。
多样化 – 大数据超越了结构化数据,它包括所有种类的非结构化数据,如文本、音频、视频、点击流、日志文件等等都可以是大数据的组成部分。
MSDN的布莱恩·史密斯在IBM的基础上增加了第四点:
变异性 – 数据可以使用不同的定义方式来进行解释。不同的问题需要不同的阐释。
03 大数据 – 技术角度
大数据包括了以下几个方面:数据采集、存储、搜索、共享、分析和可视化,而这些步骤在商务智能中也可以找到。在皮特·沃登的“ 大数据词汇表 “中,囊括了60种创新技术,并提供了相关的大数据技术概念的简要概述。
获取 :数据的获取包括了各种数据源、内部或外部的、结构化或非结构化的数据。“大多数公共数据源的结构都不清晰,充满了噪音,而且还很难获得。” 技术: Google Refine、Needlebase、ScraperWiki、BloomReach 。
序列化 :“你在努力把你的数据变成有用的东西,而这些数据会在不同的系统间传递,并可能存储在不同节点的文件中。这些操作都需要某种序列化,因为数据处理的不同阶段可能需要不同的语言和API。当你在处理非常大量的记录时,该如何表示和存储数据,你所做的选择对你的存储要求和性能将产生巨大影响。 技术: JSON、BSON、Thrift、Avro、Google Protocol Buffers 。
存储 :“大规模的数据处理操作使用了全新的方式来访问数据,而传统的文件系统并不适用。它要求数据能即时大批量的读取和写入。效率优先,而那些有助于组织信息的易于用户使用的目录功能可能就显得没那么重要。因为数据的规模巨大,这也意味着它需要被存储在多台分布式计算机上。“ 技术: Amazon S3、Hadoop分布式文件系统 。
服务器 :“云”是一个非常模糊的术语,我们可能对它所表示的内容并不很了解,但目前在计算资源的可用性方面已有了真正突破性的发展。以前我们都习惯于购买或长期租赁实体机器,而现在更常见的情况是直接租用正运行着虚拟实例的计算机来作为服务器。
这样供应商可以以较为经济的价格为用户提供一些短期的灵活的机器租赁服务,这对于很多数据处理应用程序来说这是再理想不过的事情。因为有了能够快速启动的大型集群,这样使用非常小的预算处理非常大的数据问题就可能成为现实。“ 技术: Amazon EC2、Google App Engine、Amazon Elastic Beanstalk、Heroku 。
NoSQL :在IT行为中,NoSQL(实际上意味着“不只是SQL”)是一类广泛的数据库管理系统,它与关系型数据库管理系统(RDBMS)的传统模型有着一些显著不同,而最重要的是,它们并不使用SQL作为其主要的查询语言。这些数据存储可能并不需要固定的表格模式,通常不支持连接操作,也可能无法提供完整的ACID(原子性—Atomicity、一致性—Consistency、隔离性—Isolation、持久性—Durability)的保证,而且通常从水平方向扩展(即通过添加新的服务器以分摊工作量,而不是升级现有的服务器)。 技术: Apache Hadoop、Apache Casandra、MongoDB、Apache CouchDB、Redis、BigTable、HBase、Hypertable、Voldemort 。
MapReduce :“在传统的关系数据库的世界里,在信息被加载到存储器后,所有的数据处理工作才能开始,使用的是一门专用的基于高度结构化和优化过的数据结构的查询语言。这种方法由Google首创,并已被许多网络公司所采用,创建一个读取和写入任意文件格式的管道,中间的结果横跨多台计算机进行计算,以文件的形式在不同的阶段之间传送。“ 技术: Hadoop和Hive、Pig、Cascading、Cascalog、mrjob、Caffeine、S4、MapR、Acunu、Flume、Kafka、Azkaban、Oozie、Greenplum 。
处理 :“从数据的海洋中获取你想要的简洁而有价值的信息是一件挑战性的事情,不过现在的数据系统已经有了长足的进步,这可以帮助你把数据集到转变成为清晰而有意义的内容。在数据处理的过程中你会遇上很多不同的障碍,你需要使用到的工具包括了快速统计分析系统以及一些支持性的助手程序。“ 技术: R、Yahoo! Pipes、Mechanical Turk、Solr/ Lucene、ElasticSearch、Datameer、Bigsheets、Tinkerpop 。 初创公司: Continuuity、Wibidata、Platfora 。
自然语言处理 :“自然语言处理(NLP)……重点是利用好凌乱的、由人类创造的文本并提取有意义的信息。” 技术: 自然语言工具包Natural Language Toolkit、Apache OpenNLP、Boilerpipe、OpenCalais。
机器学习 :“机器学习系统根据数据作出自动化决策。系统利用训练的信息来处理后续的数据点,自动生成类似于推荐或分组的输出结果。当你想把一次性的数据分析转化成生产服务的行为,而且这些行为在没有监督的情况下也能根据新的数据执行类似的动作,这些系统就显得特别有用。亚马逊的产品推荐功能就是这其中最著名的一项技术应用。“ 技术: WEKA、Mahout、scikits.learn、SkyTree 。
可视化 :“要把数据的含义表达出来,一个最好的方法是从数据中提取出重要的组成部分,然后以图形的方式呈现出来。这样就可以让大家快速探索其中的规律而不是仅仅笼统的展示原始数值,并以此简洁地向最终用户展示易于理解的结果。随着Web技术的发展,静态图像甚至交互式对象都可以用于数据可视化的工作中,展示和探索之间的界限已经模糊。“ 技术: GraphViz、Processing、Protovis、Google Fusion Tables、Tableau 。
04 大数据 – 挑战
最近举行的世界经济论坛也在讨论大数据,会议确定了一些大数据应用的机会,但在数据共用的道路上仍有两个主要的问题和障碍。
1.隐私和安全
正如Craig & Ludloff在“隐私和大数据“的专题中所提到的,一个难以避免的危机正在形成,大数据将瓦解并冲击着我们生活的很多方面,这些方面包括私隐权、政府或国际法规、隐私权的安全性和商业化、市场营销和广告……
2.人力资本
麦肯锡全球研究所的报告显示 ,美国的数据人才的缺口非常大,还将需要140,000到190,000个有着“深度分析”专业技能的工作人员和1.500个精通数据的经理。寻找熟练的“网站分析”人力资源是一个挑战,另外,要培养自己的真正拥有分析技能的人员,需要学习的内容很多,这无疑是另一个大挑战。
05 大数据 – 价值创造
很多大数据的内容都提及了价值创造、竞争优势和生产率的提高。要利用大数据创造价值,主要有以下六种方式。
透明度 :让利益相关人员都可以及时快速访问数据。
实验 :启用实验以发现需求,展示不同的变体并提升效果。随着越来越多的交易数据以数字形式存储,企业可以收集更准确、更详细的绩效数据。
细分 :更精细的种群细分,可以带来不同的自定义行为。
决策支持 :使用自动化算法替换/支持人类决策,这可以改善决策,减少风险,并发掘被隐藏的但有价值的见解。
创新 :大数据有助于企业创造出新的产品和服务,或提升现有的产品和服务,发明新的商业模式或完善原来的商业模式。
工业领域的增长 :有了足够的和经过适当培训的人力资源,那些重要的成果才会成为现实并产生价值。
06 数据分析的机会领域
当“网站分析”发展到“数据智能“,毫无疑问,数据分析人员也工作也应该发生一些转变,过去的工作主要是以网站为中心并制定渠道的具体战术,而在将来则需要负责更具战略性的、面向业务和(大)数据专业知识的工作。
数据分析师的主要关注点不应该是较低层的基础设施和工具开发。以下几点是数据分析的机会领域:
处理 :掌握正确的工具以便可以在不同条件下(不同的数据集、不同的业务环境等)进行高效的分析。目前网站分析专家们最常用的工具无疑是各类网站分析工具,大多数人并不熟悉商业智能和统计分析工具如Tableau、SAS、Cognos等的使用。拥有这些工具的专业技能将对数据分析人员的发展大有好处。
NLP:学习非结构化数据分析的专业技能,比如社交媒体、呼叫中心日志和邮件的数据多为非结构化数据。从数据处理的角度来看,在这个行业中我们的目标应该是确定和掌握一些最合适的分析方法和工具,无论是社会化媒体情感分析还是一些更复杂的平台。
可视化 :掌握仪表板的展示技能,或者宽泛点来说,掌握数据可视化的技术是摆在数据分析师面前一个明显的机会(注:不要把数据可视化与现在网络营销中常用的“信息图”infographics相混淆)。
07 行动计划
在大数时代,其中一个最大的挑战将是满足需求和技术资源的供给。当前的“网站分析”的基础普遍并不足够成熟以支持真正的大数据的使用,填补技能差距,越来越多的“网站分析师”将成长为“数据分析师”。
根据艾瑞的研究未来数据分析人才需要上千万人,但是一个好的数据分析师,即需要冰山上的技能,更需要冰山下的逻辑思维、对业务熟悉程度,如果把复杂的数据还原成为一个业务逻辑并指南运营,这是成功的关键。
End.
获得20G
python入门视频课
往期实战及福利
2.7G 380份最新数据分析报告
40G 人工智能算法课
已关注的小伙伴,直接回复数据分析报告、人工智能算法
关注后,回复 PM2.5 获得
关注后,回复 世界杯, 获得
关注后,回复“豆瓣电影“,获得
关注后,回复“python可视化”,获得 所有源代码
以上是关于大数据炒作?对于数据分析师意味着什么!的主要内容,如果未能解决你的问题,请参考以下文章