大数据下Python的三款大数据分析工具
Posted 21CTO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据下Python的三款大数据分析工具相关的知识,希望对你有一定的参考价值。
导读:Python在大数据领域中被常用已经不是什么稀奇事。现在让我们了解三个Python工具/库来处理自己的大数据。
在本文中,我们准备讨论三个关于Python在大数据方面处理的工具,可以帮助大家在产品层面提升大数据编程的技术。
背景
在本文中,我使用了virtualenv,pyenv,你也可以使用其它环境或本地的Python均可。
以下实例是在IPython环境下运行的,如果你也愿意用,请先安装:
$ mkdir python-big-data
$ cd python-big-data
$ virtualenv ../venvs/python-big-data
$ source ../venvs/python-big-data/bin/activate
$ pip install ipython
$ pip install pandas
$ pip install pyspark
$ pip install scikit-learn
$ pip install scipy
好的,让我们开始大数据处理之旅~
Python所用数据
在我们阅读本文时,需要使用一些测试数据来完成这些示例。
我们在Python中的数据是在几天的时间内从网站获得的实际生产日志。这些数据在技术上并不是大数据,大小只有大约2M左右,但它对我们的目标来说已经非常有用了。
要获得大数据的样本(比如大于1Tb),就需要加强我们的基础设施。
$ git clone https://github.com/admintome/access-log-data.git
该数据是一个简单的CSV文件,每行代表一个单独的日志,字段用逗号分隔,如下:
2018-08-01 17:10,'www2','www_access','172.68.133.49 - - [01/Aug/2018:17:10:15 +0000] "GET /wp-content/uploads/2018/07/spark-mesos-job-complete-1024x634.png HTTP/1.0" 200 151587 "https://dzone.com/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/67.0.3396.99 Safari/537.36"'
以下是日志的数据结构:
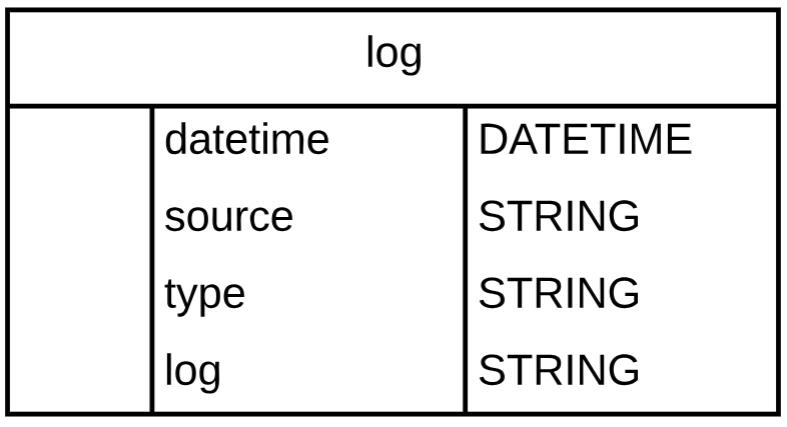
现在我们已经有了能够使用的数据,接着来看三个Python大数据工具。
由于对数据执行时会有很多多样性和复杂性,本文将重点介绍如何加载数据并分析一小部分数据样本。
对于列出的每个工具,我们也会提供链接以方便开发者了解更多信息。
1 Python Pandas
我们要讨论的第一个工具是Python Pandas(官网:https://pandas.pydata.org/)。 正如它的网站上所描述的,Pandas是一个开源的Python数据分析库。
让我们启动IPython,使用pandas来对我们的示例数据进行一些操作:
import pandas as pd
headers = ["datetime", "source", "type", "log"]
df = pd.read_csv('access_logs_parsed.csv', quotechar="'", names=headers)
大约一秒后它应会返回给我们如下数据:
[6844 rows x 4 columns]
In [3]:
如你所见,样本数据有大约7000行数据,可以看到Pandas找到了四列与上述模式匹配的数据列。
接着Pandas自动创建了一个和我们CSV文件对应的DataFrame对象。让我们看一下,使用head()函数导入的数据样本。
In [11]: df.head()
Out[11]:
datetime source type log
0 2018-08-01 17:10 www2 www_access 172.68.133.49 - - [01/Aug/2018:17:10:15 +0000]...
1 2018-08-01 17:10 www2 www_access 162.158.255.185 - - [01/Aug/2018:17:10:15 +000...
2 2018-08-01 17:10 www2 www_access 108.162.238.234 - - [01/Aug/2018:17:10:22 +000...
3 2018-08-01 17:10 www2 www_access 172.68.47.211 - - [01/Aug/2018:17:10:50 +0000]...
4 2018-08-01 17:11 www2 www_access 141.101.96.28 - - [01/Aug/2018:17:11:11 +0000]...
使用Python Pandas处理大数据,可以做很多实用的事情。单独使用Python可以修改数据,现在有了Pandas,就可以在Python中直接进行数据分析。
数据科学家通常将Python Pandas与IPython一起使用,以交互的方式分析大量数据集,从该数据中获取有意义的商业智能。开发者可以登录Pandas官方网站了解更多信息。
PySpark
我们将讨论的下一个工具叫 PySpark,这是一款来自Apache Spark项目的大数据分析库。
PySpark为我们提供了许多用在Python中分析大数据的功能。它带有自己的shell,可以从命令行运行它:
$ pyspark
这样就会启动pyspark shell。
(python-big-data)[email protected]:~/Development/access-log-data$ pyspark Python 3.6.5 (default, Apr 1 2018, 05:46:30) [GCC 7.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. 2018-08-03 18:13:38 WARN Utils:66 - Your hostname, admintome resolves to a loopback address: 127.0.1.1; using 192.168.1.153 instead (on interface enp0s3) 2018-08-03 18:13:38 WARN Utils:66 - Set SPARK_LOCAL_IP if you need to bind to another address 2018-08-03 18:13:39 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 2.3.1 /_/ Using Python version 3.6.5 (default, Apr 1 2018 05:46:30) SparkSession available as 'spark'. >>>
让我们使用PySpark Shell加载样例数据:
dataframe = spark.read.format("csv").option("header","false").option("mode","DROPMALFORMED").option("quote","'").load("access_logs.csv")
dataframe.show()
PySpark将为我们提供创建好的DataFrame示例。
>>> dataframe2.show()
+----------------+----+----------+--------------------+
| _c0| _c1| _c2| _c3|
+----------------+----+----------+--------------------+
|2018-08-01 17:10|www2|www_access|172.68.133.49 - -...|
|2018-08-01 17:10|www2|www_access|162.158.255.185 -...|
|2018-08-01 17:10|www2|www_access|108.162.238.234 -...|
|2018-08-01 17:10|www2|www_access|172.68.47.211 - -...|
|2018-08-01 17:11|www2|www_access|141.101.96.28 - -...|
|2018-08-01 17:11|www2|www_access|141.101.96.28 - -...|
|2018-08-01 17:11|www2|www_access|162.158.50.89 - -...|
|2018-08-01 17:12|www2|www_access|192.168.1.7 - - [...|
|2018-08-01 17:12|www2|www_access|172.68.47.151 - -...|
|2018-08-01 17:12|www2|www_access|192.168.1.7 - - [...|
|2018-08-01 17:12|www2|www_access|141.101.76.83 - -...|
|2018-08-01 17:14|www2|www_access|172.68.218.41 - -...|
|2018-08-01 17:14|www2|www_access|172.68.218.47 - -...|
|2018-08-01 17:14|www2|www_access|172.69.70.72 - - ...|
|2018-08-01 17:15|www2|www_access|172.68.63.24 - - ...|
|2018-08-01 17:18|www2|www_access|192.168.1.7 - - [...|
|2018-08-01 17:18|www2|www_access|141.101.99.138 - ...|
|2018-08-01 17:19|www2|www_access|192.168.1.7 - - [...|
|2018-08-01 17:19|www2|www_access|162.158.89.74 - -...|
|2018-08-01 17:19|www2|www_access|172.68.54.35 - - ...|
+----------------+----+----------+--------------------+
only showing top 20 rows
我们再次看到DataFrame中有4列与期待的模式匹配。 注意,DataFrame只是数据在内存中的表示,可以被看成数据库表或者一张Excel电子表格。
现在我们聊聊最后一个工具。
Python SciKit-Learn
任何关于大数据的研讨,都会引发机器学习方面的话题。 幸运的是,Python开发人员有很多的选择来使用机器学习算法。
在没有详细掌握机器学习的情况下,我们需要获得一些执行机器学习的数据。 在本文中提供的示例数据回为不是纯数值数据,我们需要操纵数据并将其呈现为数字格式,相关方法超过了本文范围。 比如,可以按时间映射日志条目以获得具有两列的DataFrame:一分钟内的日志数和当前时间:
+------------------+---+
| 2018-08-01 17:10 | 4 |
+------------------+---+
| 2018-08-01 17:11 | 1 |
+------------------+---+
通过以上形式的数据,我们可以执行机器学习来预测未来可能获得的访问数量。 我刚刚提到过这超出了本文的范围。
幸运的是,SciKit-Learn附带了一些样本数据集,让我们先看这些示例数据的内容,来看看能做些什么。
In [1]: from sklearn import datasets
In [2]: iris = datasets.load_iris()
In [3]: digits = datasets.load_digits()
In [4]: print(digits.data)
[[ 0. 0. 5. ... 0. 0. 0.]
[ 0. 0. 0. ... 10. 0. 0.]
[ 0. 0. 0. ... 16. 9. 0.]
...
[ 0. 0. 1. ... 6. 0. 0.]
[ 0. 0. 2. ... 12. 0. 0.]
[ 0. 0. 10. ... 12. 1. 0.]]
这将引入两个用于分类机器学习算法的数据集,用于对数据进行分类。
浏览SciKit-Learn 的scikit教程,我们还可以到http://scikit-learn.org/stable/tutorial/basic/tutorial.html 来了解相关信息。
小结
以上是三个常用于Python的大数据工具,Python现在已经大数据相关以及R和Scala语言的主要参与者。
希望大家喜欢这篇文章。 如果你有类似心得,欢迎分享给21CTO社区, 也欢迎大家在文章下面评论~
编译:洛逸
来源:https://dzone.com/articles/big-data-python-3-big-data-analytics-tools
以上是关于大数据下Python的三款大数据分析工具的主要内容,如果未能解决你的问题,请参考以下文章