数据分析的流程 -- 数据探索之开篇
Posted Python爱好者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析的流程 -- 数据探索之开篇相关的知识,希望对你有一定的参考价值。

简书专栏:https://www.jianshu.com/u/6a0df19d3f5b
本文是数据探索系列的初篇,这一系列文章将会带你摸索进入数据分析的大门,这里我们会用具体的实例串联起Python数据探索的方法和统计学的基本概念。作为开篇,让我们首先来了解下数据分析的基本流程以及统计学中的基本概念。
数据分析流程
数据分析一般包括以下步骤:
提出有价值的问题,好的问题就像是瞄准了正确的靶心,才能使后续的动作有意义。
收集原始数据,数据来源可能是丰富多样的,格式也可能不尽相同。
清洗数据,理顺杂乱的原始数据,并修正数据中的错误,这一步比较繁杂,但确是整个分析的基石。
进行探索式分析,对整个数据集有个全面的认识,以便后续选择何种分析策略。
分析数据,这里常常用到机器学习、数据挖掘、深度学习等算法。
得出结论,可视化结果,并使用报告、图表等形式展现出来,与他人交流。
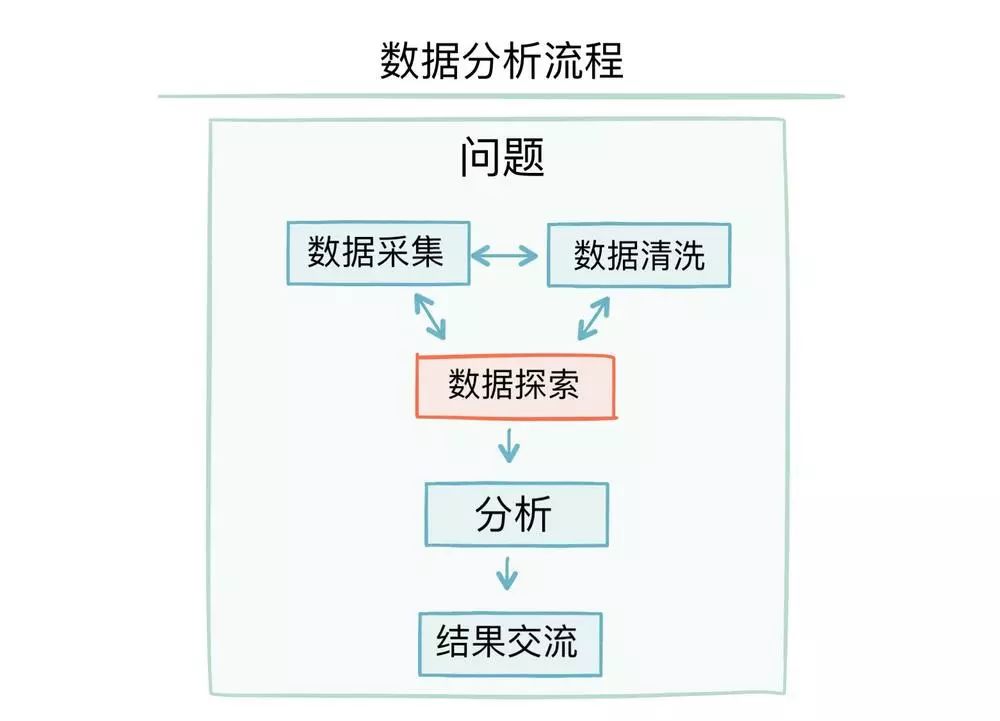
数据分析流程示意图
问题是这一系列过程的核心,所有的步骤最终都要回归到能否解决问题上来。虽然流程大体上是这样的,但具体环节之间并不一定按顺序一步步进行,它们之间可能需要往复多次。比如采集、清洗、探索数据之间,就可能需要反复多次才能得到理想的数据,而这部分往往需要消耗整个分析过程的大部分精力。
本系列文章将会集中在数据探索这一环节上,看一看怎么用Python并结合统计学知识对数据进行探索分析的。下面就让我们从具体的实例入手。
首先,我们要解决的问题是什么?我想问在如今物资极度丰富的社会中富人比一般人是更胖呢还是更瘦呢?也许在过去贫穷的年代,只有富人们能吃的饱饭,他们应该会更胖吧,可今天还是这个样子吗?
有了数据,接下来就是清洗并提取出我们想要的维度。BRFSS数据包含好几百个维度的指标,我们需要阅读其codebook才能明白数据代表的含义并找到需要的指标。原始数据是ASCII格式,需要采用 pandas.read_fwf() 来读取。清洗时不仅要正确提取所需变量,还需要对数据进行恰当转换使之成为我们可以理解的量。这里将数据提取和清洗的代码存入brfss.py中,只需按如下方式调取即可。
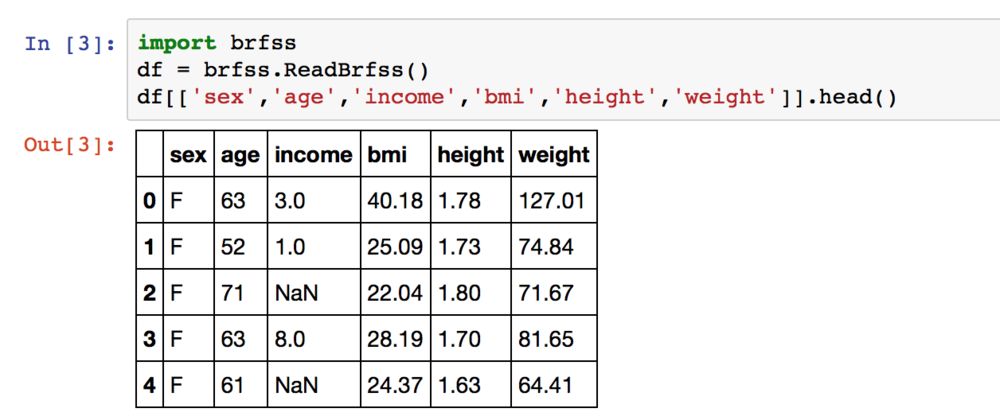
导入数据
上面显示了前几条数据,列出了调查对象的性别、年龄、收入分级、BMI指数、身高、体重信息。
接下来我们围绕之前提出的问题,就可以对数据进行探索式分析,比如查看单个变量的属性和分布、一组变量的相关性关系等描述性统计学方法,参数估计和假设检验等推断性统计学方法,以及数据可视化的方法。这些都是本系列文章后续将要展开的内容。
但在深入之前,让我们先了解下统计学中的几个基本概念。
统计学abc
为了更好地理解,我们使用一组组概念的对比来解释。
总体 VS 样本:总体是我们感兴趣的目标的数据集。在我们关于“美国的富人会更胖吗”这个问题下,总体是全部美国人的数据,显然数据量非常庞大,难以全部获取。那么如何解决呢?于是就有了样本,即在总体中取一子集,我们使用的BRFSS数据集就是一个样本数据。可见总体往往是很大的,因为不可能完整获取有时只是概念上的,所以我们常常需要采用样本观测到的数据来推测总体的性质。当然,在有了大规模分布式存储和计算能力的今天,也许总体数据的取得也不再是难事了,这正是大数据的魅力所在。
参数 VS 统计量:用来描述总体特性的测量数称为总体的参数,而用来描述样本特性的测量数称为样本统计量。在我们的问题中,全体美国人BMI指数的平均值是参数,而BRFSS数据集中BMI指数的平均值则是统计量。统计学中时常使用样本的统计量来对总体参数进行估计,在后续讲到参数估计时我们会详细展开。
因果性 VS 相关性: 统计学中常说相关性并不意味着因果性,而生活中我们却常常错把相关性的关系当成因果关系。比如公鸡总是在早上天亮的时候打鸣,那你能说是公鸡打鸣导致了天亮吗?
实验 VS 调研:那么在统计学中我们就得不到因果关系吗?也不是的。一般的调研数据得到的都是相关性关系,比如我们后续会研究的BRFSS调研数据。要想得到因果关系的证明,需要设计非常严格的实验才行。比如研究某项新药对某个疾病是否有疗效,就要设计一项统计学实验,其中又需要了解如下概念:
控制组 VS 对照组:首先需要将实验对象随机分为两组,控制组服用新药,对照组不服用新药。
** 独立变量 VS 依赖变量**:是否服用新药是独立变量(independent variables),而观测到的服药后的疗效,是相应的依赖变量(dependent variables)。我们往往需要分析这两者的关系,来判断新药是否有疗效。
药物 VS 安慰剂:对于实验对象,也许他们因为心理上相信药物有效而产生好转的征兆,为了避免这类心理上的影响,两组实验对象都需要服药,只不过控制组服用的是真正需要测试的药物,而对照组服用的是没有效果的安慰剂而已。
双盲实验:不仅受试者会受到心理的干扰,实验的观察测量人员也会受到主观偏见的影响。所以在实验中,无论是实验对象还是实验人员,都不知道哪组是控制组,而哪组又是对照组,这被称为双盲实验。
本文介绍了数据分析流程,包括提问、数据采集、清洗、探索、分析和结果交流,以及像总体和样本、相关性和因果性、调研和实验这些统计学中的基本概念。下一次我们将使用Python真刀实枪地对BRFSS数据进行描述性统计分析。
数据探索系列目录:
数据分析流程(本文)
描述性统计分析
统计分布
参数估计
假设检验
参考文献
《Think Stats 2》
《统计学》,William Mendenhall著
Data science done well looks easy
致谢:
感谢tiger同学和解密大数据社群小伙伴们的鼓励和支持,很开心能与大家一同成长

Python爱好者社区历史文章大合集:
小编的转行入职数据科学(数据分析挖掘/机器学习方向)【最新免费】
小编的Python入门免费视频课程!!!
小编的Python快速上手matplotlib可视化库!!!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。
以上是关于数据分析的流程 -- 数据探索之开篇的主要内容,如果未能解决你的问题,请参考以下文章